AWS Startups Blog
How Freebird Scaled Data Processing with AWS Step Functions – Express Workflows
(This article was authored by Pranjali Deshpande, Senior Product Manager on the AWS Step Functions team)
Imagine trying to find parking in a busy downtown area on a Friday night, or worse, being the designated driver who has to find and pay for that expensive parking spot! Rewards platform Freebird has a unique solution – get paid to go out with rides on Uber or Lyft sponsored by advertisers and businesses.
Freebird capitalizes on the popularity of ride-sharing for a night (or a day) around town. The service helps businesses in busy urban areas with limited parking spots increase footfall. Customers can get additional cash-back rewards for spending at those establishments by linking their payment method to the app. Everyone wins. Freebird is on a mission is to make transportation free and fun.

Adam Duro, CTO
As an early adopter of AWS Step Functions – Express Workflows (launched in Dec 2019), the startup moved their high-volume, low latency data processing workloads to an entirely serverless model, saving more than 33% in infrastructure costs and modernizing their application stack. They wanted workflows that ran at scale, required minimal operational overhead, and handled the complexities of their pipeline. The solution had to enable the development team to easily contribute and extend this workflow using tools and languages they were already familiar with. CTO Adam Duro walked us through the road the company took to arrive at this solution.
Duro first learned about AWS Step Functions – Express Workflows at AWS Re:Invent 2019 while looking for a micro-service orchestration solution. “One of the things that really sold me on AWS Step Functions was its first class support for running each step as a separate process (aka AWS Lambda), supporting parallelization (both branched and iteration), and that each step has built in error handling and retries,” he says.
The startup relies heavily on incoming data from ride-share providers such as Uber and Lyft. The structure of this incoming data varies based on the data source. Processing this data requires several steps, and potential failure cases need to be gracefully addressed. The startup needed a solution that could handle branching logic that required different steps based on the source of data being processed, and co-ordination with external APIs and handling errors when those external APIs have transient errors. They needed a detailed way to inspect these transient errors, and for certain ones, perform optimized retries with exponential backoff. They also needed to be able to monitor the workflow at very specific points so they could accurately determine if the failure rate was really a problem, or just the normal volume at which these external APIs fail. Before Express Workflows was launched, the dev team had zeroed in on two options to create such a workflow – use Apache Airflow or write the application code themselves.
The dev team chose to write the application code themselves by running the entire workflow within a single process running inside containers deployed to AWS EKS triggered by AWS CloudWatch scheduled events or cron jobs. They did this for about two years. The team struggled to achieve parallelization in the workflow without running the risk of a parallel branch throwing an unhandled exception which could bring down the entire workflow. The risk was further magnified as the workflow had to iterate over a set of records, and perform an operation on each item of the set. The process could get halfway through the set, and if one of the items failed, it would bring down the whole process, making it much harder to work with fail cases.
Next, they turned to Apache Airflow and used it for a year, until it became cumbersome to operate and maintain the servers. Having to manually provision, install, secure, monitor, patch, upgrade, and scale it needed dedicated resources with deep expertise that only one person on the development team had. The CTO saw the siloed expertise and heavy operational overhead as a major risk from the standpoint of investing further in the technology stack. These factors led them to a decision to re-platform their whole monolith backend architecture to be almost entirely serverless – except for their databases.
When migrating to AWS Step Functions, the startup was able to reuse some of its pre-written workflow code. “Working in this model also made our code easier to reason about,” says Duro. “Data structures could be flatter, and code is less littered with complex fail state handling code.”
Freebird utilized Express workflows due to the high volume of data that needed processing – realtime webhook data from ride-share providers. This incoming webhook data is sent to Amazon API Gateway. This data is pushed right into an Amazon Kinesis data stream using a direct integration with Amazon Kinesis. Pushing data directly into an Amazon Kinesis stream helps ensure data resilience. An AWS Lambda function is set up to pull data off this stream, and execute an AWS Step Functions – Express Workflow. This workflow goes through a complex chain of steps to validate, process, and normalize this incoming data. Ultimately, it is emitted to an SNS topic which downstream services can subscribe to. If something goes wrong downstream, Kinesis can replay the webhook events in the order they came in.
How Freebird Uses AWS Step Functions in its Data Processing Workflow
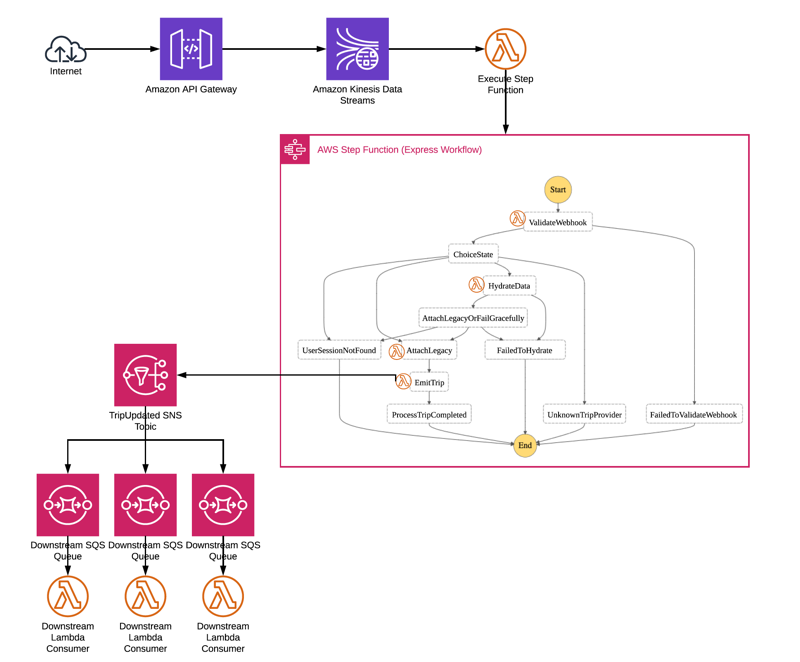
“AWS Step Functions, especially Express Workflows, has benefited us greatly. We are able to carefully handle known fail cases with retries and exponential back-off, ” Duro says. “Adding a new external source is as simple as adding one or two tasks to the workflow. The Step Functions integration with AWS Lambda allows us to leverage tools and languages that our team are already familiar with, and helps us maintain a serverless ops focus. We only pay for what we use at the request level, so when volumes are down, our costs go down.”
Looking ahead, AWS Step Functions-Express Workflows will help Freebird scale easily to adapt to additional third parties as well as process data for other business applications such as streaming data from marketing technology tools to analyze marketing spend.
Wondering how to build a serverless workflow using AWS Step Functions? Visit our resource page, which includes a detailed developer guide, reference architectures, and more.