AWS Step Functions Use Cases
What can you automate with AWS Step Functions? Get some ideas from some of the most popular use cases below.
Overview
AWS Step Functions enables you to implement a business process as a series of steps that make up a workflow.
The individual steps in the workflow can invoke a Lambda function or a container that has some business logic, update a database such as DynamoDB or publish a message to a queue once that step or the entire workflow completes execution.
AWS Step Functions has two workflow options - Standard and Express. When your business process is expected to take longer than five minutes for a single execution, you should choose Standard. Some examples of a long running workflow are an ETL orchestration pipeline or when any step in your workflow waits for response from a human to move to the next step.
Express workflows are suited for workflows that take less than five minutes, and are ideal when you need high execution volume i.e. 100,000 invocations per second. You can use either Standard or Express distinctly, or combine them such that a longer Standard workflow triggers multiple shorter Express workflows that execute in parallel.
Microservice Orchestration
Combine Lambda functions to build a web-based application
In this example of a simple banking system, a new bank account is created after validating a customer’s name and address. The workflow begins with two Lambda functions CheckName and CheckAddress executing in parallel as task states. Once both are complete, the workflow executes the ApproveApplication Lambda function. You can define retry and catch clauses to handle errors from task states. You can use predefined system errors or handle custom errors thrown by these Lambda functions in your workflow. Since your workflow code takes on error handling, the Lambda functions can focus on the business logic and have less code. Express workflows would be a better fit for this example as the Lambda functions are performing tasks that together take less than five minutes, with no external dependencies.

Combine Lambda functions to build a web-based application - with a human approval
Sometimes you might need a human to review and approve or reject a step in the business process so that the workflow can continue to the next step. We recommend using Standard workflows when your workflow needs to wait for a human or for processes in which an external system might take more than five minutes to respond. Here we extend the new account opening process with a notify approver step in between.The workflow starts with the CheckName and CheckAddress task states executing in parallel. The next state ReviewRequired is a choice state that has two possible paths - either send an SNS notification email to the approver in the NotifyApprover task or proceed to the ApproveApplication state. The NotifyApprover task state sends an email to the approver, and waits for a response before proceeding to the next choice state “Approved”. Based on the approver’s decision, the account application is either Approved or Rejected through Lambda functions,

Invoke a business process in response to an event using Express Workflows
In this example, an event on a custom Eventbridge bus satisfies a rule and invokes a Step Functions workflow as a target. Suppose you have a customer service application that needs to handle expired customer subscriptions. An EventBridge rule listens for subscription expired events and invokes a target workflow in response. The subscription expired workflow will disable all the resources that the expired subscription owns without deleting them and email the customer to notify them about their expired subscription. These two actions can be done in parallel using Lambda functions. At the end of the workflow, a new event is sent to the event bus through a Lambda function indicating that the subscription expiration has been processed. For this example, we recommend using Express Workflows. As your business grows and you start to put more events on to the event bus, the capacity to invoke 100,000 workflow executions a second with Express Workflows is powerful. See the example in action with this Github repo.

Security and IT Automation
Orchestrate a security incident response for IAM policy creation
You can use AWS Step Functions to create an automated security incident response workflow that includes a manual approval step. In this example, a Step Functions workflow is triggered when an IAM policy is created. The workflow compares the policy action against a customizable list of restricted actions. The workflow rolls back the policy temporarily, then notifies an administrator and waits for them to approve or deny. You can extend this workflow to remediate automatically such as applying alternative actions, or restricting actions to specific ARNs. See this example in action here.

