이 블로그는 Optimize and troubleshoot database performance in Amazon Aurora PostgreSQL by analyzing execution plans using CloudWatch Database Insights를 한국어로 번역 및 편집한 글입니다.
Amazon Web Services(AWS)는 Amazon Relational Database Service(Amazon RDS) 및 Amazon Aurora 데이터베이스의 성능과 이벤트에 대한 가시성을 높이기 위한 포괄적인 모니터링 도구들을 제공합니다. 이 게시물에서는 Amazon CloudWatch Database Insights를 사용하여, Aurora PostgreSQL 클러스터에서 SQL 실행 계획을 분석하여 문제를 해결하고 SQL 쿼리 성능을 최적화하는 방법을 보여줍니다.
PostgreSQL 쿼리 옵티마이저와 쿼리 액세스 플랜
PostgreSQL 쿼리 옵티마이저는 데이터베이스 엔진의 핵심 구성 요소로, SQL 쿼리를 실행하는 가장 효율적인 방법을 결정하는 역할을 합니다. 쿼리가 제출되면 PostgreSQL은 이를 직접 실행하지 않고, 여러 가능한 실행 전략을 생성한 후 비용 추정을 기반으로 최적의 전략을 선택합니다.
쿼리 실행 계획(Query Access Plan)은 옵티마이저가 선택한 단계별 실행 전략입니다. 실행 계획에는 PostgreSQL이 데이터를 검색하고 처리하는 방법이 상세히 기술되어 있으며, 순차 스캔(Sequential Scan), 인덱스 스캔(Index Scan), 조인(Join), 정렬(Sorting) 작업과 같은 다양한 기법을 사용합니다. 실행 경로를 이해하기 위해 여러 옵션들과 함께 EXPLAIN 명령어를 사용하여 쿼리 플랜을 분석할 수 있습니다.
개발자와 데이터베이스 관리자가 데이터베이스 성능을 최적화하고 리소스 사용을 효과적으로 최적화하기 위해서는, PostgreSQL 쿼리 옵티마이저와 쿼리 액세스 플랜을 이해하는 것이 중요합니다. 자세한 내용은 PostgreSQL이 쿼리를 처리하는 방법 및 분석 방법을 참조합니다.
솔루션 개요
2024년 12월, AWS는 Aurora(PostgreSQL 및 MySQL)와 PostgreSQL, MySQL, MariaDB, SQL Server, Oracle을 포함한 Amazon RDS 엔진을 지원하는 포괄적인 데이터베이스 모니터링 솔루션인 CloudWatch Database Insights를 출시했습니다. 이 가시성(observability) 도구는 DevOps 엔지니어, 개발자 및 DBA가 데이터베이스 성능 문제를 신속하게 식별하고 해결할 수 있게 하기 위해 설계되었습니다. CloudWatch Database Insights는 데이터베이스 플릿 전반에 걸친 통합된 뷰를 제공함으로써 트러블슈팅 워크플로우를 간소화하고 운영 효율성을 향상시킵니다.
CloudWatch Database Insights에는 Advanced 모드와 Standard 모드가 있습니다. Aurora PostgreSQL 실행 계획 분석 도구는 고급 모드에서만 사용 가능합니다. 다음 섹션에서는 Aurora PostgreSQL 클러스터에서 SQL 실행 계획 분석 기능을 활성화하는 방법을 설명합니다. 또한 실행 계획 변경으로 인한 쿼리 성능 문제를 해결하는 방법과 실행 계획을 기반으로 쿼리 성능을 최적화하는 방법을 설명하겠습니다.
이 게시글에서는 고객 정보, 제품 카탈로그, 주문 세부 정보, 주문 내역을 포함하는 일반적인 전자상거래(e-commerce) 애플리케이션 스키마를 사용합니다. 이러한 요소들은 각각 고객(customers), 제품(products), 주문(orders), 주문 내역(order_items) 테이블로 표현되며, 이를 통해 온라인 리테일 데이터베이스가 구성됩니다.
다음 섹션에서는 CloudWatch Database Insights를 통해 Aurora PostgreSQL 호환 에디션의 SQL 실행 계획을 분석하는 방법을 설명하겠습니다.
사전 조건
지금부터 이 게시글을 따라하려면, 추가 구성이 필요합니다. 자세한 내용은 CloudWatch Database Insights를 사용한 실행 계획 분석의 사전 조건을 참조합니다.
SQL 실행 계획 분석
이 애플리케이션에서 실행된 일반적인 쿼리 예시와 CloudWatch Database Insights를 통해 실행 계획을 분석하는 방법을 살펴보겠습니다.
CloudWatch 콘솔을 통해 CloudWatch Database Insights에 접속하면서 시작하겠습니다. Infrastructure Monitoring 하위의 Database Insights를 클릭하여 데이터베이스 보기(Database Views)로 이동한 후, Aurora PostgreSQL DB 인스턴스를 찾아 상위 SQL(Top SQL) 탭에서 성능 지표들을 확인합니다.
