AWS 기술 블로그
사조시스템즈의 사내 ERP 데이터 기반 Agentic AI 구축 여정 – Strands Agents SDK와 Kiro 활용기
이번 블로그는 AWS DEVCRAFT 2026 (2026.3.26 ~ 4.9, AWS 코리아 오피스) 해커톤 프로그램에 참여하여 진행한 프로젝트를 기반으로 작성되었습니다. DEVCRAFT는 AWS SA와 고객사 개발팀이 함께 실제 비즈니스 과제를 2주간 집중 개발하는 프로그램입니다.
회사소개
사조시스템즈는 사조그룹의 계열사로 그룹의 전산업무를 총괄 관리·운영하는 IT 전문 기업입니다. 사업영역은 Logistics, IT사업, PM(Project Management)사업 부문으로 구성되어 있으며, 그룹 내 ERP·그룹웨어·물류 시스템 등 전사 IT 인프라의 개발과 운영을 담당하고 있습니다.
AI Agent를 개발하게 된 배경
사조시스템즈는 23년 하반기부터 현재까지 사조그룹 그룹웨어에서 임직원용 내부 챗봇을 운영하고 있습니다. 해당 챗봇은 내부 직원들이 AI 서비스를 쉽게 사용해 볼 수 있도록 제공하고 있는 서비스입니다. (이하, 그룹 내에서는 SAJO AI 라고 지칭하고 있습니다.) 25년 상반기에는 챗봇 서비스를 단독으로 분리하여 프로젝트를 진행하고 있고, 25년 하반기에는 RAG (Retrieval-Augmented Generation, 검색 증강 생성) 기능을 추가하여 사용성을 높여 오늘날까지 서비스를 운영 및 개발하고 있습니다. SAJO AI 에 검색 증강 생성 기능을 추가할 때에는 Amazon Bedrock 서비스를 이용하였습니다. 과거 다른 방식으로 검색 증강 생성을 이용하는 방식보다 운영 관리, 구현이 쉬워 서비스 도입을 성공적으로 마쳤다고 생각합니다.
RAG 이외에도 별도로 파일 첨부와 같은 추가 기능이나 UI/UX 개선에 대해서 고찰하고 고도화하고 있지만 더욱 더 높은 사용성과 업무에 도움을 줄 수 있는 챗봇 서비스를 제공하기 위해 어떤 기술, 기능에 대해서 학습하고 추가해야 할지 지속적인 고민에 놓여 있습니다. 다음 고민에 대한 해답으로 “특정 서비스의 데이터를 토대로 인사이트를 얻을 수 있는 챗봇을 생성하고 SAJO AI에 추가” 해보기로 했습니다. “특정 서비스의 데이터를 토대로 인사이트를 얻을 수 있는 챗봇” 이라는 의미를 각각 단계로 구현하기 위해, 필요한 영역을 다음과 같이 분해할 수 있었습니다.
- 현재 서비스가 MCP(Model Context Protocol), API(Application Programming Interface) 호출 등을 통해 다른 서비스와 연동을 할 수 있어야 함.
- 데이터를 사용자가 원하는 형태로 변경할 수 있어야 함.
- 사용자가 원하는 데이터를 추출 후 인사이트 생성이나 2차 가공을 할 수 있어야 함.
여기서 더 나아가 사용자가 생성한 인사이트에 대해서 메일 발송과 같은 기능까지 진행할 수 있다면 그룹 내의 생성된 매출, 매입, 전표, 주문 등의 데이터 요청에 따른 부서 간의 지연 시간을 해소할 수 있을 것으로 보였습니다. 다만, 데이터 종류에 따른 접근 권한 관리는 별도의 설계가 필요한 영역으로, 이번 프로젝트 기간에는 이 부분 보다는 기능 구현과 검증에 집중하였습니다. 위 영역을 살펴보니 저희가 이번에 구현하려고 하는 기능은 지금까지 개발·운영한 단순 챗봇에 고착되지 않았습니다. 기존 서비스와 상호작용을 진행하며, 여러 동작을 수행할 수 있는 “Agentic” 한 AI 서비스라고 볼 수 있어 지금부터는 “Agent” 라고 지칭하면서 글을 이어가도록 하겠습니다.
데이터 추출을 위한 API Server 생성
Strands Agents SDK를 이용하여 원하는 Agent를 생성하고 개발하기 전에 활용할 API를 생성해서 데이터를 가져오는 테스트를 진행했습니다.
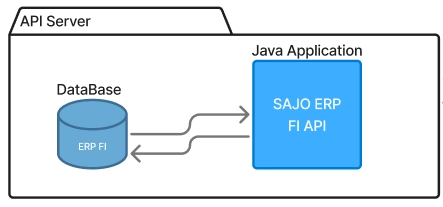
API Server (AWS DEVCRAFT FigJam)
일단 활용 가능한 범위 내의 데이터를 승인받아 그룹 내 분개장(회계 장부) 데이터를 토대로 API를 만들게 되었습니다. 분개장 데이터는 전표 데이터로 회사 혹은 회사 내의 사업장에서 각 회계 담당자들이 데이터를 사조의 ERP 서비스에 입력하여 관리하고 있는 데이터입니다.
저희 팀에서 기존에 사용하던 Spring Boot framework 사용하여 Java Application API Server 를 구성하였고, 데이터를 가져가기 전에 인증 및 인가를 진행해야 데이터를 요청할 수 있도록 보안 절차를 SAJO AI 서비스 로그인 후 JWT Token 을 발급하여 Client 에서 데이터를 Request 할 때마다 활용할 수 있도록 하였습니다. JWT Token 관련하여 언급할 이야기가 있으니 참고하시기 바랍니다.
