O blog da AWS
Apresentando novas métricas de invocação assíncrona para o AWS Lambda
Hoje, a AWS está anunciando três novas métricas do Amazon CloudWatch para invocações assíncronas de funções do AWS Lambda: AsyncEventsReceived, AsyncEventage e AsyncEventsDropped. Essas métricas fornecem visibilidade para invocações assíncronas da função Lambda.
Anteriormente, os clientes achavam difícil monitorar o processamento de invocações assíncronas. Com essas novas métricas para invocações de funções assíncronas, você pode identificar a causa raiz dos problemas de processamento. Esses problemas incluem limitação, limite de simultaneidade, erros de função, latência de processamento devido a novas tentativas, eventos perdidos e ações corretivas.
Este blog e o aplicativo de exemplo fornecem exemplos que destacam o uso das novas métricas.
Visão geral

Serviços da AWS, como Amazon S3, Amazon SNS e Amazon EventBridge, invocam funções do Lambda de forma assíncrona. O Lambda usa uma fila interna para armazenar eventos. Um processo separado lê os eventos da fila e os envia para a função.
Por padrão, o Lambda descarta eventos de sua fila de eventos se a política de repetição exceder o número de novas tentativas configuradas ou se o evento atingir sua idade máxima. No entanto, o evento, uma vez descartado da fila de eventos, vai para o destino ou DLQ, se configurado.
Esta tabela resume o comportamento da nova tentativa. Visite a documentação de invocações assíncronas do Lambda para saber mais:
| Causa | Repetir o comportamento | Substituir |
| Erros de função (retornados do código ou do tempo de execução, como tempos limite) | Tente novamente duas vezes | Defina a tentativa de nova tentativa na função entre 0-2 |
| Throttles (429) e erros do sistema (5xx) | Tente novamente por no máximo 6 horas | Defina a idade máxima do evento na função entre 60 segundos e 6 horas |
| Concorrência reservada zero | Não tente novamente | N/A |
O que há de novo
A métrica AsyncEventsReceived é uma medida do número de eventos enfileirados na fila interna do Lambda. Você pode rastrear eventos do cliente usando métricas personalizadas do CloudWatch ou extraí-las dos registros usando o Embedded Metric Format (EMF). Caso essa métrica seja menor do que o número de eventos que você espera, ela mostra que a fonte não emitiu eventos ou que os eventos não chegaram ao serviço Lambda. Isso é possível devido a problemas transitórios de rede. O Lambda não emite essa métrica para eventos repetidos.
A métrica AsyncEventage é uma medida da diferença entre o momento em que um evento é enfileirado pela primeira vez na fila interna e o momento em que o serviço Lambda invoca a função. Com novas tentativas, o Lambda emite essa métrica toda vez que tenta invocar a função com o evento. Um valor crescente mostra novas tentativas devido a erros ou throttles. Os clientes podem definir alarmes nessa métrica para alertar sobre violações de SLA.
A métrica AsyncEventsDropped é uma medida do número de eventos descartados devido à falha no processamento.
Como usar as novas métricas de eventos assíncronos
Esse fluxograma mostra como você pode combinar as novas métricas com as existentes para solucionar problemas com o processamento assíncrono:

Exemplo de aplicação
Você pode implantar um exemplo de função do Lambda para mostrar como usar as novas métricas para solucionar problemas.
Para testar os seguintes cenários, você deve instalar:
Para configurar o aplicativo:
- Defina sua região da AWS:
- Clone o repositório do GitHub:
- Crie e implante o aplicativo. Forneça lambda-async-metric como nome da pilha quando solicitado. Mantenha todo o resto como valores padrão:
- Salve o nome da função em uma variável de ambiente:
- Invoque a função usando o AWS CLI:
- Todas as métricas em Métricas no painel esquerdo no console do CloudWatch e pesquise por “assíncrono”:

- Escolha Lambda > Por nome da função e escolha AsyncEventsReceived para a função que você criou. Em “Métricas representadas graficamente”, altere a estatística para soma e “Período” para 1 minuto. Você vê um registro. Depois de esperar alguns segundos, atualize se você não ver a métrica imediatamente.