Respond to operational events in your AWS account
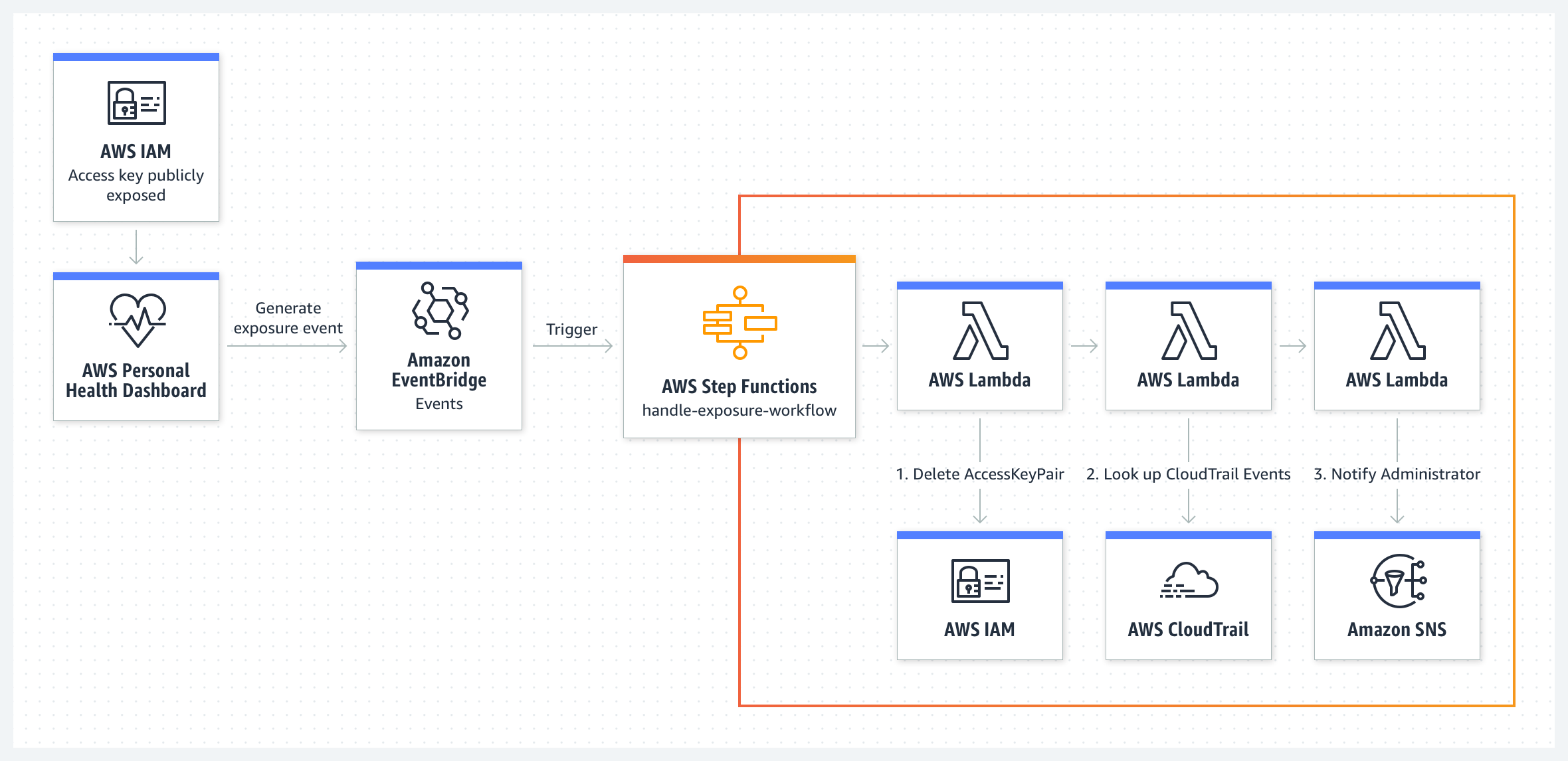
You can reduce the operational overhead of maintaining your AWS cloud infrastructure by automating how you respond to operational events for your AWS resources. Amazon EventBridge provides a near real-time stream of system events that describe most changes and notifications for your AWS resources. From this stream, you can create rules to route specific events to AWS Step Functions, AWS Lambda, and other AWS services for further processing and automated actions. In this example, an AWS Step Functions workflow is triggered based on an event sourced from AWS Health. AWS proactively monitors popular code repository sites for IAM access keys that have been publicly exposed. Let’s suppose an IAM access key was exposed on GitHub. AWS Health generates an AWS_RISK_CREDENTIALS_EXPOSED event in the AWS account related to the exposed key. A configured Amazon Eventbridge rule detects this event and invokes a Step Functions workflow. With the help of AWS Lambda functions, the workflow then deletes the exposed IAM access key, summarizes the recent API activity for the exposed key, and sends the summary message to an Amazon SNS topic to notify the subscribers―in that order. See this example in action here.
Synchronize data between source and destination S3 buckets
You can use Amazon S3 to host a static website, and Amazon CloudFront to distribute the content worldwide. As a website owner, you might need two S3 buckets for uploading your website content: one for staging and testing, and one for production. You want to update the production bucket with all changes from the staging bucket, without having to create a new bucket from scratch every time you update your website. In this example, the Step Functions workflow performs tasks in two parallel and independent loops: one loop copies all objects from source bucket to destination bucket, but leaves out objects already present in the destination bucket. The second loop deletes any objects in the destination bucket not found in the source bucket. A set of AWS Lambda functions carry out the invididual steps: validate input, get the lists of objects from both source and destination buckets, and copy or delete objects in batches. See this example along with its code in detail here. Learn more about how to create parallel branches of execution in your state machine here.