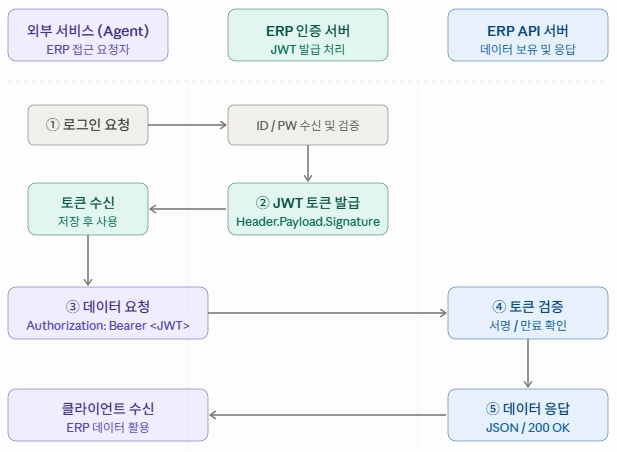
전체적인 서버 동작 아키텍쳐
이후 AI 데이터를 가져올 수 있는 Database와 Table 정보에 대해서 ERP FI(Financial Accounting, 회계) 모듈 담당자에게 소개를 받았고 Table 정보를 잘 명세 해 두었습니다. 확인해보니 컬럼의 개수가 20~30개는 되는 것 같아 불필요한 내용을 쿼리하여 추출하면 데이터 요청 시간도 길어질 뿐만 아니라 LLM에 데이터를 보내서 답변받을 때도 비효율적일 수 있어 컬럼 추상화도 진행했습니다. 여기까지 로그인 후 데이터를 가져갈 수 있는 서버는 올바르게 구성하였습니다.
Agent 생성 전 Project 세팅
Agent 를 생성하고 구현을 진행하려면 Strands Agents SDK에 대해서 정의 및 명세하고 있는 문서를 읽으면서 진행해야 하지만 현재는 AI 코딩 어시스턴트 도구들이 시장에 많이 출시되어 있습니다. 이번 프로젝트에서는 Kiro 를 사용해 보기로 하였습니다. Kiro는 VS Code IDE를 기반으로 만들어져 UI가 친숙하고, 현재 보고 있는 파일이나 전체적인 프로젝트의 흐름을 파악해서 코드를 생성해 주는 점이 좋았지만 이 기능은 다른 AI 코딩 어시스턴트와 크게 다르지 않았습니다.
하지만 SDD(Spec Driven Development) 라는 사상을 가지고 요구사항 명세 – 디자인 – 작업을 정리하고 단계별로 수행하면서 오류를 집어내고 나아갈 수 있게 하는 점이 Kiro 의 가장 두드러진 강점이었습니다. 저희 팀이 기존에 사용하던 AI 코딩 어시스턴트는 LLM 성능이 좋아짐에 따라 많은 Context를 유지할 수 있는 것은 장점이지만 모델 성능이 좋아지고 넓은 범위를 탐색해서 답변을 내려고 하므로 종종 요구사항보다 더 많은 것들을 고려하고 바꾸려고 해서 오히려 개발 속도가 저하되는 현상을 겪고 있었습니다.
이외에도 최근 이슈가 되고 있는 하네스도 적용할 수 있도록 steering에 코드 스타일, 깃 전략, 핵심 개발원칙 등을 사전에 정의하고 LLM이 답변을 생성할 때 참고할 수 있도록 한 점이 개발 진척도가 회귀하지 않는 것에 크게 도움이 되었습니다.
AWS에서 제공한 하네스
저희는 이러한 Kiro를 등에 업고 기능 개발에 몰두할 수 있었습니다.
Agent 개발 (AI Agent feat. ERP FI API)
Agent를 설계하기 전에 Strands Agents SDK에서 제공하는 Multi-Agent 협업 패턴에 대해서 간단히 알아보겠습니다. Strands Agents SDK는 크게 4가지 Multi-Agent 패턴을 지원하고 있으며, 자세한 활용 방법은 AWS DEVCRAFT 프로그램 교육 자료 워크샵에서 확인하실 수 있습니다.
1) Agents-as-Tools 패턴: 하나의 Orchestrator(관리자) Agent가 전문화된 하위 Agent들을 도구(Tool)처럼 호출하는 계층적 구조입니다. 팀장이 각 전문가에게 업무를 위임하는 것과 유사합니다. 각 하위 Agent는 특정 도메인에 집중하고, Orchestrator는 어떤 Agent를 언제 호출할지 결정합니다.
2) Swarm 패턴: 중앙 관리자 없이 여러 동급(peer) Agent들이 서로 직접 소통하며 협력하는 분산형 구조입니다. 단순한 개별 Agent들의 상호작용으로 복잡한 결과물을 만들어내고, 공유 메모리나 메시지 공간을 통해 조율됩니다.
3) Graph 패턴: Agent들을 노드(Node)로, 통신 경로를 엣지(Edge)로 정의하여 정보 흐름을 명시적으로 설계하는 구조입니다. Swarm과 달리 개발자가 Agent 간의 연결과 흐름 방향을 직접 설계하므로, 예측 가능한 실행 순서와 조건부 분기가 가능합니다.
4) Workflow 패턴: 고전적인 파이프라인처럼 Agent들을 사전 정의된 순서대로 실행하는 구조입니다. 작업 순서와 의존성을 명시적으로 관리하며, 각 Agent의 출력이 다음 Agent의 입력으로 전달됩니다.
