O blog da AWS
Como governar assets não gerenciados com Amazon DataZone
Por Nayra Gomes, Arquiteta de Soluções na AWS Brasil e Vinicius Batista, Arquiteto de Soluções Sr da AWS Brasil no time de Setor Público com foco em Governo.
A governança de dados em ambientes híbridos representa um grande desafio para organizações que possuem sistemas on-premises e também sistemas em nuvem. Muitas empresas desejam centralizar a descoberta e o acesso a dados que residem tanto em datacenters corporativos, quanto na AWS.
O Amazon DataZone oferece uma solução para catalogação e governança de dados na nuvem, mas como governar dados que residem em ambientes on-premise e não podem ser replicados para a nuvem? Este post demonstra uma solução que permite integrar dados corporativos on-premises ao Amazon DataZone, centralizando a governança através de uma arquitetura serverless e totalmente gerenciada.
Visão geral da solução
O Amazon DataZone permite que os usuários publiquem dados, chamados de assets (ativos) em um catálogo de dados, que permite gerenciar a descoberta, compartilhamento e governança dos dados de forma centralizada. O Amazon DataZone gerencia automaticamente dados como tabelas e visualizações do Amazon Redshift, catálogos de dados do AWS Glue, sendo chamados de assets gerenciados. Todos os outros assets aos quais o Amazon DataZone não pode conceder acessos automaticamente são chamados de assets não gerenciados. Para esse tipo de asset, o Amazon DataZone fornece um caminho para você fazer a gestão de acessos através da integração com o Amazon EventBridge, como mostrado nesse blogpost.
O Amazon EventBridge é um serviço serverless que usa eventos para conectar componentes de uma aplicação, facilitando a criação de aplicativos escaláveis orientados por eventos. O Amazon EventBridge se integra nativamente com outros AWS serviços para processar eventos ou invocar um recurso como alvo (target) de uma regra.
Através do Amazon EventBridge, podemos invocar múltiplos serviços, incluindo funções do AWS Lambda, um serviço de computação sem servidor (serverless) orientado a eventos, que permite executar código para praticamente qualquer tipo de aplicação, sem provisionar ou gerenciar servidores. Quando a assinatura de um asset no catálogo de dados de negócios é aprovada pelo proprietário dos dados, o Amazon DataZone publica um evento no Amazon EventBridge, junto com as informações do pedido em seu payload. Ao receber esse evento, a aplicação pode acionar um processo personalizado, que usa as informações do evento para criar as concessões necessárias pode ser acionado. Na arquitetura apresentada, usamos o AWS Lambda como manipulador, o que permite a customização através do SDK em python da AWS (boto3).
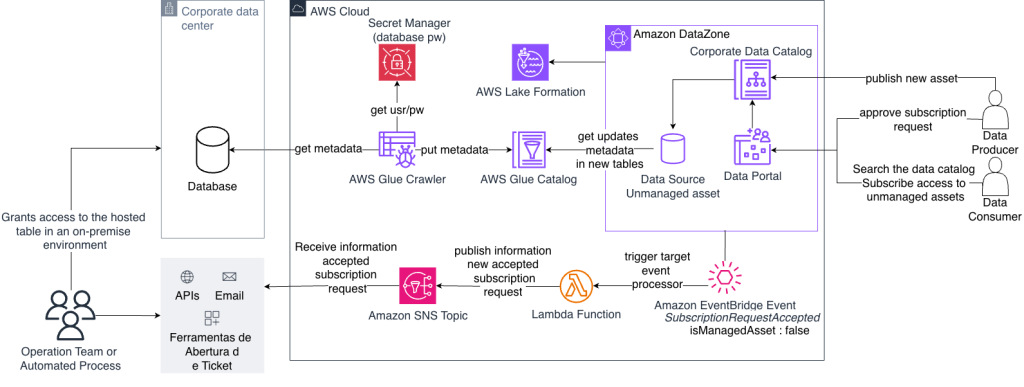
Arquitetura Geral da Solução
Essa arquitetura utiliza os seguintes serviços:
- AWS Glue Crawler para catalogação automática de schemas das fontes de dados
- Amazon DataZone como portal central de governança de dados
- Amazon EventBridge e AWS Lambda para processamento de eventos de subscrição
- Amazon Simple Notification Service (SNS) para envio de mensagens de eventos de forma assíncrona por meio de um tópico
- AWS Lake Formation para controle de permissões em conjunto com o Amazon DataZone
Implementação passo a passo
Para implementar a solução, considere as seguintes etapas:
- Deploy dos seguintes recursos: um domínio do Amazon DataZone contendo 2 projetos (ProjetoAnalytics e ProjetoML), e um banco de dados postgresql (rodando em uma instância do Amazon EC2). Definimos esses recursos usando o AWS CDK (Cloud Development Kit), em linguagem python.
- Verificação da origem de dados no AWS Glue Data Catalog.
- Inclusão do usuário consumidor no projeto Analytics criado via portal de dados.
- Publicação de um asset não gerenciado no projeto ML, criado via portal de dados.
- Pesquisa, solicitação e concessão de acesso ao asset não gerenciado.
- Envio do evento através do Amazon EventBridge e função do AWS Lambda para um tópico do Amazon SNS.
- Recebimento de notificação por email sobre aprovação de um novo acesso a um asset.
Link para o repositório no GitHub.