상위 SQL 표에 있는 계획 수(Plans Count) 열은 각 다이제스트 쿼리에 대해 수집된 계획의 수를 나타냅니다. 필요한 경우 설정 아이콘을 선택하여 상위 SQL 표의 열 표시 및 정렬을 사용자 정의할 수 있습니다.
다음으로 전자상거래 애플리케이션에서 실행된 특정 SQL 문에 집중하겠습니다. 다이제스트 쿼리를 선택하여 SQL 텍스트(SQL text) 탭에 표시된 세부 정보를 통해, 실행 중인 정확한 SQL 문을 확인할 수 있습니다. 실행 계획(Plans) 탭에서는 쿼리 실행 계획에 대한 상세한 보기를 제공합니다.
비교 분석을 위해 다음 스크린샷과 같이 최대 두 개의 실행 계획을 동시에 선택할 수 있습니다.
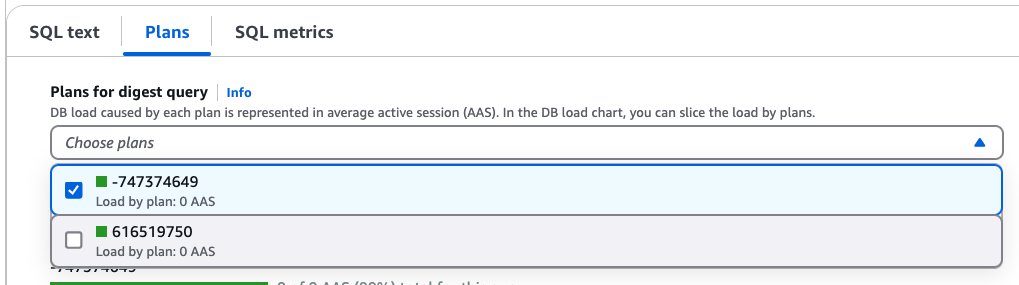
두 실행 방식을 함께 비교해보면 중요한 차이점을 확인할 수 있습니다. 한 실행 계획은 순차 스캔 방식을 사용한 반면, 다른 실행 계획은 인덱스 스캔을 활용했다는 것입니다. 접근 경로 선택에 대한 차이점을 확인함으로써 쿼리 성능 변동과 자원 활용 패턴에 대해 귀중한 통찰력을 얻을 수 있습니다.

다음은 위 스크린샷에서 확인된 실행 계획의 세부 사항입니다.
첫 번째 실행 계획 -74374649:
Gather (cost=1000.00..266914.09 rows=95345 width=126) (actual time=0.264..307.518 rows=100799 loops=1)
Workers Planned: 2
Workers Launched: 2
-> Parallel Seq Scan on person (cost=0.00..256379.59 rows=39727 width=126) (actual time=0.023..367.948 rows=33600 loops=3)
Filter: (age = 40)
Rows Removed by Filter: 3299734
두 번째 실행 계획 616519750:
Gather (cost=3904.96..220491.70 rows=105342 width=126) (actual time=26.699..158.131 rows=100799 loops=1)
Workers Planned: 2
Workers Launched: 2
-> Parallel Bitmap Heap Scan on person (cost=2904.96..208957.50 rows=43892 width=126) (actual time=21.423..209.867 rows=33600 loops=3)
Recheck Cond: (age = 40)
Rows Removed by Index Recheck: 534444
Heap Blocks: exact=6437 lossy=4705
-> Bitmap Index Scan on idx_person_age_date_active (cost=0.00..2878.62 rows=105342 width=0) (actual time=17.911..17.911 rows=100799 loops=1)
Index Cond: (age = 40)
첫 번째 실행 계획은 순차 스캔을 사용해 PostgreSQL 엔진이 ‘person’ 테이블 전체를 읽도록 강제합니다. 반면 두 번째 실행 계획은 더 효율적인 인덱스 스캔을 사용합니다. 두 번째 계획은 풀 테이블 스캔 대신 인덱스를 활용해 실행 시간을 단축함으로써 더 우수한 성능을 보입니다. CloudWatch Database Insights에서 실행 계획 차이를 분석함으로써 쿼리 성능 병목 현상을 효과적으로 식별하고 최적화할 수 있습니다.
성능 저하 문제 해결을 위한 실행 계획 비교
DBA와 DBE는 SQL 쿼리의 성능 저하 문제를 조사할 때 종종 쿼리 실행 계획 분석에 의존하며, 삭제된 인덱스, 비효율적인 조인 전략, 최적화되지 않은 쿼리 패턴과 같이 성능에 영향을 미칠 수 있는 실행 동작의 변화를 찾습니다. 하지만 서로 다른 시간대에 걸쳐 실행된 SQL 쿼리의 실행 계획을 수동으로 비교하려면 복잡하고 중첩된 실행 계획을 확인해야 하며, 이 때 오류가 발생하기 쉽습니다. 예를 들어 예시 애플리케이션에서 실행되는 다음 SQL 문을 살펴보겠습니다. 이 SQL 문은 특정 날짜 이후에 접수된 주문에 대한 주문 세부 정보와 연관된 고객 및 제품 정보를 조회합니다.
