AWS 기술 블로그
Amazon SageMaker Unified Studio에서 Cross-Account Amazon Redshift Data Sharing 거버넌스 패턴 검증
도입 배경
소스 컴퓨트를 격리하면서 다른 계정이 Redshift로 쿼리하게 만들 수 있을까요? 한국 대형 리테일 그룹의 데이터 플랫폼 통합 프로젝트에서 맞닥뜨린 질문입니다. 자회사별로 Amazon Redshift와 ML 워크로드가 분리 운영되어 그룹 차원의 통합 분석과 AI/ML 활용에 사일로가 발생하던 환경이었고, SageMaker Unified Studio(이하 SMUS)로 그룹 단위 거버넌스를 통합해야 하지만, 동시에 각 자회사의 데이터 소스 컴퓨트는 다른 자회사 워크로드의 영향을 받지 않아야 했습니다. 이 환경에서 동시에 만족시켜야 하는 요건은 네 가지입니다.
- 소스 데이터의 컴퓨트는 외부에 노출되지 않는다
- 데이터는 다른 계정의 분석 팀이 안전하게 조회할 수 있다
- 데이터 카탈로그에서 자산을 검색하고, 게시(publish)하고, 구독(subscribe) 워크플로우로 거버넌스할 수 있다
- 구독한 쪽은 Amazon Redshift 엔진으로 직접 쿼리한다
소스 Redshift 컴퓨트에 영향 주지 않으면서 도메인 계정 컨슈머가 쿼리하게 만드는 4가지 구성을 직접 검증했고, 오직 하나의 구성만이 네 요건을 모두 충족했습니다. 같은 요건을 검토하는 독자분들이 동일한 시행착오에 시간을 쓰지 않으시도록, 본 글은 다음 순서로 정리합니다.
- 권장 아키텍처와 작동 원리(TL;DR)
- 다른 세 가지 직관적 시도가 막히는 지점
- SMUS의 cross-account 설계 원칙(Publisher와 소스 데이터의 계정 관계)
- 권장 패턴 상세 구현
- 운영 고려사항과 트레이드오프
TL;DR: 권장 아키텍처
본문 전체에서 두 계정을 다음과 같이 부릅니다. 소스 계정(Source Account)은 운영용 Amazon Redshift 클러스터를 보유한 계정이며, 그 컴퓨트는 외부 워크로드에 노출하지 않는 것이 본 시나리오의 전제입니다. 도메인 계정(Domain Account) 은 SMUS 도메인이 생성되고 Consumer 프로젝트가 위치하는 계정입니다.
권장 패턴은 Publisher 프로젝트를 소스 계정에 배치하고, Consumer 프로젝트는 도메인 계정에 두는 구조입니다. 다계정 환경에서 단일 표준 profile로 이를 운영하려면 Account-agnostic Project Profile(필요 시 Account Pool과 결합)을 함께 사용합니다.
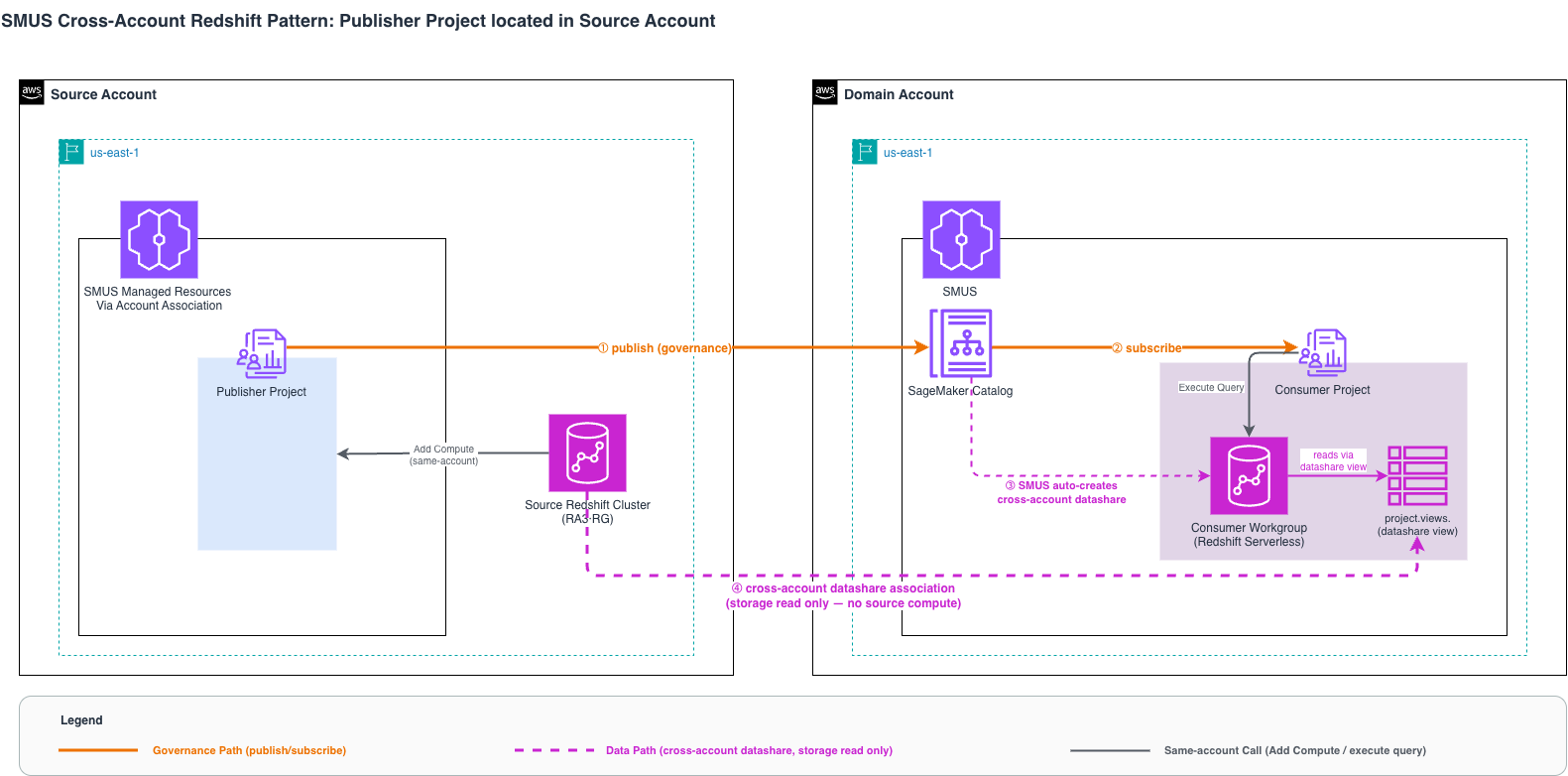
Figure 1: 권장 패턴의 두 메커니즘. 거버넌스 경로(주황, SageMaker Catalog publish/subscribe)와 데이터 경로(분홍 점선, cross-account datashare association)가 같은 trust boundary 안에서 분업합니다. Publisher 프로젝트와 소스 cluster가 같은 계정에 있어 datashare grant 권한이 자체 행사되고, 컨슈머 쿼리는 자기 워크그룹에서 실행되므로 소스 cluster에는 storage read만 발생합니다.
이 구조가 네 요건을 한꺼번에 충족하는 이유는 거버넌스와 컴퓨트 격리를 각각 담당하는 두 메커니즘이 서로의 전제를 깨뜨리지 않고 맞물려 동작하기 때문입니다.
- 메커니즘 1 – 거버넌스 경로 (SMUS cross-account 구독). 컨슈머가 자산을 구독하고 Publisher가 승인하면, SMUS가 cross-account datashare를 자동 생성하고 컨슈머 namespace에 associate합니다. 이때 Publisher 프로젝트의 IAM role이 소스 클러스터와 같은 계정에 있으므로 publisher가 소스 클러스터에 대한 datashare 생성·grant 권한을 그대로 행사할 수 있습니다. 즉 publish/subscribe 거버넌스 워크플로우가 한 trust boundary 안에서 완결됩니다.
- 메커니즘 2 – 컴퓨트 격리 경로 (Redshift data sharing). datashare로 grant된 view(project.views.)는 컨슈머의 자기 워크그룹 컴퓨트에서 실행되고, 소스 클러스터에는 storage read만 발생합니다. 데이터를 복제하지 않고도 소스 컴퓨트 부하 0을 유지하는 Redshift data sharing의 본래 설계가 그대로 동작합니다.
메커니즘 1이 “누가 자산을 publish하고 누가 subscribe할 권한을 갖는가”를 정의하고, 메커니즘 2가 “쿼리는 어느 컴퓨트에서 실행되는가”를 정의합니다. 두 메커니즘이 같은 자산을 두고 충돌 없이 분업하기 때문에, 거버넌스는 SMUS 안에서 완결되고 소스 컴퓨트는 그대로 격리됩니다.
| 요건 | 권장 패턴에서의 결과 |
|---|---|
| 소스 컴퓨트 격리 | 충족. 컨슈머 쿼리는 자체 워크그룹에서 실행, 소스에는 datashare read만 발생 |
| 다른 계정 분석 팀의 안전한 조회 | 충족. SMUS subscribe 워크플로우 + cross-account datashare로 권한 부여 |
| SageMaker Catalog publish/subscribe | 충족. 자산 등록, 게시, 구독 워크플로우, business glossary 모두 사용 가능 |
| 컨슈머가 Redshift 엔진으로 쿼리 | 충족 |
다른 세 구성이 안되는 이유
설계 원칙을 모르고 접근하면 다음 세 가지 구성을 차례로 시도하게 됩니다. 모두 어느 한 지점에서 막히는데, 막히는 지점이 서로 달라 그 차이를 이해하면 권장 패턴이 왜 유일한 답인지가 보입니다.
구성 1: 수동 Cross-Account Datashare에 Add Compute로 연결
가장 직관적인 구성입니다.
- 소스 계정의 Redshift에서 도메인 계정의 Redshift로 cross-account datashare를 수동으로 생성
- 도메인 계정의 Redshift가 datashare를 association하면 외부 데이터베이스로 인식됩니다
- 도메인 계정의 SMUS 프로젝트에서 그 Redshift를 Add Compute로 연결
데이터 자체는 Redshift 쿼리 에디터에서 잘 보입니다. 그러나 카탈로그 진입에서 막힙니다.
Datashare로 도메인 계정에 들어온 데이터베이스는 CREATE DATABASE … FROM DATASHARE 구문으로 만들어진 datashare 기반 database(datashare consumer database)입니다. SMUS Data Source는 공식 docs 기준 “Amazon Redshift data warehouse의 database tables and views의 technical metadata를 import”하는 메커니즘으로 정의되며, datashare 기반 database의 객체는 자산 자동 등록 대상에서 제외됩니다. SageMaker Catalog의 publish/subscribe 워크플로우에 진입할 수단이 없는 셈입니다.
