AWS 기술 블로그
Amazon Nova Premier와 에이전트 워크플로우를 활용한 코드 마이그레이션 간소화
시작하기 전에
많은 기업들이 레거시 기술로 구축된 미션 크리티컬 시스템의 유지보수와 확장성 한계로 어려움을 겪고 있습니다. 동일 언어 내에서의 코드 리팩터링이나 일반적인 코드 변환의 경우에는 다양한 LLM 모델과 솔루션이 존재하지만, 서로 다른 프로그래밍 언어 간의 변환이나 고객의 복잡하고 특수한 요구사항을 충족하는 시스템 전환은 여전히 까다로운 과제입니다.이 블로그 포스트는 Amazon Bedrock Converse API와 Amazon Nova Premier를 에이전트 워크플로우를 활용하여 레거시 C 코드를 현대적인 Java/Spring 프레임워크 애플리케이션으로 체계적으로 마이그레이션하는 방법을 보여줍니다. 마이그레이션 프로세스를 전문화된 에이전트 역할로 분해하고 견고한 검증 루프를 구현함으로써 저희가 제안하는 코드 마이그레이션 방식은 다음과 같은 이점을 얻을 수 있습니다:
- 마이그레이션 시간과 비용 절감: 자동화가 반복적인 변환 작업을 처리하는 동안 엔지니어는 고부가가치 작업에 집중할 수 있습니다.
- 코드 품질 향상: 전문화된 검증 에이전트가 마이그레이션된 코드가 현대적인 모범 사례를 따르도록 보장합니다.
- 위험 최소화: 체계적인 접근 방식이 마이그레이션 중 중요한 비즈니스 로직 손실을 방지합니다.
- 클라우드 통합 지원: 결과로 나온 Java/Spring 코드는 AWS 서비스와 쉽게 통합될 수 있습니다.
코드 전환 과제 고려사항
C에서 Java로의 대규모 코드 마이그레이션 프로젝트는 언어적 차이를 넘어서는 근본적인 설계 및 실행상의 도전과제들을 수반합니다:
- 언어 패러다임 차이: C와 Java는 메모리 관리, 오류 처리, 프로그래밍 접근 방식에서 근본적으로 다른 철학을 가진 언어입니다. C는 개발자가 메모리를 직접 할당하고 해제하는 절차적 프로그래밍 방식을 사용하는 반면, Java는 가비지 컬렉터가 메모리를 자동으로 관리하는 객체 지향 환경을 제공합니다. AI가 기본적인 문법 변환은 효과적으로 수행할 수 있지만, 이러한 언어 간 패러다임 차이로 인한 변환 결과의 정확성과 적절성은 반드시 개발자가 검토해야 합니다.
- 아키텍처 복잡성: 레거시 시스템은 종종 여러 모듈이 복잡하게 얽혀있는 상호 의존성 구조를 가지고 있어 체계적인 분석과 계획이 필요합니다. 기존 코드베이스에서는 하나의 컴포넌트가 다수의 다른 모듈들과 밀접하게 연결되어 있는 경우가 많아, 개발자가 전체 의존성 구조를 파악하고 적절한 마이그레이션 순서를 결정해야 합니다. 일반적으로 의존성이 적은 모듈부터 시작하여 점진적으로 복잡한 모듈로 진행하는 전략을 사용합니다. AI는 모듈 간 관계 분석을 지원할 수 있지만, 마이그레이션의 우선순위와 전략적 방향성은 전문가의 판단이 필요합니다.
- 비즈니스 로직 유지: 마이그레이션 과정에서 핵심 비즈니스 로직이 정확하게 보존되도록 하려면 지속적인 개발자의 의견이 필요합니다. 범용 LLM을 활용하여 코드 마이그레이션을 시도할 경우 단순하고 잘 구조화된 코드에 대해서는 높은 성공률을 보이지만, 저희 실험에서는 700줄 정도까지의 파일에서 비교적 안정적인 결과를 얻을 수 있었습니다. 그러나 더 큰 규모이거나 복잡한 비즈니스 로직을 포함한 코드는 오류나 누락을 방지하기 위해 신중한 개발자 검토와 추가적인 수동 개선 작업이 필요한 경우가 많습니다.
- 일관성 없는 명명 및 구조: 마이그레이션 과정에서는 기존 코드의 명명 규칙과 구조를 회사 표준에 맞춰 일관되게 개선하고자 하는 경우가 많습니다. AI는 함수 이름 변환, C 스타일 오류 코드를 Java 예외로 바꾸기, 구조체를 클래스로 변환하는 등 기본적인 변환 작업은 잘 수행할 수 있습니다. 하지만 회사의 코딩 표준이나 명명 규칙에 맞춰 변환하려면 개발자가 명확한 가이드라인을 제공해야 하며, 이러한 기준 없이는 AI가 적절한 판단을 내리기 어렵습니다.
- 통합 복잡성: AI는 처리할 수 있는 코드 양에 한계가 있어 전체 시스템을 한번에 변환할 수 없고, 개별 파일 단위로 나누어 작업해야 합니다. 개별적으로 변환된 파일들을 다시 하나의 응집력 있는 시스템으로 통합하는 과정에서 여러 문제가 발생합니다. 원래 C 코드에서 일관되게 사용되던 변수명이나 함수명이 각각 다르게 변환되거나, 모듈 간의 인터페이스가 맞지 않는 경우가 생기므로, 개발자가 이를 조정하고 전체 시스템이 올바르게 동작하도록 통합 작업을 수행해야 합니다.