Cenários
Esses cenários mostram como você pode usar as três novas métricas.
Cenário 1: Solução de problemas de atrasos devido a erro de função
O Lambda tenta processar novamente o evento de invocação assíncrona por no máximo duas vezes, em caso de erro ou exceção da função. O Lambda retira o evento de sua fila interna se as novas tentativas estiverem esgotadas.
Para simular um erro de função, lance uma exceção do manipulador Lambda:
- Edite o código da função em hello_world/app.py para gerar uma exceção:
- Crie e implante:
- Invoque a função:
É uma prática recomendada alertar sobre erros de função usando a métrica de erro e usar as métricas para obter melhores informações sobre o comportamento de novas tentativas, como o intervalo entre as novas tentativas. Por exemplo, se uma função errar devido à sobrecarga de um sistema downstream, você pode usar as métricas AsyncEventage e Concurrency.
Se você recebeu um alerta de erro de função, verá pontos de dados para AsyncEventsDropped. É 1 para esse cenário. A sobreposição das métricas Errors and Throttles reconfirma que o erro da função causa isso.

Há duas novas tentativas antes que o serviço Lambda cancele o evento. Nenhuma limitação confirma o erro da função. Em seguida, você pode confirmar que o AsyncEventage está aumentando. O Lambda publica essa métrica toda vez que faz uma pesquisa na fila de eventos e a envia para a função. Isso cria vários pontos de dados para a métrica.
Você pode duplicar a métrica para ver as duas estatísticas em um único gráfico. Aqui, as duas linhas se sobrepõem porque há apenas um ponto de dados publicado em cada intervalo de 1 minuto.

O evento passou 37 ms na fila interna antes da primeira tentativa de invocação. A primeira tentativa do Lambda acontece após 63,5 segundos. A segunda e última tentativa acontece após 189,6 segundos.
Cenário 2: Solução de problemas de atrasos devido aos limites de simultaneidade
Em caso de limitação ou erros do sistema, o Lambda tenta invocar novamente o evento até o maximumEventageInSeconds configurado (o máximo é de 6 horas). Para simular o erro de limitação sem atingir o limite de simultaneidade da conta, você pode:
- Defina a função de simultaneidade reservada como 1
- Introduza um intervalo de 90 segundos no código da função para simular uma execução longa da função.
O serviço Lambda acelera novas invocações enquanto a primeira solicitação está em andamento. Você invoca a função em rápida sucessão a partir da linha de comando para simular a aceleração e observar o comportamento de repetição:
- Defina a concorrência reservada da função como 1 atualizando o modelo do AWS SAM.
- Edite o código da função em hello_world/app.py para introduzir um sono de 90 segundos. Substitua o código existente pelo seguinte em app.py:
- Crie e implante:
- Invoque a função duas vezes consecutivas na linha de comando:
Em um caso de uso real, a falta do SLA de processamento deve acionar o fluxo de trabalho de solução de problemas. Comece com AsyncEventsReceived para confirmar eventos enfileirados pelo serviço Lambda. Isso é 2 nesse cenário. Procure eventos descartados usando a métrica AsyncEventsDropped.

O AsyncEventage verifica atrasos no processamento. Conforme mencionado na seção anterior, pode haver vários pontos de dados para essa métrica em um intervalo de um minuto. Você pode duplicar a métrica para comparar os valores mínimo e máximo.

Existem 2 pontos de dados no primeiro minuto. A idade do evento aumenta para 31 segundos durante esse período.

