O blog da AWS
Otimizando o processamento de arrays JSON aninhados usando AWS Step Functions Distributed Map
Por Biswanath Mukherjee, Sr. Solutions Architect e Rahul Sringeri, Technical Account Manager.
Quando você trabalha com grandes conjuntos de dados, provavelmente já encontrou o desafio de processar estruturas JSON complexas em seus fluxos de trabalho automatizados. Você precisa pré-processar arrays dentro de objetos JSON aninhados antes de poder executar o processamento paralelo neles. A extração de dados costumava exigir código personalizado e etapas de processamento extras, atrasando você na construção da lógica principal da sua aplicação.
Com o AWS Step Functions Distributed Map, você pode processar grandes conjuntos de dados com iterações simultâneas de etapas de fluxo de trabalho em entradas de dados. Usando o recurso aprimorado ItemsPointer do Distributed Maps, você pode extrair dados do array diretamente de objetos JSON armazenados no Amazon S3. Alternativamente, para objetos JSON como entrada de estado, você pode usar Items (JSONata) ou ItemsPath (JSONPath). Com esse aprimoramento, você pode apontar diretamente para arrays aninhados dentro de estruturas JSON, eliminando a necessidade de pré-processamento personalizado de seus dados. Com ItemsPointer, Items e ItemsPath, você pode selecionar os dados de array aninhados e simplificar seus fluxos de trabalho.
Nesta postagem, exploramos como otimizar o processamento de dados de array incorporados em estruturas JSON complexas usando AWS Step Functions Distributed Map. Você aprenderá como usar ItemsPointer para reduzir a complexidade de suas definições de máquina de estado, criar designs de fluxo de trabalho mais flexíveis e simplificar seus pipelines de processamento de dados—tudo sem escrever código de transformação adicional ou funções AWS Lambda.
Este post faz parte de uma série de posts sobre AWS Step Functions Distributed Map:
|
Caso de uso: enriquecimento de dados de produtos de e-commerce
Neste exemplo de caso de uso de e-commerce, você construirá uma aplicação de exemplo que demonstra o processamento de dados de inventário de produtos para uma aplicação de e-commerce usando AWS Step Functions Distributed Map. A aplicação recebe um arquivo JSON de uma aplicação upstream contendo um array de informações de produtos. O fluxo de trabalho do Step Functions lê o arquivo JSON contendo dados de produtos de um bucket S3 e itera sobre o array para enriquecer cada dado de produto no array.
O diagrama a seguir apresenta a máquina de estado do AWS Step Functions.
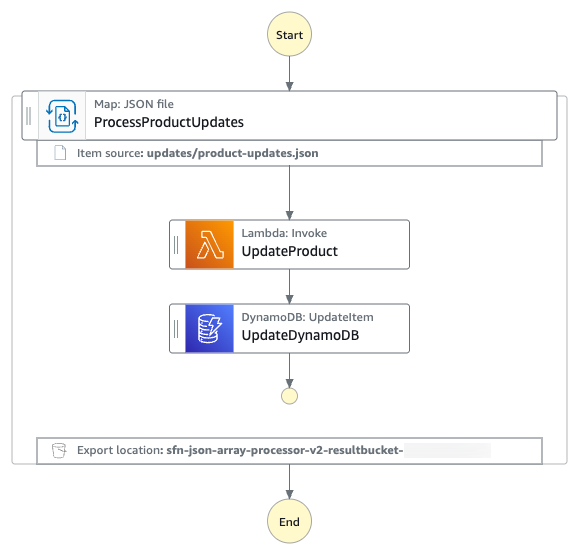
Fluxo de trabalho de processamento de array JSON
O array JSON é processado usando o seguinte fluxo de trabalho:
- A máquina de estado lê o arquivo product-updates.json de um bucket S3 de entrada. O arquivo contém um array JSON de produtos.
- O estado Distributed Map na máquina de estado seleciona o nó do array JSON usando
ItemsPointere itera sobre o array JSON. - Para cada um dos itens dentro do array, a máquina de estado invoca uma função Lambda para enriquecimento de dados. A função Lambda adiciona informações de estoque e preço do produto aos dados do produto.
- A máquina de estado salva os dados atualizados do produto em uma tabela do Amazon DynamoDB.
- Finalmente, a máquina de estado carrega os metadados de execução em um bucket S3 de saída. Veja os limites relacionados a execuções de máquina de estado e execuções de tarefas.
MaxConcurrency pode ser configurado para especificar o número de execuções de fluxo de trabalho filho em um Distributed Map que podem ser executadas em paralelo. Se não especificado, o Step Functions não limita a simultaneidade e executa 10.000 execuções de fluxo de trabalho filho em paralelo.
Você pode ler um arquivo JSON de um bucket S3 usando ItemReader e seus subcampos. Se o arquivo JSON, do bucket S3, contiver uma estrutura de objeto aninhada, você pode selecionar o nó específico com seu conjunto de dados com um ItemsPointer. Por exemplo, o seguinte arquivo JSON de entrada:
A seguinte configuração de fluxo de trabalho baseada em JSONata extrai uma lista aninhada de produtos de productUpdates/items:
Para fluxo de trabalho baseado em JSONPath, observe que Arguments é substituído por Parameters:
O campo ItemReader não é necessário quando seu conjunto de dados é dados JSON de uma etapa anterior. ItemsPointer é aplicável apenas quando os objetos JSON de entrada são lidos de um bucket S3. Se você estiver usando JSON como entrada de estado para um Distributed Map, então você pode usar o campo ItemsPath (para JSONPath) ou Items (para JSONata) para especificar um local na entrada que aponta para array ou objeto JSON usado para iterações.