- 검증 체계 구축: 변환된 코드가 원본과 동일한 기능을 수행하는지 확인하려면 체계적인 검증이 필요합니다. 복잡한 비즈니스 로직에서는 미묘한 차이가 중요한 문제로 이어질 수 있어, 개발자가 자동화된 테스트와 코드 검토를 조합한 검증 프로세스를 설계하여 마이그레이션 정확성을 확보해야 합니다.
이러한 과제들을 해결하기 위해서는 AI의 자동화 능력과 개발자의 전문 지식을 효과적으로 결합한 체계적인 접근 방식이 필요합니다. AI는 반복적인 구문 변환과 기본적인 코드 변환 작업을 효율적으로 처리하고, 개발자는 아키텍처 설계, 비즈니스 로직 검증, 통합 조정, 품질 검증 등 판단이 필요한 핵심 영역에 집중하는 역할 분담이 성공적인 마이그레이션의 열쇠입니다. 결국 AI의 처리 속도와 정확성을 활용하되, 전략적 의사결정과 복잡한 문제 해결은 여전히 개발자가 주도해야 하는 협력 모델이 가장 효과적입니다.
다음 섹션에서는 이 에이전트 기반 코드 변환 솔루션의 실제 구현 과정을 단계별로 살펴보겠습니다. AWS 환경 설정부터 시작하여 각 에이전트의 구체적인 구현 방법, 그리고 실제 C 코드를 Java/Spring 애플리케이션으로 변환하는 전체 워크플로우를 자세히 다룰 예정입니다.
이 블로그 포스트에서 사용된 모든 소스 코드와 예제 파일은 GitHub 리포지토리에서 확인하실 수 있습니다.
솔루션 환경 설정
코드 변환 솔루션을 원활하게 활용하기 위해서는 사전 환경 설정이 필요합니다. 다음 구성요소들이 준비 되어 있는지 확인하십시오:
AWS 환경:
- Amazon Bedrock과 Amazon Nova Premier 모델 액세스에 대한 적절한 권한을 가진 AWS 계정
- 개발 및 테스트용 EC2 인스턴스(t3.medium 이상) 또는 로컬 머신의 개발 환경
개발 환경:
- boto3 SDK 및 Strands Agents가 설치된 Python 3.10+
- 적절한 자격 증명 및 리전으로 구성된 AWS CLI
- 레거시 코드베이스 및 변환된 코드의 버전 관리를 위한 Git
- C 및 Java 코드베이스를 모두 처리할 수 있는 텍스트 에디터 또는 IDE
소스 및 대상 코드베이스 요구사항:
- 구조화된 디렉토리 형식으로 구성된 C 소스 코드
- Java 11+ 및 Maven/Gradle 빌드 도구
- Spring Framework 5.x 또는 Spring Boot 2.x+ 의존성
솔루션 소개
이 솔루션은 Amazon Bedrock Converse API와 Amazon Nova Premier를 활용하여 체계적인 에이전트 워크플로우를 통해 레거시 C 코드를 현대적인 Java/Spring 프레임워크 코드로 변환합니다. 이 솔루션은 복잡한 마이그레이션 프로세스를 관리 가능한 단계로 분해하여 반복적인 개선과 토큰 제한 처리를 가능하게 합니다.
아키텍처 개요
이 코드 변환 솔루션은 각각 특화된 역할을 담당하는 5개의 핵심 에이전트로 구성되어 있습니다:
- 코드 분석 에이전트(Code Analysis Agent): C 코드 구조와 의존성을 분석합니다.
- 코드 변환 에이전트(Conversion Agent): C 코드를 Java/Spring 코드로 변환합니다.
- 데이터베이스 연동 코드 변환 에이전트(DBIO Conversion Agent): SQL문을 포함한 특수 목적의 데이터 베이스 연동 C 코드를 Java 환경에 맞게 변환합니다.
- 검증 에이전트(Validation Agent): 변환 완성도와 정확성을 검증합니다.
- 개선 에이전트(Refine Agent): 검증 에이전트의 피드백을 바탕으로 코드를 다시 작성합니다.
- 통합 에이전트(Integration Agent): 개별적으로 변환된 파일들을 결합합니다.
코드 변환 워크플로우
이 솔루션의 에이전트 워크플로우는 견고한 에이전트 오케스트레이션과 LLM 추론을 위해 Strands Agents 프레임워크와 Amazon Bedrock Converse API를 결합하여 구현 되었습니다. 아키텍처는 Strands Agents의 세션 관리 기능과 토큰 연속을 위한 사용자 정의 Bedrock Inference 처리를 결합한 하이브리드 접근 방식을 활용합니다.