차단 지점: SMUS Data Source는 외부 객체(datashare 기반 DB)를 자산으로 import하지 않음 → publish 불가
구성 2: SMUS Federated Catalog 경로 (Data → Connection)
이 구성은 SMUS의 Account Association 기능을 토대로 합니다. 도메인이 다른 AWS 계정을 자기 거버넌스 경계 안으로 포함시키는 기능이며, RAM 공유 + 대상 계정 owner 수락 + blueprint 활성화의 3단계로 구성됩니다(공식 docs).
이 토대 위에서 SMUS의 Data → Add → Connection 경로로 소스 Redshift를 federated 형태로 끌어다 쓰는 접근입니다.
- 소스 계정을 SMUS 도메인에 associated account로 등록
- 소스 Redshift를 Data → Connection으로 등록 (Cross-account access role + Secrets Manager 사용)
- SMUS 내부에 federated catalog가 자동으로 생성됩니다
여기서 SMUS Query Editor에서 Athena 엔진 쿼리는 가능합니다. 그러나 SageMaker Catalog publish는 별개의 진입점이며, 이 federated catalog는 그 진입점에 후보로 노출되지 않습니다.
Create Amazon Redshift data source 공식 docs는 두 진입점을 명시적으로 분리합니다.
“Adding a data source in the project catalog makes it possible to publish that data into the Amazon SageMaker Catalog. To add a data source for analyzing and editing within your project, use the Data page of your project.”
즉 publish 진입점은 Manage → Catalog management → Data sources이고, Data → Connection은 단순 데이터 접근/탐색 용도입니다. 본 검증에서 Catalog management → Data Source 생성 화면의 Connection 드롭다운에 Data → Connection으로 만든 federated catalog가 후보로 노출되지 않음을 확인했습니다.
추가 검증으로, federated catalog 트리에서 직접 테이블을 우클릭해 “Publish to Catalog”를 시도하면 다음 에러가 발생합니다.
Error - Data source id is not defined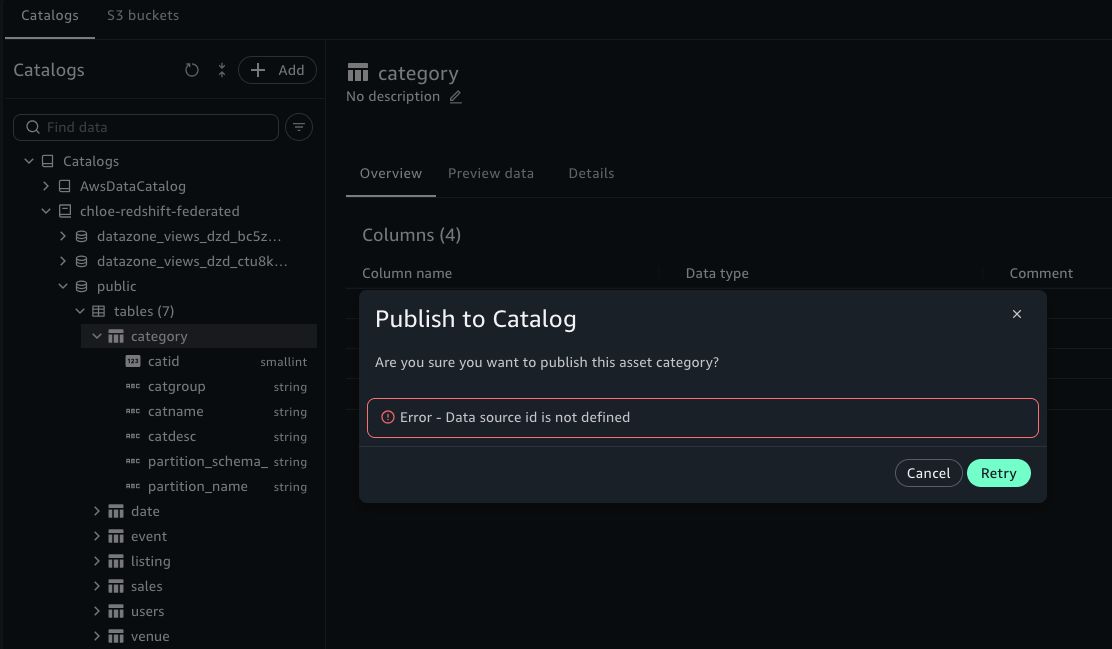
Figure 2: federated catalog의 category 테이블을 우클릭해 “Publish to Catalog”를 시도하면 Error – Data source id is not defined 에러로 차단되는 모습입니다. 컬럼 metadata(catid, catgroup 등)는 트리에 정상 노출되지만, publish의 prerequisite인 data_source_id가 부여되어 있지 않습니다.
테이블 metadata(컬럼 정보 등)는 UI 트리에 정상 노출되지만, publish flow의 prerequisite인 data_source_id가 federated catalog 테이블에는 부여되지 않으므로 SMUS가 자산 등록 자체를 거부합니다. schema metadata read는 가능하지만 publish는 불가라는 구조적 차단이 한 줄의 정확한 에러 메시지로 드러나는 지점입니다.
더 근본적으로, federated catalog의 작동 방식 자체가 JDBC pass-through 모델입니다. Athena가 federated catalog를 통해 Redshift 자산을 쿼리하면 connector Lambda가 JDBC로 소스 Redshift를 호출하므로 매 쿼리가 소스 컴퓨트에서 실행됩니다(참고: Athena Redshift connector docs). 즉 publish 가능 여부와 무관하게 컴퓨트 격리 요건이 구조적으로 충족되지 않습니다.
이 동작은 검증으로 정확히 확인됩니다. 컨슈머 portal의 Athena Query Editor에서 다음 쿼리를 실행하면,
SELECT * FROM "<federated-catalog>"."public"."category" LIMIT 10;소스 클러스터의 STL_QUERY에 같은 시점, 컬럼 단위까지 동일한 쿼리가 잡힙니다.
SELECT "catid", "catgroup", "catname", "catdesc"
FROM "public"."category" LIMIT 10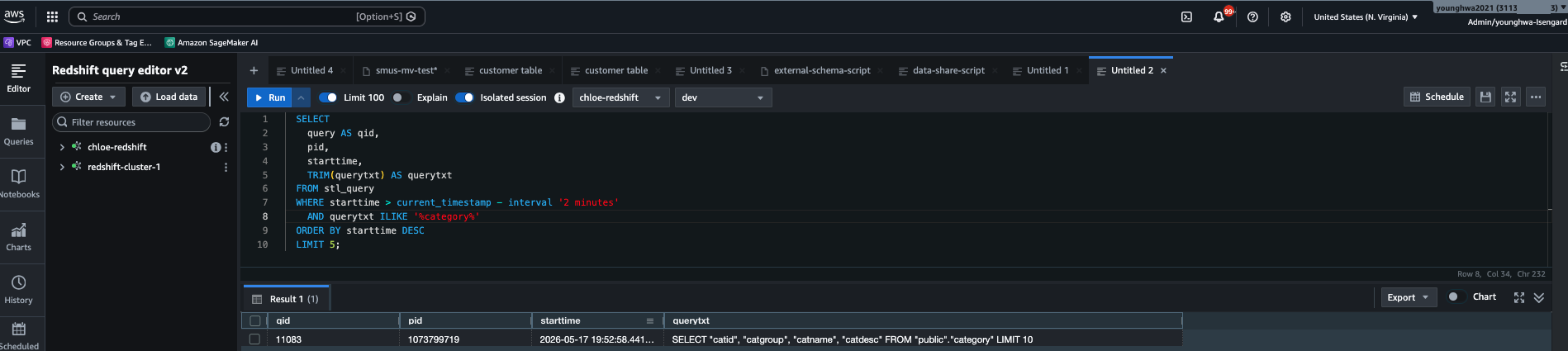
Figure 3: 컨슈머 Query Editor에서 실행한 federated 쿼리가 소스 계정의 STL_QUERY에 동일한 컬럼 단위까지 그대로 기록되어, 쿼리 처리가 소스 컴퓨트에서 일어났음을 보여줍니다.
Athena의 SELECT *이 federated catalog의 JDBC 레이어에서 명시적 컬럼 projection으로 전개되어 그대로 소스 클러스터로 위임됩니다. 즉 컬럼 레벨 쿼리 처리까지 소스 컴퓨트에서 실행되며, “소스 컴퓨트는 외부에 노출되지 않는다”는 대전제가 정면으로 깨집니다.
차단 지점: 자산화 진입점이 분리되어 있어 Data → Connection으로는 publish 불가(Error – Data source id is not defined). 동시에 JDBC pass-through로 컴퓨트 격리도 위배.
구성 3: Add Compute Cross-Account에 Publisher를 도메인 계정에 배치
여기까지 읽고 나면 다음 구성이 자연스럽게 떠오릅니다. SMUS가 datashare를 자동으로 만들어주는 경로(Add Compute 기반 native pub/sub)를 사용하면서, Publisher 프로젝트가 cross-account access role로 소스 클러스터를 가리키게 하는 구성입니다.
- Publisher 프로젝트를 도메인 계정에 생성
- 소스 계정에 SMUS용 access role을 두고 trust policy로 도메인 계정 프로젝트 role을 신뢰
- Publisher 프로젝트에서 Add Compute로 소스 클러스터를 연결할 때 cross-account access role을 사용
- Data Source Run으로 자산 import, publish, Consumer 프로젝트에서 subscribe
이 구성은 가장 헷갈리는 케이스입니다. 거의 모든 단계가 성공하기 때문입니다. Add Compute, Data Source Run, 자산 publish, 컨슈머 subscribe 요청, Publisher 승인까지 모두 정상 동작합니다. 막히는 곳은 마지막 권한 부여 단계입니다.
Cluster redshift-cluster-1 not found.
