AWS 기술 블로그
Amazon EKS에서 운영하는 자체 관리형 Agentic AI 플랫폼 : 인프라 자동화와 관측성으로 운영 안정성 확보하기
서론
많은 기업이 LLM 기반 에이전틱 워크플로우를 실제 업무에 투입하고 있습니다. 그러나 프로덕션 규모로 확대하면 단일 거대 LLM에 모든 호출을 의존하는 방식의 한계가 드러납니다. 에이전트 내부에서 발생하는 도구 분류·요약·포맷팅 등 매 단계마다 동일한 토큰 과금이 누적되고, 거대 모델의 긴 응답 지연(TTFT)은 실시간 대화에 부적합합니다. 요금 계산이나 약관 검증처럼 정확성이 요구되는 업무에서 환각(hallucination)은 비즈니스 리스크가 되며, 민감 데이터가 외부 API로 전송되는 거버넌스 문제도 수반됩니다.
이러한 제약은 하나의 결론으로 이어집니다: 모든 작업에 동일한 거대 LLM을 사용하는 방식은 지속 가능하지 않습니다. 복잡한 추론은 고성능 LLM이, 반복적 실무(FAQ, 분류, 데이터 추출)는 도메인 특화 SLM이 담당하는 이질적 다중 모델 생태계가 필요합니다. 연구에 따르면 에이전트 LLM 호출의 40~70%는 파인튜닝된 SLM으로 대체 가능합니다. Kubernetes 생태계도 Gateway API Inference Extension(LLM 라우팅 표준화), Kueue(AI 워크로드 스케줄링), LeaderWorkerSet(분산 추론 패턴) 등 AI 네이티브 기능을 빠르게 확장하며, 다중 모델 운영을 위한 인프라 플랫폼으로 진화하고 있습니다.
본 게시글에서는 Amazon EKS Auto Mode로 GPU 인프라를 자동화하고, Bifrost AI Gateway로 자체 호스팅 모델(vLLM)과 Amazon Bedrock을 하나의 엔드포인트로 통합하며, Langfuse로 2-Tier 관측성을 확보하는 자체 관리형 Agentic AI 플랫폼 구축 방법을 소개합니다.
EKS 기반 오픈 아키텍쳐를 채택하는 이유
Amazon Bedrock은 인프라 구축 없이 에이전틱 AI 플랫폼 개발을 바로 시작할 수 있는 강력한 출발점입니다. GPU 관리, 스케일링, 가용성을 AWS가 처리하므로 팀은 Agent 비즈니스 로직에 집중할 수 있습니다.
그러나 기업이 다음 단계로 나아가면 추가적인 요구사항이 생깁니다:
- Open Weight 모델 자체 호스팅: Llama, Qwen, DeepSeek 같은 모델을 직접 운영하여 토큰 과금을 GPU 고정비로 전환하고, 대량 트래픽에서 비용을 절감
- 도메인 특화 SLM 파인튜닝: 자사 데이터로 학습한 경량 모델(7B~14B)을 LoRA 어댑터로 서빙하여 품질과 비용을 동시에 최적화
- 통합 게이트웨이: 자체 호스팅 모델과 Bedrock을 하나의 API 엔드포인트로 통합하여, 앱 코드 변경 없이 모델 간 라우팅을 전환
이러한 요구사항을 충족하기 위해 EKS 기반의 오픈 아키텍쳐를 함께 고려할 수 있습니다. Bedrock으로 시작하고, 필요에 따라 EKS로 자체 호스팅을 확장하며, Bifrost가 양쪽을 하나의 인터페이스로 통합하는 하이브리드 접근이 현실적인 최적의 접근 방식입니다. 이 글에서는 EKS Auto Mode를 사용하여 운영 부담을 최소화하면서도 오픈소스의 유연성을 확보하는 방법을 다룹니다.
솔루션 개요
본 솔루션은 Amazon EKS Auto Mode 클러스터 위에 GPU 인프라를 자동화하고, Bifrost와 Langfuse를 통해 2계층 (2-Tier) 관측성을 구현합니다.