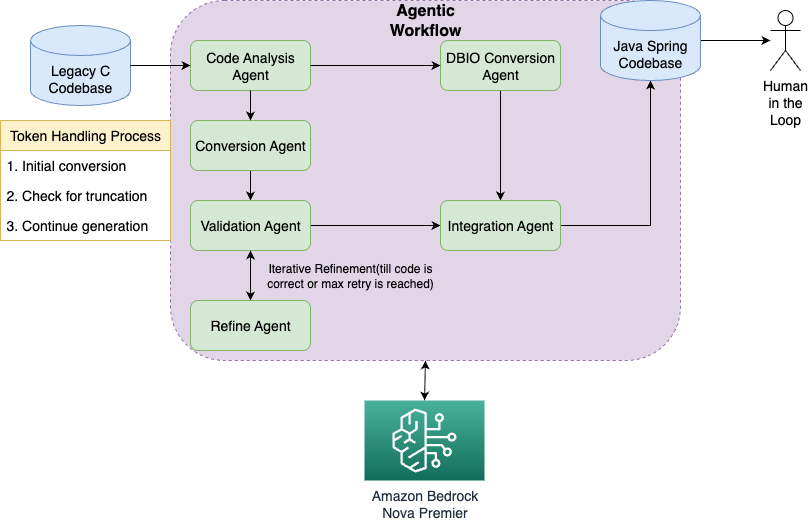
그림: 코드 변환을 위한 에이전트 워크플로우
주요 구성 요소:
- Strands Agents Framework (v1.1.0+): 에이전트 라이프사이클 관리, 세션 처리, 구조화된 에이전트 통신을 제공합니다
- Amazon Bedrock Converse API: Amazon Nova Premier 모델로 LLM 추론을 지원합니다.
- 사용자 정의 Bedrock Inference 클래스: 텍스트 프리필링과 응답 연속을 통해 토큰 제한을 처리합니다.
- Asyncio 기반 오케스트레이션: 동시 처리와 비차단 에이전트 실행을 가능하게 합니다.
주요 오케스트레이션 기능:
- 세션 지속성: 각 변환은 모든 에이전트 상호작용에 걸쳐 세션 상태를 유지
- 오류 복구: 우아한 성능 저하를 포함한 포괄적인 오류 처리
- 성능 추적: 처리 시간, 반복 횟수, 성공률에 대한 내장 메트릭 제공
- 토큰 제약 처리: 응답 스티칭을 통한 큰 파일의 원활한 처리
단계별 상세 워크플로우
1. 코드 분석
코드 분석 에이전트가 변환 요구사항을 이해하기 위해 입력 코드 분석을 수행합니다. C 코드베이스 구조를 검사하고, 의존성을 식별하며, 복잡성을 평가합니다. Bedrock Inference를 활용한 분석 시 Strands Agents를 세션 관리에 활용합니다. 최종적으로는 의존성 매핑 정보과 변환 권장사항이 포함된 JSON 구조의 분석 결과를 출력합니다.
2. 파일 분류 및 메타데이터 생성
복잡성 평가가 포함된 FileMetadata 데이터클래스를 다음과 같은 형태로 분류하여 생성합니다.
- 카테고리: 단순(0-300줄), 중간(300-700줄), 복잡(700줄 이상)
- 파일 유형: 표준 C 파일, 헤더 파일, 데이터 베이스 연동 파일 등
3. 개별 파일 변환
코드 변환 에이전트가 코드 분석 에이전트로부터 얻은 정보를 바탕으로 개별 파일에 대한 코드 마이그레이션을 수행합니다. 토큰 제한을 초과하는 큰 파일을 처리하기 위해 stitch_output() 메서드를 활용합니다.
4. 검증 및 피드백 루프
검증 에이전트가 변환 완성도와 정확석을 분석하고, 개선 에이전트는 검증 결과를 바탕으로 반복적인 개선을 적용합니다. 만족스러운 결과를 제공하기 위해 최대 5회 피드백을 반복하고 불필요시 조기 종영하는 반복 제어 기능을 제공합니다. Strands Agents 프레임워크를 활용하여 반복 전반에 걸쳐 대화 컨텍스트를 유지하게 하여 세션 지속성을 보장합니다.
5. 통합 및 최종화
통합 에이전트가 개별적으로 변환된 파일을 통합 합니다. 이때 변수 명명을 표준화 하고 코드간의 의존성을 보장합니다. 이를 통해 일관성 있는 Java/Spring 애플리케이션 구조를 생성합니다.
6. 특수목적의 코드 변환 (데이터 베이스 연동 코드)
데이터베이스 연동 코드는 SQL 문법, 파라미터 바인딩, 결과 매핑 등 고유한 변환 패턴을 가지고 있어 일반 코드 변환과는 다른 전문적 접근이 필요합니다. 레거시 C 코드의 데이터베이스 연동 부분을 Java 환경으로 마이그레이션할 때는 JPA, MyBatis, JDBC Template 등 다양한 옵션이 있습니다. 이 솔루션에서는 MyBatis로 전환하는 예시를 보여줍니다. MyBatis는 기존 C 코드에서 사용하던 직접적인 SQL 작성 방식과 가장 유사하여 마이그레이션 복잡성을 줄이고 기존 비즈니스 로직을 그대로 유지할 수 있기 때문입니다. 이 단계에서는 DBIO에이전트가 SQL를 포함한 C 소스 코드를 MyBatis XML 매퍼 파일로 변환합니다.
이러한 체계적인 에이전트 기반 접근 방식을 통해 다양한 규모와 복잡성을 가진 C 코드베이스에 대해 안정적이고 확장 가능한 마이그레이션을 제공할 수 있습니다.