(Service: Redshift, Status Code: 404)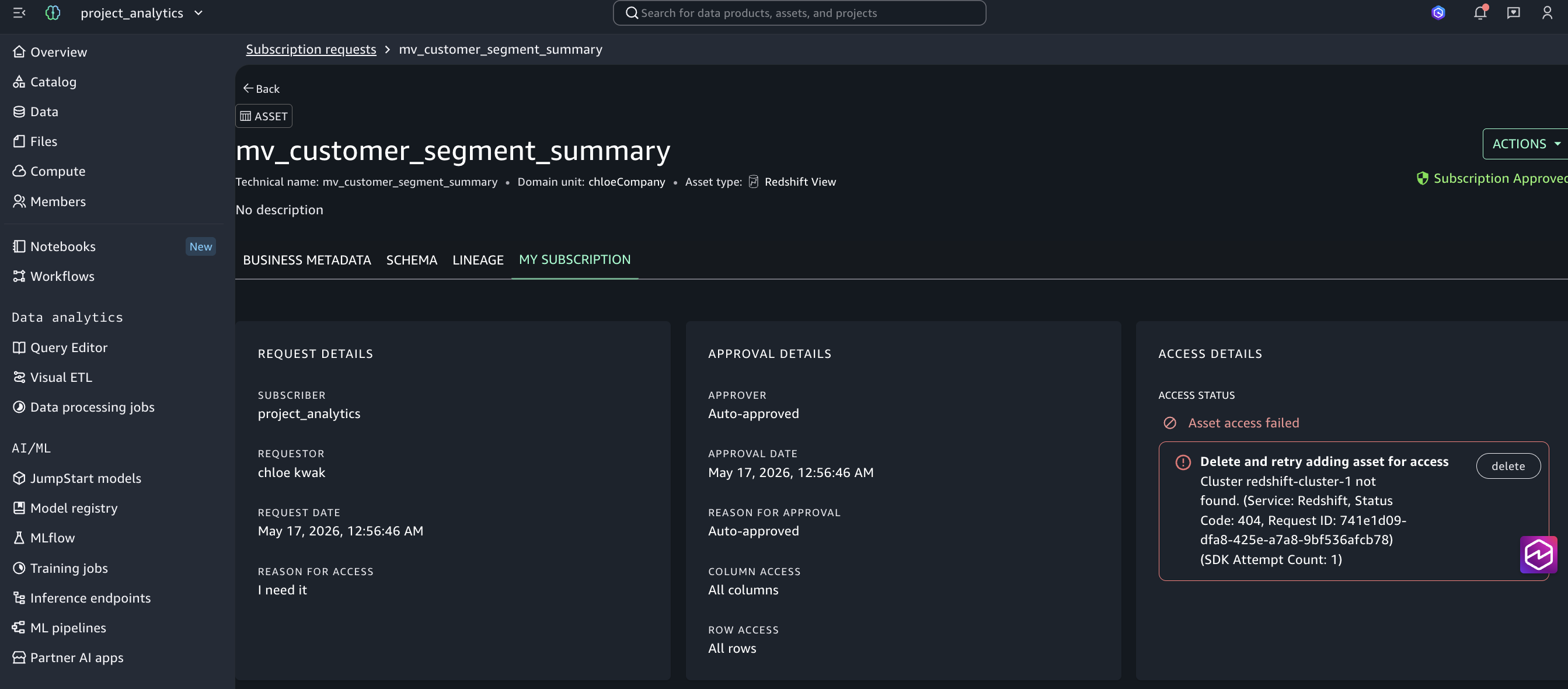
Figure 4: 구성 3에서 구독은 “Subscription Approved”로 통과했지만 마지막 권한 부여 단계가 Cluster redshift-cluster-1 not found (404)로 실패한 모습입니다. 두 상태가 같은 화면에 공존하는 비대칭이 본 구성의 핵심 증상입니다.
권한이나 태그 문제로 보이지만, aws datazone get-subscription으로 자산 메타데이터를 확인하면 결정적인 단서가 나옵니다.
"RedshiftViewForm": {
"accountId": "<도메인 계정 ID>", ← 잘못 기록됨
"redshiftStorage": {
"redshiftClusterSource": {"clusterName": "redshift-cluster-1"}
}
}Connection 메타데이터에는 cluster ARN이 소스 계정 namespace로 정확히 기록되어 있는데, 자산 메타데이터에는 publisher 프로젝트가 속한 계정(도메인 계정)이 owner로 기록됩니다. 마지막 권한 부여 로직은 이 자산 메타데이터를 읽고 도메인 계정에서 클러스터를 찾으려 하기 때문에 404가 발생합니다.
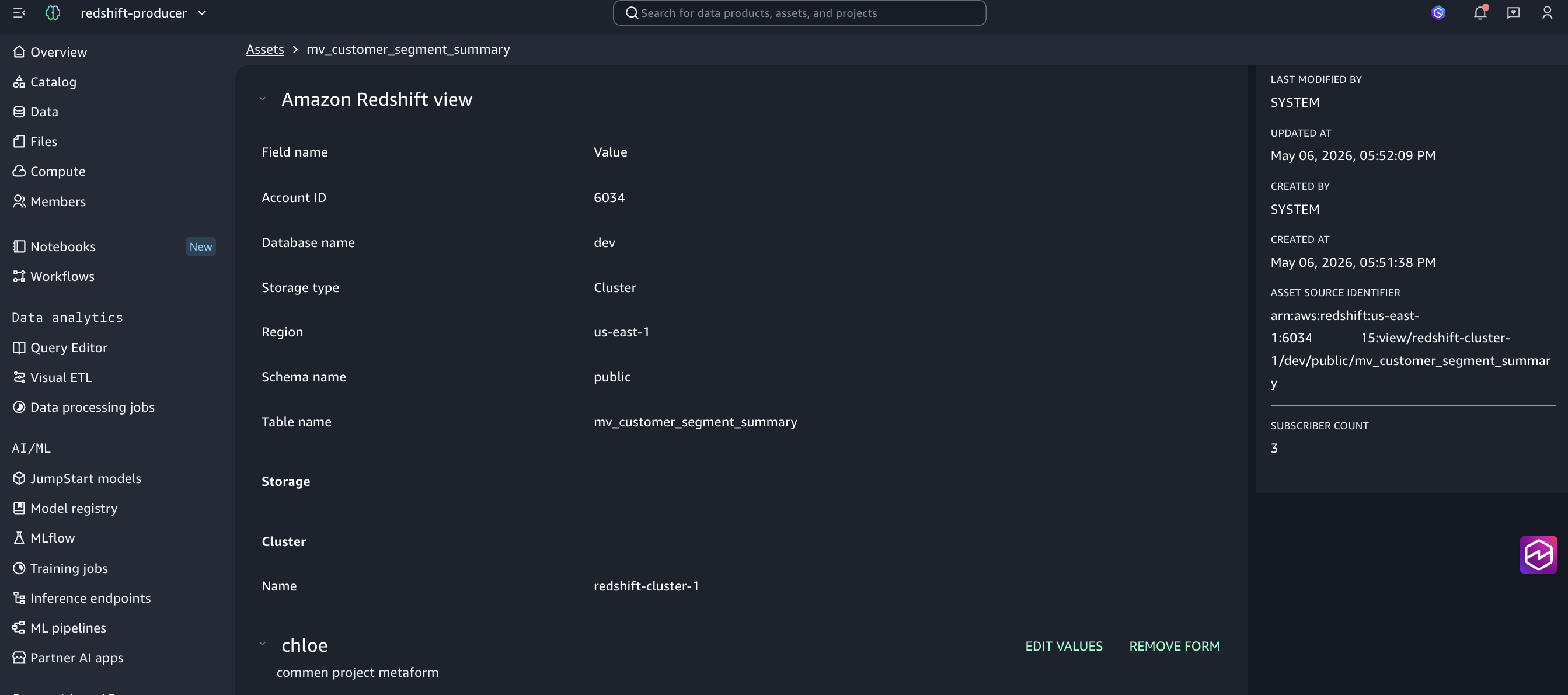
Figure 5: 자산 메타데이터에 cluster는 소스 클러스터(redshift-cluster-1)로 정확히 기록되지만 Account ID는 도메인 계정(6034xxxxxxxx)으로 기록되는 모습입니다. 마지막 권한 부여 로직이 Account ID를 기준으로 클러스터를 찾기 때문에 404가 발생합니다.
이 비대칭은 우연이 아니라 SMUS publish/subscribe 거버넌스 워크플로우의 설계 결과입니다. 자세한 이유는 다음 절에서 설명합니다.
차단 지점: Publisher가 cross-account role로 외부 클러스터를 읽을 수는 있지만(Data Source Run 동작), 마지막 권한 부여 단계는 publisher 계정 안에서 클러스터를 찾는 전제로 구현되어 있어 404 발생.
SMUS의 설계 원칙: Publish/Subscribe 거버넌스에서 Publisher와 소스는 같은 계정
세 구성을 종합하면 SMUS publish/subscribe 거버넌스 워크플로우의 설계 원칙이 드러납니다. 앞서 TL;DR에서 “Publisher = 소스 계정”이라는 전제를 짧게 제시했다면, 여기서는 세 실패 케이스로부터 그 전제가 왜 필연인지를 거꾸로 짚습니다.

Figure: SMUS publish/subscribe 거버넌스의 설계 원칙. Publisher 프로젝트와 소스 데이터는 같은 계정에 있어야 하며, cross-account는 subscribe 방향에서만 지원됩니다. 컨슈머 워크그룹은 Consumer 프로젝트와 같은 계정에 위치하여 소스 컴퓨트 격리가 가능합니다.
이 다이어그램의 핵심은 화살표의 방향성입니다. Publish/Subscribe 거버넌스 워크플로우 안에서 cross-account는 subscribe 방향에서만 지원됩니다. Publisher가 게시한 자산을 다른 계정의 Consumer 프로젝트가 구독하는 방향은 지원되지만, 그 반대 – 소스가 다른 계정에 있고 Publisher만 도메인 계정에 두는 구성 – 은 지원되지 않습니다. 구성 2의 federated catalog가 cross-account 데이터 접근을 허용하긴 하지만, 이는 publish/subscribe 워크플로우와 분리된 경로이며 컴퓨트 격리 요건도 충족하지 않습니다.
이 비대칭이 구성 3에서 관찰된 이상한 동작 – “거의 다 되다가 마지막에서만 막힘” – 을 일관되게 설명합니다. Data Source Run 단계는 cross-account access role을 assume해 외부 클러스터를 읽으니 동작하지만, 구독 단계는 project role이 직접 클러스터를 잡으려 하기 때문에 실패합니다. 후자가 “publisher와 소스가 같은 계정”이라는 전제 위에 구현되어 있기 때문이며, 이 전제는 구성 1·2에서도 동일하게 작동해 모두 다른 지점에서 막히게 만들었습니다.