EKS Auto Mode는 VPC CNI, EBS CSI Driver, CoreDNS 등 핵심 컴포넌트를 자동으로 설치·관리하며, Karpenter가 내장되어 GPU 노드의 Just-in-Time 프로비저닝과 Spot 인스턴스 활용을 자동 처리합니다.
2계층 관측성 전략
AI 플랫폼의 비용과 품질을 함께 관리하려면 인프라 레벨과 애플리케이션 레벨, 두 가지 관측성이 필요합니다.
- 인프라 레벨 (Bifrost): “어떤 모델이 비용 대비 효율적인가?” — 모델별 API 호출 비용, 토큰 사용량, 지연 시간을 추적합니다.
- 애플리케이션 레벨 (Langfuse): “어떤 에이전트가 병목인가?” — 각 에이전트의 실행 시간, 입출력, 품질 평가를 추적합니다.
이와 같이 2계층 구조로 인프라 비용 최적화(모델 선택)와 애플리케이션 품질 최적화(에이전트 튜닝)를 동시에 수행할 수 있습니다.
아키텍쳐
본 솔루션의 핵심은 EKS Auto Mode를 기반으로 Kubernetes의 운영 부담을 줄이고 GPU 인프라 프로비저닝을 자동화하는 것입니다.
![]()
레이어별 구성
| 레이어 | 구성 요소 | 역할 |
|---|---|---|
| 인프라 | Amazon EKS Auto Mode | 관리형 Control Plane + VPC CNI, EBS CSI, CoreDNS 자동 설치 |
| 프로비저닝 | Karpenter v1.0+ | Just-in-Time GPU 노드 프로비저닝, Spot 인스턴스 활용 |
| 게이트웨이 | Bifrost | AI Gateway + 인프라 비용 추적, 다중 모델 제공자 연동 |
| 관측성 | Langfuse | LLM 트레이싱 + 애플리케이션 비용 추적, 자체 호스팅 가능 |
사전 준비사항
본 솔루션을 구성하기 위해 다음과 같은 사전 준비가 필요합니다:
- AWS CLI 및 kubectl 설치
- Amazon EKS 클러스터 생성 권한
- Helm 3.x 설치
- GPU 인스턴스(g5, p4d 등)에 대한 서비스 할당량
전체 코드와 매니페스트는 GitHub 리포지토리에서 확인할 수 있습니다.
단계별 구현
1단계 : EKS Auto Mode 클러스터 구성
EKS Auto Mode는 Karpenter를 포함한 핵심 컴포넌트들을 자동으로 구성하고 관리하여, AI 인프라 자동화의 중요한 마지막 구성 요소를 제공합니다. GPU 워크로드를 위한 커스텀 NodePool을 추가할 수 있으며, 기본 NodeClass에 GPU 드라이버가 포함된 AMI가 자동으로 선택됩니다.
aws eks update-cluster-config \
--name $CLUSTER_NAME \
--compute-config enabled=true \
--kubernetes-network-config '{"elasticLoadBalancing":{"enabled": true}}' \
--storage-config '{"blockStorage":{"enabled": true}}'
EKS Auto Mode에서 AI 워크로드 배포 시 고려사항
- Graviton(ARM64) 인스턴스 선택 가능성: NodePool에 인스턴스 타입을 명시하지 않으면, Auto Mode가 비용 최적화를 위해 Graviton(ARM64)을 선택할 수 있습니다. 실제 테스트에서 기본 노드가 c6g, c6gn으로 프로비저닝되었습니다. ARM64 이미지를 제공하지 않는 컴포넌트(예: vLLM Production Stack의 router)가 있다면 NodePool requirements에
kubernetes.io/arch: amd64를 명시하여 대응합니다. - GPU 드라이버·Device Plugin 자동 관리: Auto Mode는 GPU 드라이버, Container Toolkit, Device Plugin을 AMI에 사전 설치합니다. Pod에서
nvidia.com/gpu: 1을 요청하면 추가 설정 없이 GPU를 바로 사용할 수 있으며, GPU 메트릭 모니터링이 필요한 경우 DCGM Exporter를 standalone DaemonSet으로 배포하면 됩니다. - StorageClass 필수 설정:
ebs.csi.eks.amazonaws.comprovisioner를 사용하는 StorageClass를 default로 설정해야 합니다. Langfuse의 ClickHouse, PostgreSQL, Redis 등 StatefulSet의 PVC가 정상적으로 바인딩되려면 이 설정이 선행되어야 합니다. - Add-on 자동 관리: VPC CNI, EBS CSI Driver, CoreDNS가 자동으로 설치·업그레이드됩니다. 수동 구성 대비 초기 구축 시간을 크게 단축할 수 있습니다.