에이전트 기반 변환 프로세스
이 솔루션의 핵심은 AWS Strands Agents 프레임워크를 사용하여 구현된 정교한 멀티 에이전트 시스템에 있으며, 각 에이전트는 코드 변환 프로세스의 특정 측면을 전문으로 합니다. 이 분산 접근 방식은 다양한 코드 구조와 복잡성을 처리할 수 있는 유연성을 유지하면서 철저한 분석, 정확한 변환, 포괄적인 검증을 보장합니다.
Strands 프레임워크 통합
각 에이전트는 BaseStrandsConversionAgent 클래스를 확장하며, 이는 Strands Agents 세션 관리와 사용자 정의 BedrockInference 기능을 결합한 하이브리드 아키텍처를 제공합니다:
class BaseStrandsConversionAgent(ABC):
def __init__(self, name: str, bedrock_inference, system_prompt: str):
self.name = name
self.bedrock = bedrock_inference # 토큰 처리를 위한 사용자 정의 BedrockInference
self.system_prompt = system_prompt
# 세션 관리를 위한 strands agents 생성
self.strands_agent = Agent(name=name, system_prompt=system_prompt)
async def execute_async(self, context: ConversionContext) -> Dict[str, Any]:
# 각 전문화된 에이전트에 의해 구현됨
pass
그럼 여기에서는 각 에이전트의 구체적인 역할과 작동 방식을 이해하기 위해 실제 프롬프트 템플릿을 통해 어떤 작업을 수행하는지 살펴보겠습니다.
1. 코드 분석 에이전트
코드 분석 에이전트는 C 코드베이스의 구조를 검사하여 파일 간의 의존성을 식별하고 최적의 변환 전략을 결정합니다. 이 에이전트는 어떤 파일을 먼저 변환할지 우선순위를 정하고 잠재적인 과제를 식별하는 데 도움을 줍니다.
코드 분석 에이전트를 위한 프롬프트 템플릿:
당신은 레거시 C 코드베이스와 현대적인 Java/Spring 아키텍처에 대한 전문 지식을 가진 코드 분석 에이전트입니다.
<c_codebase>
{c_code}
</c_codebase>
## 작업
제공된 C 코드를 분석하여 마이그레이션을 준비하는 것이 당신의 작업입니다.
포괄적인 분석을 수행하고 다음을 제공하십시오:
## 지침
1. 의존성 분석:
- 모든 파일 의존성 식별 (어떤 파일이 다른 파일을 포함하거나 참조하는지)
- 파일 간 함수 호출 매핑
- 공유 데이터 구조 및 전역 변수 감지
2. 복잡성 평가:
- 각 파일을 단순(0-300줄), 중간(300-700줄), 또는 복잡(700줄 이상)으로 분류
- 복잡한 제어 흐름, 포인터 조작, 또는 메모리 관리가 있는 파일 식별
- 플랫폼별 또는 하드웨어 종속적인 코드 표시
3. 변환 계획:
- 변환 순서 권장 (어떤 파일을 먼저 변환할지)
- 큰 파일에 대한 논리적 분할 지점 제안
- 변환 중 표준화할 수 있는 공통 패턴 식별
4. 위험 평가:
- 잠재적인 변환 과제 강조 (예: 포인터 산술, 비트 연산)
- 특별한 주의가 필요한 비즈니스 크리티컬 섹션 식별
- 문서화되지 않은 가정이나 동작 주목
5. 아키텍처 권장사항:
- 각 C 모듈에 적합한 Java/Spring 구성 요소 제안
- DTO 구조 및 서비스 조직 권장
- 지속성 프레임워크를 사용한 데이터베이스 액세스 전략 제안
응답을 이러한 섹션들이 포함된 구조화된 JSON 문서로 형식화하십시오.
2. 변환 에이전트
변환 에이전트는 C 코드를 Java/Spring 코드로 실제 변환을 처리합니다. 이 에이전트는 C와 Java/Spring 프레임워크 모두에 대한 전문 지식을 가진 시니어 소프트웨어 개발자의 역할을 맡습니다.
변환 에이전트를 위한 프롬프트 템플릿:
당신은 C와 Java Spring 프레임워크 모두에서 15년 이상의 경험을 가진 시니어 소프트웨어 개발자입니다.
<c_file>
{c_code}
</c_file>
## 작업
레거시 C 코드를 정확하고 완전하게 현대적인 Java Spring 코드로 변환하는 것이 당신의 작업입니다.