SELECT o.order_id, c.customer_name, p.product_name
FROM orders o
JOIN customers c ON c.customer_id = o.customer_id
JOIN order_items oi ON oi.order_id = o.order_id
JOIN products p ON p.product_id = oi.product_id
WHERE o.order_date > '2024-01-01';
실제 환경에서 발생할 수 있는 인덱스 삭제로 인한 장애를 시뮬레이션하기 위해, 주문(orders) 및 주문 항목(order_items) 테이블에서 일부 인덱스(특히 조인 조건에 포함된 인덱스)를 삭제하고 테이블 통계를 업데이트했습니다. 이러한 변경으로 인해 최적화되지 않은 실행 계획이 생성되어 쿼리 속도가 급격히 저하되었고, 이는 애플리케이션 전체 성능에 부정적인 영향을 미쳤습니다.
CloudWatch Database Insights를 사용하면 동일한 SQL 문에 대한 실행 계획을 시간 경과에 따라서도 비교할 수 있습니다. 이는 성능 저하를 초래했을 가능성이 있는 변경 사항을 표시하여, 문제 해결을 단순화 하고, 팀이 성능 문제를 신속하게 진단 및 해결할 수 있도록 지원합니다. 다음 스크린샷은 CloudWatch Database Insights에서 가져온 SQL 쿼리와 해당 실행 계획 정보입니다. 실행 계획을 복사하거나 다운로드할 수도 있습니다.
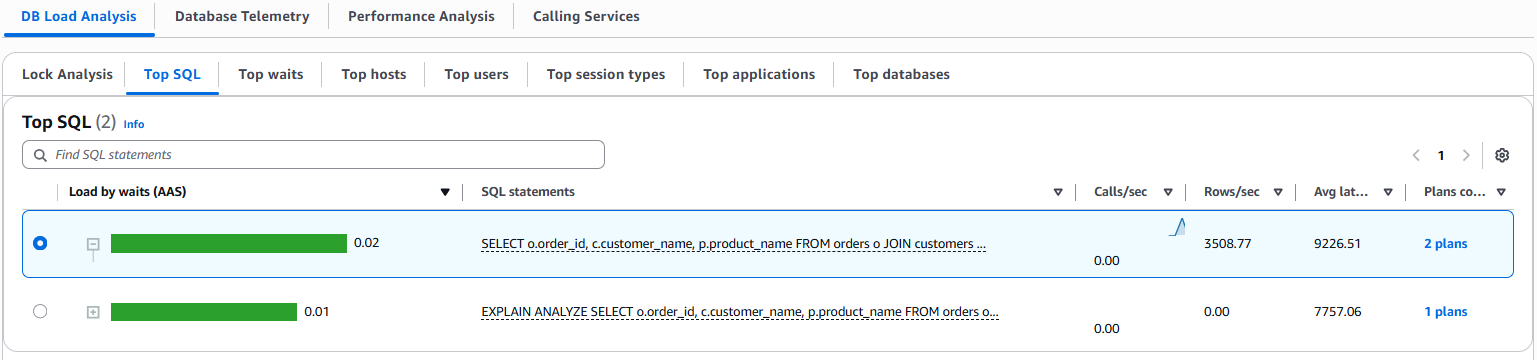
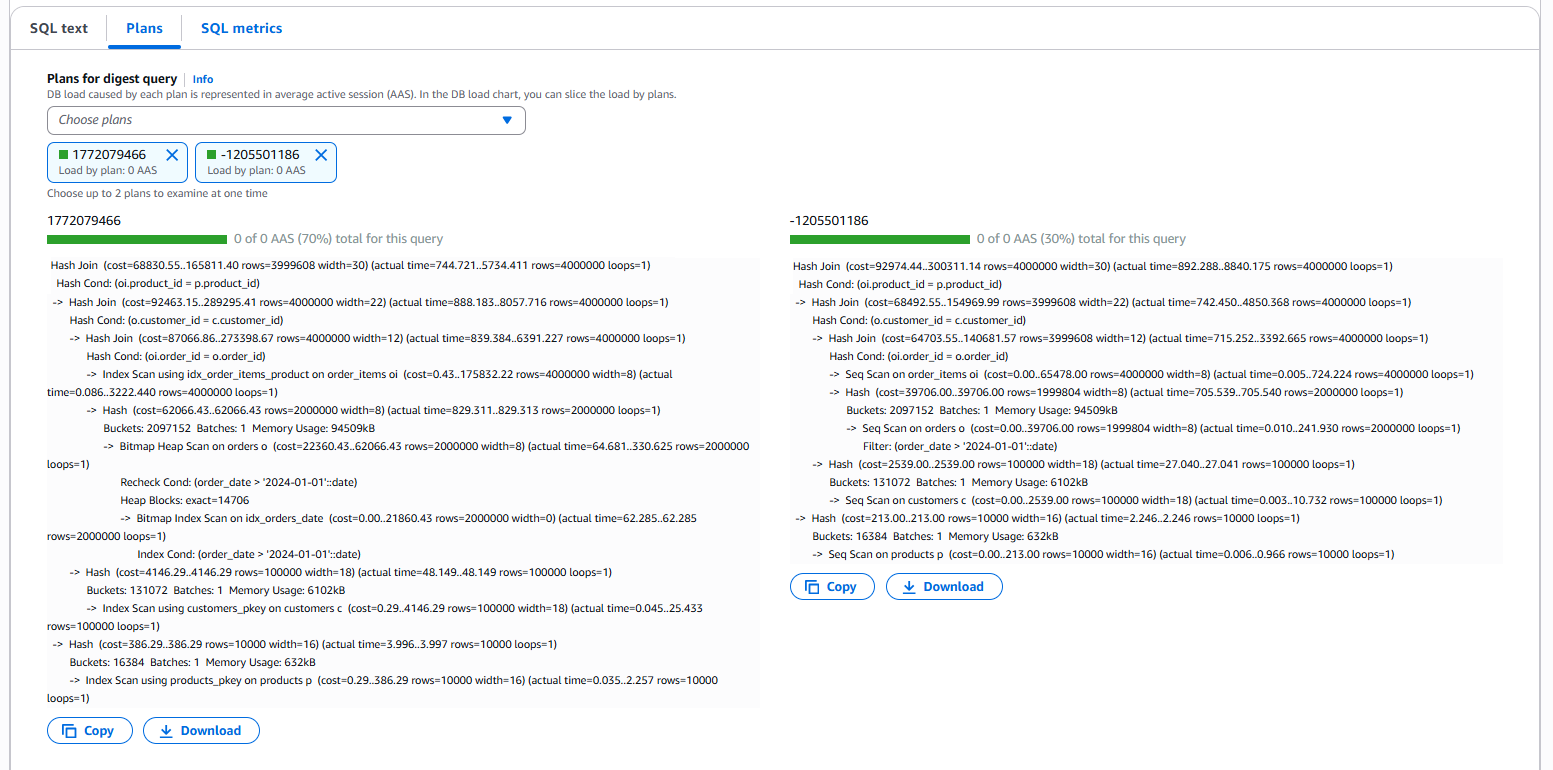
다음은 위 스크린샷에서 볼 수 있는 두 실행 계획의 세부 사항입니다.
첫 번째 실행 계획 1772079466
Hash Join (cost=68830.55..165811.40 rows=3999608 width=30) (actual time=744.721..5734.411 rows=4000000 loops=1)
Hash Cond: (oi.product_id = p.product_id)
-> Hash Join (cost=92463.15..289295.41 rows=4000000 width=22) (actual time=888.183..8057.716 rows=4000000 loops=1)
Hash Cond: (o.customer_id = c.customer_id)
-> Hash Join (cost=87066.86..273398.67 rows=4000000 width=12) (actual time=839.384..6391.227 rows=4000000 loops=1)
Hash Cond: (oi.order_id = o.order_id)
-> Index Scan using idx_order_items_product on order_items oi (cost=0.43..175832.22 rows=4000000 width=8) (actual time=0.086..3222.440 rows=4000000 loops=1)
-> Hash (cost=62066.43..62066.43 rows=2000000 width=8) (actual time=829.311..829.313 rows=2000000 loops=1)
Buckets: 2097152 Batches: 1 Memory Usage: 94509kB
-> Bitmap Heap Scan on orders o (cost=22360.43..62066.43 rows=2000000 width=8) (actual time=64.681..330.625 rows=2000000 loops=1)
Recheck Cond: (order_date > '2024-01-01'::date)