2단계 : GPU NodePool 설정과 노드 자동 프로비저닝
EKS Auto Mode에서 GPU 워크로드용 커스텀 NodePool을 생성합니다. 일반적인 Karpenter NodePool과 달리 eks.amazonaws.com 그룹의 NodeClass를 사용합니다.
apiVersion: karpenter.sh/v1
kind: NodePool
metadata:
name: gpu-inference-pool
spec:
template:
spec:
requirements:
- key: karpenter.sh/capacity-type
operator: In
values: ["spot", "on-demand"]
- key: node.kubernetes.io/instance-type
operator: In
values: ["g5.xlarge", "g5.2xlarge", "g5.4xlarge"]
- key: eks.amazonaws.com/instance-gpu-count
operator: Gt
values: ["0"]
nodeClassRef:
group: eks.amazonaws.com
kind: NodeClass
name: default
limits:
nvidia.com/gpu: 50
disruption:
consolidationPolicy: WhenEmptyOrUnderutilized
consolidateAfter: 30s
주요 설정 :
- Spot 우선:
capacity-type에 Spot을 포함하여 최대 70% 비용을 절감합니다. GPU 추론 워크로드는 요청 간 상태 의존성이 낮아 Spot 중단의 영향이 비교적 제한적입니다. - 자동 Consolidation: 유휴 GPU 노드를 30초 내에 자동 정리하여, 요청이 없는 시간대에 GPU 비용이 발생하지 않습니다.
- Auto Mode 전용 NodeClass:
eks.amazonaws.com그룹과eks.amazonaws.com/instance-gpu-count레이블을 사용합니다. 기존 Karpenter의karpenter.k8s.aws그룹은 Auto Mode에서 동작하지 않습니다. - 워크로드 연동: vLLM 등 GPU 워크로드가 스케줄링되면 Karpenter가 조건에 맞는 인스턴스를 자동 프로비저닝하고, 워크로드가 제거되면 노드도 함께 정리됩니다.
3단계 : Bifrost AI Gateway 를 통한 멀티 모델 라우팅 구현
Bifrost는 20개 이상의 모델 제공자(Amazon Bedrock, OpenAI, Anthropic 등)를 OpenAI-compatible API로 통합하는 AI Gateway입니다. 애플리케이션은 단일 엔드포인트만 호출하고, provider/model 형식으로 라우팅 대상을 지정합니다.
helm repo add bifrost https://maximhq.github.io/bifrost/helm-charts helm install bifrost bifrost/bifrost -n ai-inference -f manifests/bifrost-values.yaml
자체 호스팅 vLLM을 Custom Provider로 등록
Bifrost의 주요 장점은 자체 호스팅 모델도 외부 API 제공자와 동일한 인터페이스로 통합할 수 있다는 점입니다. vLLM은 OpenAI-compatible API를 제공하므로, base_provider_type: "openai"로 설정하면 Bifrost가 동일한 프로토콜로 vLLM과 통신합니다.