## 변환 가이드라인:
1. 코드 구조:
- 적절한 Java 클래스 생성 (Service, DTO, Mapper 인터페이스)
- Java 규칙과 충돌하지 않는 한 원래 함수 및 변수 이름 보존
- Spring 어노테이션 적절히 사용 (@Service, @Repository 등)
- 기능에 따른 적절한 패키지 구조 구현
2. Java 모범 사례:
- 보일러플레이트를 줄이기 위해 Lombok 어노테이션 사용 (@Data, @Slf4j, @RequiredArgsConstructor)
- 오류 코드 대신 적절한 예외 처리 구현
- 포인터 연산을 적절한 Java 구조로 대체
- 적절한 경우 C 스타일 배열을 Java 컬렉션으로 변환
3. Spring 프레임워크 통합:
- 전역 변수 대신 의존성 주입 사용
- 데이터베이스 작업을 위한 지속성 프레임워크 매퍼 구현
- 직접 SQL 호출을 매퍼 인터페이스로 대체
- Spring의 트랜잭션 관리 사용
4. 특정 변환:
- PFM_TRY/PFM_CATCH를 Java try-catch 블록으로 대체
- mpfmdbio 호출을 지속성 프레임워크 매퍼 메서드 호출로 변환
- mpfm_dlcall을 적절한 Service bean 주입으로 대체
- NGMHEADER 참조를 input.getHeaderVo() 호출로 변환
- PRINT_ 및 PFM_DBG 매크로를 SLF4J 로깅으로 대체
- ngmf_ 메서드를 CommonAPI.ngmf 메서드 호출로 변환
5. 데이터 처리:
- 입력 및 출력 구조를 위한 별도의 DTO 클래스 생성
- 적절한 Java 데이터 타입 사용 (char 배열 대신 String 등)
- 적절한 null 처리 및 검증 구현
- 수동 메모리 관리 코드 제거
## 출력 형식:
- 각 Java 파일 상단에 파일명 포함: #filename: [filename].java
- <java></java> 태그 내에 실행 가능한 Java 코드 배치
- 적절한 헤더로 여러 출력 파일을 명확하게 구성
원래 C 코드의 모든 기능을 완전히 구현하는 완전하고 프로덕션 준비된 Java 코드를 생성하십시오.
3. 검증 에이전트
검증 에이전트는 변환된 코드를 검토하여 누락되거나 잘못 변환된 구성 요소를 식별합니다. 이 에이전트는 후속 변환 반복에서 사용되는 상세한 피드백을 제공합니다.
검증 에이전트를 위한 프롬프트 템플릿:
당신은 C에서 Java/Spring 마이그레이션 검증을 전문으로 하는 코드 검증 에이전트입니다.
원본 C 코드:
<c_code>
{c_code}
</c_code>
변환된 Java 코드:
<java_code>
{java_code}
</java_code>
## 작업
변환 품질을 철저히 분석하고 문제나 누락을 식별하는 것이 당신의 작업입니다.
다음 측면에 중점을 두고 포괄적인 검증을 수행하십시오:
## 지침
1. 완성도 확인:
- C 코드의 모든 함수가 Java에서 구현되었는지 확인
- 모든 변수와 데이터 구조가 적절히 변환되었는지 확인
- 모든 논리적 분기와 조건이 보존되었는지 확인
- 모든 오류 처리 경로가 구현되었는지 확인
2. 정확성 평가:
- 변환에서 논리적 오류 식별
- C별 구조(포인터, 구조체 등)의 적절한 변환 확인
- 메모리 관리 패턴의 올바른 구현 확인
- 문자열 연산 및 바이트 조작의 적절한 처리 검증
3. Spring 프레임워크 준수:
- Spring 어노테이션 및 패턴의 적절한 사용 확인
- 의존성 주입의 적절한 구현 확인
- 지속성 프레임워크 매퍼의 올바른 사용 검증
- 적절한 서비스 구조 및 조직 확인
4. 코드 품질 평가:
- Java 코드 품질 및 모범 사례 준수 평가
- 적절한 예외 처리 확인
- 적절한 로깅 구현 검증
- 전반적인 코드 조직 및 가독성 평가
## 출력 형식
다음 필드가 포함된 구조화된 JSON으로 분석을 제공하십시오:
- "complete": 변환이 완료되었는지를 나타내는 불린값
- "missing_elements": 누락된 특정 함수, 변수, 또는 논리 블록의 배열
- "incorrect_transformations": 잘못 변환된 요소들의 배열
- "spring_framework_issues": Spring별 구현 문제들의 배열
- "quality_concerns": 코드 품질 문제들의 배열
- "recommendations": 개선을 위한 구체적이고 실행 가능한 권장사항
당신의 피드백이 변환 프로세스의 다음 반복에 직접적으로 정보를 제공할 것이므로 철저하고 정확하게 분석하십시오.
4. 개선 에이전트와 피드백 루프 구현
피드백 루프는 변환된 코드의 반복적인 개선을 가능하게 하는 중요한 구성 요소입니다. 이 프로세스는 다음을 포함합니다:
- 변환 에이전트에 의한 초기 변환
- 검증 에이전트에 의한 검증
- 개선 에이전트에 의한 피드백 통합
- 만족스러운 결과가 달성될 때까지 반복
코드 개선을 위한 프롬프트 템플릿:
당신은 C에서 Java/Spring 마이그레이션을 전문으로 하는 시니어 소프트웨어 개발자입니다.
원본 C 코드:
<c_code>
{c_code}
</c_code>
이전 Java 변환:
<previous_java>
{previous_java_code}
</previous_java>
검증 피드백:
<validation_feedback>
{validation_feedback}
</validation_feedback>
## 작업
이전에 C 코드를 Java로 변환했지만, 검증 프로세스에서 해결해야 할 문제들이 식별되었습니다. 식별된 모든 문제를 해결하여 변환을 개선하는 것이 당신의 작업입니다. 완전하고 정확하며 고품질의 Java/Spring 구현을 생성하는 것이 목표입니다.