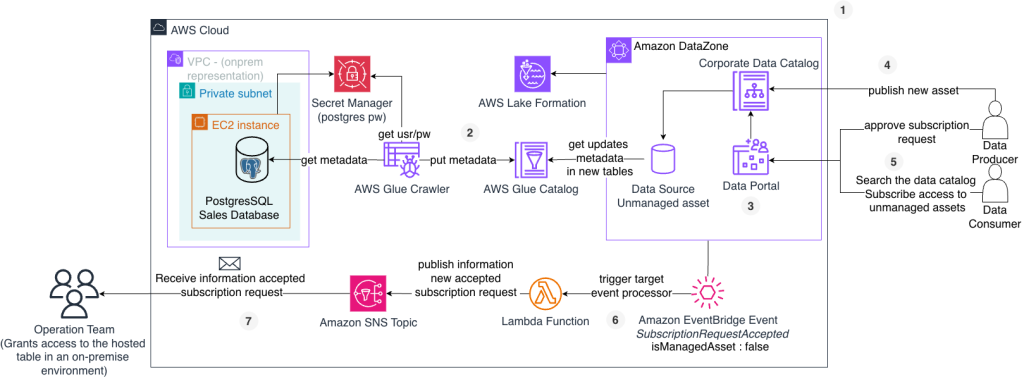
Passo a passo da implementação da solução
Pré requisitos
- Uma conta ativa na AWS.
- AWS CLI instalado. Para esse blogpost, recomendamos utilizar uma máquina com sistema operacional Linux ou MacOS.
- GNU Make
- Python versão 3.12 ou superior.
- Usuário com permissões para acessar os serviços.
- Uma instância do AWS IAM Identity Center configurado na conta. O AWS IAM Identity Center é necessário para centralizar o acesso via single sign-on (SSO) dos usuários ao portal do Amazon DataZone.
Etapa 1: Preparar o Ambiente
Clone o repositório e configure o ambiente Python conforme indicado no README do projeto e configure as variáveis de contexto em cdk.context.json:
| datazone_user_role_arn | arn:aws:iam::ACCOUNT-ID:role/***** | Arn da role de um usuário que que será proprietário do domínio do Amazon DataZone. Como proprietário esse usuário é membro de todos os projetos criados nesse domínio e pode administrar o Portal de Dados. |
| datazone_idc_instance_arn | arn:aws:sso:::instance/ssoins-********* | Arn da instância do IAM Identity Center (IDC) provisionada na conta, o portal de dados permitirá autenticação de usuários e grupos usando SSO. |
| identity_store_id | d-********* | Id do identity store da Instância do IDC provisionada na conta |
| lake_formation_admin_role_arn | arn:aws:iam::ACCOUNT-ID:role/***** | Arn da role que será Administrador do Data Lake no AWS LakeFormation, esse usuário pode conceder permissões a usuários as base de dados (*pub_db e *sub_db) e tabelas do AWS Glue Data Catalog que são gerenciadas pelo Amazon DataZone via AWS LakeFormation |
| sns_email | teste@teste.com | Endereço de e-mail que receberá o evento que uma aprovação de acesso a um asset não gerenciado foi realizada |
| region | sa-east-1 | Região de deploy da infraestrutura |
| datazone_domain_name | minha-empresa-ponto-com | Nome do domínio do portal de dados do Amazon DataZone |
| datazone_domain_description | Portal de dados da Minha Empresa.com | Descrição do domínio |
| datazone_project_names | ProjetoAnalytics,ProjetoML | Nomes dos projetos que serão criados dentro do domínio separados por vírgula |
| datazone_project_descriptions | Projeto para analises de dados,Projeto para machine learning | Descrições dos projetos separados por vírgula |
| stack_name | DataZoneCFStack | Nome da stack do AWS CloudFormation |
| enable_unmanaged_dataset | True | Habilita o deploy de um asset não gerenciado (dataset de sales usando postgresql em uma instância do Amazon EC2) |
| project_name_for_unmanaged_dataset | ProjetoML | Nome do projeto que será proprietário do asset não gerenciado |
Faça o deploy da solução que provisionará a arquitetura para esse blogpost. Siga os passos do arquivo README, para obter as instruções necessárias.
Etapa 2: Verificação da Origem de Dados
- Na console da AWS, navegue até o serviço AWS Glue. No menu esquerdo selecione Connections em Data Catalog.
- Selecione a conexão postgres-sales-connection na tabela Connections.
- Verifique a URL de conexão com o banco de dados Postgresql provisionado na Etapa 1 em: jdbc:postgresql://<ip da instância EC2 com PostgresSql>:5432/salesdb. Essa conexão é usada pelo Crawler do AWS Glue que captura os metadados da base de dados.

- O banco de de dados de vendas possui duas tabelas: Customers e Product, que o crawler populou, e seus metadados podem ser observados navegando em Data Catalog > Databases. Selecione o database environmentdatalakeprojetoml_pub_db, que possui duas tabelas com os nomes de unmanaged_table_salesdb_public_customers e unmanaged_table_salesdb_public_products
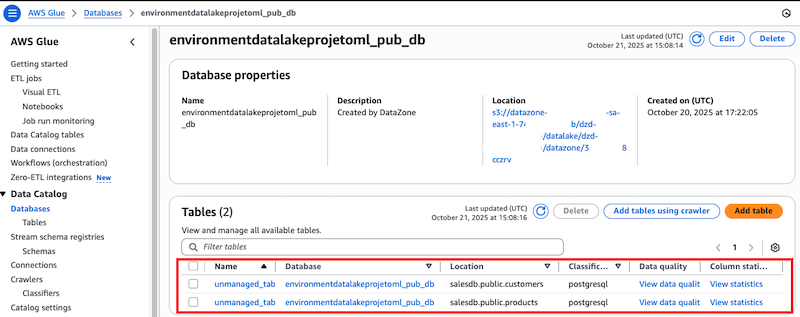
Utilizaremos esses dados adiante como origem de dados para a publicação de dados não gerenciados.