Heap Blocks: exact=14706
-> Bitmap Index Scan on idx_orders_date (cost=0.00..21860.43 rows=2000000 width=0) (actual time=62.285..62.285 rows=2000000 loops=1)
Index Cond: (order_date > '2024-01-01'::date)
-> Hash (cost=4146.29..4146.29 rows=100000 width=18) (actual time=48.149..48.149 rows=100000 loops=1)
Buckets: 131072 Batches: 1 Memory Usage: 6102kB
-> Index Scan using customers_pkey on customers c (cost=0.29..4146.29 rows=100000 width=18) (actual time=0.045..25.433 rows=100000 loops=1)
-> Hash (cost=386.29..386.29 rows=10000 width=16) (actual time=3.996..3.997 rows=10000 loops=1)
Buckets: 16384 Batches: 1 Memory Usage: 632kB
-> Index Scan using products_pkey on products p (cost=0.29..386.29 rows=10000 width=16) (actual time=0.035..2.257 rows=10000 loops=1)
두 번째 실행 계획 -1205501186
Hash Join (cost=92974.44..300311.14 rows=4000000 width=30) (actual time=892.288..8840.175 rows=4000000 loops=1)
Hash Cond: (oi.product_id = p.product_id)
-> Hash Join (cost=68492.55..154969.99 rows=3999608 width=22) (actual time=742.450..4850.368 rows=4000000 loops=1)
Hash Cond: (o.customer_id = c.customer_id)
-> Hash Join (cost=64703.55..140681.57 rows=3999608 width=12) (actual time=713.232..3392.665 rows=4000000 loops=1)
Hash Cond: (oi.order_id = o.order_id)
-> Seq Scan on order_items oi (cost=0.00..65478.00 rows=4000000 width=8) (actual time=0.005..724.224 rows=4000000 loops=1)
-> Hash (cost=39706.00..39706.00 rows=1999804 width=8) (actual time=705.539..705.540 rows=2000000 loops=1)
Buckets: 2097152 Batches: 1 Memory Usage: 94509kB
-> Seq Scan on orders o (cost=0.00..39706.00 rows=1999804 width=8) (actual time=0.010..241.930 rows=2000000 loops=1)
Filter: (order_date > '2024-01-01'::date)
-> Hash (cost=2539.00..2539.00 rows=100000 width=18) (actual time=29.162..29.162 rows=100000 loops=1)
