O blog da AWS
Minimizando alucinações em orquestrações multi-agentes
Por Neuton Assis, Enterprise Solutions Architect, AWS AGS.
Os agentes de IA representam uma mudança fundamental em como construímos sistemas inteligentes. Diferentemente de aplicações monolíticas que centralizam toda a lógica em um único modelo, agentes especializados podem executar tarefas específicas com precisão, autonomia e adaptabilidade. Esta abordagem abriu novas possibilidades de arquitetura: sistemas que podem decompor problemas complexos em subtarefas, que podem usar ferramentas específicas para cada contexto e que podem tomar decisões baseadas em informação em tempo real. Nos últimos meses, arquiteturas multi-agentes evoluíram significativamente, com serviços como Amazon Bedrock AgentCore, modelos com uso de tool avançado e frameworks de orquestração emergentes demonstrando que agentes não apenas funcionam isoladamente, mas podem trabalhar juntos de forma coordenada para resolver problemas em que um agente isolado teria grande dificuldade para resolver. Adicionalmente, o surgimento de Small Language Models (SLMs) especializados tem complementado essa evolução. Com eles, agentes individuais operam de forma mais eficiente e econômica em tarefas específicas dentro da arquitetura multi-agentes: veja mais detalhes neste artigo da NVIDEA. Esta evolução abriu novas oportunidades para empresas que buscam automatizar processos complexos, criar sistemas mais resilientes e escalar inteligência artificial de forma granular e controlada.
Introdução
Nesta experimentação que fiz, construindo um pipeline de dados com três agentes especializados (extração, análise e geração de relatório), observei um problema recorrente: o agente extrator, em vez de apenas extrair dados, começava a analisar, visualizar e modelar previsões. O cientista de dados refazia essas análises e criava seus próprios gráficos. O gerador de relatórios ficava confuso com múltiplos arquivos conflitantes. O resultado final não correspondia à solicitação original.
Esse comportamento, que aqui chamo de alucinação em cenário de orquestração, não é falha do modelo de linguagem em si. É um problema arquitetural que surge por falta de contexto apropriado, comunicação inadequada entre agentes ou ausência de limites explícitos sobre responsabilidades. Este post documenta os desafios encontrados, os experimentos realizados e as práticas que se mostraram eficazes para minimizar essas alucinações. Os experimentos usam o framework Strands Agents com modelos disponíveis no Amazon Bedrock.
O paradoxo da autonomia
O núcleo do problema é um paradoxo arquitetural que se manifesta diferentemente conforme o cenário de orquestração.
Agentes locais com contexto compartilhado: quando os agentes operam no mesmo runtime, utilizando a tool Swarm do Strands Agents, o problema de alucinação diminui. Os agentes têm acesso natural ao estado compartilhado e entendem implicitamente seus papéis. Porém, como veremos nos resultados, essa abordagem tem trade-offs reais: em 2 de 5 execuções, o volume de dados acumulado excedeu o limite máximo da janela de contexto do modelo.
Agentes distribuídos com contexto acumulado: em arquiteturas distribuídas, a reação comum é compensar a falta de contexto compartilhado passando todo o histórico para cada agente. Essa lógica se revela problemática: o orquestrador chama o primeiro agente e recebe um resultado; chama o segundo passando o contexto original mais esse resultado; o terceiro recebe tudo acumulado. O que começou com centenas de tokens cresce exponencialmente. Quando a janela de contexto fica preenchida com histórico acumulado, a qualidade se degrada, a latência aumenta e — paradoxalmente — a taxa de alucinação pode aumentar.
Contexto certo vs contexto completo
Essa observação nos leva a um princípio central: agentes não precisam de todo o contexto, mas do contexto certo para sua execução.
Um agente extrator não precisa conhecer quais análises estatísticas serão realizadas posteriormente. Precisa saber onde encontrar os dados e qual estrutura aplicar durante a extração. Um agente analisador não precisa do arquivo bruto original nem do histórico de tentativas — precisa dos dados já extraídos em formato estruturado e instruções claras sobre qual análise realizar.
Abaixo, um exemplo de implementação Agent-As-Tool com template de contexto selecionado:
from strands import Agent, tool
from strands_tools import python_repl, file_read, file_write
A2A_PROMPT_TEMPLATE = """VOCÊ ESTÁ EM MODO COLABORATIVO COM OUTRO AGENTE.
Sua tarefa: {task}
Dados de contexto: {context_data}
Retorno esperado: {output_specification}
Critério de sucesso: {completion_criteria}
Importante: sua saída será consumida por outro agente, como parte de uma tarefa maior.