"self-hosted-vllm": {
"keys": [
{"name": "vllm-key-1", "value": "dummy", "models": ["qwen3-8b"], "weight": 1.0}
],
"network_config": {
"base_url": "http://vllm.ai-inference.svc.cluster.local:8000"
},
"custom_provider_config": {
"base_provider_type": "openai",
"allowed_requests": { "chat_completion": true, "chat_completion_stream": true }
}
}
network_config.base_url에 클러스터 내부 DNS를 지정하여 외부 네트워크 없이 통신합니다. 등록 후 앱 코드에서 self-hosted-vllm/qwen3-8b로 모델을 지정할 수 있습니다.
Amazon Bedrock Provider 추가
복잡한 문의에 고성능 모델을 사용하기 위해 Amazon Bedrock provider를 추가합니다. AWS credentials Secret을 생성하고 Bifrost Pod에 환경변수를 주입한 후, Bifrost Web UI 또는 API(/api/providers)로 등록합니다.
구성이 완료되면 앱 코드에서 모델 이름만 변경하여 라우팅을 전환 가능합니다:
- 간단한 문의:
self-hosted-vllm/qwen3-8b→ vLLM (외부 API 비용 $0, GPU 인프라 비용만 지출) - 복잡한 문의:
bedrock/global.anthropic.claude-haiku-4-5-20251001-v1:0→ Amazon Bedrock
Kubernetes ConfigMap으로 쿼리 타입별 모델을 MODEL_SIMPLE, MODEL_COMPLEX 등으로 지정하면, Orchestrator가 쿼리를 분류한 뒤 해당 모델로 라우팅합니다. 앱 코드 변경 없이 ConfigMap만 수정하면 라우팅이 전환됩니다.
4단계 : vLLM 자체 호스팅 추론 서버
vLLM은 PagedAttention 알고리즘으로 GPU 메모리 효율을 극대화하는 고성능 오픈소스 LLM 서빙 라이브러리입니다. 본 데모에서는 자체 호스팅 모델로 Alibaba Cloud의 Qwen3-8B를 사용합니다. 8B급 오픈소스 모델 중 에이전트 태스크 성능이 높고, gated model이 아니라 HuggingFace 접근 승인 없이 바로 사용할 수 있으며, g5.2xlarge(24GB VRAM)에서 안정적으로 동작합니다.
EKS Auto Mode에서는 Graviton 인스턴스가 선택될 수 있으므로, vLLM Production Stack Helm chart 대신 직접 Kubernetes Deployment를 작성하여 GPU NodePool에 배포하는 방법이 보다 적절합니다.
vLLM Deployment의 핵심 설정:
spec:
nodeSelector:
node-type: gpu-inference # GPU NodePool에 스케줄링
enableServiceLinks: false # vLLM 환경변수 충돌 방지
containers:
- name: vllm
image: vllm/vllm-openai:v0.17.1
args: ["--model", "Qwen/Qwen3-8B",
"--served-model-name", "qwen3-8b",
"--max-model-len", "4096"]
resources:
requests:
nvidia.com/gpu: "1"
limits:
nvidia.com/gpu: "1"
enableServiceLinks: false: Kubernetes가 Service 이름(vllm)으로 생성하는VLLM_*환경변수가 vLLM 자체 설정과 충돌하는 것을 방지합니다.--max-model-len 4096: g5.2xlarge(24GB VRAM) 환경에서 안정적으로 동작하도록 컨텍스트 길이를 제한합니다.nodeSelector: node-type: gpu-inference: GPU NodePool에만 스케줄링합니다. Deployment가 생성되면 Karpenter가 g5 Spot 인스턴스를 자동 프로비저닝합니다.
5단계 : Langfuse 관측성
Langfuse는 LLM 애플리케이션의 트레이싱, 평가, 비용 추적을 위한 오픈소스 관측성 플랫폼입니다. 데이터 주권이 중요하거나 비용 최적화가 필요한 경우 자체 호스팅을 권장합니다.