## 지침
1. 누락된 요소 해결:
- 누락된 것으로 식별된 함수, 변수, 또는 논리 블록 구현
- 원본 코드의 모든 제어 흐름 경로가 보존되도록 보장
- 누락된 오류 처리나 엣지 케이스 추가
2. 변환 수정:
- 잘못 변환된 코드 구조 수정
- 변환의 논리적 오류 수정
- Java에서 C별 패턴을 적절히 구현
3. Spring 구현 개선:
- Spring 어노테이션이나 패턴의 문제 수정
- 적절한 의존성 주입 및 서비스 구조 보장
- 필요한 경우 지속성 프레임워크 매퍼 구현 수정
4. 코드 품질 향상:
- 지시된 곳에서 예외 처리 개선
- 로깅 구현 향상
- 코드 조직이나 가독성 문제 해결
5. 일관성 유지:
- 코드 전반에 걸쳐 명명 규칙이 일관되도록 보장
- 유사한 작업에 대해 일관된 패턴 유지
- 적절한 경우 원본 코드의 구조 보존
## 출력 형식
적절한 파일 헤더와 함께 개선된 Java 코드를 <java></java> 태그 내에 출력하십시오. 원본 C 코드의 어떤 기능도 생략하지 마십시오.
5. 통합 에이전트
통합 에이전트는 각각 별도로 변환된 Java 파일들을 통합하여 완성된 애플리케이션을 구성합니다. 개별 변환 과정에서 발생한 명명 규칙의 차이를 조정하고, 각 모듈이 서로 정확하게 연동될 수 있도록 의존성을 정리합니다.
통합 에이전트를 위한 프롬프트 템플릿:
당신은 개별적으로 변환된 Java 파일들을 응집력 있는 Spring 애플리케이션으로 결합하는 것을 전문으로 하는 통합 에이전트입니다.
변환된 Java 파일들:
<converted_files>
{converted_java_files}
</converted_files>
원본 파일 관계:
<relationships>
{file_relationships}
</relationships>
## 작업
C에서 변환된 여러 Java 파일들을 통합하여 함께 적절히 작동하도록 하는 것이 당신의 작업입니다.
다음 통합 작업을 수행하십시오:
## 지침
1. 의존성 해결:
- 서비스와 구성 요소 간의 의존성을 식별하고 해결
- 적절한 자동 연결 및 의존성 주입 보장
- 서비스 메서드 시그니처가 파일 간 사용과 일치하는지 확인
2. 명명 일관성:
- 파일 간에 일관되어야 하는 변수 및 메서드 이름 표준화
- 명명 충돌이나 불일치 해결
- 관련 클래스 간에 DTO 필드 이름이 일치하도록 보장
3. 패키지 조직:
- 클래스를 적절한 패키지 구조로 조직
- 관련 기능을 함께 그룹화
- 모든 파일에 걸쳐 적절한 import 문 보장
4. 서비스 구성:
- 적절한 서비스 구성 패턴 구현
- 서비스들이 서로 올바르게 상호작용하도록 보장
- 데이터가 구성 요소 간에 올바르게 흐르는지 확인
5. 공통 구성 요소:
- 공통 유틸리티 함수를 추출하고 표준화
- 서비스 간에 일관된 오류 처리 보장
- 로깅 패턴 표준화
6. 구성:
- 필요한 Spring 구성 클래스 생성
- 적절한 빈 정의 설정
- 필요한 속성이나 설정 구성
다음과 함께 적절히 조직된 파일 세트로 통합된 Java 코드를 출력하십시오:
- 적절한 패키지 선언
- 올바른 import 문
- 적절한 Spring 어노테이션
- 명확한 파일 헤더 (#filename: [filename].java)
각 파일의 코드를 <java></java> 태그 내에 배치하십시오. 통합된 애플리케이션이 응집력 있는 구조를 제공하면서 개별 구성 요소의 모든 기능을 유지하도록 보장하십시오.
6. 데이터베이스 연동 코드 변환 에이전트
이 에이전트는 C 코드에서 사용하던 SQL 데이터베이스 연동 부분을 Java Spring 환경에 맞는 XML 매퍼 파일로 변환합니다.
데이터베이스 연동 코드 변환 에이전트를 위한 프롬프트 템플릿:
당신은 C 기반 SQL DBIO 코드를 Spring 애플리케이션용 지속성 프레임워크 XML 매핑으로 변환하는 전문 지식을 가진 데이터베이스 통합 전문가입니다.
SQL DBIO C 소스 코드:
<sql_dbio>
{sql_dbio_code}
</sql_dbio>
## 작업
제공된 SQL DBIO C 코드를 적절히 구조화된 지속성 프레임워크 XML 파일로 변환하는 것이 당신의 작업입니다.