저희 프로젝트에서는 최종적으로 Agents-as-Tools 패턴을 선택했습니다. 그 이유는 저희가 필요로 하는 하위 Agent들(Excel Agent, Mail Sender Agent, Report Agent)이 서로 데이터를 주고받을 필요가 없고, Supervisor의 지시에 따라 각자의 역할만 수행하면 되는 구조였기 때문입니다. Swarm은 Agent 간 상호 소통이 불필요한 저희 케이스에는 적합하지 못한 구조였고, Graph 패턴은 초기 설계에서 시도했으나 Context 관리의 복잡도가 높아 더 단순한 Agents-as-Tools로 전환하게 되었습니다. 결과적으로 초기 설계와 달라지게 되는, 구현을 하면서 겪었던 일들로 토대로 자세히 설명 드리도록 하겠습니다.
프로젝트 기간 동안 투입 가능한 인원이 적어 두 명이 나누어 개발을 진행하게 되었고, 처음에는 크게 두 영역으로 나뉘어 설계하고 각각의 Agent를 개발하여 Merge 하는 방식으로 하였습니다. 각각의 영역은 아래의 사진과 함께 자세히 알아보도록 하겠습니다.

전체적인 흐름 설계. 왼쪽 – 1번 영역, 오른쪽 – 2번 영역 (FigJam)
영역 1 – 사용자의 input을 토대로 Plan을 세워 승인받고 데이터를 조회 (인증 후 조회)
첫번째 영역에 대해서 설계부터 설명하면 큰 틀은 Planner Agent가 Agent 실행 계획을 세우고 사용자에게 승인을 받은 이후 데이터가 필요한 경우 Data Agent에 요청하여 데이터를 내려받는 것을 진행하려고 했습니다.
계획을 세우는 Planner Agent 와 같은 경우 Context를 많이 담을 수 있고 확장된 사고가 가능한 고성능 모델을 사용하는 것이 효과적입니다. 하지만 사용자는 간단한 질문을 통해서 Agent에게 요청할 내용을 정리할 수 있기 때문에 Planner Agent 앞단에 Coordinator Agent를 생성하여 경량화 된 모델을 사용하여 토큰을 낭비하지 않도록 하였습니다.
이후에는 Planner Agent가 계획을 세우고 계획을 승인하는 경우에는 Data Agent로 진행하여 분개장(FI) 데이터를 가져올 수 있게 하였고, 계획이 괜찮지 않으면 Plan Reviewer Agent가 사용자로 하여금 다시 원하는 계획을 세울 수 있도록 유도하도록 했습니다.
위와 같은 동작을 수행하기 위해서 Graph라는 패턴을 적용하였으며, Agent들은 Node로 되어있고 해당 Agent들을 잇는 Edge로 이어져 있습니다. 각 Node에서 동작을 수행하면 이어져 있는 Agent에 조건부로 런타임에 동적 라우팅이 가능합니다.
현재까지의 설계를 토대로 Kiro 와 Spec 기반 개발을 진행하여 정상적으로 구현을 이어나갔고 승인 절차는 IDE에 있는 터미널로 승인할지 승인하지 않을지 에 따라서 계획을 다시 세우는 것 까지 확인할 수 있었습니다.
영역 2 – 조회된 데이터를 토대로 사용자의 input을 해석하여 2차 가공이 필요하면 추가로 동작 (Excel이나 Mail Sender와 같은 동작)
다음으로 설계된 2번째 영역에 대해서 설명한 후 구현 과정을 다루겠습니다.
Data Agent로 인해서 데이터를 생성, 조회하게 되는데 이에 대해 로컬에 파일로 생성할 것인가 변수에 담아서 LLM 에 직접 Request 할 때 파라미터로 보낼 것인가에 대해서 고찰이 있었습니다.
이와 같은 사안에 대해서는 ‘LLM에 수 만건 데이터를 보내도 되는가?’ 에 대한 답변을 받아보면 쉽게 해결할 수 있습니다. 회계 데이터와 같은 경우 컬럼이 10개 일 때, 특정 사업장의 데이터를 1개월 정도만 조회해도 수백 건에서 수천 건 정도 되었습니다. 그렇다면 Postman 으로 확인했을 때 JSON 데이터가 수 천 Row가 생기는 것을 볼 수 있습니다. 저희는 이와 같은 사안은 모든 데이터를 보내지 않고 파일로 생성 후 경로를 return 하도록 했습니다. 이렇게 했을 때 전체 데이터에 대한 분석, 파일화(Excel) 이 필요할 때는 Python 도구를 사용 할 수 있어 전체 데이터를 불필요하게 LLM 에 던져 생기는 Context Window 압박이나 비용 증가 측면에서 이점을 볼 수 있습니다.
구현에 적용된 패턴을 살펴보겠습니다. Orchestrator (Agents-as-tools) 패턴을 적용하였고 Supervisor Agent가 생성된 데이터를 용도에 맞는 Agent에 전달하는 과정을 할 수 있게 구현했습니다. 각 Agent 들은 Supervisor의 요청에만 응답할 수 있으며 Agent 끼리 소통하는 것은 지양하는 패턴입니다.
- 여기서 왜 각 Agent 들은 소통할 필요가 없는가?
Mail Sender, Excel Creative 를 담당하는 Agent 들의 의미를 살펴보면 됩니다. 종단 Agent들의 특징을 보면 데이터를 이미 정제하였고 같은 Level의 다른 Agent 들로 하여금 받을 Data나 형태가 없습니다. 따라서 ‘Supervisor의 지시에 따라 올곧게 역할만 다하면 되기 때문에 Orchestrator 패턴을 이용했다’ 라고 볼 수 있습니다. - Data를 가져오는 Agent는 Supervisor가 같이 수행하면 되지 않을까?