Data Processing and ETL Orchestration
Build a data processing pipeline for streaming data
In this example, Freebird built a data processing pipeline to process webhook data from multiple sources in real time and run Lambda functions that modify the data. In this use case, webhook data from several third party applications is sent through Amazon API Gateway to an Amazon Kinesis data stream. An AWS Lambda function pulls data off this Kinesis stream, and triggers an Express Workflow. This workflow goes through a series of steps to validate, process and normalize this data. In the end, a Lambda function updates the SNS topic that triggers messages to downstream Lambda functions for next steps through an SQS queue. You could have up to 100,000 invocations of this workflow per second to scale the data processing pipeline.

Automate steps of an ETL process
In this example, the Step Functions ETL workflow refreshes Amazon Redshift whenever new data is available in the source S3 bucket. The Step Functions state machine initiates an AWS Batch job and monitors its status for completion or errors. The AWS Batch job fetches the ETL workflow .sql script from the source i.e. Amazon S3 and refreshes the destination i.e. Amazon Redshift through a PL/SQL container. The .sql file contains the SQL code for each step in the data transformation.You can trigger the ETL workflow with an EventBridge event or manually through the AWS CLI or using AWS SDKs or even a custom automation script. You can alert an admin through SNS that triggers an email for failures at any step of the workflow or at the end of the workflow execution. This ETL workflow is an example where you can use Standard Workflows. See this example in detail here. You can learn more about submitting an AWS Batch job through a sample project here.

Run an ETL pipeline with multiple jobs in parallel
You can use Step Functions to run multiple ETL jobs in parallel where your source datasets might be available at different times, and each ETL job is triggered only when its corresponding dataset becomes available. These ETL jobs can be managed by different AWS services, such as AWS, Glue, Amazon EMR, Amazon Athena or other non-AWS services.
In this example, you have two separate ETL jobs running on AWS Glue that process a sales dataset and a marketing dataset. Once both datasets are processed,a third ETL job combines the output from the previous ETL jobs to produce a combined dataset.The Step Functions workflow waits until data is available in S3. While the main workflow is kicked off on a schedule, an EventBridge event handler is configured on an Amazon S3 bucket, so that when Sales or Marketing dataset files are uploaded to the bucket, the State Machine can trigger the ETL job “ProcessSales Data” or “ProcessMarketingData” depending on which dataset became available.

Large scale data processing
In this example, the Step Functions workflow uses a Map state in Distributed mode to process a list of S3 objects in an S3 bucket. Step Functions iterates over the list of objects and then launches thousands of parallel workflows, running concurrently, to process the items. You can use compute services, such as Lambda, helping you write code in any language supported. You can also choose from over 220 purpose-built AWS services to include in the Map state workflow. Once executions of child workflows are complete, Step Functions can export the results to an S3 bucket making it available for review or for further processing.

Machine Learning Operations
Run an ETL job and build, train and deploy a machine learning model
In this example, a Step Functions workflow runs on a schedule triggered by EventBridge to execute once a day. The workflow starts by checking whether new data is available in S3. Next, it performs an ETL job to transform the data. After that, it trains and deploys a machine learning model on this data with the use of Lambda functions that trigger a SageMaker job and wait for completion before the workflow moves to the next step. Finally, the workflow triggers a Lambda function to generate predictions that are saved to S3.