다음 가이드라인에 따라 변환을 수행하십시오:
## 지침
1. XML 구조:
- 적절히 형식화된 지속성 프레임워크 매퍼 XML 파일 생성
- Java 매퍼 인터페이스와 일치하는 적절한 네임스페이스 포함
- 쿼리에 대해 올바른 resultType 또는 resultMap 속성 설정
- 적절한 지속성 프레임워크 XML 구조 및 구문 사용
2. SQL 변환:
- 원본 코드의 정확한 SQL 로직 보존
- C별 SQL 매개변수 처리를 지속성 프레임워크 매개변수 마커로 변환
- 모든 WHERE 절, JOIN 조건, 기타 SQL 로직 유지
- SQL 기능을 설명하는 주석 보존
3. 매개변수 처리:
- C 변수 바인딩을 지속성 프레임워크 매개변수 참조(#{param})로 변환
- 적절한 지속성 프레임워크 기술을 사용하여 복잡한 매개변수 처리
- 매개변수 타입이 Java 동등물과 일치하도록 보장 (char[] 대신 String 등)
4. 결과 매핑:
- 복잡한 결과 구조를 위한 적절한 resultMap 요소 생성
- 컬럼 이름을 Java DTO 속성 이름에 매핑
- 데이터베이스와 Java 타입 간에 필요한 타입 변환 처리
5. 동적 SQL:
- 조건부 SQL 생성을 지속성 프레임워크 동적 SQL 요소로 변환
- 적절한 경우 <if>, <choose>, <where>, 기타 동적 요소 사용
- 원본 코드와 동일한 조건부 로직 유지
6. 조직:
- 관련 쿼리를 함께 그룹화
- 각 쿼리의 목적을 설명하는 명확한 주석 포함
- 매퍼 조직을 위한 지속성 프레임워크 모범 사례 따르기
## 출력 형식
변환된 지속성 프레임워크 XML을 <xml></xml> 태그 내에 출력하십시오. 상단에 파일명 주석 포함: #filename: [EntityName]Mapper.xml
XML이 잘 형성되고, 적절히 들여쓰기되며, Spring 애플리케이션용 지속성 프레임워크 규칙을 따르도록 보장하십시오.
토큰 제한 처리
LLL AI Agent가 한 번에 처리할 수 있는 텍스트 양에는 한계가 있어, 큰 파일을 변환할 때 중간에 작업이 중단되는 문제가 발생합니다. 이를 해결하기 위해 중단된 지점에서 자동으로 작업을 이어갈 수 있는 기술을 구현했습니다. 이 방식을 통해 대용량 코드 파일도 끊김 없이 완전한 변환이 가능합니다.
기술적 구현
연속 지원이 포함된 BedrockInference 클래스:
class BedrockInference:
def __init__(self, region_name: str = "us-east-1", model_id: str = "us.amazon.nova-premier-v1:0"):
self.config = Config(read_timeout=300)
self.client = boto3.client("bedrock-runtime", config=self.config, region_name=region_name)
self.model_id = model_id
self.continue_prompt = {
"role": "user",
"content": [{"text": "중단된 지점에서 코드 변환을 계속하십시오."}]
}
def run_converse_inference_with_continuation(self, prompt: str, system_prompt: str) -> List[str]:
"""큰 출력에 대한 연속 처리가 포함된 추론 실행"""
ans_list = []
messages = [{"role": "user", "content": [{"text": prompt}]}]
response, stop = self.generate_conversation([{'text': system_prompt}], messages)
ans = response['output']['message']['content'][0]['text']
ans_list.append(ans)
while stop == "max_tokens":
logger.info("응답이 잘렸습니다. 생성을 계속합니다...")
messages.append(response['output']['message'])
messages.append(self.continue_prompt)
# 연속 컨텍스트를 위해 마지막 몇 줄 추출
sec_last_line = '\n'.join(ans.rsplit('\n', 3)[1:-1]).strip()
messages.append({"role": "assistant", "content": [{"text": sec_last_line}]})
response, stop = self.generate_conversation([{'text': system_prompt}], messages)
ans = response['output']['message']['content'][0]['text']
del messages[-1] # 프리필 메시지 제거
ans_list.append(ans)
return ans_list
연속 전략 세부사항
1. 응답 모니터링:
- 시스템이 Bedrock 응답의 stopReason 필드를 모니터링합니다.
- stopReason이 “max_tokens”와 같을 때 연속이 자동으로 트리거됩니다.
- 이는 토큰 제한으로 인해 코드 생성이 손실을 방지합니다.
2. 컨텍스트 보존:
- 생성된 코드의 마지막 몇 줄을 연속 컨텍스트로 추출합니다.
- 텍스트 프리필링을 사용하여 코드 구조와 형식을 유지합니다.
- 연속 전반에 걸쳐 변수 이름, 함수 시그니처, 코드 패턴을 보존합니다.
3. 응답 연결하기:
def stitch_output(self, prompt: str, system_prompt: str, tag: str = "java") -> str:
"""여러 응답을 연결하고 지정된 태그 내의 내용을 추출"""
ans_list = self.run_converse_inference_with_continuation(prompt, system_prompt)
if len(ans_list) == 1:
final_ans = ans_list[0]
else:
final_ans = ans_list[0]
for i in range(1, len(ans_list)):
# 겹치는 부분을 제거하여 응답을 원활하게 결합
final_ans = final_ans.rsplit('\n', 1)[0] + ans_list[i]
# 지정된 태그 내의 내용 추출 (java, xml 등)
if f'<{tag}>' in final_ans and f'</{tag}>' in final_ans:
final_ans = final_ans.split(f'<{tag}>')[-1].split(f'</{tag}>')[0].strip()
return final_ans
변환 품질 최적화를 위한 권장 사항
실험을 통해 변환 품질에 상당한 영향을 미치는 여러 요인을 식별했습니다:
- 파일 크기 관리: 약 300줄 이상의 코드가 있는 파일은 변환 전에 더 작은 논리적 단위로 분해하는 것이 유리합니다.
