AWS Big Data Blog
Under the hood: Scaling your Kinesis data streams
Real-time delivery of data and insights enables businesses to pivot quickly in response to changes in demand, user engagement, and infrastructure events, among many others. Amazon Kinesis offers a managed service that lets you focus on building your applications, rather than managing infrastructure. Scalability is provided out-of-the-box, allowing you to ingest and process gigabytes of streaming data per second. Data replication to three Availability Zones offers high availability and durability. Pricing is based on usage and requires no upfront costs, making Kinesis a cost-effective solution.
Amazon Kinesis Data Streams use a provisioned capacity model. Each data stream is composed of one or more shards that act as units of capacity. Shards make it easy for you to design and scale a streaming pipeline by providing a predefined write and read capacity. As workloads grow, an application may read or write to a shard at a rate that exceeds its capacity, creating a hot shard and requiring you to add capacity quickly. Shards also enable you to parallelize the processing of large datasets and compute results quickly.
This post discusses how to scale your data streams and avoid hot shards. The post first shows you how to estimate the number of shards you need in your data stream as you design your streaming pipeline. Then it looks at reasons that lead to hot shards and how to avoid those using Kinesis Data Streams scaling mechanisms and reviews important metrics for monitoring.
Estimating your stream capacity
The following diagram shows a streaming data pipeline connected to a multiplayer video game. Kinesis Data Streams ingest player scores and other stats. You can filter and enrich the data, and write it to DynamoDB tables that populate the game’s various leaderboards.

As you embark on designing your streaming pipeline, it’s important to set up the data stream with enough capacity to handle producers ingesting the data records producers create, and handle users consuming the same records. You can ingest up to 1 MB per second per shard or 1,000 data records per second per shard for writes. Read capacity is up to 2 MB per second per shard or five read transactions per second. All applications reading from the stream share the read capacity. You can use the enhanced fan-out feature to scale the number of consuming applications and make sure that each has a dedicated 2 MB per second connection.
This post uses the preceding application as an example. It’s estimated that producers create data records at a rate of 20,000 KB per second, and your consumer nodes need to process this same amount of data at the other end of the stream. In addition to handling these rates, it is a good idea to add extra capacity to give the stream headroom for growth.
This headroom also helps your application recover faster in scenarios that could cause a delay or a pause in ingesting or processing data. These scenarios may include:
- Deploying a new version of a consumer application
- Transient network issues
As these nodes work to catch up after recovery, they produce or consume records at a higher than standard rate, requiring higher capacity. For this example, you can add 25% percent, or five shards, for headroom. Shards are cost-efficient, but it is up to you how many you want to add.
Scaling scenario
At the time of the game’s release, this capacity is deemed sufficient for the application. Ingestion and processing of the data are both running smoothly, and the game’s leaderboards are populated with current data. It’s now a few weeks after release; the game is steadily gaining popularity and concurrent player numbers are increasing. In a scenario such as this, it’s important to have sufficient monitoring to detect the increased load so you can increase throughput by scaling the stream.
The following diagram provides a simplified view of using CloudWatch metrics to monitor your data streams and triggering scaling operations
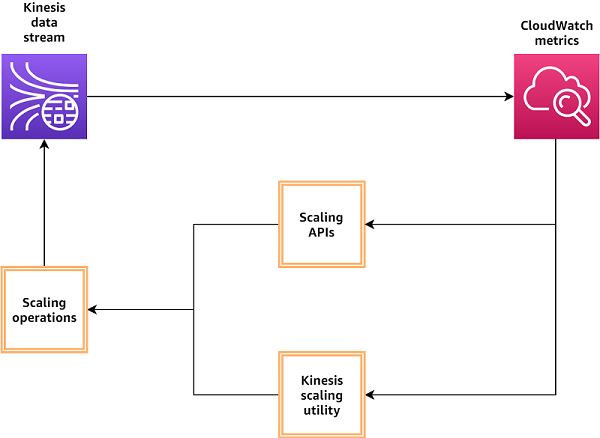
In this example, these scaling issues could manifest in delayed leaderboard update reports. Because shards are the capacity units in a data stream, each shard’s capacity is independent of other shards. If the producers write to a single shard at a rate higher than 1 MB per second or 1,000 records per second, that shard becomes a hot shard and requests exceeding that capacity get throttled, leading to a delay in leaderboard updates. This condition can happen while other shards in the stream are underutilized, so if you are monitoring metrics at the stream level, you may not see any cause for concern, because the stream overall is ingesting data at a rate below its total capacity of 25 MB per second. Amazon Kinesis enables you to seamlessly scale your stream without interrupting your streaming pipeline.