AWS 기술 블로그 ‘Deep Insight 아키텍처로 배우는 실전 설계’를 토대로 정리하면 Supervisor Agent는 Orchestration 역할만 하는 것을 지향해야 한다고 합니다. Data Agent의 역할만 해도 타 서비스에 로그인해야 하고 로그인 이후 데이터를 가져와서 JSON 파일까지 생성해야 합니다. 여기까지만 해도 역할이 많습니다. 위와 작업들은 Data Agent에게 위임하여 필요한 상황에 호출하여 사용하는 것이 효과적입니다. 결국 Supervisor 는 필요에 의해 다음 layer 에 존재하는 Agent만 Tools(도구)로 활용하는 것에 집중하여 Context를 유지할 수 있도록 해줘야 하기 때문에 역할 분리를 해주었습니다.
예상대로 진행되지 않았던 부분 – Context 공유의 중요성
영역 1과 영역 2를 각각 개발 진행한 후 하나로 Merge를 하면서 문제점들이 생겨났습니다. Context 관리, 유지, 공유를 고려하지 않아 Assistants가 바라보고 있는 개발 환경 명세들에 대해서 다른 부분이 생겨났고 결국 다음과 같은 상황을 초래하였습니다.
첫 번째는 영역 1에서는 IDE의 터미널을 통해서 사용자에게 Plan에 대해서 승인/거절 의사를 받아서 계획을 다시 세울지 이어서 진행할지를 판단하였는데 영역 2 에서는 Python 라이브러리인 Streamlit 을 사용하여 웹에서 호스팅한 Client 에서 승인/거절 의사를 넣으니 정확하게 동작하지 못했습니다. 이는 Streamlit 을 이용하려면 영역 1에서 세션(session)에 저장하는 설계가 필요했습니다. Plan을 생성하고 결과를 멈춘 상태에서 승인/거절 의사를 받은 후 세션에 현재 상태가 승인되었다는 결과 값을 가지고 다음 Node에 가야 정상 동작을 하게 되어 있었습니다. 터미널에서는 바로 승인 후 상태 보존을 할 수 있었는데 해당 부분이 누락된 것이었습니다.
두 번째로는 JWT Token 에 대한 정보 누락이 있습니다. 연결된 서비스 환경에 대한 Context가 부재했습니다. API 를 개발할 때 설정한 JWT Token의 expiration 시간은 수시간 정도이고 그 시간이 지난 이후에는 401 Error를 발생하게 서버 설정은 해 두었습니다. 이러한 설정에 대한 것은 API 문서와 개발자는 알고 있지만 AI는 알 수 없으므로, Error 처리와 Response HTTP 상태 코드 명세를 FI_Data Agent(회계 데이터 추출 Agent)에게 제공했어야 했습니다. Agent는 에러만 확인한 후 권한에 대한 이야기를 먼저 꺼냈습니다. 실제로는 로그인에 대한 발급된 Token이 만료된 것이었습니다.
이러한 문제들로 고군분투했던 경험들 덕분에 개발자 간의 Context 유지, 관리가 중요하다는 것을 알게 되었습니다. 그리고 환경 설정, 모듈 연결(MCP, API) 등이 있을 때마다 Agent가 참조할 수 있는 Memory와 같은 것을 계속 명세하면서 진행 해야 했다는 것을 느꼈습니다.
최종 에이전트 구성
남은 기간 안에 프로젝트 목표로 설정한 내부 서비스의 데이터로부터 AI가 여러 동작을 할 수 있는 Agent를 만들어야 했습니다. 설계를 아래와 같이 수정하였습니다.
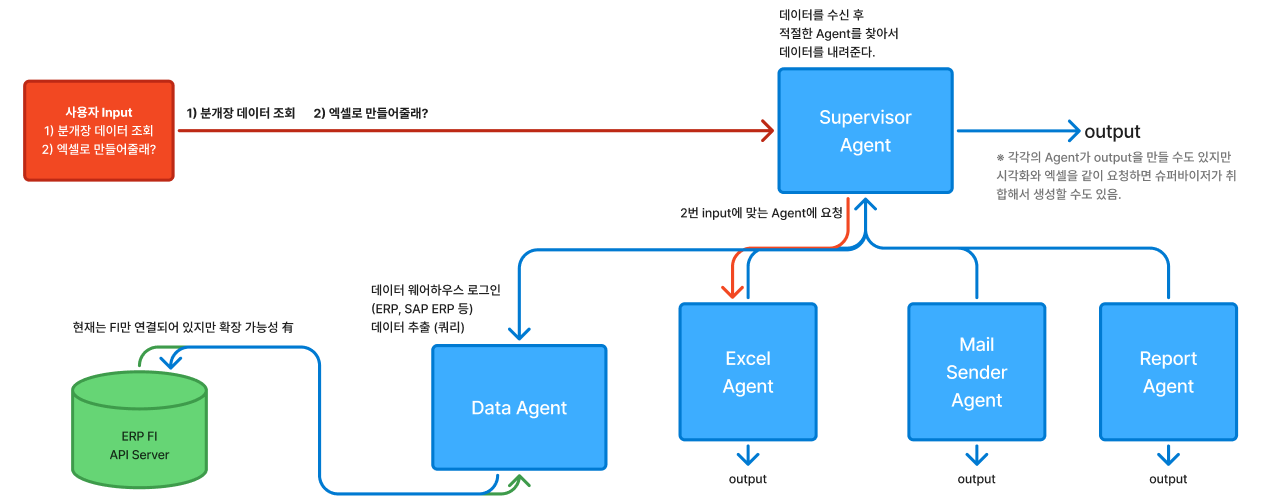
현재 원하는 서비스는 Plan을 생성해서 Agent의 동작을 명세하고 순차적으로 결과물을 만들 필요는 없다고 판단하여 Supervisor Agent를 통해서 각 Agent 들에게 동작을 지시하는 것만 할 수 있도록 변경하였습니다.