이 비대칭은 단순한 구현 디테일이 아니라 거버넌스 모델 자체의 정합성 결과로 이해해야 합니다. Asset의 ownership(누가 publish할 권한을 갖는가)과 데이터의 ownership(누가 datashare를 grant할 권한을 갖는가)이 분리되면, audit 추적과 cross-account 권한 부여가 두 계정에 흩어집니다. SMUS의 publish/subscribe 거버넌스 워크플로우가 일관되게 publisher = 소스 데이터 계정으로 수렴하는 이유는 그래야 ownership과 권한 grant가 한 trust boundary 안에서 완결되기 때문입니다. 이 정합성이 깨지는 구성 1·2·3가 결국 어느 단계에서든 막히는 것은 우연이 아닙니다(같은 사상이 Navigating multi-account deployments in Amazon SageMaker Unified Studio에서도 governance-first 관점으로 다뤄집니다).
Grant access to managed Amazon Redshift assets 공식 docs는 cross-account 케이스에서 producer 측의 datashare authorization과 consumer 측의 association이라는 두 추가 단계를 명시합니다. 두 단계 모두 “Publisher와 소스 데이터가 같은 계정”이라는 전제 위에서 정의되며, 이 전제가 무너지는 경로는 docs에 정의되어 있지 않습니다.
도메인 계정에 중간 워크그룹을 두고 거기서 다시 컨슈머로 재전파하는 우회 경로도 생각할 수 있습니다. 그러나 이는 Redshift datashare의 manageability 제약에 걸립니다. Consumer가 inbound datashare 객체를 다시 다른 datashare로 묶거나, 그 객체를 참조하는 view를 datashare에 추가할 수 없다는 제약입니다(Considerations for data sharing reads and writes). 직접 경로는 SMUS 구현 제약에, 우회 경로는 Redshift 설계 제약에 막힙니다.
권장 패턴 상세 구현
설계 원칙을 그대로 따르면 정답은 한 줄입니다. Publisher 프로젝트를 소스 계정에 생성한다.
이 한 가지 변경으로 SMUS Data Source는 datashare 경유 객체가 아닌 소스 계정의 로컬 테이블/뷰를 직접 보게 됩니다. 구성 1에서 막혔던 “datashare 기반 database 자산 자동 등록 불가” 제약이 자연스럽게 해소되면서 자산이 SageMaker Catalog에 정상 publish됩니다.
Publisher의 IAM role은 같은 계정의 클러스터에 직접 접근하므로 Data Source Run도, 구독 단계도 모두 정상 동작합니다. Consumer 프로젝트는 도메인 계정에 생성되고 자체 Redshift Serverless 워크그룹으로 쿼리합니다. Subscribe 승인 시 SMUS가 cross-account datashare를 자동 생성하고 컨슈머의 namespace에 associate합니다. 컨슈머의 쿼리는 자기 워크그룹에서 실행되므로 소스 컴퓨트는 그대로 격리됩니다.
이는 컨슈머 워크그룹의 SYS_QUERY_HISTORY와 동일 시간대 소스 cluster의 STL_QUERY를 비교한 다음 두 화면으로 검증됩니다(본 검증은 RA3 클러스터에서 수행했고, 동일 메커니즘은 후속 RG 인스턴스 패밀리에도 그대로 적용됩니다).
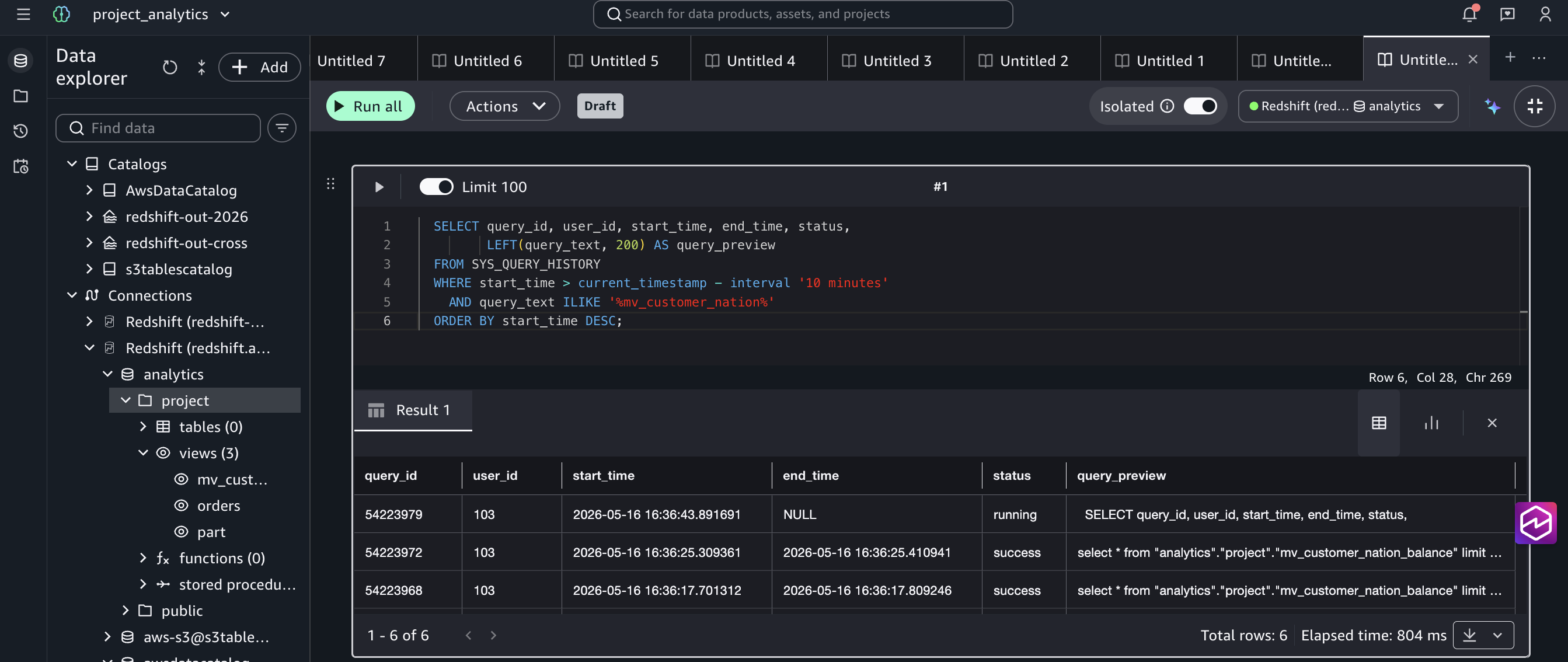
Figure 6: 컨슈머 워크그룹의 SYS_QUERY_HISTORY에 컨슈머가 실행한 mv_customer_nation* 쿼리가 그대로 기록된 모습입니다. 컨슈머 측에서 쿼리가 실제로 실행됐다는 직접 증거입니다.
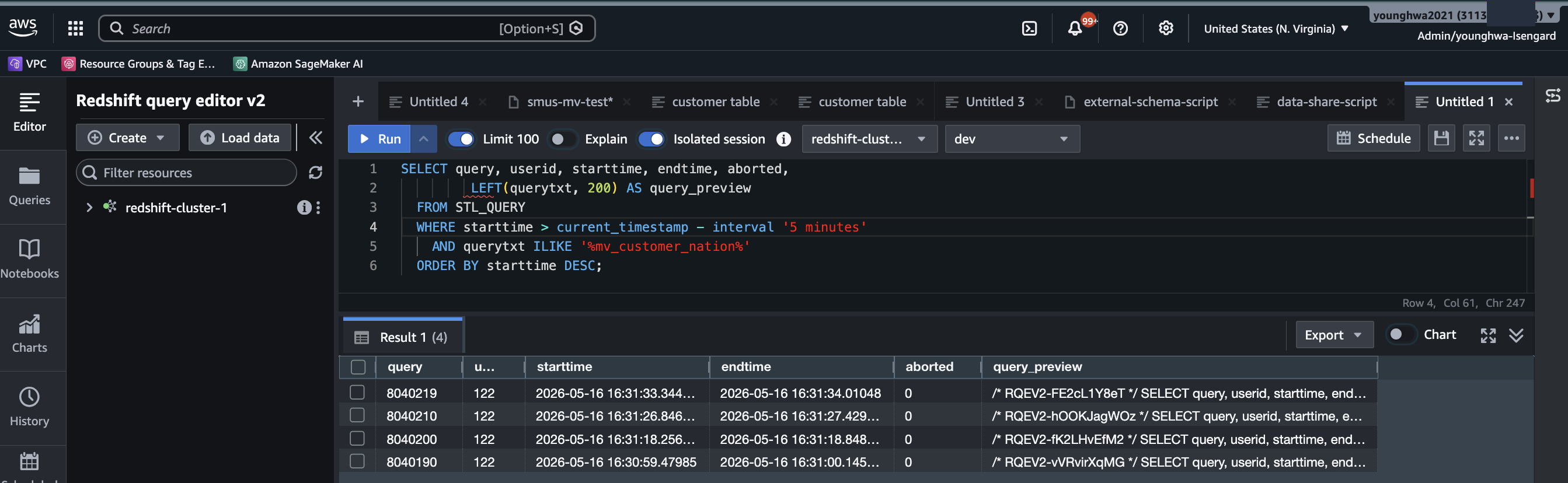
Figure 7: 동일 시간대의 소스 클러스터 STL_QUERY를 같은 키워드(mv_customer_nation)로 조회한 결과입니다. 다른 쿼리들은 잡히지만 컨슈머의 쿼리는 흔적이 없어, 쿼리 처리가 소스 컴퓨트에 도달하지 않았음을 확인할 수 있습니다. Figure 6과 함께 보면 storage-compute 분리가 실제로 작동했음이 확인됩니다. 동일한 STL_QUERY 검증 기법을 구성 2(Figure 3)에 적용했을 때는 컨슈머 쿼리가 컬럼 단위까지 그대로 잡혔다는 점을 함께 보면, 두 패턴이 컴퓨트 격리 측면에서 정반대 결과를 만든다는 것이 분명해집니다.
여기서 자연스러운 의문이 생깁니다. “SMUS 도메인은 도메인 계정에 있는데, 어떻게 다른 계정(소스 계정)에 프로젝트를 만들 수 있지?”
첫 번째 전제는 account association입니다. 도메인 계정이 RAM으로 association을 요청하고 소스 계정이 수락한 뒤, 소스 계정에서 Tooling을 비롯한 blueprint를 enable하면 그 시점부터 SMUS가 소스 계정 안에 프로젝트와 환경을 deploy할 수 있게 됩니다(Associated accounts docs). 참고로 구성 1·3처럼 “도메인 계정 안에서 외부 리소스를 참조만 하는” 패턴은 IAM trust로 association 없이도 동작하지만, publish/subscribe 워크플로우를 한 번에 완결하지 못합니다. Cross-account 거버넌스를 SMUS 안에서 구현하려면 association은 우회 불가능한 전제라고 보는 편이 맞습니다.