Não tente ser completo. Seja preciso no seu escopo."""
DATA_ANALYZER_PROMPT = """Você é um cientista de dados especializado em análise estatística.
Suas responsabilidades:
1. Realizar análises exploratórias de dados
2. Calcular estatísticas descritivas
3. Identificar padrões e tendências
4. Criar arquivos de dados prontos para serem consumidos para visualizações (gráficos, plots)
5. Gerar insights e conclusões
6. Informar todos os arquivos criados prontos para consumo
Use bibliotecas como pandas, matplotlib, seaborn para suas análises.
Sempre salve gráficos como arquivos PNG para uso em relatórios."""
def create_data_analyzer():
"""Cria o agente analisador de dados"""
return Agent(
system_prompt=DATA_ANALYZER_PROMPT,
tools=[file_read, file_write, python_repl]
)
@tool
def analyze_data(task: str, context_data: str, output_specification: str, completion_criteria: str) -> str:
"""
Agente especializado para realizar análises estatísticas e extração de insights
Args:
task (str): Descrição específica da tarefa que deverá ser realizada.
context_data (str): Dados de contexto relevantes para entendimento e realização da tarefa.
output_specification (str): Especificação do formato e conteúdo esperado na saída.
completion_criteria (str): Critérios claros que definem quando a tarefa foi concluída com sucesso.
Returns:
str: Resposta do agente especialista contendo os dados com a especificação de saída informada.
"""
print("???? Executando Agente Analisador de Dados...")
prompt = A2A_PROMPT_TEMPLATE.format(
task=task,
context_data=context_data,
output_specification=output_specification,
completion_criteria=completion_criteria
)
analyzer = create_data_analyzer()
response = analyzer(prompt)
return str(response)Roteamento inadequado e Agent Cards
Além do contexto excessivo, identifiquei um segundo problema: o roteamento inadequado de requisições. Quando o usuário solicita “Preveja as vendas para o próximo trimestre” e nenhum agente possui capacidade preditiva, o orquestrador roteia a solicitação para o agente analisador. Este, tentando ser útil, baixa bibliotecas de machine learning e implementa modelos não solicitados que resultam em alucinação por falta de clareza sobre responsabilidades.
A abordagem tradicional seria incluir Agent Cards detalhados no esquema do orquestrador. Agent Cards são arquivos de metadados no formato JSON que especificam o agente, como o que eles contêm (incluindo nome, descrição e habilidades/tools), onde residem e qual o protocolo de comunicação. Isso facilita sua descoberta dinâmica por outro agente. Porém, Agent Cards completos para agentes com múltiplas ferramentas podem adicionar milhares de tokens ao contexto de cada chamada. Para organizações que realizam 100 mil orquestrações por mês, esse overhead representa custos significativos.
Uma evolução possível é a descoberta semântica em tempo de execução: quando uma tarefa chega, o sistema busca semanticamente entre agentes disponíveis e traz apenas ferramentas relevantes para o contexto. Essa busca semântica já é possível sobre tools MCP disponíveis para um agente, através do Gateway do Amazon Bedrock AgentCore. O AgentCore Gateway indexa tools, vinculadas a ele através de servidores MCPs ou APIs, e permite realizar pesquisa semântica para um prompt específico. Assim, apenas as tools mais prováveis de uso são consideradas pelo agente.
Steering como abordagem eficaz para minimizar alucinações
O Steering, na abordagem do Strands Agents apresentada aqui, utiliza um segundo modelo para avaliar e redirecionar o comportamento do agente durante a execução. Na prática, funciona como um supervisor que verifica se o agente está seguindo as regras e o escopo definidos.
O Strands Agents implementa o Steering nas formas de Tool Steering, quando há uma avaliação antes de invocar uma ferramenta, e Model Steering, quando há avaliação da saída gerada pelo modelo principal do agente. A forma utilizada nos experimentos deste post foi a de Model Steering, abordagem que reduziu alucinações de forma consistente e manteve o agente alinhado ao objetivo.