Etapa 3: Inclusão do usuário consumidor
- Faça a criação de um usuário consumidor (consumer, nesse exemplo) no AWS Identity Center. Não são necessárias permissões adicionais.
- Após isso, acesse o Amazon DataZone na console AWS. Acesse o menu Domains e na lista de domínios, selecione Open data portal. Note que seu usuário da console da AWS deve ter a mesma role do IAM informada no parâmetro datazone_user_role_arn do arquivo cdk.content.json (definido na Etapa 1).

- Realizado o login, selecione o projeto ProjetoAnalytics e selecione Members > Add Members.
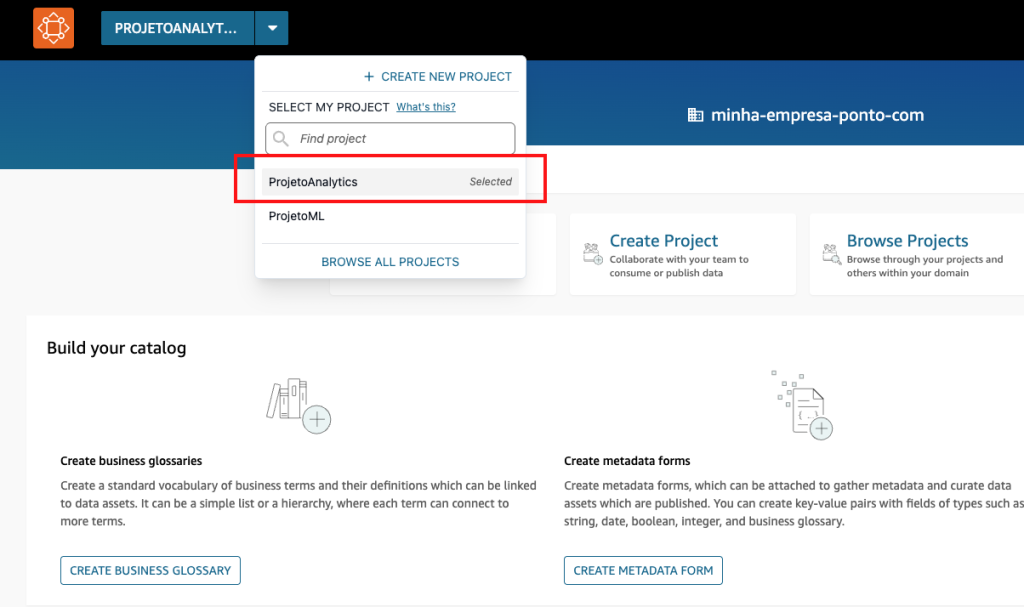
- Adicione o usuário consumidor do SSO como Contributor do projeto de Analytics.
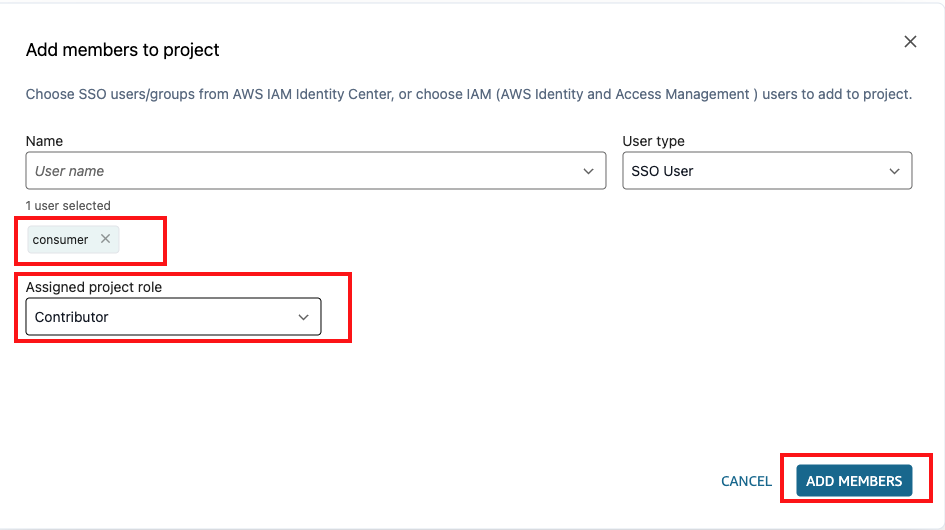
Agora o usuário consumer pode solicitar acesso a asset de outros projetos em nome do Projeto de Analytics.
Etapa 4: Publicação de um asset não gerenciado
- Selecione o projeto ProjetoML e navegue ate Data Sources.

- Em seguida, selecione EnvironmentDataLakeProjetoML-default-datasource que possui em sua definição:
- Data source type: AWS Glue (Lakehouse)
- Database name: environmentdatalakeprojetoml_pub_db (Mesmo database verificado na etapa 2)
- Clique em Run para encontrar as tabelas de customers e products disponíveis no banco de dados “sales” do postgresql. Aguarde até que o status mude para completed.

- Clique no asset com nome “unmanaged_table_salesdb_public_customers” e observe os metadados técnicos provenientes da origem do AWS Glue Table.