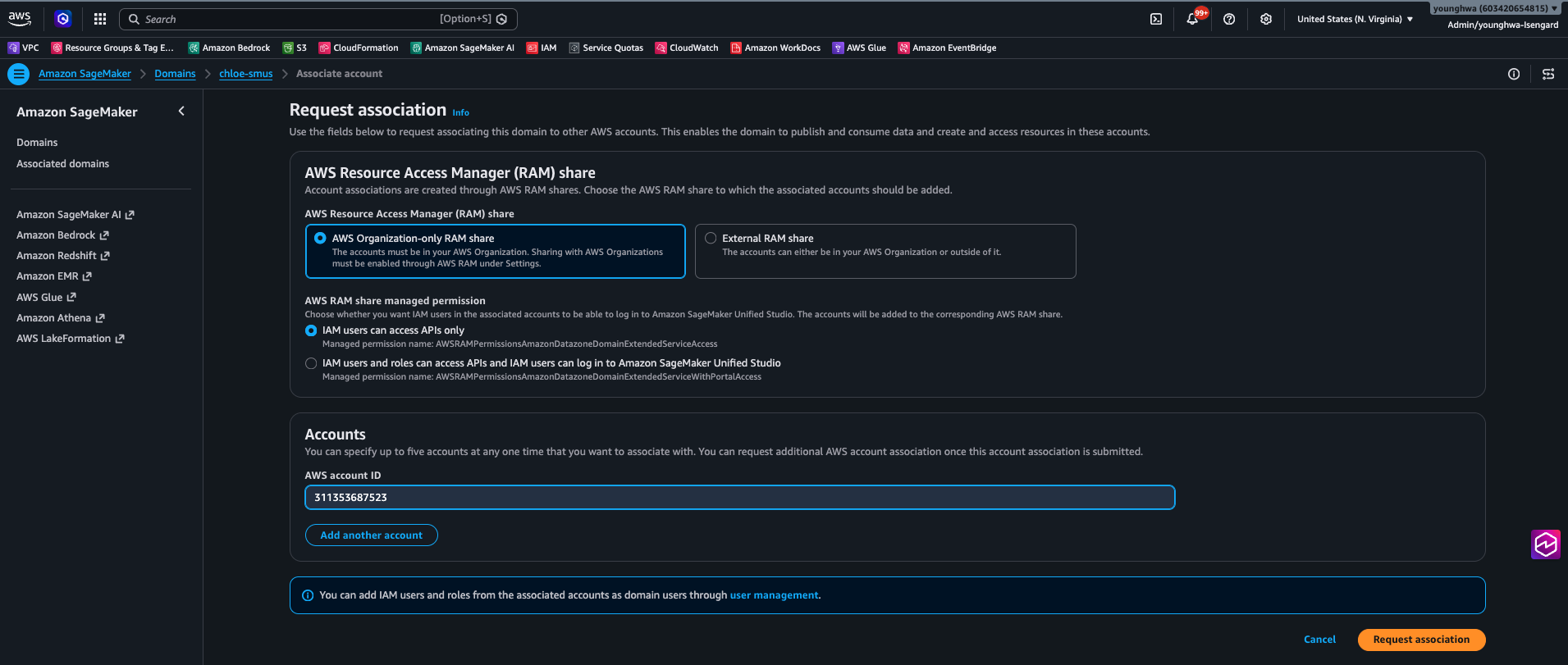
Figure 8: 도메인 계정에서 SMUS Console의 Account associations 메뉴로 소스 계정 연결을 요청하는 화면입니다. 소스 계정이 RAM 초대를 수락하고 blueprint를 enable해야 SMUS가 소스 계정 안에 프로젝트를 deploy할 수 있게 됩니다.
그 위에 올라가는 두 메커니즘이 Account-agnostic Project Profile과 Account Pool입니다.
- Account-agnostic Project Profile: custom project profile에서 “Choose account and region during project creation” 옵션을 켠 형태입니다. 프로젝트 생성 시점에 (a) All associated accounts 또는 (b) Specific account pool 중에서 계정을 선택합니다(Custom project profile, AWS Big Data Blog 소개).
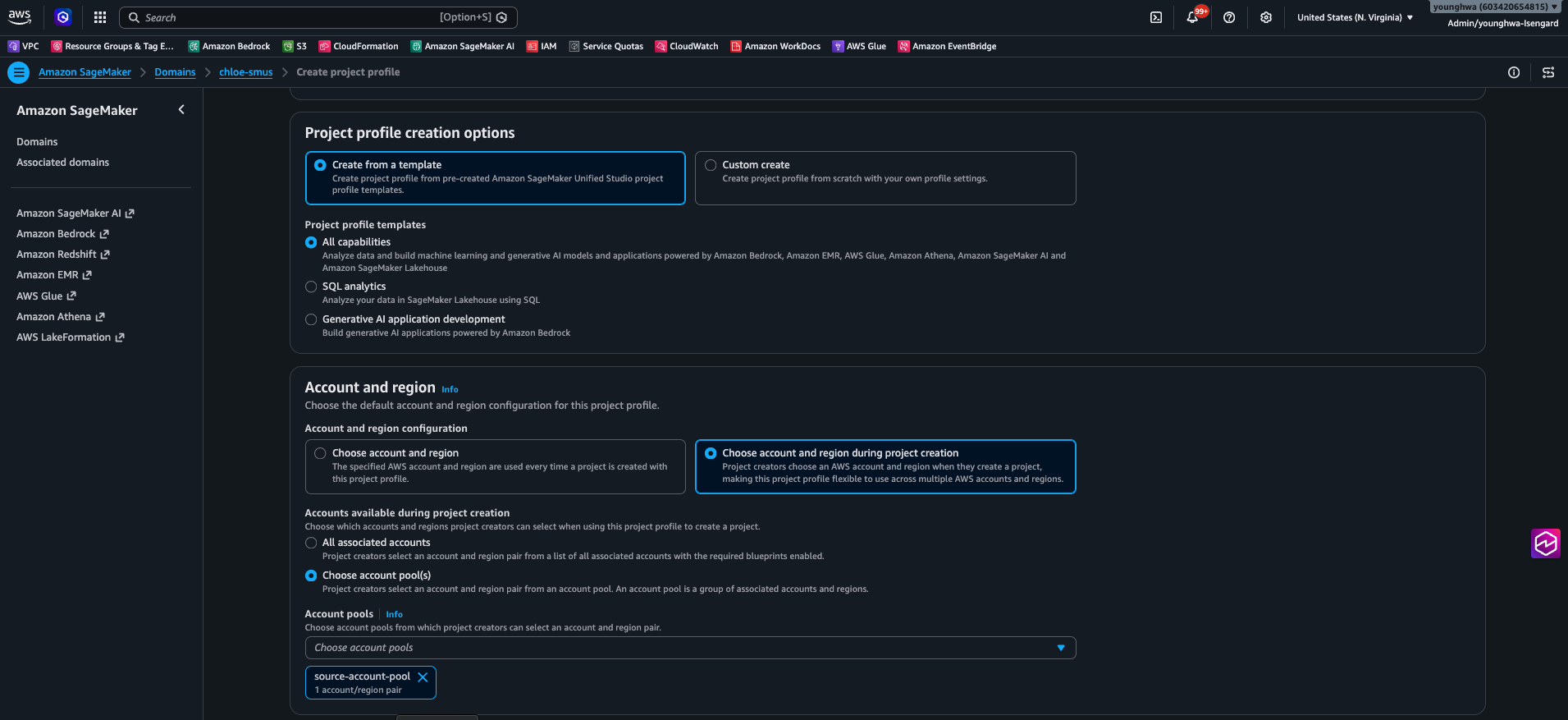
Figure 9: All capabilities 템플릿으로 Project Profile을 생성하면서 “Choose account and region during project creation” 옵션을 활성화하고, 사전에 만들어둔 account pool을 연결한 모습입니다. 이 한 개의 profile이 여러 자회사 계정에 그대로 재사용됩니다.
- Account Pool: 도메인이 프로젝트 생성에 사용할 수 있는 AWS 계정/리전 인가 리스트입니다. Static 또는 Lambda 기반 dynamic resolution으로 정의하며, Pool의 생성/수정/삭제는 AWS CLI 전용입니다(Account pools docs).
두 기능을 합치면 도메인 owner가 다른 계정에 프로젝트를 배포할 수 있는 선택지 묶음을 미리 정의하고, 사용자는 프로젝트 생성 시점에 그 안에서 계정을 고르는 흐름이 만들어집니다.
이 옵션이 없다면 자회사가 늘 때마다 profile을 복제해야 하므로, 단일 표준으로 그룹 단위 거버넌스를 유지한다는 SMUS의 본래 가치가 무너집니다. Account-agnostic profile은 profile 1개 = 그룹 표준 1개라는 등식을 가능하게 해주는 핵심 도구입니다.
Note: associated 계정이 하나뿐인 환경에서는 Pool 없이 “All associated accounts” 옵션만으로 동일한 결과를 얻을 수 있고 CLI 단계가 빠져 더 단순합니다. 다수 계정/리전을 거버넌스 단위로 분리해야 하는 엔터프라이즈 환경에서는 Pool이 의미 있는 도구가 됩니다.
리소스 배치 매핑
본 패턴에서 어떤 리소스가 어느 계정에 위치하는지 정리하면 다음과 같습니다.
| 리소스 | 배치 위치 | 비고 |
|---|---|---|
| SMUS Domain (Portal, Catalog, Metadata Forms, Authorization Policies) | 도메인 계정 | 거버넌스 control plane |
| Account Pool, Project Profile (Account-agnostic) | 도메인 계정 | Domain owner 계정에서만 생성 가능 |
| Publisher 프로젝트 (Tooling env, project role) | 소스 계정 | Publisher IAM role이 source data와 same-account에 있는 것이 핵심 |
| 소스 Redshift cluster, Secret | 소스 계정 | Publisher 프로젝트와 same-account |
| Cross-account datashare | 소스 계정에서 생성 → 도메인 계정 namespace로 association | Subscribe 승인 시 SMUS가 자동 생성 |
| Consumer 프로젝트 | 도메인 계정 | |
| Consumer Redshift Serverless workgroup | 도메인 계정 | 컨슈머 쿼리가 실행되는 곳, 소스 컴퓨트 격리의 핵심 |
| project.views.<asset> (datashare view) | 도메인 계정의 컨슈머 워크그룹 | SMUS가 자동 생성, 컨슈머가 실제 쿼리하는 entry point |
이 매핑이 본 글의 핵심 메시지를 한 표로 압축합니다. Publisher가 소스 계정에 있어야 구독 단계가 동작하고, 컨슈머 워크그룹이 도메인 계정에 따로 있어야 소스 컴퓨트가 격리됩니다.