Bifrost가 인프라 레벨에서 모델별 API 비용을 추적한다면, Langfuse는 애플리케이션 레벨에서 각 에이전트의 실행 시간, 입출력, 품질을 추적합니다. 두 레벨을 결합하면 “어떤 모델이 효율적인지”와 “어떤 에이전트가 병목인지”를 동시에 파악할 수 있습니다.
helm repo add langfuse https://langfuse.github.io/langfuse-k8s helm install langfuse langfuse/langfuse -n observability --create-namespace -f manifests/langfuse-values.yaml
Langfuse Helm chart는 ClickHouse, PostgreSQL, Redis, Zookeeper, S3(MinIO)를 포함합니다. EKS Auto Mode에서는 StatefulSet PVC에 StorageClass 지정이 필수이므로, 1단계에서 설정한 default StorageClass(ebs-auto)가 선행되어야 합니다.
사용 시나리오 : 지능형 고객 지원 시스템
인프라 구성이 완료되면 실제 AI Agent 시스템에서 멀티모델 라우팅과 관측성이 어떻게 동작하는지 확인 가능합니다. 여기서는 Bifrost 멀티모델 라우팅과 LangGraph 멀티 에이전트 오케스트레이션을 결합한 지능형 고객 지원 시스템을 구현합니다.
데모 개요
고객이 AWS 서비스에 대한 문의를 입력하면, 시스템이 문의 유형을 분석하여 적절한 모델과 전문 에이전트로 자동 라우팅합니다.
![]()
핵심 구현 포인트는 다음과 같습니다.
핵심 1. Bifrost를 통한 멀티 모델 라우팅
앱 코드에서 langchain_openai.ChatOpenAI의 base_url에 Bifrost 엔드포인트를 지정합니다. 모든 LLM 호출이 Bifrost를 경유하며, provider/model 형식으로 라우팅 대상이 결정됩니다.
from langchain_openai import ChatOpenAI
llm = ChatOpenAI(
base_url="http://bifrost.ai-inference.svc.cluster.local:8080/v1",
api_key="test-1234",
model="self-hosted-vllm/qwen3-8b", # 또는 "bedrock/global.anthropic.claude-haiku-4-5-20251001-v1:0"
)
본 시나리오에서는 ConfigMap 기반의 정적 라우팅을 사용합니다. 운영자가 쿼리 타입별 모델을 명시적으로 지정하므로 비용 예측이 쉽고 운영이 단순합니다. 이후 Langfuse 평가 데이터를 기반으로 동적 전환하거나, Bifrost의 fallback·load balancing 기능으로 확장할 수 있습니다.
핵심 2 . LangGraph 멀티 에이전트 워크플로우
LangGraph의 StateGraph로 에이전트 간 워크플로우를 정의합니다. Orchestrator가 쿼리를 분류하면 조건부 라우팅으로 전문 에이전트를 호출하고, Evaluation Agent가 응답 품질을 평가합니다.
from langgraph.graph import StateGraph, END
def build_workflow():
graph = StateGraph(SupportState)
graph.add_node("orchestrator", classify_query)
graph.add_node("rag_agent", rag_respond)
graph.add_node("document_agent", document_respond)
graph.add_node("evaluation", evaluate_response)
graph.set_entry_point("orchestrator")
graph.add_conditional_edges(
"orchestrator",
route_by_type,
{"rag_agent": "rag_agent", "document_agent": "document_agent"}
)
graph.add_edge("rag_agent", "evaluation")
graph.add_edge("document_agent", "evaluation")
graph.add_edge("evaluation", END)
return graph.compile()
핵심 3. Langfuse 트레이싱 통합
Langfuse Python SDK v4는 OpenTelemetry 기반입니다. 각 에이전트에 @observe 데코레이터를 추가하면 span이 자동 기록되고, propagate_attributes()로 trace metadata가 하위 span에 전파됩니다.
from langfuse import observe, propagate_attributes
@observe(name="orchestrator")
def classify_query(state: SupportState) -> SupportState:
# Langfuse가 자동으로 입출력, 실행 시간을 기록
...
@app.post("/query")
def handle_query(req: QueryRequest):
with propagate_attributes(
trace_name="customer_support",
tags=["eks-demo", "support"],
):
result = run_workflow(req.query)
return result
Langfuse 키가 설정되지 않은 환경에서는 no-op으로 동작합니다. 따라서 개발 환경에서는 트레이싱 없이, 프로덕션에서는 활성화하는 구성이 가능합니다.