Buckets: 131072 Batches: 1 Memory Usage: 6102kB
-> Seq Scan on customers c (cost=0.00..2539.00 rows=100000 width=18) (actual time=0.003..10.732 rows=100000 loops=1)
-> Hash (cost=213.00..213.00 rows=10000 width=16) (actual time=2.246..2.246 rows=10000 loops=1)
Buckets: 16384 Batches: 1 Memory Usage: 632kB
-> Seq Scan on products p (cost=0.00..213.00 rows=10000 width=16) (actual time=0.006..0.966 rows=10000 loops=1)
실행 계획 세부 내용에서 볼 수 있듯 동일한 쿼리에 대해 기록된 두 실행 계획 간에는 상당한 차이가 있으며, 각각은 성능에 직접적인 영향을 미칩니다. 스크린샷 왼쪽 하단의 쿼리 실행 계획은 적절한 인덱스가 설정된 초기 상태를 나타내며, 관련 테이블에 대한 인덱스 스캔이 수행되어 총 쿼리 비용이 165811.40입니다. 반면, 오른쪽 아래 실행 계획은 해당 인덱스가 실수로 삭제된 후의 상태를 반영합니다. 이로 인해 관련 테이블에 대한 순차 스캔이 수행되며 총 비용이 300311.14로 훨씬 높아졌습니다. 이러한 비용 증가는 인덱스가 실수로 삭제된 후 경험한 성능 저하의 원인을 명확히 설명합니다.
이처럼 CloudWatch Database Insights의 실행 계획 병렬 비교 기능을 활용하면, 수동으로 쿼리 계획을 추출하고 비교해야 했던 작업을 자동화함으로써 성능 저하의 근본 원인을 파악하는 과정을 간소화할 수 있습니다.
실행 계획 분석을 통한 쿼리 성능 최적화
SQL 쿼리 실행 계획을 분석하면 데이터베이스 엔진이 쿼리를 처리하는 방식을 깊이 있게 파악할 수 있습니다. 조인 유형, 스캔 방법, 정렬 기법, 예상 및 실제 행 수, 연산자 비용과 같은 핵심 요소를 검토함으로써 비효율성과 성능 병목 현상을 식별할 수 있습니다. 이러한 세부 정보는 누락된 인덱스, 비효율적인 조인 순서, 오래된 통계, 잘못 구성된 데이터베이스 파라미터 등의 문제를 파악하는 데 도움이 됩니다. 그런 다음 이 정보를 활용하여 쿼리를 튜닝하고 성능을 최적화할 수 있습니다.
다음 예시에서는 주문 날짜별 고객 지출을 요약하고 총 지출 금액이 높은 순서에서 낮은 순서로 정렬하는 전자상거래 애플리케이션의 SQL 문을 고려해 보겠습니다. 데이터베이스 모니터링을 통해 애플리케이션 속도 저하 및 전반적인 성능 병목 현상의 원인이 쿼리 실행 시간 저하로 확인된 상황을 가정하겠습니다. CloudWatch Database Insights를 사용하여 쿼리 성능을 최적화하는 과정의 일환으로 EXPLAIN ANALYZE를 사용하여 실제 실행 계획을 검토하고 개선 기회를 식별합니다.
SELECT c.customer_name, o.order_date, SUM(oi.quantity * p.price) AS total_spent
FROM customers c
JOIN orders o ON c.customer_id = o.customer_id
JOIN order_items oi ON o.order_id = oi.order_id
JOIN products p ON oi.product_id = p.product_id
GROUP BY c.customer_name, o.order_date
ORDER BY total_spent DESC;
다음 스크린샷은 CloudWatch Database Insights의 쿼리 실행 계획을 보여줍니다.