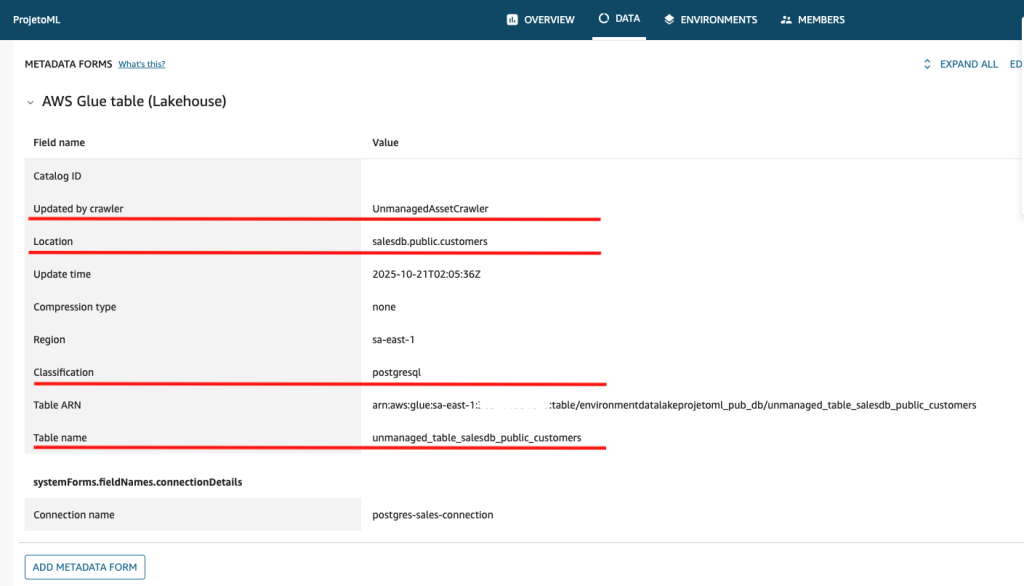
- Edite:
- Nome do Asset:
Customer Data Unmanaged Table - Descrição do Asset:
Main table that stores customer registration data in the sales system. Contains essential information such as personal data, contact details, and addresses of both active and inactive customers of the organization. This table serves as the central reference for all customer-related operations in the sales database.**This table is not an asset managed for Amazon DataZone.** - E adicione no campo README:
Notice This data source is not managed by the data platform as it resides in an on-premises environment. Access Process Submit your access request. After data owner approval, an internal company ticket will be created and the IT team will provide your credentials via email. Support For access inquiries contact the data owner. Unauthorized access attempts are not permitted.

- Nome do Asset:
- No canto superior direito da tela, clique em Publish Asset para tornar esse asset disponível e pesquisável por consumidores. Para confirmar a publicação, uma mensagem de Unmanaged asset aparecerá. Essa mensagem indica que esse asset não é gerenciado, e portanto não é possível adicioná-lo no environment de outros projetos (por exemplo: um workgroup do Amazon Athena para executar consultas). Essa mensagem é esperada pois a origem dos dados (banco de dados Postgresql) não é um asset gerenciado.
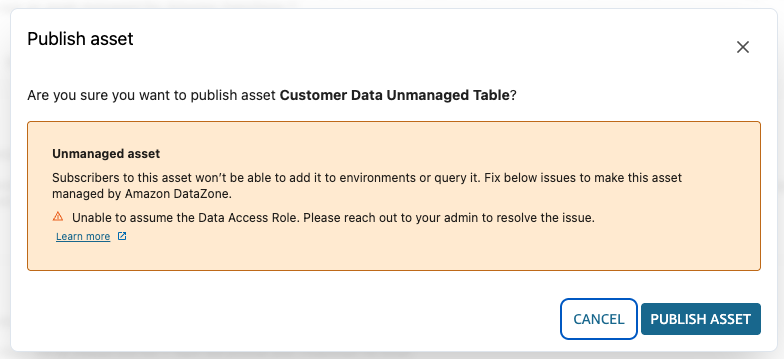
- Clique em Publish Asset para prosseguir.
Etapa 5: Pesquisa, solicitação e concessão de acesso
- Para pesquisar e solicitar acesso ao asset Customer Data Unmanaged Table que foi publicado na etapa anterior, faça login com o usuário Consumer (mesmo usado na etapa 3).
- Na barra de pesquisa, pesquise por Customer e selecione o asset Customer Data Unmanaged Table.

- Solicite acesso ao asset, preenchendo as informações da tela Request Subscription. Em projeto, selecione ProjetoAnalytics, que permitirá que todos os membros do projeto tenham acesso a essa tabela. Insira uma justificativa e submeta a solicitação clicando em Request.
