- Библиотека разработчиков Amazon
- Работа распределенных систем без необходимости откатов
Работа распределенных систем без необходимости откатов
ARCHITECTURE | LEVEL 300
Введение
Из-за критических сбоев сервисы не выдают полезных результатов. Например, при ошибке запроса к базе данных на сайте интернет-магазина страница продукта не отображается должным образом. Для надежной работы сервисы Amazon должны обрабатывать большинство критических сбоев. Существует четырех широкие категории их обработки:
-
Повторите попытку: выполните неудачное действие снова немедленно или с некоторой задержкой.
-
Упреждающий повтор: выполняйте задание несколько раз параллельно и используйте первое задание для завершения.
-
Аварийное переключение: повторите операцию на другой копии конечной точки или, предпочтительно, выполните несколько параллельных копий операции, чтобы повысить вероятность успешного выполнения хотя бы одной из них.
-
Резервный вариант: используйте другой механизм для достижения того же результата.
В этой статье рассматриваются стратегии откатов и объясняется, почему компания Amazon практически никогда их не использует. Это может показаться вам странным. Как бы там ни было, инженеры часто используют практические примеры в начале разработки проектов. А в реальном мире стратегии откатов необходимо планировать заранее и использовать при необходимости. Предположим, что в аэропорту погасли информационные табло. В таком случае нужен запасной план действий (например, сотрудники должны записывать информацию вручную на досках), чтобы пассажиры смогли находить выходы на посадку. Однако такой запасной план имеет кучу недостатков: читать и обновлять данные на досках крайне неудобно; к тому же, усиливается риск внесения неправильной информации из-за человеческого фактора. Стратегия отката с использованием досок необходима, но сопряжена с рядом проблем.
В области распределенных систем стратегии откатов представляют собой одну из наиболее сложных задач, особенно что касается сервисов, зависящих от фактора времени. Эти трудности усугубляются тем, что достижение результатов с помощью плохих стратегий откатов может занять много времени (даже несколько лет), а отличить хорошую стратегию от плохой достаточно сложно. В этой статье мы в первую очередь рассмотрим следующий вопрос: почему стратегии откатов могут вызвать больше проблем, чем устранить. Мы также приведем примеры случаев, когда у компании Amazon возникали проблемы из-за стратегий откатов. Наконец, мы рассмотрим альтернативные варианты, которые компания Amazon использует вместо откатов.
Анализ стратегий откатов для сервисов не является интуитивно понятным процессом, а их последствия сложно предвидеть в распределенных системах, поэтому сначала нужно рассмотреть стратегии откатов, применяемые к одному компьютеру.
Откаты при использовании одного компьютера
Рассмотрим указанный ниже фрагмент кода на языке C, который иллюстрирует шаблон обработки сбоев, связанных с выделением памяти, который широко используется во многих приложениях. В этом коде для выделения памяти используется функция malloc(), после чего буфер изображений копируется в этот блок памяти с определенным преобразованием:
pixel_ranges = malloc(image_size); // allocates memory
if (pixel_ranges == NULL) {
// On error, malloc returns NULL
exit(1);
}
for (i = 0; i < image_size; i++) {
pixel_ranges[i] = xform(original_image[i]);
}Резервный вариант на одну машину (продолжение)
Этот код не восстанавливается при ошибке функции выделения памяти malloc. На практике вызовы функции malloc редко завершаются ошибками, поэтому разработчики часто игнорируют эти сбои в коде. Почему эта стратегия пользуется такой популярностью? Причина состоит в следующем: если функция malloc завершается ошибкой на одном компьютере, возможно, на нем закончилась память. Поэтому имеются более серьезные проблемы, чем ошибка одного вызова функции malloc, и работа компьютера вскоре может завершиться сбоем. В большинстве случаев это разумное утверждение для одного компьютера. Многие приложения не являются критически важными, поэтому решение этой сложной проблемы не стоит затрачиваемых усилий. Но что если вы захотите устранить эту ошибку? Сделать что-то полезное в этом случае достаточно сложно. Скажем, мы внедрим второй метод под именем malloc2, который по-другому выделяет память, и будем вызывать его, если используемая по умолчанию функция malloc завершается ошибкой:
pixel_ranges = malloc(image_size);
if (pixel_ranges == NULL) {
pixel_ranges = malloc2(image_size);
}Резервный вариант на одну машину (продолжение)
На первый взгляд этот код кажется рабочим, но с ним связаны определенные проблемы (одни менее, а другие более очевидные). Начнем с того, что запасную логику сложно протестировать. Мы можем перехватить вызов функции malloc и смоделировать сбой, но не факт, что это позволит в точности имитировать события, которые произошли бы в рабочей среде. Если функция malloc завершается ошибкой в рабочей среде, скорее всего, на компьютере закончилась или заканчивается память. Как смоделировать более широкие проблемы с памятью, похожие на эту? Даже если вам удастся создать среду с низким уровнем памяти для этой проверки (скажем, в контейнере Docker), как внедрить условие нехватки памяти таким образом, чтобы оно происходило одновременно с выполнением кода отработки отката malloc2?