Automate a machine learning workflow using AWS Step Functions Data Science SDK
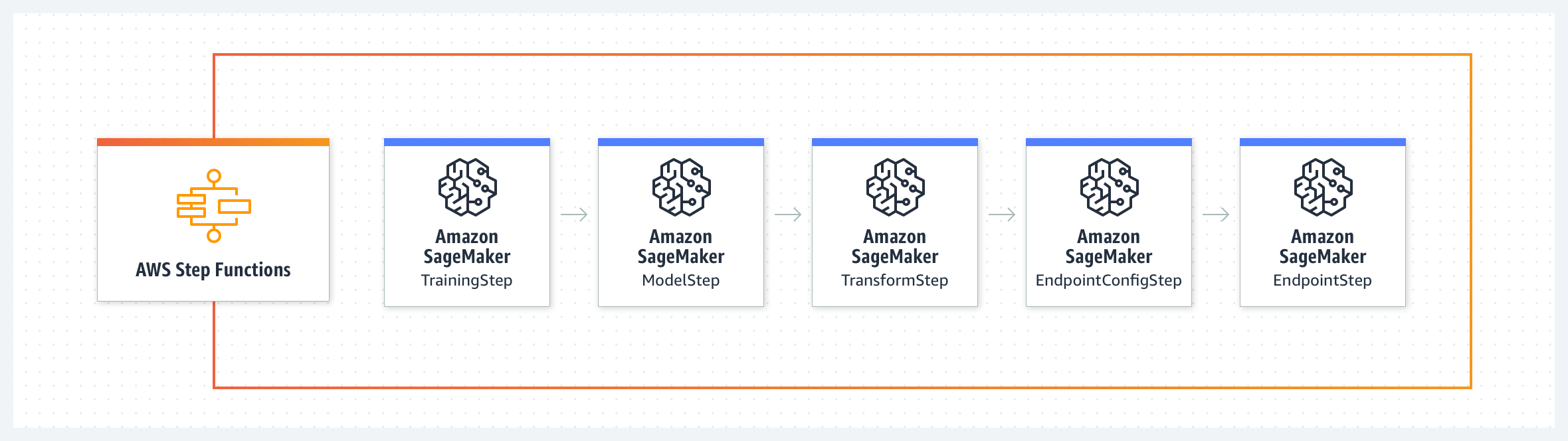
The AWS Step Functions Data Science SDK is an open-source library that enables you to create workflows that process and publish machine learning models using Amazon SageMaker and AWS Step Functions.The SDK provides a Python API that covers every step of a machine learning pipeline - train, tune, transform, model and configure endpoints. You can manage and execute these workflows directly in Python, and in Jupyter notebooks. The below example illustrates the train and transform steps of a machine learning workflow. The train step starts a Sagemaker training job and outputs the model artifacts to S3. The save model step creates a model on SageMaker using the model artifacts from S3. The transform step starts a SageMaker transform job. The create endpoint config step defines an endpoint configuration on SageMaker. The create endpoint step deploys the trained model to the configured endpoint. See the notebook here.
Media Processing
Extract data from PDF or images for processing
In this example, you will learn how to combine AWS Step Functions,AWS Lambda and Amazon Textract to scan a PDF invoice to extract its text and data to process a payment. Amazon Textract analyses the text and data from the invoice and triggers a Step Functions workflow through SNS, SQS and Lambda for each successful job completion. The workflow begins with a Lambda function saving the results of a successful invoice analysis to S3. This triggers another Lambda function that processes the analyzed document to see if a payment can be processed for this invoice, and updates the information in DynamoDB. If the invoice can be processed, the workflow checks if invoice is approved for payment. If its not, it notifies a reviewer through SNS to manually approve the invoice. If its approved, a Lambda function archives the processed invoice and ends the workflow. See this example along with its code in detail here.

Split and transcode video using massive parallelization
In this example, Thomson Reuters built a serverless split video transcoding solution using AWS Step Functions and AWS Lambda. They needed to transcode about 350 news video clips per day into 14 formats for each video clip - as quickly as possible. The architecture uses FFmpeg, an open source audio and video encoder that only processes a media file serially. In order to improve the throughput to provide the best customer experience, the solution was to use AWS Step Functions and Amazon S3 to process things in parallel. Each video is split into 3 second segments, processed in parallel and then put together at the end.
The first step is a Lambda function called Locate keyframes that identifies the information required to chunk the video. The Split video Lambda function then splits the video based on the keyframes and stores the segments into an S3 bucket. Each segment is then processed in parallel by Lambda functions and put into a destination bucket. The state machine follows the processing until all N segments are processed. It then triggers a final Lambda function that concatenates the processed segments, and stores the resultant video in an S3 bucket.

Build a serverless video transcoding pipeline using Amazon MediaConvert
In this example, we will learn how AWS Step Functions, AWS Lambda and AWS Elemental MediaConvert can be orchestrated together towards fully-managed transcoding abilities for on-demand content.This use case applies to companies with high volume or varying volumes of source video content that want to process video content in the cloud or want to move workloads to the cloud in the future.
The video-on-demand solution has three sub workflows triggered from a main Step Functions workflow:
- Ingestion: This could be an Express Workflow. A source file dropped in S3 triggers this workflow to ingest data.
- Processing: This workflow looks at the height and width of the video and creates an encoding profile. After processing, an encoding job is triggered via AWS Elemental MediaConvert.
- Publishing: The final step checks whether the assets are available in the destination S3 buckets and notifies the administrator that the job is complete.