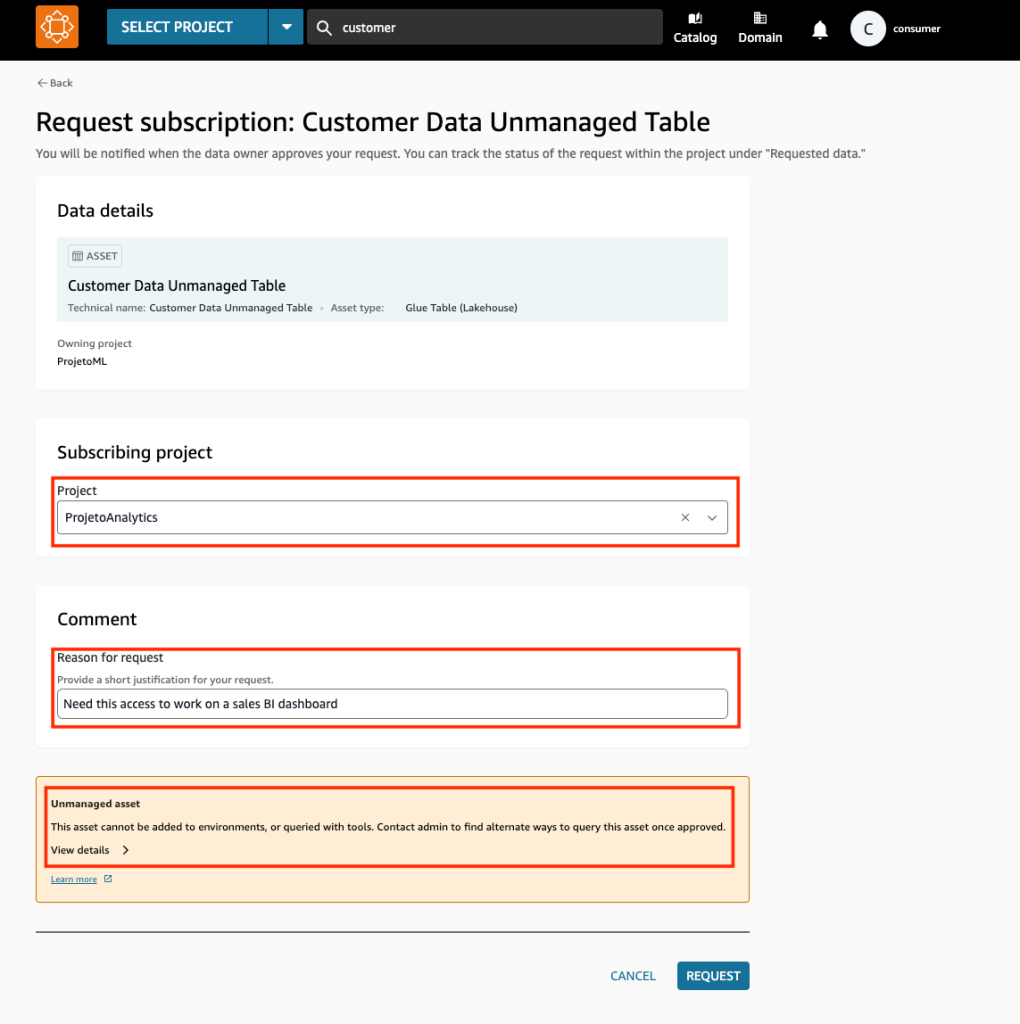
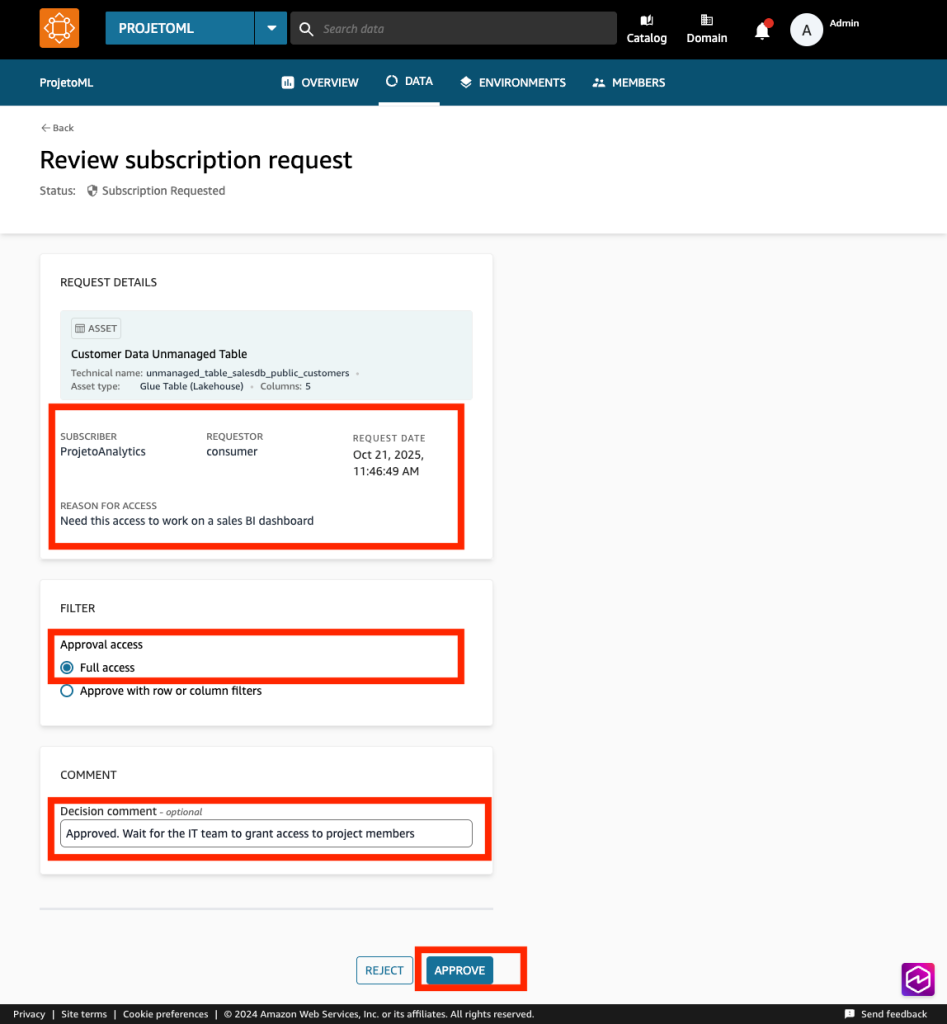
- Faça login novamente com o mesmo usuário que possua a role datazone_user_role_arn. Observe que a solicitação de acesso à tabela Customer Data Unmanaged Table foi feita para o projeto ProjetoAnalytics.
- Preencha os campos solicitados e clique em Approve.