Core concepts that enable scaling
You can write records to a data stream using Put APIs. To write a single record, use PutRecord; to write multiple records, use PutRecords. When executing either one, the request to the Kinesis API has to include the following three components:
- The stream name.
- The data record to write to the stream. For this post, this is the scoring result of a particular round in the game.
- A partition key (for example, the fame session).
The following diagram shows multiple producers writing to a Kinesis data stream. The partition key value is used in combination with a hash function to determine the shard a given record will be written to.
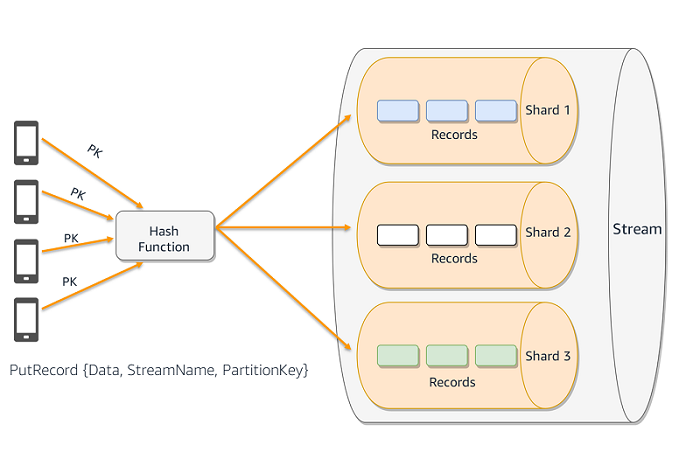
The partition key determines to which shard the record is written. The partition key is a Unicode string with a maximum length of 256 bytes. Kinesis runs the partition key value that you provide in the request through an MD5 hash function. The resulting value maps your record to a specific shard within the stream, and Kinesis writes the record to that shard. Partition keys dictate how to distribute data across the stream and use shards.
Certain use cases require you to partition data based on specific criteria for efficient processing by the consuming applications. As an example, if you use player ID pk1234 as the hash key, all scores related to that player route to shard1. The consuming application can use the fact that data stored in shard1 has an affinity with the player ID and can efficiently calculate the leaderboard. An increase in traffic related to players mapped to shard1 can lead to a hot shard. Kinesis Data Streams allows you to handle such scenarios by splitting or merging shards without disrupting your streaming pipeline.
If your use cases do not require data stored in a shard to have high affinity, you can achieve high overall throughput by using a random partition key to distribute data. Random partition keys help distribute the incoming data records evenly across all the shards in the stream and reduce the likelihood of one or more shards getting hit with a disproportionate number of records. You can use a universally unique identifier (UUID) as a partition key to achieve this uniform distribution of records across shards. This strategy can increase the latency of record processing if the consumer application has to aggregate data from multiple shards.
Kinesis Data Streams scaling mechanisms
The stream remains fully functional during these actions. Producers and consumers can continue to read and write to the stream during the scaling process.
Upon receiving the scaling request, Kinesis sets the stream status to Updating. You can use the DescribeStreams API to check the stream status. When the operation is complete, the stream status shows as Active.
The SplitShard action splits one active shard into two shards, increasing the read and write capacity of the stream. This can be helpful if there is an expected increase in the number of records ingested into the stream or so more Kinesis Data Streams applications can simultaneously read data from the stream for real-time processing.
SplitShard facilitates that process. The hash key space of the parent shard also splits. The two new shards accept new data records and the parent shard stops accepting new records. Existing records in the parent shard are retained for the duration of the stream retention period (the default is 24 hours, configurable up to 7 days). You must specify the new-starting-hash-key value when issuing this command. This value determines the point of the split within the parent shard’s hash key space. In most cases, you want to do an even split. However, you might need to do an uneven split if you have unbalanced shards that you want to rebalance, for example. The following diagram shows the SplitShard process in action.