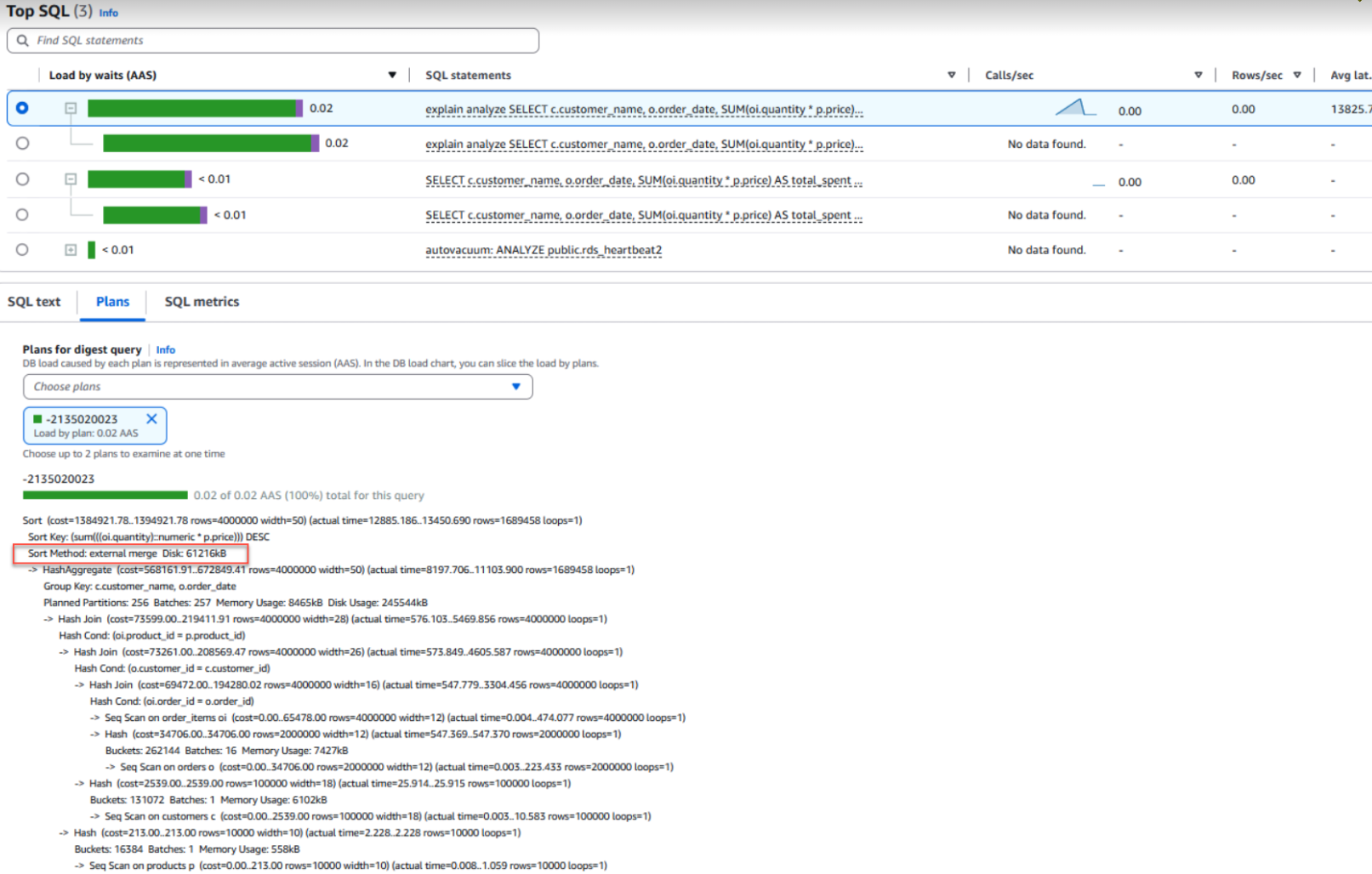
다음은 위 스크린샷에서 볼 수 있는 실행 계획의 세부 사항입니다.
실행 계획 -2135020023
Sort (cost=1384921.78..1394921.78 rows=4000000 width=50) (actual time=12885.186..13450.690 rows=1689458 loops=1)
Sort Key: (sum(((oi.quantity)::numeric * p.price))) DESC
Sort Method: external merge Disk: 61216kB
-> HashAggregate (cost=568161.91..672849.41 rows=4000000 width=50) (actual time=8197.706..11103.900 rows=1689458 loops=1)
Group Key: c.customer_name, o.order_date
Planned Partitions: 256 Batches: 257 Memory Usage: 8465kB Disk Usage: 245544kB
-> Hash Join (cost=73599.00..219411.91 rows=4000000 width=28) (actual time=576.103..5469.856 rows=4000000 loops=1)
Hash Cond: (oi.product_id = p.product_id)
-> Hash Join (cost=73261.00..208569.47 rows=4000000 width=26) (actual time=573.849..4605.587 rows=4000000 loops=1)
Hash Cond: (o.customer_id = c.customer_id)
-> Hash Join (cost=69472.00..194280.02 rows=4000000 width=16) (actual time=547.779..3304.456 rows=4000000 loops=1)
Hash Cond: (oi.order_id = o.order_id)
-> Seq Scan on order_items oi (cost=0.00..65478.00 rows=4000000 width=12) (actual time=0.004..474.077 rows=4000000 loops=1)
-> Hash (cost=34706.00..34706.00 rows=2000000 width=12) (actual time=547.369..547.370 rows=2000000 loops=1)
Buckets: 262144 Batches: 16 Memory Usage: 7427kB
-> Seq Scan on orders o (cost=0.00..34706.00 rows=2000000 width=12) (actual time=0.003..223.433 rows=2000000 loops=1)
-> Hash (cost=2539.00..2539.00 rows=100000 width=18) (actual time=25.914..25.915 rows=100000 loops=1)
Buckets: 131072 Batches: 1 Memory Usage: 6102kB
-> Seq Scan on customers c (cost=0.00..2539.00 rows=100000 width=18) (actual time=0.003..10.583 rows=100000 loops=1)
-> Hash (cost=213.00..213.00 rows=10000 width=10) (actual time=2.228..2.228 rows=10000 loops=1)
Buckets: 16384 Batches: 1 Memory Usage: 558kB
-> Seq Scan on products p (cost=0.00..213.00 rows=10000 width=10) (actual time=0.008..1.059 rows=10000 loops=1)
쿼리 실행 계획에서 Sort Method: external merge Disk: 61216kB 부분에 주목합니다. 이는 데이터베이스가 모든 내용을 메모리에 유지하지 못하고 디스크 기반 정렬을 사용해야 했음을 나타냅니다. 이러한 외부 디스크 사용은 SQL 문에서 성능 병목 현상이 발생했음을 강력히 시사합니다.