No menu lateral esquerdo, em Incoming Request é possível ver o histórico e o status da solicitação.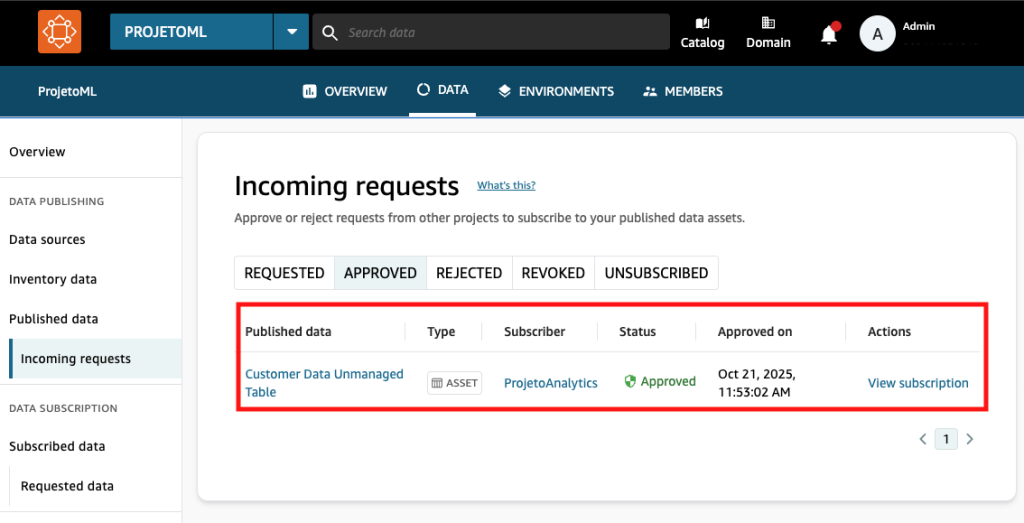
Com a aprovação do Proprietário do asset, um evento é disparado pelo Amazon EventBridge.
6. Envio do evento
Criamos uma regra no Amazon EventBridge para acionar uma função Lambda que consolidará as informações da solicitação do asset.
Regras no Amazon EventBridge são as definições sobre como os eventos (mensagens) que chegam a um barramento são roteados para targets (destinos) específicos. Elas recebem eventos de entrada e, à medida que os eventos correspondem a um padrão definido na regra, o Amazon EventBridge então encaminha o evento para os destinos para processamento.
- Na console da AWS, navegue para o Amazon EventBridge. No menu principal, selecione Rules. No quadro “Rules on default even bus”, clique em DataZoneCFStack-EventBridgeDataZoneSubscriptionRule-******
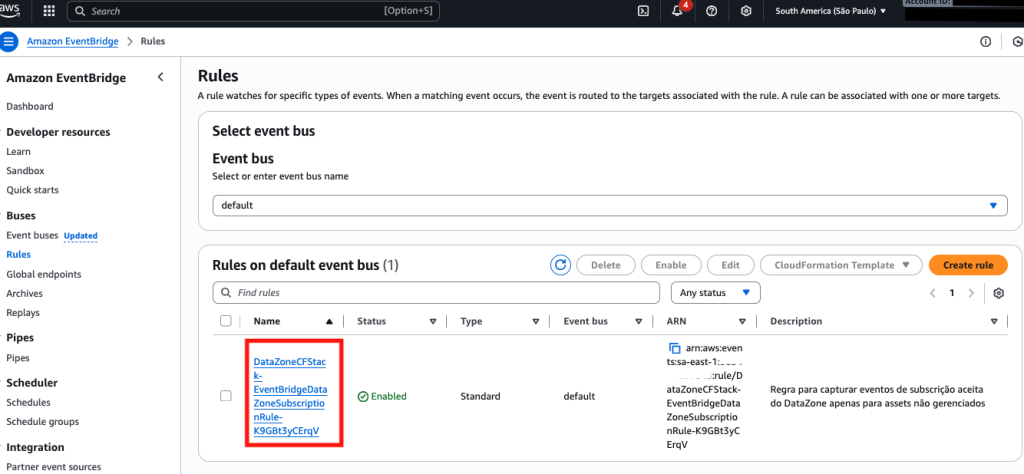
- No Event Pattern foi definido a função Lambda EventProcessorFunction é invocada somente se evento conter em seu campo “detail-type” o valor “Subscription Request Accepted”. Tais eventos são gerados somente quando um uma solicitação de subscrição é aceita pelo produtor do asset, conforme exemplo.