구현 단계
전체 작업은 세 가지 단계로 나뉩니다. (A) 도메인 계정에서 거버넌스 base를 깐 뒤, (B) 소스 계정에 Publisher 환경을 배포하고, (C) 도메인 계정의 Consumer 측에서 구독·쿼리합니다.
A. Domain Owner — 도메인 계정에서 거버넌스 base 구축
- RAM으로 소스 계정 → 도메인 association 수락 (Figure 8 참조)
- SMUS Console의 Account associations 플로우를 통해 진행합니다. RAM 측에서 적절한
AWSRAMPermission*AmazonDataZoneDomain*managed permission이 적용됩니다(콘솔에서 표시되는 권한 항목 그대로 수락). - Blueprint configuration이 소스 계정에 활성화되면서 SMUS가 사용할 IAM role이 자동 프로비저닝됩니다.
- SMUS Console의 Account associations 플로우를 통해 진행합니다. RAM 측에서 적절한
- (다계정만) Account Pool에 소스 계정 등록
aws datazone create-account-pool \ --domain-identifier <domain-id> \ --name source-account-pool \ --resolution-strategy MANUAL \ --account-source '{"accounts": [{"awsAccountId": "<source-account-id>", "supportedRegions": ["us-east-1"]}]}' - 도메인 계정에서 Account-agnostic Project Profile 생성 (Figure 9 참조)
- Template: All capabilities
- “Choose account and region during project creation” 활성화
- 계정 선택 옵션: 단일 계정이면 “All associated accounts”, 다수 계정이면 step 2의 account pool 연결
B. Publisher 측 — 소스 계정에 Publisher 환경 배포
- Publisher 프로젝트 생성 → 소스 계정에 배포
- SMUS Portal의 Create project 화면에서 위 profile 선택
- 계정 드롭다운에서 소스 계정 선택
- 프로젝트가 소스 계정에 배포되면서 project role도 소스 계정 안에 생성됩니다.
- 소스 계정에 같은 이름의 Publisher 프로젝트가 이미 존재하면 Glue database 충돌(
Glue database with name <name> already exists)이 발생합니다. 다른 도메인이라도 Glue catalog는 계정 단위로 공유되므로 도메인 간 이름이 겹치지 않게 명명 규칙을 잡아두는 편이 안전합니다.
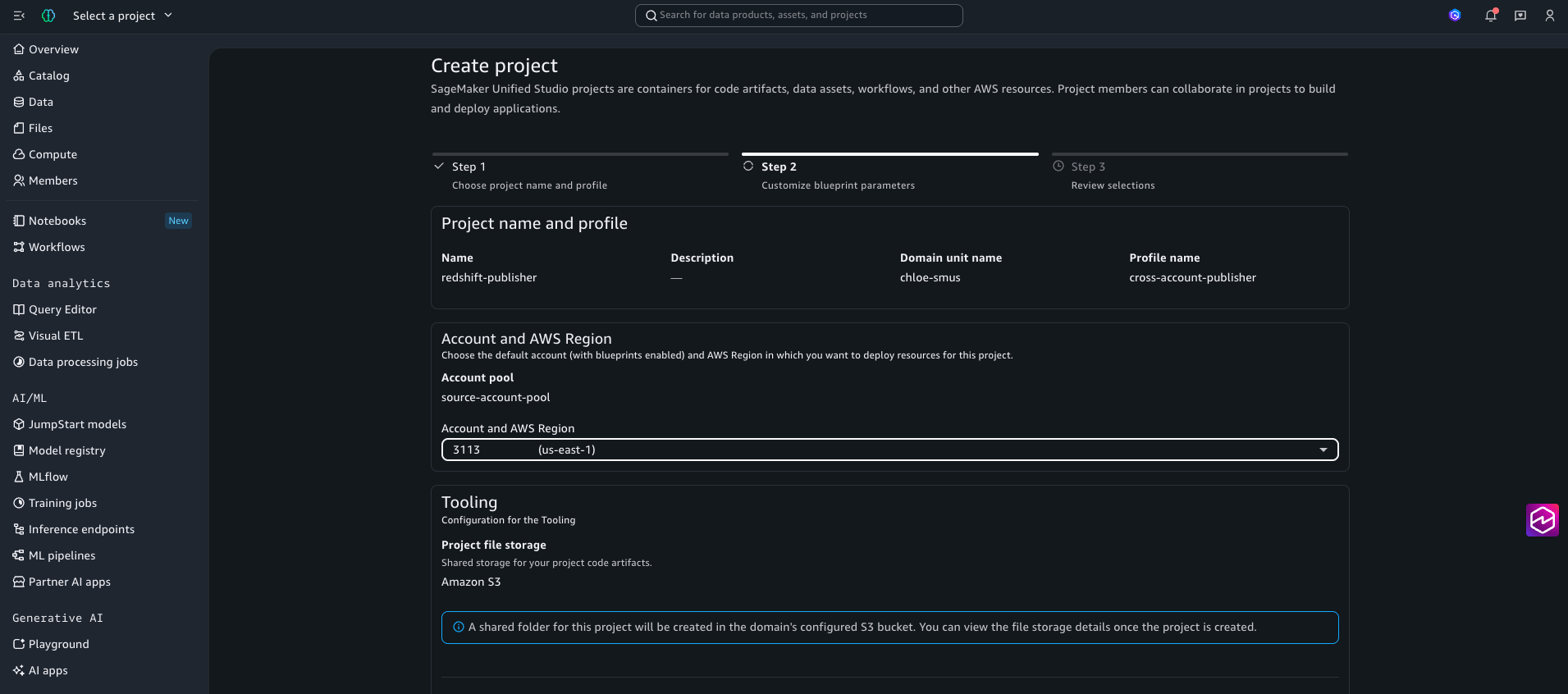
Figure 10: Publisher 프로젝트가 cross-account-publisher profile을 통해 소스 계정(3113xxxxxxxx)에 배포되도록 선택된 모습입니다. project role과 Tooling environment가 모두 소스 계정 안에 생성됩니다.
- Cluster·Secret에 SMUS 인식 태그 3종 부착
- Cluster와 Secret 모두에 다음 세 태그를 함께 설정합니다.
for-use-with-all-datazone-projects=trueAmazonDataZoneDomain=<domain-id>AmazonDataZoneProject=<publisher-project-id>
- 첫 번째 태그만으로는 SMUS Add Compute UI 드롭다운에는 노출되지만, 구독 단계의 ManageAccess role이 Secret을 읽을 때 도메인/프로젝트 태그 조건이 추가로 적용됩니다. 누락 시 이 단계에서
secretsmanager:GetSecretValueAccessDenied가 발생합니다.
- Cluster와 Secret 모두에 다음 세 태그를 함께 설정합니다.
- SMUS Tooling VPC ↔ 클러스터 VPC peering 설정
- 클러스터를 publicly accessible로 바꾸지 말고 peering으로 연결
- 양쪽 route table 업데이트
- 클러스터 보안 그룹에서 Tooling VPC CIDR로부터 Redshift 포트(기본 5439) inbound 허용
AllowDnsResolutionFromRemoteVpc: true양방향 설정 필수. 이 항목을 빠뜨리면 hostname이 public IP로 resolve되어 연결 실패하는데, 에러 메시지가 모호해(Failed to initialize pool: The connection attempt failed) 디버깅에 시간이 많이 듭니다.
- Publisher 프로젝트에서 same-account Add Compute
- Same-account이므로 클러스터/Secret 드롭다운에서 자동으로 검색됩니다
- Access role ARN 칸은 비워둡니다 (cross-account access role을 사용하지 않습니다)
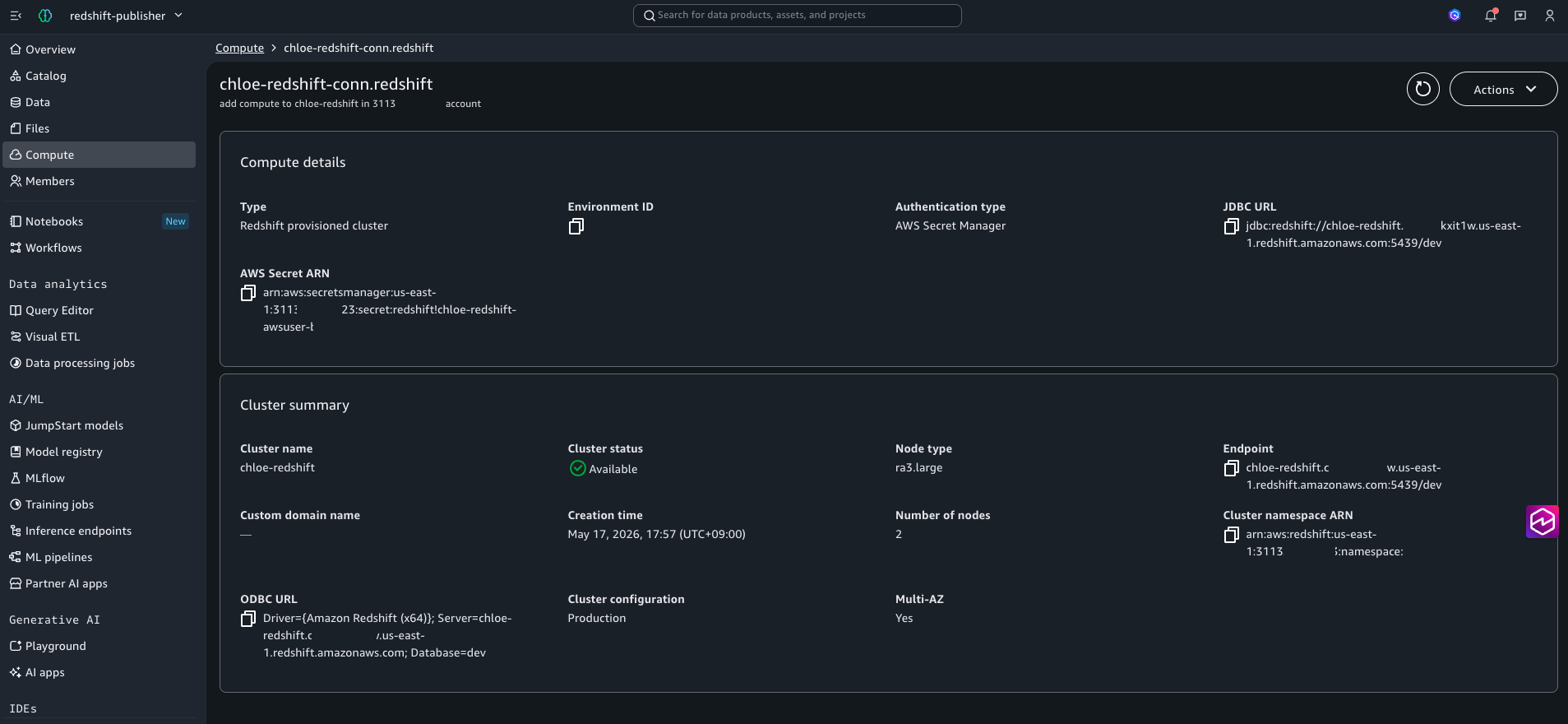
Figure 11: Publisher 프로젝트가 same-account로 소스 클러스터(ra3.large)에 직접 연결된 컴퓨트 상세입니다. Cross-account access role 없이 project role이 직접 클러스터에 권한을 행사합니다.