데모 수행 결과
EKS 클러스터에 배포한 데모 앱의 테스트 결과입니다.
Scene 1: 간단한 문의 → vLLM 자체 호스팅
{
"user_query": "S3 버킷 생성 방법을 알려주세요",
"query_type": "simple",
"selected_model": "self-hosted-vllm/qwen3-8b",
"response": "S3 버킷을 생성하려면 ...",
"evaluation_score": 7.0
}
Orchestrator가 쿼리를 simple로 분류하고, Bifrost가 클러스터 내부의 vLLM으로 라우팅합니다. 외부 API 호출 비용은 $0이며, GPU 인프라 비용만 발생합니다.
Scene 2: 비교적 복잡한 문의 → Bedrock Claude
{
"user_query": "EKS 클러스터에서 OOM 에러가 발생합니다",
"query_type": "complex",
"selected_model": "bedrock/global.anthropic.claude-haiku-4-5-20251001-v1:0",
"response": "EKS 클러스터에서 OOM(Out-of-Memory) 에러가 발생했을 때 다음과 같은 방법으로 디버깅할 수 있습니다: 1. 클러스터 및 노드 상태 확인 ...",
"evaluation_score": 7.0
}
complex로 분류된 쿼리는 Bifrost가 Amazon Bedrock으로 라우팅합니다. Claude의 한국어 이해력과 추론 능력으로 높은 품질의 응답을 반환합니다. 간단한 문의(전체의 ~65%)를 vLLM으로 처리하면 외부 API 비용을 대폭 줄일 수 있습니다.
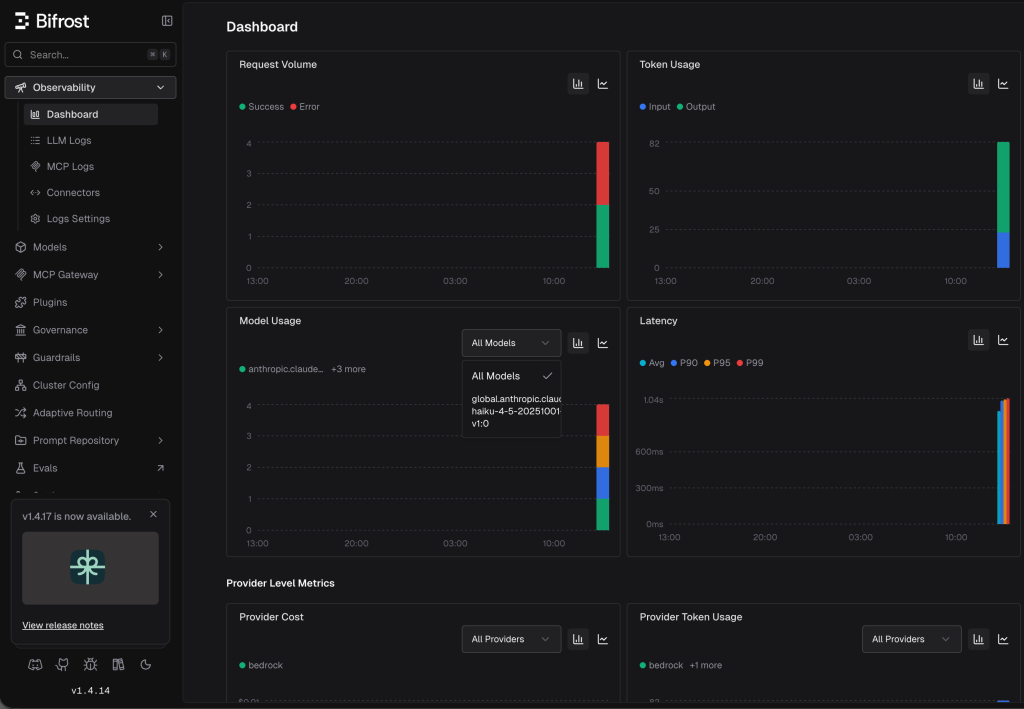
Bifrost 대시보드 : provider 별 호출 결과
Request Volume, Token 사용량, Model 사용량, Latency 를 조회할 수 있습니다.