Abaixo uma ilustração de como acontece o fluxo em ambas as formas do Steering:
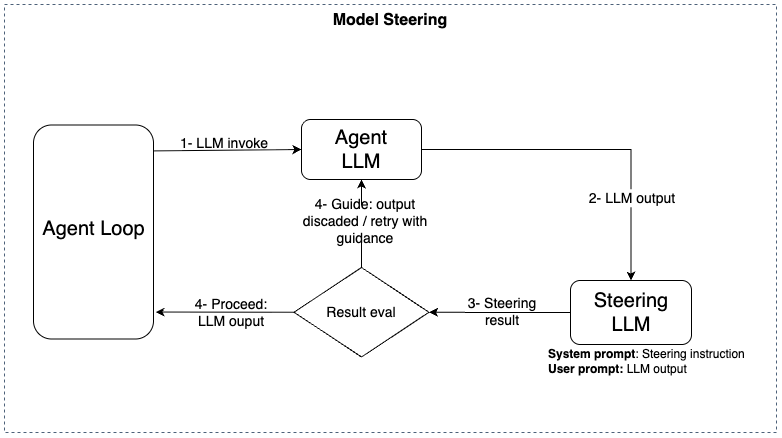
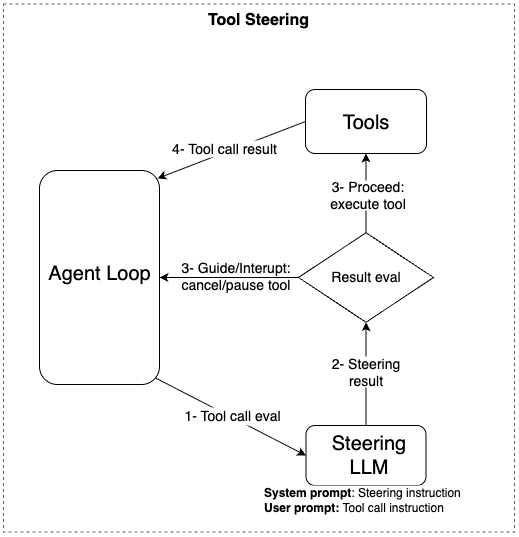
Resultado do experimento
Para ranquear e definir a qualidade do relatório gerado, estabeleci que um bom relatório HTML deveria apresentar:
- Formatação HTML sem erro.
- Extração de indicadores conforme solicitado: para a solicitação de “relatório de vendas do último trimestre”, era esperado que o agente apresentasse indicadores como “produtos mais vendidos”, “vendedores que mais venderam” e “valor total das vendas”.
- Detalhe da observação dos dados, indicando achados e tendências.
Os que não cumpriram integralmente esses requisitos foram classificados e descritos conforme o resultado observado: “Não completou a tarefa”, “HTML com formatação parcial” ou “Relatório pouco detalhado”.
Testei diferentes configurações de arquitetura, modelos e técnicas de controle no pipeline de três etapas descritas, medindo tempo de execução e qualidade do resultado.
| Configuração | Modelo do Agente | Modelo do Steering | Tempo (minuto:segundo) | Resultado |
| Multi-agentes sem contexto | Claude Haiku 4.5 | — | 16:33 | Não completou a tarefa |
| Multi-agentes com contexto selecionado | Claude Haiku 4.5 | — | 30:29 | Bom relatório HTML |
| Multi-agentes com contexto + prompt otimizado | Claude Haiku 4.5 | — | 14:24 | HTML com formatação parcial |
| Multi-agentes com contexto + Steering | Claude Haiku 4.5 | Claude Haiku 4.5 | 06:58 | Bom relatório HTML |
| Multi-agentes — Swarm | Claude Haiku 4.5 | — | 04:19 | Relatório pouco detalhado (excedeu a janela de contexto em 40% das execuções) |
| Multi-agentes — Swarm | Claude Sonnet 4.5 | — | 06:27 | Bom relatório HTML |
| Agente único | Claude Haiku 4.5 | — | 01:40 | Relatório pouco detalhado |
| Agente único + Steering | Claude Haiku 4.5 | Claude Haiku 4.5 | 02:18 | Bom relatório HTML |
| Agente único + Steering | Claude Opus 4.6 | Claude Haiku 4.5 | 04:14 | Bom relatório HTML |
| Agente único + Steering (prompt ajustado) | Claude Haiku 4.5 | Amazon Nova 2 Lite | 02:32 | Bom relatório HTML |
O que os resultados revelam
Contexto selecionado reduz alucinação viabilizando a solução: a configuração sem contexto sequer completou a tarefa — os agentes expandiram seu escopo de forma descontrolada. Com contexto selecionado e Steering, o tempo caiu de 30 para 7 minutos com resultado de qualidade.