PostgreSQL의 파라미터 그룹 구성을 더 깊이 살펴본 결과, 정렬 작업은 work_mem 파라미터로 제어되며 현재 기본값인 4MB로 설정되어 있음을 발견했습니다. 데이터 세트가 작았을 때는 이 설정이 충분했지만, 최근 데이터 증가로 인해 메모리 요구량이 이 제한을 훨씬 초과하게 되었습니다. 조사 결과, 현재 쿼리는 정렬 작업에 약 61MB의 메모리를 필요로 합니다. 사용 가능한 work_mem이 4MB에 불과하기 때문에 PostgreSQL은 정렬 작업을 디스크로 스필(spill)할 수밖에 없으며, 이는 높은 I/O 비용과 상당한 성능 저하를 초래합니다.
검토 결과에 따르면, 쿼리 실행 전에 세션 또는 쿼리 수준에서 work_mem을 256MB로 증가시켜 성능을 최적화할 수 있습니다. 이렇게 하면 Aurora PostgreSQL은 비용이 많이 드는 디스크 기반 정렬 대신 퀵정렬과 같은 더 빠른 인메모리 정렬 방법을 사용할 수 있습니다. 다음 코드를 참조합니다:
SET WORK_MEM = '256 MB';
EXPLAIN ANALYZE SELECT c.customer_name, o.order_date, SUM(oi.quantity * p.price) AS total_spent
FROM customers c
JOIN orders o ON c.customer_id = o.customer_id
JOIN order_items oi ON o.order_id = oi.order_id
JOIN products p ON oi.product_id = p.product_id
GROUP BY c.customer_name, o.order_date
ORDER BY total_spent DESC;
이 주제에 대한 자세한 내용은 work_mem을 사용한 PostgreSQL 정렬 작업 튜닝을 참조합니다.
다음 스크린샷은 이제 정렬 작업이 디스크가 아닌 데이터베이스의 메인 메모리에서 수행되고 있음을 보여줍니다.
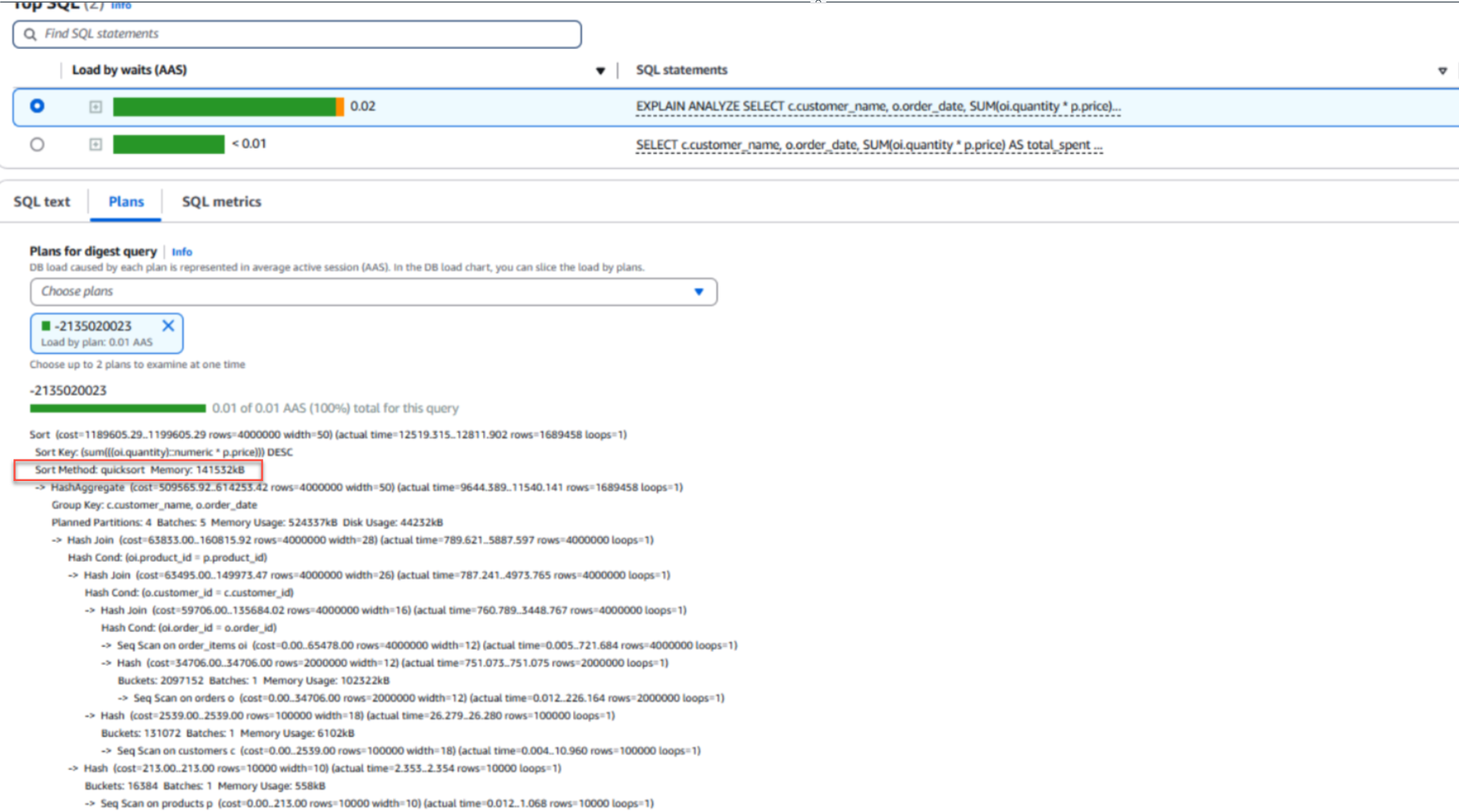
다음은 위 스크린샷에서 볼 수 있는 실행 계획의 세부 사항입니다.
실행 계획 -2135020023
Sort (cost=1189605.29..1199605.29 rows=4000000 width=50) (actual time=12519.315..12811.902 rows=1689458 loops=1)
Sort Key: (sum((oi.quantity)::numeric * p.price))) DESC
Sort Method: quicksort Memory: 141532kB
-> HashAggregate (cost=509565.92..614253.42 rows=4000000 width=50) (actual time=9644.389..11540.141 rows=1689458 loops=1)
Group Key: c.customer_name, o.order_date
Planned Partitions: 4 Batches: 5 Memory Usage: 524288kB Disk Usage: 442432kB
-> Hash Join (cost=63853.00..160815.92 rows=4000000 width=28) (actual time=789.621..5887.597 rows=4000000 loops=1)
Hash Cond: (oi.product_id = p.product_id)