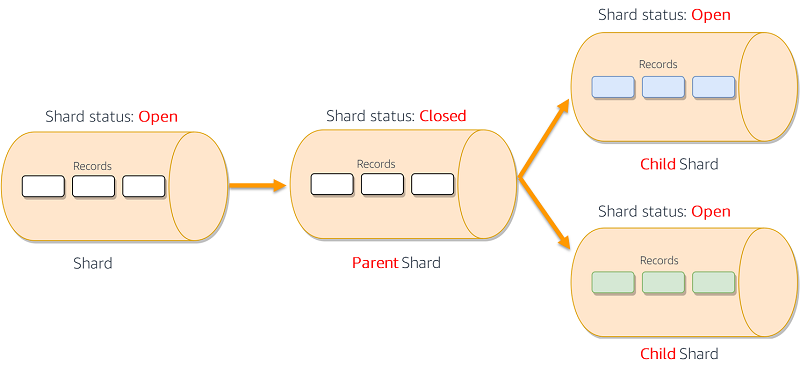
Many streaming workloads have variable data flow rates that fluctuate over time, sometimes following daily, weekly, or seasonal patterns. As you monitor your data flow rates, you may see underutilized shards that, if merged, still have a data flow rate below the shard limits, yet reduce the cost of the stream.
The MergeShards action merges two adjacent shards, producing one shard. Two shards are considered adjacent if the hash key spaces for the two form a contiguous set with no gaps. When the two shards merge, their hash key spaces also merge. The new shard starts accepting new data records. The two parent shards stop accepting new records and retain existing records up to the stream’s configured retention period. The following diagram shows the MergeShards process in action.

The UpdateShardCount action is useful when you need to scale your stream, up or down, to a specific number of shards, and you provide that number as a parameter in the API call. Scaling in increments of 25% of the current capacity (25%, 50%, 75%, 100%) helps the operation complete faster, but is not required. The command executes a series of SplitShard and MergeShards actions as needed to reach the explicit number of shards you specified. This command splits shard hash key space evenly, creating shards of equal size. There is no option to choose a different value.
Additionally, the Kinesis Scaling Utility available on GitHub provides autoscaling for Kinesis Data Streams by monitoring a stream’s Amazon CloudWatch metrics and scaling it up or down accordingly. It can scale a stream by an explicit shard count or as a percentage of the total fleet. There is no requirement for you to manage the allocation of the key space to shards when using this API; it happens automatically.
Balancing shards
After completing a scaling operation, check the distribution of the hash key space in your stream. In most use cases, the hash key space should be evenly distributed across the shards in the stream. Errors in calculating or inputting a shard’s hash key space starting value can lead to creating new shards with an unusually large or small hash key space. Unusually large shards receive a high number of read and write requests, leading to throttling and underutilizing the unusually small shards.
The output of the ListShards API lists the starting and ending hash key value for each shard in the stream. You can use these values to identify unbalanced shards, and perform the necessary splits or merges to balance them. The Kinesis Scaling Utility can also generate a report of shard key space sizes that can help you achieve the same result. See the following code:
Monitoring your streams to preempt hot shards
As the hot shard scenario has demonstrated, monitoring your data streams at only the stream level does not prepare you for issues at the shard level. Kinesis offers a multitude of stream level and shard level metrics. At the shard level, IncomingBytes and IncomingRecords show you the ingestion rate into the shard. WriteProvisionedThroughputExceeded and ReadProvisionedThroughputExceeded indicate throttled Put and Get requests, respectively. At the stream level, keep an eye on PutRecord.Success, in which the average value reflects the percentage of PutRecord success over time. Paired with proper thresholds for alerting, they should help you take scaling actions proactively in response to flow changes in and out of your streams, and reduce the possibility of developing hot shards.
The following image shows a snapshot of a CloudWatch dashboard with several metrics of a Kinesis data stream.

Conclusion
This post discussed how to simplify the scaling and monitoring of your Kinesis Streams. It’s important to spend some time considering the expected data flow rate for your stream to find the appropriate capacity. Choosing a good partition key strategy helps you take full advantage of the capacity you provision and avoid hot shards. Monitoring your stream metrics and setting alarm thresholds helps you gain the visibility you need to make better scaling decisions.
For more information, see What Is Amazon Kinesis Data Streams? For more information about Kinesis API actions, see Actions.
About the Author
 Ahmed Gaafar is a senior technical account manager at AWS.
Ahmed Gaafar is a senior technical account manager at AWS.