단, Data Agent 는 데이터가 필요한 경우 Supervisor Agent 를 통해서 호출할 수 있도록 하였습니다. 데이터를 추출 후 JSON 파일로 생성하면 경로를 Return 받게 되는데 해당 경로를 가진 상태에서 Excel 이나 Mail Sender 와 같은 작업을 사용자에게 묻고 사용자가 추가로 지시한 Input 내용에 따라서 분기할 수 있도록 하여 정상적으로 동작할 수 있었습니다.
마치며 – 프로젝트 인사이트와 현업 피드백
이번 프로젝트를 진행하면서 가장 크게 느낀 점은 Agent 개발 시 Context 유지·관리의 중요성이었습니다. Agentic AI를 구현하는 많은 팀이 비슷한 과제를 경험할 것이라 생각합니다.
저희가 제공해 드리고 있는 SAJO AI 서비스를 “Agentic”하게 그리고 더욱 더 효용성 있는 서비스로 발전하는 데에 테스트해볼 수 있어서 뜻깊은 시간이었습니다. 현재 테스트가 서비스 운영 Level로 고도화가 진행된다면 Amazon Bedrock AgentCore 를 이용하여 모니터링, 정성·정량 평가를 통해 고품질의 답변을 내는 데에도 기여할 계획입니다.
현업 담당자 인터뷰 – 정량적 기대 효과
회계 데이터 기반 챗봇을 제공할 경우, 현업 담당자 인터뷰를 통해 다음과 같은 정량적 효과를 예상할 수 있었습니다.
- 차대 균형 검증 작업: 기존 ERP에서는 전표 자체의 대차를 맞춰서 등록하지만, 담당자가 이를 확인하는 데 약 30분이 소요되었습니다. Agent 기반으로 전환 시 30~40초 내외로 단축됩니다.
- 회계 데이터 분석 작업: 보고 유형에 따라 기존에는 1~2시간이 소요되었으나, Agent 기반으로는 약 1분 이내에 완료할 수 있었습니다.
추가로 실제 현업 담당자의 요청을 받아 주요 매출 거래처·매입 거래처 상위 건 및 계열사 간 매출처/매입처 분석을 수행하였습니다. 월 기준 수천 건의 데이터가 존재했으며, JSON 데이터를 Pandas로 처리하여 Agent 기반 3분 이내에 분석 결과를 확인할 수 있었습니다.
아래는 구현한 Agent 에 대해서 간략하게 소개하겠습니다.
먼저 SAJO AI 그룹웨어 챗봇 화면입니다.
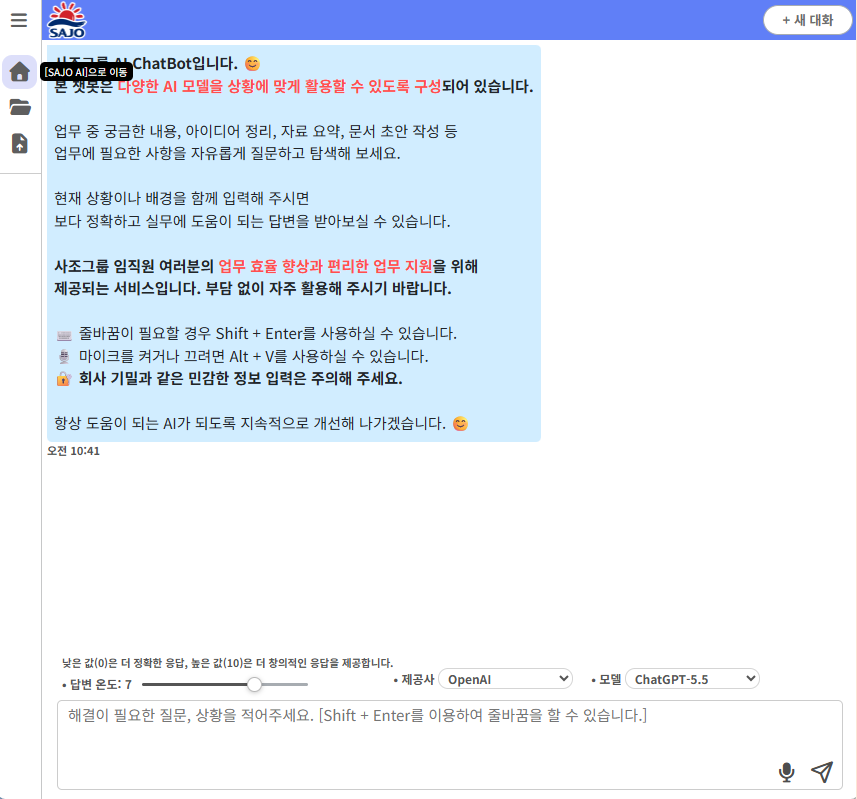
현재 운영 중인 SAJO AI 서비스
다음은 이번 DEVCRAFT에서 구현한 Agent 프로토타입 화면들입니다.