{
"detail-type": ["Subscription Request Accepted"],
"detail": {
"metadata": {
"domain": ["dzd-6fkxl*******"]
},
"data": {
"isManagedAsset": [false]
}
},
"source": ["aws.datazone"]
}
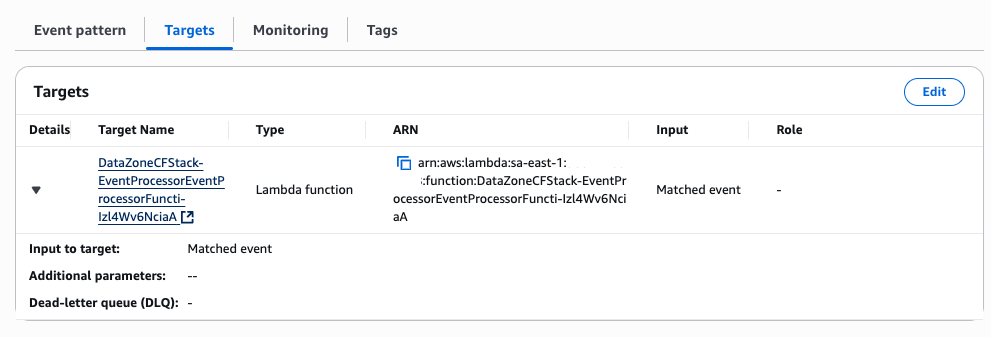
- A função lambda receberá um evento similar ao JSON abaixo:
{ "version": "0", "id": "********-73e6-2260-*********", "detail-type": "Subscription Request Accepted", "source": "aws.datazone", "account": "**********", "time": "2025-07-20T18:19:43Z", "region": "sa-east-1", "resources": [], "detail": { "version": null, "internal": null, "metadata": { "id": "6d5m6a*******", "domain": "dzd_6s1nnz*******", "awsAccountId": "**********", "owningProjectId": "5jf3xu*********" }, "data": { "autoApproved": false, "isManagedAsset": false, "requesterId": "*******-a001-70a7-ebce-********", "reviewerId": null, "status": "ACCEPTED", "subscribedListings": [ { "description": null, "id": "5bh6x1*********", "item": { "assetListing": { "assetScope": null, "assetScopeId": null, "entityId": "5u4crq********", "entityType": "GlueTableAssetType", "entityVersion": null, "forms": null, "glossaryTerms": null }, "productListing": null }, "name": null, "namespace": null, "ownerProjectId": "5jf3xu********", "ownerProjectName": null, "version": "2" } ], "subscribedPrincipals": [ { "id": "5jf3xu9******", "name": null, "type": "PROJECT" } ] } } }
A partir desse payload, é possível extrair via função do AWS Lambda os dados relevantes. Por exemplo:
- Metadados técnicos dos assets não gerenciados: Usando a API GetAsset , com o parâmetros –domain-identifier e –identifier (“entityId”: $ASSET_ID).
- Informações de membros que devem receber acesso: Através da API ListProjectMemberships, com parâmetros –domain-identifier e –project-identifier (Presente no evento no campo “subscribedPrincipals” : “id”: “$PROJECT_ID”).
- Perfil do usuário para capturar as roles e usuários do SSO dos membros do projeto – Usando API GetUserProfile com os parâmetros –domain-identifier e –user-identifier (presente na API listProjectMemberships no campo “memberDetails”: “user”: “userId”: $USER_ID).
- Informações como Usuário e E-mail vindos do AWS IAM ou IAM IdentityCenter – Usando API GetUser (AWS IAM) e API DescriberUser (IAM Identity Center).
Uma implementação prática dessa função pode ser encontrada no repositório do projeto, ou observada na console AWS, através função DataZoneCFStack-EventProcessorEventProcessorFuncti-***** no AWS Lambda.
Exemplo da função de processamento do evento
7. Recebimento dos dados
Quando um asset não gerenciado é publicado no Amazon DataZone, o sistema envia por e-mail as informações necessárias para conceder acesso no ambiente on-premises através de um tópico do Amazon SNS.
O Amazon SNS é um serviço totalmente gerenciado que fornece entrega de mensagens de editores (produtores) para assinantes (consumidores). Os publicadores se comunicam de maneira assíncrona com os assinantes produzindo e enviando mensagens para um tópico, que é um canal de comunicação e um ponto de acesso lógico. Os assinantes de um tópico podem receber mensagens por meio de diferentes endpoints, como: Uma fila do Amazon SQS, uma função Lambda, Endpoints HTTP(S), Notificações por push para dispositivos móveis ou um endereço de E-mail.
O processo de envio e recebimento dos eventos é flexível e pode ser adaptado para integrar com sistemas de gerenciamento de chamados ou workflows que concedam acessos automaticamente usando uma API com o Endpoint HTTP do Amazon SNS, proporcionando maior eficiência ao time de operações. Após a aprovação da subscrição no endereço de e-mail cadastrado, você receberá um JSON contendo todas as informações relevantes, incluindo detalhes sobre o novo acesso concedido ao grupo de consumidores de dados. Esta solução simplifica o processo de gerenciamento de acessos, garantindo que todas as informações necessárias estejam prontamente disponíveis para a equipe responsável.
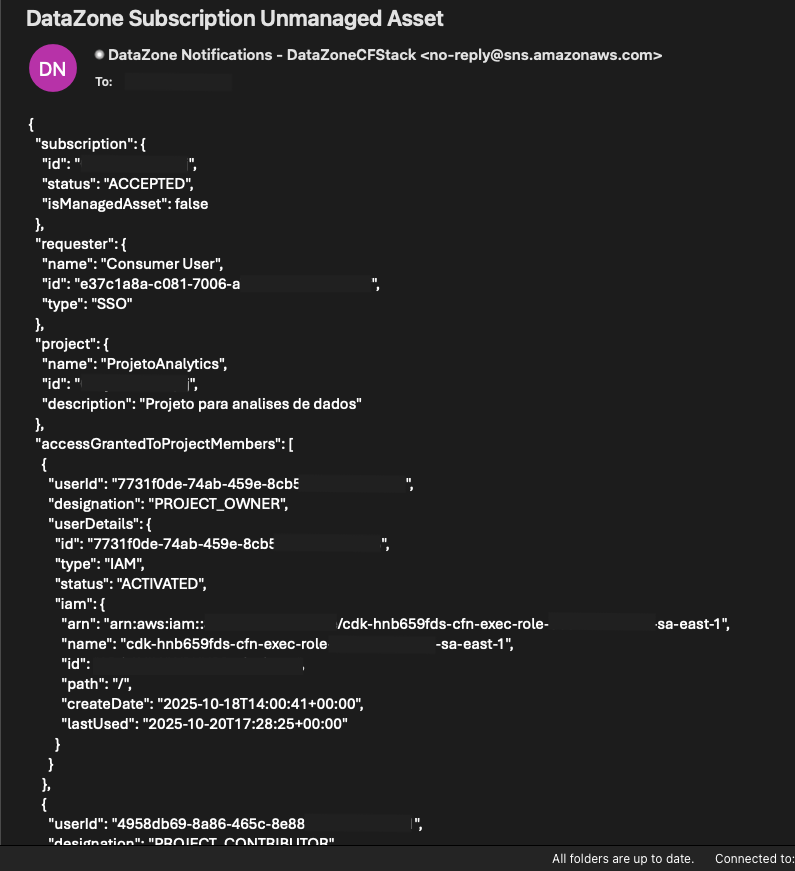
Uma cópia do evento completo, em formato json pode ser encontrada no repositório do github.