Agentes únicos são mais rápidos para tarefas de escopo definido: o agente único completou o pipeline gerando um relatório simpes (pouco detalhado) em 1m:40s e, quando aplicado Steering, gerou um bom relatório em 2m:18s — fração do tempo da melhor configuração multi-agentes. Isso reforça que a arquitetura multi-agentes deve ser justificada pela complexidade real do problema.
Modelos maiores nem sempre significam melhores resultados: nos experimentos realizados, o modelo Claude Haiku 4.5 consistentemente entregou resultados equivalentes ou superiores a modelos maiores como Claude Opus 4.6, com menor latência. Opus levou 4m:14s para uma tarefa que Haiku completou em 2m:18s com qualidade similar.
Steering não exige modelo grande: a combinação Claude Haiku 4.5 (agente) + Amazon Nova Lite (Steering) produziu bons resultados, demonstrando que o supervisor pode usar um modelo econômico desde que o prompt seja bem calibrado.
Contexto compartilhado (Swarm) tem trade-offs reais: duas das cinco execuções falharam por exceder a janela de contexto, confirmando que mais contexto pode significar pior performance.
Demonstração do agente único
Nos cenários multi-agentes, as instruções abaixo foram distribuídas entre os sub-agentes especializados, cada um recebendo apenas a parte relevante. O código abaixo demonstra a configuração do agente único:
from strands import Agent, tool
from strands_tools import file_read, file_write
from strands.models import BedrockModel
from strands.experimental.steering import LLMSteeringHandler
import os, time, webbrowser
os.environ["BYPASS_TOOL_CONSENT"] = "True"
bedrock_model_id = "global.anthropic.claude-haiku-4-5-20251001-v1:0"
bedrock_steering_model_id = "global.amazon.nova-2-lite-v1:0"
ORCHESTRATOR_PROMPT = """
Você coordena um pipeline de análise de dados de 3 fases, para geração de relatório HTML.
Atue como profissional especialista em engenharia de dados e front-end,
utilizando código python para realizar tarefas específicas em cada etapa.
REGRA FUNDAMENTAL: Cada fase produz EXATAMENTE 1 arquivo.
SEQUÊNCIA OBRIGATÓRIA:
1. extract_data → [contexto]_dados.csv
2. analyze_data → [contexto]_analise.json
3. generate_report → [contexto]_relatorio.html
- Relatório HTML profissional, gráficos e visualizações
- Todas as sessões com dados (não vazias)
- CSS moderno, paleta AWS, menu âncora fixo, página única
Não leia dados desnecessariamente, prefira processá-los via código.
ANTES de avançar para próxima etapa, confirme que o arquivo anterior existe.
"""
report_steering = LLMSteeringHandler(
system_prompt="""
Verifique se o agente segue o pipeline de 3 fases:
1. extract_data → [contexto]_dados.csv
2. analyze_data → [contexto]_analise.json
3. generate_report → [contexto]_relatorio.html
- Mandatório incluir gráficos e visualizações
- Verifique se todos os gráficos declarados possuem scripts correspondentes
- Não permitir sessões sem dados
- Página única com menu âncora fixo, paleta AWS
""",
model=BedrockModel(model_id=bedrock_steering_model_id)
)
@tool
def python_repl(code: str) -> str:
"""Executa código Python e retorna a saída em formato JSON estruturado."""
from io import StringIO
from contextlib import redirect_stdout, redirect_stderr
import json
result = {"success": False, "output": None, "stdout": "", "stderr": "", "error": None}
stdout_buffer, stderr_buffer = StringIO(), StringIO()
try:
with redirect_stdout(stdout_buffer), redirect_stderr(stderr_buffer):
exec(code, globals())
result["success"] = True
result["stdout"] = stdout_buffer.getvalue()
result["stderr"] = stderr_buffer.getvalue()
except Exception as e:
result["error"] = {"type": type(e).__name__, "message": str(e)}
result["stderr"] = stderr_buffer.getvalue()
return json.dumps(result, indent=2, default=str)
@tool
def open_html_in_browser(file_path: str) -> str:
"""Abre um arquivo HTML no browser padrão."""
full_path = os.path.abspath(file_path)
webbrowser.open(f'file://{full_path}')
return f"Relatório aberto no browser: {full_path}"
def create_orchestrator():
return Agent(
model=BedrockModel(model_id=bedrock_model_id),
system_prompt=ORCHESTRATOR_PROMPT,
tools=[file_read, file_write, python_repl, open_html_in_browser],
hooks=[report_steering]
)
if __name__ == "__main__":
prompt = "Gere um relatório com os produtos mais vendidos de Q4,
no arquivo vendas_q4.csv"
orchestrator = create_orchestrator()
start_time = time.time()
orchestrator(prompt)
elapsed = time.strftime("%H:%M:%S", time.gmtime(time.time() - start_time))
print(f"\nTempo gasto: {elapsed}")Práticas para implementação imediata
Com base nos experimentos, três práticas podem ser implementadas hoje:
- Seleção contextual consciente: o orquestrador deve manter um “perfil contextual” para cada agente, passando apenas informações específicas para a tarefa. Isso vale mesmo para agentes locais.