-> Hash Join (cost=63495.00..149973.47 rows=4000000 width=26) (actual time=787.241..4973.765 rows=4000000 loops=1)
Hash Cond: (o.customer_id = c.customer_id)
-> Hash Join (cost=59706.00..135884.02 rows=4000000 width=16) (actual time=760.789..3448.767 rows=4000000 loops=1)
Hash Cond: (order_id = order_id)
-> Seq Scan on order_items oi (cost=0.00..65478.00 rows=4000000 width=12) (actual time=0.005..721.684 rows=4000000 loops=1)
-> Hash (cost=34706.00..34706.00 rows=2000000 width=12) (actual time=751.073..751.075 rows=2000000 loops=1)
Buckets: 2097152 Batches: 1 Memory Usage: 102522kB
-> Seq Scan on orders o (cost=0.00..34706.00 rows=2000000 width=12) (actual time=0.012..226.164 rows=2000000 loops=1)
-> Hash (cost=2539.00..2539.00 rows=100000 width=18) (actual time=26.279..26.280 rows=100000 loops=1)
Buckets: 131072 Batches: 1 Memory Usage: 6102kB
-> Seq Scan on customers c (cost=0.00..2539.00 rows=100000 width=18) (actual time=0.004..10.960 rows=100000 loops=1)
-> Hash (cost=213.00..213.00 rows=10000 width=10) (actual time=2.355..2.354 rows=10000 loops=1)
Buckets: 16384 Batches: 1 Memory Usage: 558kB
-> Seq Scan on products p (cost=0.00..213.00 rows=10000 width=10) (actual time=0.012..1.068 rows=10000 loops=1)
CloudWatch Database Insights를 통해 쿼리 실행 패턴을 명확하게 시각화하여 최적화 프로세스를 간소화할 수 있었으며, 이를 통해 work_mem 파라미터가 근본 원인임을 파악할 수 있었습니다.
결론
이 글에서는 Aurora PostgreSQL용 CloudWatch Database Insights를 활용하여 데이터베이스 성능에 영향을 미치는 실행 계획 변경 사항과 리소스 제약 조건을 분석하는 방법을 소개했습니다. 예시 시나리오에서는 인덱스 삭제로 인한 쿼리 접근 경로 변경으로 발생한 쿼리 지연 시간 급증을 확인하고, 디스크 기반 정렬 작업으로 인한 성능 병목 현상을 진단한 후 work_mem 파라미터 증가로 해결했습니다.
CloudWatch Database Insights를 시작해 보세요.