Langfuse 대시보드 : 트레이싱 결과
각 API 호출마다 Langfuse에 트레이스가 자동 기록됩니다
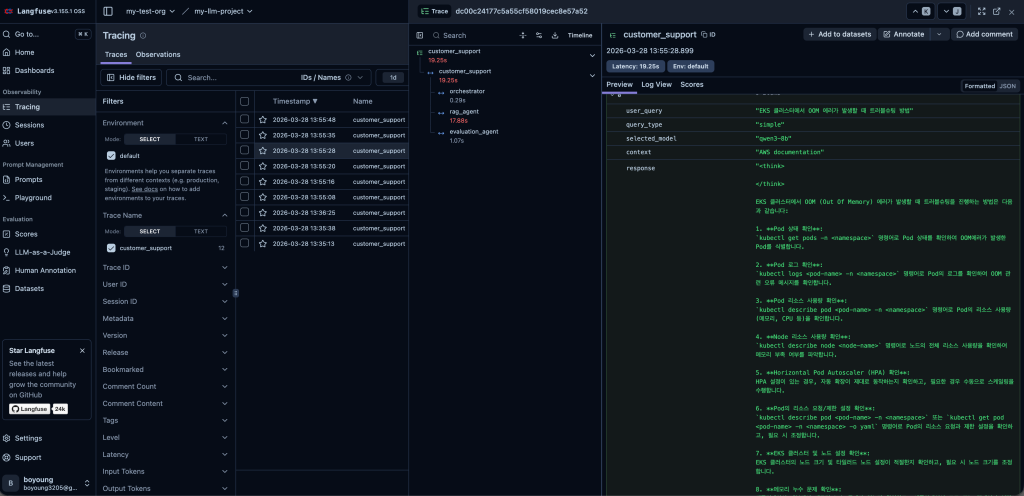
트레이스 구조:
customer_support (trace)
├── orchestrator (span) — 쿼리 분류
├── rag_agent (span) — RAG 응답 생성 (또는 document_agent)
├── evaluation_agent (span) — 응답 품질 평가
└── customer_support (span) — 전체 워크플로우
`@observe` 데코레이터가 각 에이전트의 입출력, 실행 시간, 에러를 자동으로 기록하므로 별도의 로깅 코드를 추가하지 않습니다.
프로덕션 비용 분석
멀티모델 라우팅 적용 시 예상 비용입니다. 일 10,000건 요청, 평균 500 input / 200 output tokens 기준입니다.
10,000~$3.75
| 모델 | 제공자 | 비중 (건/일) | API 비용/일 | 용도 |
|---|---|---|---|---|
| qwen3-8b | vLLM (자체 호스팅) | 75% (7,500) | $0 (GPU 인프라만) | 간단한 문의 |
| Claude Haiku 4.5 | Bedrock | 25% (2,500) | ~$3.75 | 복잡한 문의 |
| 합계 |
- 가격 기준: Claude Haiku 4.5 $1.00/$5.00 per 1M tokens (input/output) — [Anthropic 공식 페이지]
(https://www.anthropic.com/claude/haiku) - 비용 계산 예시 (10,000건/일, 평균 500 input + 200 output tokens):
- Input: 10,000건 × 500 tokens = 5,000,000 tokens → 5M × $1.00/1M = $5.00
- Output: 10,000건 × 200 tokens = 2,000,000 tokens → 2M × $5.00/1M = $10.00
- 합계: $15.00/일
만약 모든 요청을 Claude Haiku 4.5로 처리하면 일 ~$15.00이 발생합니다. 멀티모델 라우팅으로 간단한 문의(75%)를 자체 호스팅 vLLM으로 처리하면 API 비용을 약 75% 절감할 수 있습니다.