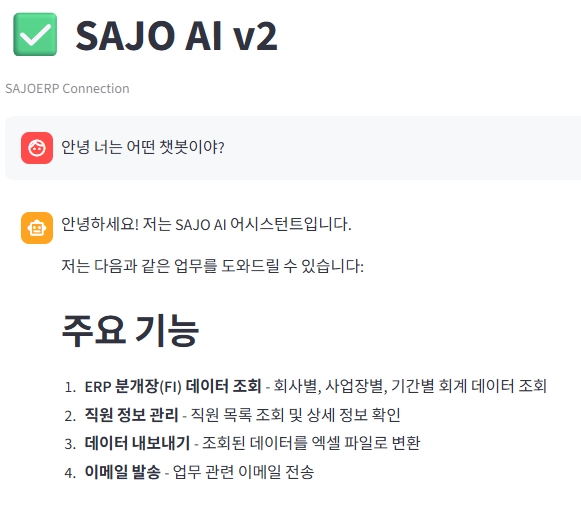
Streamlit UI 사용 – 챗봇화면 Load

분개장 조회를 위한 필수 조건(파라미터)를 받기 위한 모습
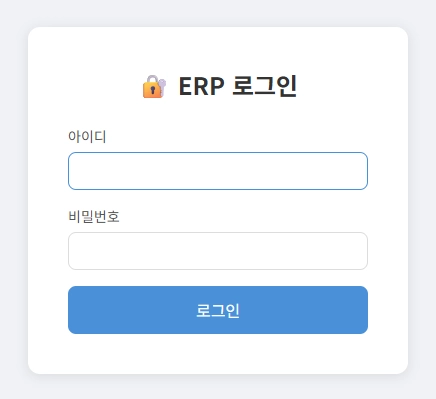
AI가 요청한 로그인 화면
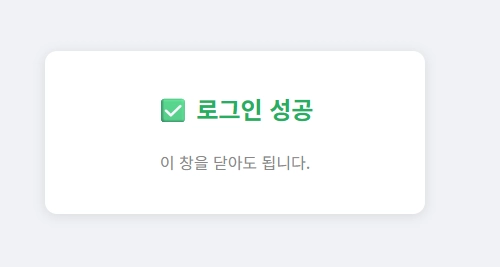
로그인 성공 시 (Token 발급)
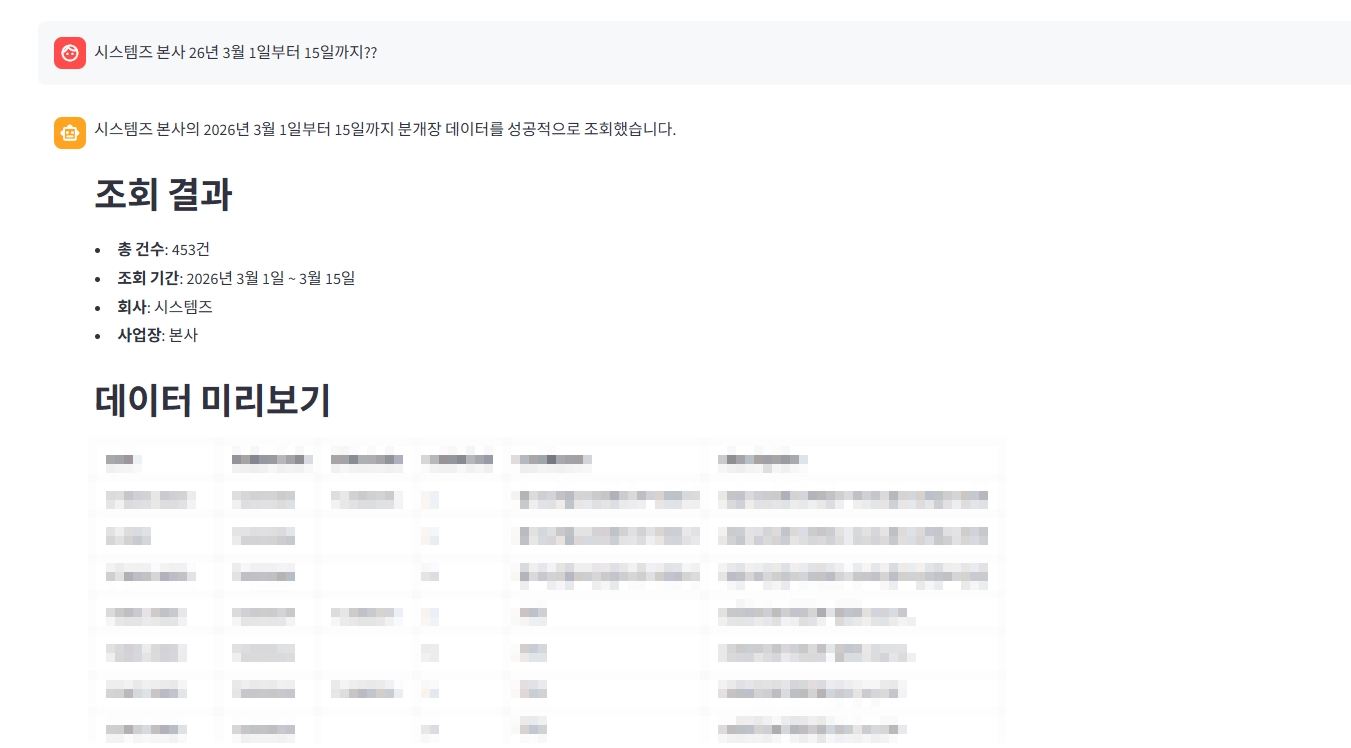
로그인 후 데이터 정상 조회 시 화면
정상 조회 시 JSON 파일 생성

계정과목별 데이터 분석
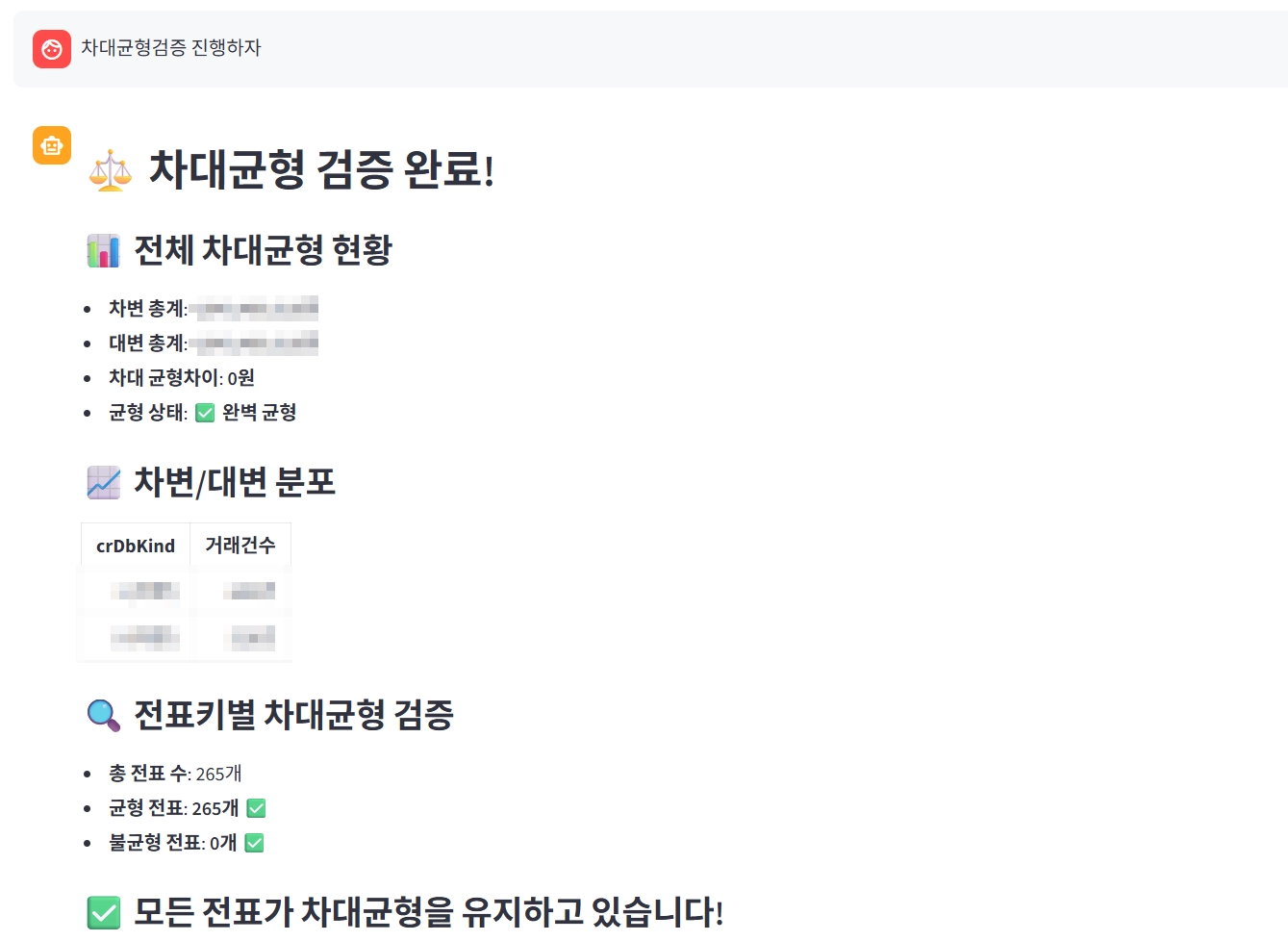
차대 균형 검증
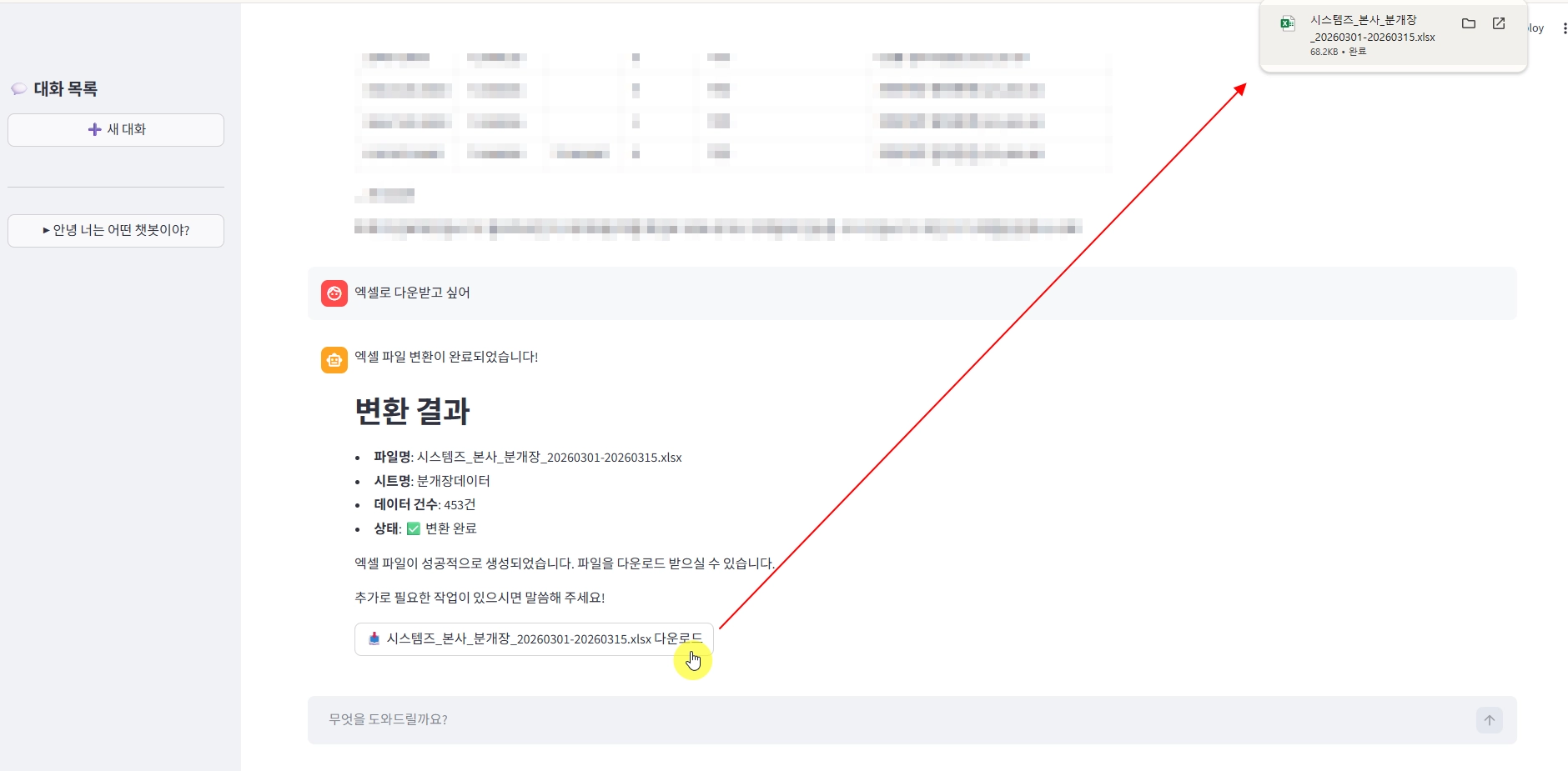