- Data Source Run으로 자산 import
- Schema는 public
- Run 후 자산이 inventory로 자동으로 import됩니다
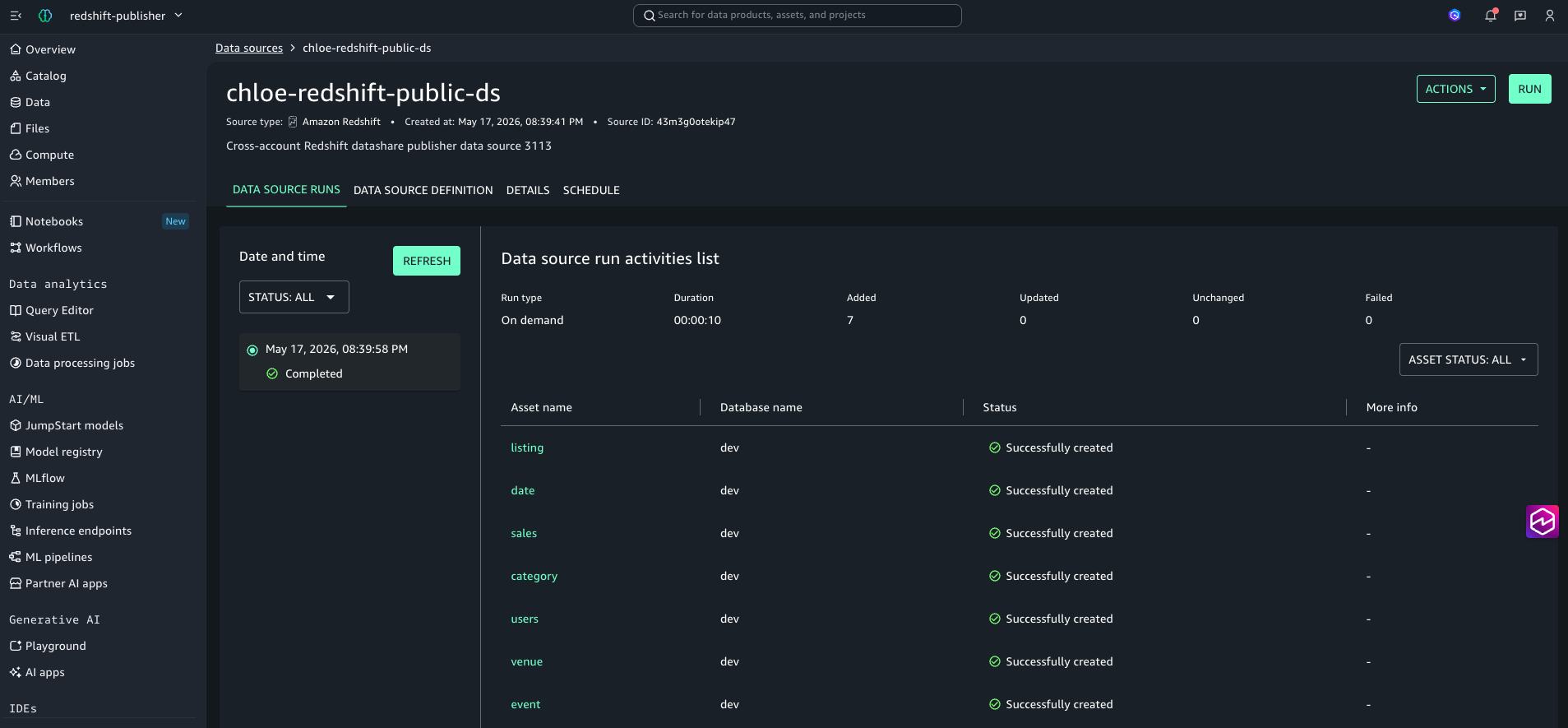
Figure 12: Data Source Run이 성공하면 publisher 프로젝트의 inventory에 7개 자산이 자동 import됩니다. 이 단계에서 자산이 SageMaker Catalog로 publish 가능한 상태가 됩니다.
C. Consumer 측 — 도메인 계정에서 구독 및 쿼리
- Consumer 프로젝트에 Serverless 워크그룹 provisioning
- Consumer 프로젝트 자체는 도메인 계정에 만들어두되, OnDemand RedshiftServerless blueprint로 환경을 추가해 워크그룹이 provisioning될 때까지 기다린 후 subscribe 요청을 보냅니다.
- 컨슈머 namespace가 없는 상태에서 subscribe 요청을 보내면 구독 단계가 “Adding asset” 상태에 머무릅니다. 워크그룹이 provisioning되면 구독 단계가 자연스럽게 진행됩니다.
- 자산 publish → Consumer subscribe → Publisher 승인 → 쿼리
- SMUS가 subscription target을 자동 생성하므로 별도 CLI 불필요
- Catalog에서 자산 검색 → subscribe 요청 → Publisher 승인 → 컨슈머 워크그룹의
project.views.<asset>경로에서 쿼리
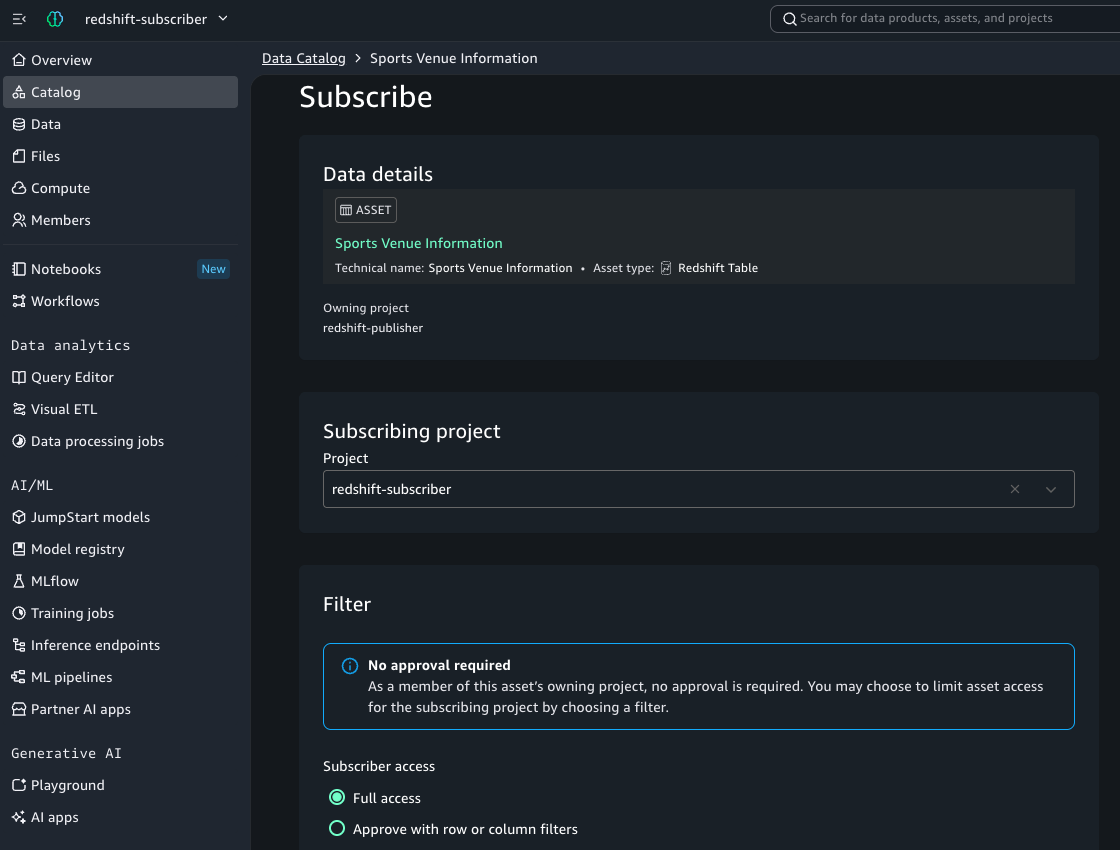
Figure 13: Subscriber 프로젝트가 publisher 프로젝트의 자산을 구독하는 화면입니다. Owning project와 subscribing project가 명시적으로 분리되어 있어, 누가 자산을 소유하고 누가 구독하는지를 거버넌스 차원에서 추적할 수 있습니다.