- Inclusão seletiva de Agent Cards: inclua apenas informações essenciais (nome e descrição das Skills) no esquema do orquestrador, evitando overhead de tokens desnecessário.
- Steering como mecanismo de supervisão: como demonstrado, mesmo modelos econômicos como Amazon Nova Lite podem exercer supervisão eficaz, tornando a prática viável em cenários com restrição de custo.
Detectando alucinações: métricas essenciais
Para medir o impacto dessas práticas, monitore:
- Artefatos criados: se o agente extrator foi instruído a criar um CSV mas retorna cinco arquivos com gráficos e scripts auxiliares, o escopo foi expandido além do esperado.
- Conformidade de estrutura: cada agente deve retornar dados no formato especificado. Validação de schema rigorosa detecta desvios automaticamente.
- Consumo de recursos: uma tarefa simples de leitura de arquivo com consumo elevado de CPU pode indicar operações adicionais não solicitadas.
- Duração de execução: variações significativas de tempo entre execuções com configurações similares indicam comportamento imprevisível.
Implementação na AWS
Para times de desenvolvimento que inovam com o Amazon Bedrock AgentCore, ao comunicar com agentes via invocação direta ou protocolo A2A, estruture o prompt indicando explicitamente que o agente está em modo colaborativo, qual é seu papel específico e onde suas responsabilidades começam e terminam.
Ao construir agentes com Strands Agents, configure explicitamente quais ferramentas estão disponíveis para cada agente. Um agente extrator que não precisa executar código Python complexo não deve ter acesso a essa ferramenta, reduzindo a chance de distração.
Para monitorar e mitigar alucinações de modelo, utilize:
- Prevenção em tempo real com Guardrails — Amazon Bedrock Guardrails pode ser posicionado entre agentes para validar cada mensagem trocada. Seus Automated Reasoning checks verificam saídas contra regras de negócio de forma determinística, detectando expansão de escopo e fabricação de dados antes que se propaguem pela cadeia.
- Avaliação contínua com AgentCore Evaluations — Amazon Bedrock AgentCore Evaluations monitora continuamente interações em produção com 13 avaliadores built-in (correctness, helpfulness, tool selection accuracy, entre outros) e suporta avaliadores customizados. Com isso, as quatro métricas anteriores podem se tornar dimensões de avaliação automatizadas com scores quantificáveis e histórico de tendências.
Conclusão
Os experimentos demonstram que alucinações em orquestração multi-agentes são primariamente um problema arquitetural — não do modelo de linguagem em si. Surgem quando agentes não possuem consciência clara do contexto, recebem mais informação do que conseguem processar, ou são solicitados a realizar tarefas fora de seu escopo.
Três princípios devem guiar o design: clareza absoluta de responsabilidades (cada agente com uma única responsabilidade bem definida), minimalismo contextual (apenas informação necessária — mais contexto não significa melhor performance) e roteamento correto (informação suficiente sobre capacidades dos agentes para atribuição adequada de tarefas).
Os resultados são concretos: seleção contextual reduziu o tempo de execução em aproximadamente 75%, economizando em recursos de computação e volume de tokens. Modelos menores como Claude Haiku 4.5 apresentaram resultados equivalentes a modelos maiores com fração do custo. E Steering, mesmo com modelos econômicos, melhorou consistentemente a aderência ao escopo. Ao implementar essas práticas, é possível obter reduções significativas em alucinações, melhor latência, custos reduzidos e maior confiabilidade em sistemas de orquestração multi-agentes.
Autor
 |
Neuton Assis é Arquiteto de Soluções na AWS para o segmento de Enterprise e membro da comunidade de AI/ML, com foco em Agentic AI. Antes disso, trabalhou por mais de 10 anos na arquitetura e desenvolvimento de softwares voltados para automação, auditoria de sistemas e gestão de identidade e acesso. Atualmente ajuda clientes da AWS, brasileiros e multinacionais, a implementarem arquiteturas de agentes seguras, escaláveis e confiáveis. |