Há apenas um ponto de dados para a métrica nos intervalos restantes de um minuto, então as linhas se sobrepõem. A idade do evento aumenta para 59.153 ms (~ 59 segundos) em um intervalo e depois para 130.315 ms (~ 130 segundos) no próximo intervalo de um minuto. Como a função permanece suspensa por 90 segundos, isso explica por que a última tentativa ocorre em torno de 2 minutos desde que a função recebeu o evento.
Ao verificar a limitação da função, esta captura de tela confirma a aceleração seis vezes no primeiro minuto (horário das 07:12 UTC) e uma vez no minuto seguinte (horário das 07:13 UTC).

Isso se deve ao comportamento de recuo da fila interna do Lambda. Os dados de AsyncEventage mostram que há apenas um acelerador no segundo intervalo. O Lambda entrega o evento durante o próximo intervalo de um minuto depois de passar cerca de 2 minutos na fila interna.
A sobreposição das métricas ConcurrentExecutions e AsyncEventsReceived fornece mais informações. Você vê o recebimento de dois eventos, mas a simultaneidade permaneceu em 1. Isso resulta na limitação de um evento:
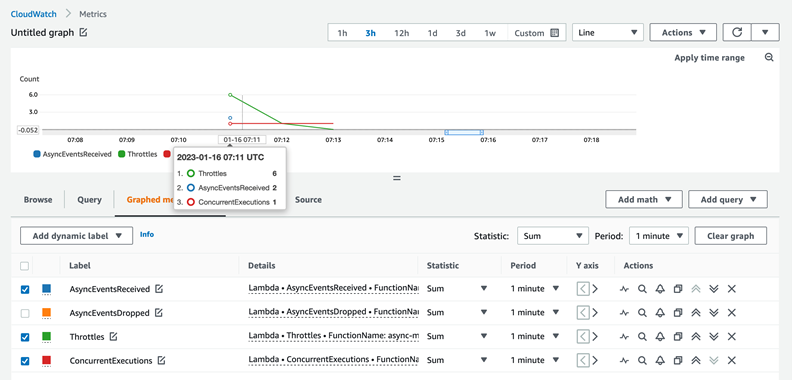
Há várias maneiras de resolver erros de limitação. Você otimiza a função para ser executada mais rapidamente ou aumenta os limites de simultaneidade da função ou da conta para solucionar erros de limitação.
O aplicativo de exemplo abrange outros cenários, como solução de problemas de eventos perdidos na expiração do evento e solução de problemas de eventos descartados quando a simultaneidade reservada de uma função é definida como zero.
Limpando
Use o comando a seguir e siga as instruções para limpar os recursos:
Conclusão
Usando essas novas métricas do CloudWatch, você pode obter visibilidade do processamento de invocações assíncronas do Lambda. Este blog explicou as novas métricas AsyncEventsReceived, AsyncEventage e AsyncEventsDropped e como usá-las para solucionar problemas. Com essas novas métricas, você pode rastrear as solicitações de invocação assíncrona enviadas às funções do Lambda. Você monitora quaisquer atrasos no processamento e toma medidas corretivas, se necessário.
O serviço Lambda envia essas novas métricas para o CloudWatch sem nenhum custo para você. No entanto, cobranças se aplicam aos CloudWatch Metric Streams e aos alarmes do CloudWatch. Consulte os preços do CloudWatch para obter mais informações.
Para obter mais recursos de aprendizado Serverless, visite Serverless Land.
Este artigo foi traduzido do Blog da AWS em Inglês.
Sobre o autor
 Arthi Jaganathan, Principal SA, Serverless
Arthi Jaganathan, Principal SA, Serverless
 Dhiraj Mahapatro, Principal SA, Serverless
Dhiraj Mahapatro, Principal SA, Serverless
Tradutor
 Rodrigo Peres é um Solutions Architect na AWS, com mais de 20 anos trabalhando com arquitetura de soluções, desenvolvimento de sistemas e modernização de sistemas legados.
Rodrigo Peres é um Solutions Architect na AWS, com mais de 20 anos trabalhando com arquitetura de soluções, desenvolvimento de sistemas e modernização de sistemas legados.