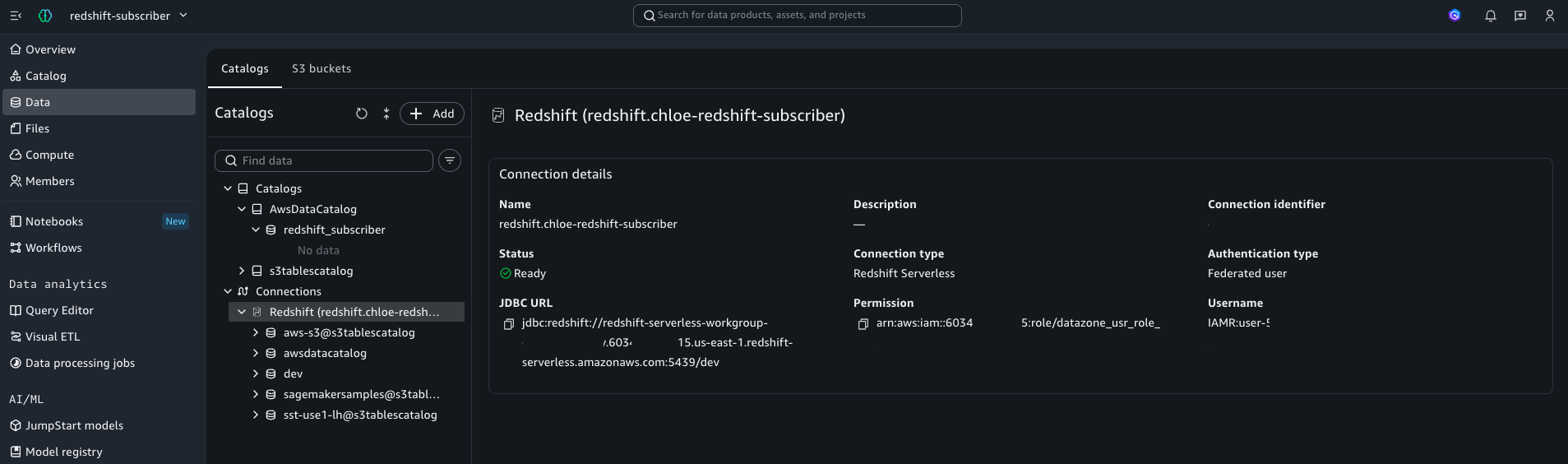
Figure 14: 구독이 끝난 뒤 subscriber 프로젝트의 컴퓨트 연결 상세 화면입니다. JDBC URL이 subscriber 계정(6034xxxxxxxx)의 redshift-serverless workgroup을 가리키며, subscriber 쿼리가 향하는 엔드포인트가 자기 계정 컴퓨트라는 점이 확인됩니다(앞서 Figure 6·7의 쿼리 로그 비교가 이 엔드포인트에서 실제로 쿼리가 실행됐음을 입증합니다).
End-to-end 동작
| 단계 | 결과 |
|---|---|
| Publisher in 소스 계정 (same-account Add Compute) | 성공 |
| Data Source Run | 성공, 자산 자동 import |
| Asset publish | 성공 |
| 컨슈머 subscribe 요청 → Publisher 승인 | 성공 |
| 구독 단계 (권한 부여) | 성공 (구성 3에서 실패했던 단계) |
| 컨슈머 워크그룹에서 Redshift 엔진으로 쿼리 | 성공 |
| 소스 컴퓨트 격리 | 유지 (datashare 본래 설계대로) |
운영 고려사항
메커니즘과 쿼리 엔진을 분리해서 봐야 합니다
“쿼리 엔진을 Redshift로 쓰면 격리되는 거 아니냐”는 자연스러운 의문이 생깁니다. 답은 그 아래에 깔린 메커니즘이 무엇이냐에 달려 있습니다.
| 메커니즘 | 데이터 위치 | 쿼리 실행 위치 | 소스 컴퓨트 부하 |
|---|---|---|---|
| SMUS Federated Catalog (JDBC connector) | 소스에 그대로 | Athena connector(Lambda)가 JDBC로 소스 컴퓨트에서 실행 | 있음 (매 쿼리가 소스에서 처리) |
| Redshift Datashare | 소스에 그대로 | 컨슈머 워크그룹의 컴퓨트에서 실행 | 없음 (소스에는 storage read만 발생) |
핵심 포인트:
- SMUS federated catalog는 통과(pass-through) 모델입니다. Athena가 federated catalog를 통해 Redshift 자산을 쿼리하면 connector Lambda가 JDBC로 소스 Redshift를 호출하므로, 결국 소스 컴퓨트에서 쿼리가 실행됩니다(참고: Athena Redshift connector docs, 검증 화면은 앞서 Figure 3).
- Datashare는 namespace 레벨의 association 메커니즘입니다. 컨슈머가 자기 워크그룹에서 datashare view를 통해 데이터를 읽고, 쿼리 실행 자체가 컨슈머 컴퓨트에서 일어납니다. 소스에는 컴퓨트 부하가 가지 않습니다.
SageMaker Catalog ≠ Glue Data Catalog (자주 받는 질문)
이 패턴을 설명하면 “그래서 Athena로도 쿼리되나요?”라는 질문이 자주 나옵니다. 답은 아니오이고, 그 이유는 “카탈로그”라는 단어가 문맥에 따라 다른 두 객체를 가리키기 때문입니다.
| 카탈로그 | 역할 | 본 패턴에서 |
|---|---|---|
| SageMaker Catalog (좌측 네비게이션의 Catalog) | Discovery, publish/subscribe, business glossary, lineage 등 거버넌스 메타데이터 | 완전히 사용 |
| AWS Glue Data Catalog (Data 페이지 Catalogs 탭의 AwsDataCatalog, federated catalogs 등) | Athena 등 분석 엔진이 쿼리 대상으로 사용하는 기술 카탈로그 | 사용하지 않음 |
본 패턴에서 SMUS가 자동 생성하는 컨슈머 측 객체는 project.views.<asset> 형태의 Redshift datashare 기반 view이며, 쿼리 엔진은 Redshift입니다. 컨슈머 UI에서 publish된 자산은 좌측 Catalog 메뉴에서 검색·구독되고, 실제 쿼리는 Data 페이지의 Connections 트리에서 project.views.<asset> 경로로 이루어집니다. Catalogs 탭(기술 카탈로그)에는 등장하지 않으며, 이 때문에 Athena 쿼리도 불가능합니다.
근거 docs(Redshift vs Glue 자산 권한 부여 방식 차이):
- Redshift asset: “Amazon SageMaker Unified Studio creates a datashare between the source and target cluster and creates a view on top of the shared table.” (Grant access to managed Amazon Redshift assets)
- Glue asset (비교): “assets that are granted appear in the AWS Glue Data Catalog as resources in your account. You can then use Amazon Athena, Amazon Redshift, or Spark to query the tables.” (Grant access to managed Glue assets)
즉 자산 타입에 따라 권한 부여 방식이 달라지며, Redshift 자산은 본 패턴처럼 datashare view로만 노출됩니다.
VPC CIDR 기본값 주의
신규 도메인을 SMUS quick setup으로 생성하면 Tooling VPC가 default CIDR(10.38.0.0/16)로 자동 생성됩니다. 다른 SMUS 도메인이나 클러스터 VPC와 같은 CIDR을 쓰는 환경이라면 peering 라우팅이 충돌하므로, custom VPC 옵션으로 CIDR을 명시 지정하는 편이 안전합니다.
자회사 계정이 추후 추가될 때: Pool과 Profile의 확장성
자회사가 단계적으로 SMUS에 합류하는 환경에서는 Pool과 Profile을 어디서 늘릴 수 있는가가 운영상 중요한 의사결정 포인트입니다.
- Account Pool은 update 가능합니다. aws datazone update-account-pool로 기존 pool에 계정을 추가하거나 제거할 수 있고, 같은 pool을 참조하는 모든 Project Profile에 변경이 즉시 반영됩니다(Account pools considerations). Profile 자체를 다시 만들 필요가 없고, 이미 배포된 다른 자회사 프로젝트에도 영향이 없습니다. 단, Pool 생성/수정/삭제는 CLI 전용이며 정적 리스트 기준 pool 하나당 최대 25개 계정, 도메인당 최대 100개 pool 제한이 있습니다.
- “All associated accounts” 옵션을 선택한 Profile은 한층 더 단순합니다. 새 자회사 계정을 도메인에 associate하기만 하면 자동으로 동일 profile에서 선택 가능해지므로 별도의 update 단계가 없습니다. 거버넌스 단위 분리가 필요 없는 환경이라면 가장 운영 부담이 적은 선택지입니다.
| 운영 시나리오 | 권장 구성 | 신규 자회사 추가 시 절차 |
|---|---|---|
| 인가 통제 필요(어떤 계정에 배포 허용할지 명시) | Account Pool + Account-agnostic profile | update-account-pool로 계정 추가 |
| 도메인 association = 배포 허용으로 충분 | All associated accounts + Account-agnostic profile | 도메인에 신규 계정 associate만 |
| 단일 자회사, 확장 계획 없음 | 일반 custom profile (계정 고정) | N/A |
핵심은 Profile은 처음 만들 때의 형태가 그대로 유지되더라도, Pool 또는 associated accounts 쪽에서 확장이 흡수된다는 점입니다. 그룹 단위 SMUS 거버넌스를 설계할 때 자회사 enumerate가 어렵더라도 Profile을 잘게 쪼갤 필요가 없습니다.
Athena 호환과 컴퓨트 격리의 트레이드오프
Athena 호환이 필요하다면 구성 2의 SMUS federated catalog(JDBC 통과 모델) 경로가 유일한 옵션이지만, 그 경우 컴퓨트 격리 원칙이 깨집니다. 컴퓨트 격리와 Athena 쿼리는 현재 동시에 만족시키기 어려운 트레이드오프라는 점이 의사결정 시 명확히 인지되어야 합니다(Lake Formation 공식 제약: “Athena doesn’t support querying Amazon Redshift datashares managed by Lake Formation”).
마무리
결론은 단순합니다. SMUS의 publish/subscribe 거버넌스 워크플로우는 “Publisher와 소스는 같은 계정, cross-account는 subscribe 방향에서만”이라는 원칙 위에 설계되어 있습니다. Publisher 프로젝트는 소스 데이터와 같은 계정에 있어야 하며, 다계정 환경에서 단일 표준 profile로 이를 운영하려면 Account-agnostic Project Profile(필요 시 Account Pool과 결합)을 함께 사용합니다. 이 원칙을 모른 채 직관적으로 도메인 계정에 Publisher를 두면 publish까지는 동작하지만 권한 부여 단계에서 무너집니다.
Cross-account로 데이터 거버넌스를 SMUS 위에 올리려는 팀이라면, 처음부터 Publisher 프로젝트를 데이터 소스 계정에 배치하는 것을 기본 패턴으로 권장합니다. 컴퓨트 격리, 카탈로그 거버넌스, Redshift 엔진 쿼리라는 세 요건이 한 구조 안에서 자연스럽게 충족되고, Athena 호환이 필요한 경우의 트레이드오프도 명시적으로 인지한 상태에서 의사결정할 수 있습니다.
참고 자료
- SMUS: Associated accounts in Amazon SageMaker Unified Studio
- SMUS: Account pools in Amazon SageMaker Unified Studio
- SMUS: Account pools considerations
- SMUS: Custom project profile
- SMUS: Grant access to managed Redshift assets
- SMUS: Grant access to managed Glue assets
- SMUS: Create Amazon Redshift data source
- Use account-agnostic reusable project profiles in Amazon SageMaker to streamline governance
- Lake Formation: Limitations of Amazon Redshift data sharing
- Redshift: Data sharing considerations
- Athena: Amazon Athena Redshift connector
- Navigating multi-account deployments in Amazon SageMaker Unified Studio: a governance-first approach
- Meet Amazon Redshift RG – AWS Graviton-based instances with an integrated data lake query engine