Karpenter GPU 자동 프로비저닝 확인
vLLM Deployment가 생성되면 Karpenter가 GPU 노드를 자동 프로비저닝합니다.
$ kubectl get nodeclaim NAME TYPE CAPACITY ZONE gpu-inference-pool-xxxxx g5.2xlarge spot ap-northeast-2a $ kubectl get pods -n ai-inference -l app=vllm NAME READY STATUS RESTARTS AGE vllm-xxxxx-xxxxx 1/1 Running 0 ...
워크로드가 스케줄링되면 Karpenter가 g5.2xlarge(amd64, Spot) 노드를 자동 프로비저닝하고, 워크로드가 없으면 consolidateAfter: 30s 설정에 따라 노드가 자동 정리되어 불필요한 GPU 비용이 발생하지 않습니다.
결론
이 글에서는 Amazon EKS Auto Mode 기반으로 GPU 인프라를 자동화하고, Bifrost AI Gateway로 멀티모델 라우팅을, Langfuse로 LLM 트레이싱을 구현하여 자체 관리형 Agentic AI 플랫폼의 운영 안정성을 확보하는 방법을 살펴보았습니다.
- EKS Auto Mode가 GPU 드라이버, VPC CNI, EBS CSI를 자동 관리하여 인프라 운영 부담을 줄입니다.
- Bifrost로 자체 호스팅 vLLM과 Amazon Bedrock을 동일한
provider/model형식으로 통합하고, ConfigMap만 수정하면 앱 코드 변경 없이 라우팅을 전환할 수 있습니다. - Langfuse 의
@observe데코레이터와propagate_attributes()로 최소한의 코드 변경으로 전체 워크플로우의 트레이싱을 구현할 수 있습니다. - Karpenter의 Spot 활용과 자동 consolidation으로 GPU 비용을 최적화하고, 간단한 문의를 vLLM으로 처리하여 외부 API 비용을 75% 절감할 수 있습니다.
다음 단계: 프로덕션 확장
본 게시글에서는 EKS Auto Mode + Bifrost + Langfuse로 기본 구조를 구축했습니다. 프로덕션으로 확장할 때 고려해야 할 주요 영역은 다음과 같습니다.
| 영역 | 솔루션 | 내용 |
|---|---|---|
| 컨트롤 플레인 확장 | Provisioned Control Plane (PCP) | API 동시성 1,700+ seats, 99.99% SLA |
| AWS 리소스 관리 | ACK (AWS Controllers for Kubernetes) | S3, RDS 등을 Kubernetes 네이티브로 관리 |
| 인프라 추상화 | KRO (Kubernetes Resource Orchestrator) | AI 추론 스택을 단일 리소스로 추상화 |
| MLOps 자동화 | Argo CD + Argo Workflows | GitOps 기반 모델 배포, ML 파이프라인 오케스트레이션 |
| 트래픽 관리 | kgateway + Bifrost (2-Tier Gateway) | Gateway API 기반 인증/Rate Limiting + 모델 라우팅 분리 |
| 추론 최적화 | llm-d | KV Cache-aware 라우팅으로 Prefix cache 히트율 극대화 |
| LoRA Lifecycle | vLLM Multi-LoRA + Adapter Registry | 도메인 SLM 파인튜닝 → 핫스왑 배포, 팀별 어댑터 라우팅 |
| Agent 안전성 | NeMo Guardrails | 프롬프트 인젝션 방어, PII 유출 방지, 출력 검증 |
| GPU 파티셔닝 | DRA (Dynamic Resource Allocation) | MIG 단위 GPU 세밀 할당 (Self-managed 노드 필요) |
AWS Native(Bedrock)로 시작 → EKS Auto Mode로 자체 호스팅 확장 → EKS Capability(ACK, KRO, Argo)로 운영 자동화를 완성하는 점진적 도입이 권장됩니다.
참고 자료
– Amazon EKS Auto Mode Documentation
– Karpenter Documentation
– Bifrost AI Gateway
– Langfuse Documentation
– vLLM Documentation
– LangGraph Documentation