사용자 추가 요구에 따른 Excel 파일 생성
향후 계획
이번 프로젝트에서 검증한 AI Agent 기능을 현재 운영 중인 SAJO AI 플랫폼에 통합하거나 별도의 업무 전용 챗봇으로 파생하여 임직원에게 제공할 예정입니다.
- SAJO AI 플랫폼 통합: 현재 Streamlit으로 구현한 프로토타입을 기존 SAJO AI UI에 통합하여 직원들에게 제공할 예정입니다.
- UI/UX 고도화: 현재 Streamlit 기반의 테스트 UI에서 벗어나, 기존 SAJO AI의 채팅 인터페이스에 Plan 승인/거절, 데이터 미리보기, 파일 다운로드 등의 Agent 전용 UI 컴포넌트를 추가할 계획입니다.
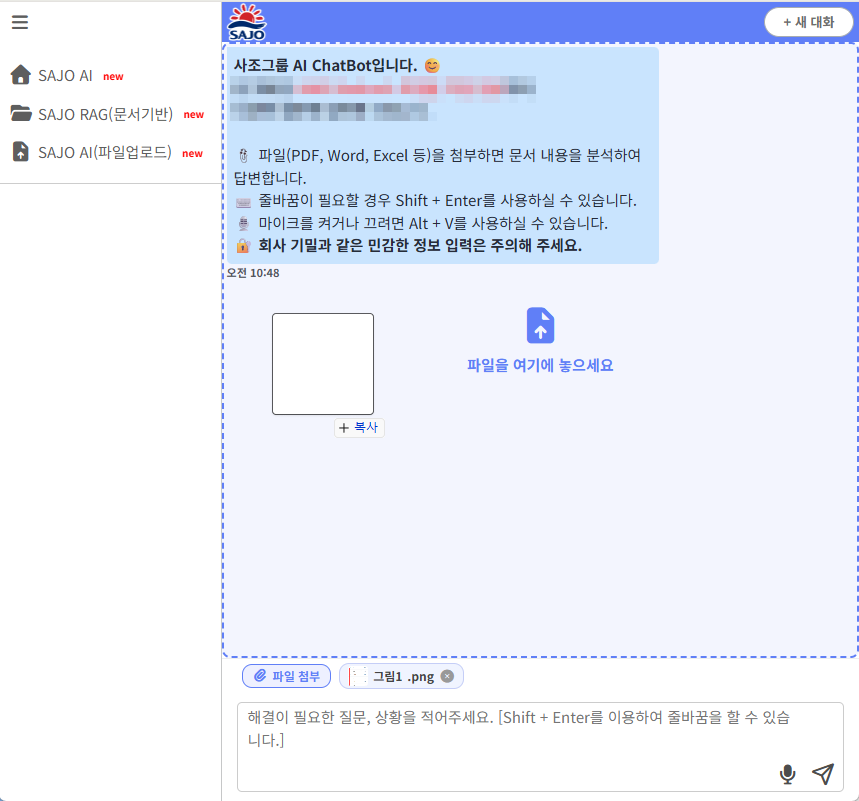
실제 SAJO AI – 파일 첨부 기능
- 모니터링 및 평가: Amazon Bedrock AgentCore를 활용하여 Agent 응답의 정성정량 평가 체계를 구축하고, 지속적인 품질 개선을 진행할 예정입니다.
- 데이터 확장: 현재 회계(FI) 모듈에 한정된 데이터 연동 범위를 인사(HR), 생산, SAP ERP 모듈, 주문, WMS 등 다른 사조그룹의 서비스의 데이터를 통해서 확장하여 더 넓은 범위의 업무를 지원할 계획입니다.
업무에 맞는 Agent 를 생산하고 제공하려면 권한과 같은 설계, 권한 관리 시스템 구축도 필요한 상황입니다. 추후에는 Agent 개발과 동시에 권한 서비스도 같이 개발될 예정이며 가장 중요한 업무에도 이용할 수 있는 수준으로 답변 정확도를 높이는 튜닝 작업도 지속적으로 할 예정입니다.