Pré-requisito
Para usar o Step Functions Distributed Map, verifique se você tem:
- Acesso a uma conta AWS através do AWS Management Console e da Interface de Linha de Comando da AWS (AWS CLI). O usuário AWS Identity and Access Management (IAM) que você usa deve ter permissões para fazer as chamadas de serviço AWS necessárias e gerenciar os recursos AWS mencionados neste post. Ao fornecer permissões ao usuário IAM, siga o princípio do menor privilégio.
- AWS CLI instalada e configurada. Se você estiver usando credenciais de longo prazo como chaves de acesso, siga gerenciar chaves de acesso para usuários IAM e proteger chaves de acesso para melhores práticas.
- Git Instalado
- AWS Serverless Application Model (AWS SAM) instalado
- Python 3.13+ instalado
Configurar e executar o fluxo de trabalho
Execute as seguintes etapas para implantar a máquina de estado do Step Functions.
- Clone o repositório GitHub em uma nova pasta e navegue até a pasta do projeto.
- Execute os seguintes comandos para implantar a aplicação.
Insira os seguintes detalhes:
- Stack name: Nome da pilha para CloudFormation (por exemplo, stepfunctions-json-array-processor)
- AWS Region: Uma região AWS suportada (por exemplo, us-east-1)
- Aceite todos os outros valores padrão.
As saídas do sam deploy serão usadas nas etapas subsequentes.
- Execute o seguinte comando para gerar o arquivo
product-updates.jsoncontendo um array JSON aninhado de produtos de exemplo e carregar o arquivoproduct-updates.jsonno bucket S3 de entrada. SubstituaInputBucketNamepelo valor da saída do sam deploy. - Execute o seguinte comando para iniciar a execução do fluxo de trabalho do Step Functions. Substitua o
StateMachineArnpelo valor da saída dosam deploy.A máquina de estado lê o arquivo de entrada
product-updates.jsone invoca uma função Lambda para atualizar o banco de dados para cada produto no array após adicionar informações de preço e estoque. Os metadados de execução também são carregados no bucket de resultados.
Monitorar e verificar resultados
Execute as seguintes etapas para monitorar e verificar os resultados do teste.
- Execute o seguinte comando para obter os detalhes da execução. Substitua executionArn pelo ARN da sua máquina de estado.
Aguarde até que o status mostre
SUCCEEDED. - Execute os seguintes comandos para validar a saída processada da tabela DynamoDB
ProductCatalogTableName. Substitua o valorProductCatalogTableNamepelo valor da saída do sam deploy. - Verifique se a tabela DynamoDB contém os dados de produto enriquecidos, incluindo atributos de preço e estoque. Exemplo de saída:
Limpeza
Para evitar custos, remova todos os recursos que você criou ao seguir este postagem.
Execute o seguinte comando após substituir a variável <placeholder> para excluir os recursos que você implantou para a solução deste post:
Conclusão
Nesta postagem, você aprendeu como usar o Step Functions Distributed Map para extrair dados de array nativamente de objetos JSON armazenados em um bucket S3. Ao remover código personalizado de extração de dados, você pode simplificar o processamento de suas cargas de trabalho paralelas em larga escala. Com ItemsPointer você pode extrair dados de array dentro de arquivos JSON armazenados em um bucket S3, e com Items(JSONata) ou ItemsPath (JSONPath), você pode extrair arrays de entrada de estado JSON complexa, adicionando flexibilidade aos seus designs de fluxo de trabalho.
Novas fontes de entrada para Distributed Map estão disponíveis em todas as regiões AWS comerciais onde o AWS Step Functions está disponível. Para uma lista completa de regiões AWS onde o Step Functions está disponível, consulte a Tabela de Regiões AWS. Para começar, você pode usar o modo Distributed Map hoje no console do AWS Step Functions. Para saber mais, visite o guia do desenvolvedor do Step Functions.
Para mais recursos de aprendizado serverless, visite Serverless Land.
Este conteúdo foi traduzido do post original do blog, que pode ser encontrado aqui.
Autores
 |
Biswanath Mukherjee, Sr. Solutions Architect |
 |
Rahul Sringeri, Technical Account Manager |
Tradutores
 |
Rodrigo Peres é Arquiteto de Soluções na AWS, com mais de 20 anos de experiência trabalhando com arquitetura de soluções, desenvolvimento de sistemas e modernização de sistemas legados. |
 |
Daniel Abib é arquiteto de soluções sênior na AWS, com mais de 25 anos trabalhando com gerenciamento de projetos, arquiteturas de soluções escaláveis, desenvolvimento de sistemas e CI/CD, microsserviços, arquitetura Serverless & Containers e segurança. Ele trabalha apoiando clientes corporativos, ajudando-os em sua jornada para a nuvem. https://www.linkedin.com/in/danielabib/ |