Com essas informações, é possível identificar quem aprovou o acesso ao asset, quem solicitou o acesso, informações sobre os membros do projeto que receberam acesso, assim como as informações do próprio asset, como banco de dados, tabela e colunas. Essa solução permite que assets não gerenciados como aqueles que residem em ambientes on-premises, sem replicação para a AWS possam ser catalogados e governados a partir de um serviço central como o Amazon DataZone.
Limpeza
Para evitar custos desnecessários, remova os recursos criados nesse blogpost usando o passo a passo descrito na seção Limpeza no README do repositório do projeto.
Para executar a limpeza automatizada, execute: make undeploy-solution
Caso prefira o processo manual, siga as seguintes instruções:
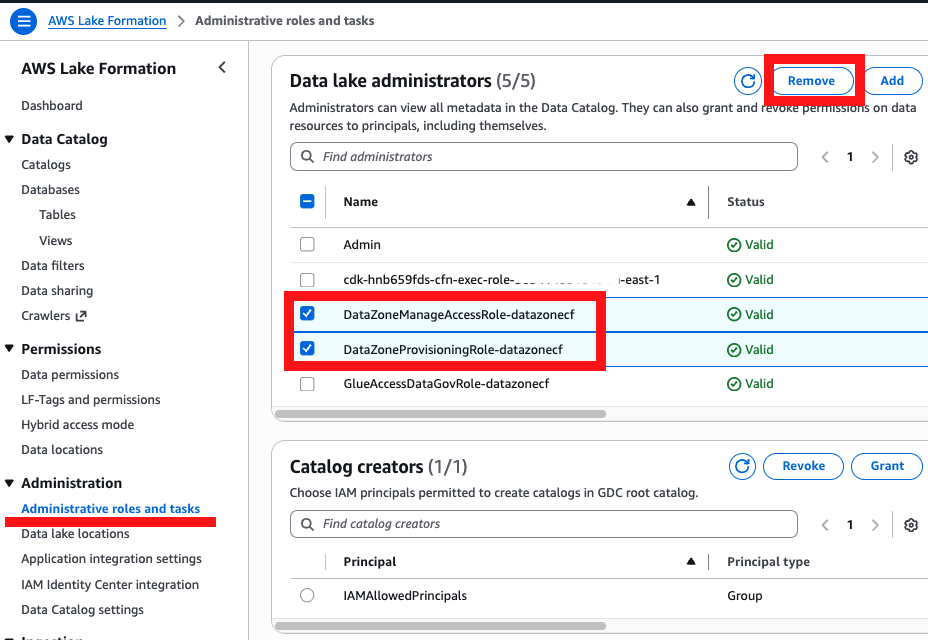
- Na console da AWS, navegue até o serviço AWS LakeFormation. No menu lateral esquerdo, navegue em Administration > Administrative roles and tasks > Data lake administrators, e remova as roles que começam com DataZoneManageAccessRole e DataZoneProvisioningRole.
- Após, execute o comando
cdk destroy - Quando a stack for completamente removida, é necessário acessar a console da AWS, acessar o Amazon DataZone e remover o domínio.
Quando um ambiente é criado em um projeto, o Amazon DataZone cria recursos em seu domínio para fornecer funcionalidade aos usuários. Abaixo está a lista de recursos que o Amazon DataZone criou para os projetos de Analytics e ML. Excluir um domínio não remove nenhum desses recursos da conta, e portanto, também devem ser excluídos manualmente.
- Perfis do IAM: datazone_usr_<environmentId>.
- Banco de dados do Glue: (1) <environmentName>_pub_db-*, (2) <environmentName>_sub_db-*.
- Grupos de trabalho do Athena: <environmentName>-*.
- CloudWatch grupo de registros: datazone_ <environmentId>
Conclusão
Este artigo demonstrou como a integração de dados on-premises com Amazon DataZone oferece benefícios para as organizações, tais como, governança centralizada, através de um portal único para descoberta de dados híbridos, além de automação na catalogação e processamento de eventos, tudo isso apoiado por uma arquitetura serverless que escala conforme a demanda. Esta integração permite que as organizações mantenham suas fontes de dados no ambiente on-premises enquanto aproveitam os benefícios da governança moderna de dados usando a nuvem. Para aprofundar seus conhecimentos sobre esta solução, recomendamos consultar a documentação oficial do Amazon DataZone e explorar o código fonte disponível no GitHub.
Autores
 |
Nayra Gomes é Arquiteta de Soluções na AWS Brasil no time de Setor Público com foco em Governo. Tem especial interesse por aplicações orientada a eventos e arquiteturas cloud native. |
 |
Vinicius Batista é Arquiteto de Soluções Sr da AWS Brasil no time de Setor Público com foco em Governo. Tem especial interesse por desenvolvimento de aplicações em nuvem e resiliência. |