- 집중된 변환: 다른 파일 유형(C, 헤더, DBIO)을 별도로 변환하면 각 파일 유형이 고유한 변환 패턴을 가지므로 더 나은 결과를 얻을 수 있습니다. 변환 중에 C 함수는 클래스 내의 Java 메서드로 변환되고, C 구조체는 Java 클래스가 됩니다. 그러나 파일이 교차 파일 컨텍스트 없이 개별적으로 변환되므로, 최적의 객체 지향 설계를 달성하려면 관련 기능을 통합하고, 적절한 클래스 계층을 설정하며, 변환된 코드베이스 전반에 걸쳐 적절한 캡슐화를 보장하기 위한 인간의 개입이 필요할 수 있습니다.
- 반복적 개선: 여러 피드백 루프(4-5회 반복)가 더 포괄적인 변환을 생성합니다.
- 역할 할당: 모델에 특정 역할(시니어 소프트웨어 개발자)을 할당하면 출력 품질이 향상됩니다.
- 상세한 지침: 공통 패턴에 대한 특정 변환 규칙을 제공하면 일관성이 향상됩니다.
적용 전제 조건
이 솔루션이 제안하는 마이그레이션 전략은 다음과 같은 주요 가정을 합니다:
- 코드 품질: 레거시 C 코드가 식별 가능한 구조를 가진 합리적인 코딩 관행을 따릅니다. 난독화되거나 구조가 좋지 않은 코드는 자동 변환 전에 전처리가 필요할 수 있습니다.
- 범위 제한: 이 접근 방식은 저수준 시스템 코드보다는 비즈니스 로직 변환을 대상으로 합니다. 하드웨어 상호작용이나 플랫폼별 기능이 있는 C 코드는 수동 개입이 필요할 수 있습니다.
- 테스트 커버리지: 마이그레이션 후 기능적 동등성을 검증하기 위해 레거시 애플리케이션에 대한 포괄적인 테스트 케이스가 존재합니다. 적절한 테스트 없이는 추가 검증 단계가 필요합니다.
- 도메인 지식: 에이전트 워크플로우가 C와 Java 모두에 대한 전문 지식의 필요성을 줄이지만, 중요한 비즈니스 로직의 보존을 검증하기 위해 비즈니스 도메인을 이해하는 주제 전문가에 대한 액세스가 필요합니다.
- 단계적 마이그레이션: 이 접근 방식은 전체 프로젝트 수준 마이그레이션보다는 구성 요소를 개별적으로 변환하고 검증할 수 있는 점진적 마이그레이션 전략이 허용 가능하다고 가정합니다.
결과 및 성능
Amazon Nova Premier 기반 마이그레이션 접근 방식의 효과를 평가하기 위해, 일반적인 고객 시나리오를 나타내는 엔터프라이즈급 코드베이스에서 성능을 측정했습니다. 우리의 평가는 두 가지 성공 요인 구조적 완성도 (모든 비즈니스 로직과 함수의 보존)와 프레임워크 준수 (Spring Boot 모범 사례와 규칙 준수) 에 중점을 두었습니다.
코드베이스 복잡성별 마이그레이션 정확도
에이전트 워크플로우는 파일 복잡성에 따라 다양한 효과를 보여주었으며, 모든 결과는 개발자에 의해 검증되었습니다.
| 파일 사이즈 분류 | 구조적 완성도 | 프레임 워크 준수 | 평균 처리 시간 |
|---|---|---|---|
| Small (0-300 lines) | 93% | 100% | 30-40 seconds |
| Medium (300-700 lines) | 81%* | 91%* | ~7 mins |
| Large (700+ lines) | 62%* | 84%* | ~21 mins |
* 여러 검증 사이클 적용 후
실험 결과를 통해 확인한 바에 따르면, 이 솔루션을 활용한 코드 마이그레이션 방식은 기존의 수동 변환 작업 대비 상당한 시간 단축 효과를 기대할 수 있습니다. 특히 반복적이고 패턴화된 코드 변환 작업에서 높은 효율성을 보여주었으며, 개발자들이 복잡한 비즈니스 로직 검증과 아키텍처 설계 등 보다 전략적인 업무에 집중할 수 있도록 지원합니다.
엔터프라이즈 도입을 위한 주요 통찰
이러한 결과는 중요한 패턴을 보여줍니다: 에이전트 접근 방식은 대부분의 마이그레이션 작업(소형에서 중형 파일)을 처리하는 데 뛰어나면서도 인간 감독이 필요한 복잡한 파일에 대해서도 상당한 가치를 제공합니다. 이는 AI가 일상적인 변환을 처리하고 개발자가 통합 및 아키텍처 결정에 집중하는 하이브리드 접근 방식을 만듭니다.
결론
우리의 솔루션은 Amazon Bedrock Converse API와 Amazon Nova Premier를 에이전트 워크플로우 내에서 구현할 때 레거시 C 코드를 현대적인 Java/Spring 프레임워크 코드로 효과적으로 변환할 수 있음을 보여줍니다. 이 접근 방식은 복잡한 코드 구조를 처리하고, 토큰 제한을 관리하며, 최소한의 인간 개입으로 고품질 변환을 생성합니다.
성공의 핵심은 변환 프로세스를 전문화된 에이전트 역할로 분해하고, 견고한 피드백 루프를 구현하며, 연속 기술을 통해 토큰 제한을 처리하는 것에 있습니다. 이 접근 방식은 마이그레이션 프로세스를 가속화할 뿐만 아니라 코드 품질을 향상시키고 오류 가능성을 줄일 수 있을 것으로 기대합니다.