Другая проблема заключается в том, что сам запасной вариант может выйти из строя. Предыдущий код отработки отката не обрабатывает ошибки функции malloc2, поэтому программа не настолько полезна, как может показаться. Стратегия откатов может уменьшить вероятность возникновения полного сбоя, но не устраняет ее. Компания Amazon обнаружила, что привлекать технических специалистов для повышения надежности первичного кода (не предназначенного для отката) более целесообразно, чем инвестировать средства в нечасто используемую стратегию откатов.
Кроме того, если доступность является нашим главным приоритетом, запасная стратегия, возможно, не стоит рисковать. Зачем вообще уделять внимание функции malloc, если функция malloc2 имеет лучшие шансы на успешное выполнение? Логично предположить, что вам нужно пойти на компромисс, так как функция malloc2 обеспечивает более высокую доступность. Возможно, она выделяет память с более высокой задержкой, но гарантирует больший объем SSD-хранилища. Однако возникает следующий вопрос: почему функция malloc2 приводит к этому компромиссу? Рассмотрим потенциальную последовательность событий, которые могут возникнуть при использовании этой стратегии откатов. Сначала клиент использует приложение. Неожиданно (вследствие ошибки функции malloc) срабатывает функция malloc2, и приложение начинает медленнее работать. Это плохо, но является ли такое замедление работы нормальным? И это не единственная проблема. Предположим следующее: скорее всего, на компьютере закончилась или вот-вот закончится память. Теперь у клиента вместо одной возникло две проблемы: замедление работы приложения и компьютера. Побочные эффекты переключения на функцию malloc2 могут еще больше усугубить общую проблему. Например, другие подсистемы также могут обращаться к тому же SSD-хранилищу.
Резервная логика также может создавать непредсказуемую нагрузку на систему. Даже простая и широко используемая логика, такая как запись сообщения об ошибке в журнал с трассировкой стека, на первый взгляд кажется безопасной, но если эта ошибка будет возникать при высокой скорости из-за неожиданных изменений, работа приложения, непосредственно зависящего от мощности ЦПУ, может быть резко ограничена скоростью ввода-вывода данных. Кроме того, если для обработки записи на этой скорости или для сохранения данных в требуемом объеме не выделен диск, это может привести к замедлению работы или сбою приложения.
Резервная стратегия может не только усугубить проблему, но и проявиться как скрытая ошибка. Вполне можно разработать стратегии откатов, которые редко запускаются в рабочей среде. Может пройти несколько лет, прежде чем на одном из компьютеров клиента действительно закончится память, чтобы запустилась определенная строка кода с откатом на описанную выше функцию malloc2. Если в логике отката возникнет ошибка или побочный эффект, которые усугубляют общую проблему, специалисты, которые написали код, могут не помнить, как он работал с самого начала, поэтому им будет труднее исправить код. Это может оказаться приемлемым компромиссом, если используется один компьютер, но в распределенных системах последствия могут быть намного более значимыми, о чем мы поговорим позже.
Все это сложные проблемы, но, исходя из нашего опыта, мы можем утверждать, что их зачастую можно проигнорировать без каких-либо последствий в средах с одним компьютером. Самое распространенное решение уже упоминалось ранее: просто позвольте ошибкам, возникающим при выделении памяти, привести к сбою приложения. Код, который выделяет память, «разделяет судьбу» с другими компонентами компьютера (принцип fate-sharing), поэтому в этом случае его работа с высокой вероятностью может завершиться сбоем. Даже если «разделения судьбы» не произошло, приложение окажется в непредвиденном состоянии, поэтому быстрый сбой – это хорошая стратегия. В этом случае целесообразно прийти к бизнес-компромиссу.
Одно из решений в критически важных средах с одним компьютером, которые должны работать в случае ошибок выделения памяти, заключается в следующем: предварительно выделите всю динамическую память при запуске и никогда больше не полагайтесь на функцию malloc даже при возникновении ошибок. Компания Amazon несколько раз применяла эту стратегию. Например, она использовалась для мониторинга демонов, запускаемых на производственных серверах, и демонов Amazon Elastic Compute Cloud (Amazon EC2), которые отслеживают пиковые нагрузки на ЦПУ клиентов.
Откаты в распределенных системах
Компания Amazon не допускает компромиссов, которые характерны для сред с одним компьютером, в отношении распределенных систем, особенно предназначенных для реагирования в реальном времени. Одна из причин – несоответствие принципу «разделения судьбы» с клиентом (fate-sharing). Мы можем предположить, что приложения выполняются на компьютере, за которым сидит клиент. Если приложению не хватает памяти, вероятно, клиент будет ожидать завершения его работы. Сервисы не выполняются на компьютере, который непосредственно используется клиентом, поэтому ожидания в этом случае другие. Кроме того, клиенты обычно используют сервисы ввиду их большей доступности по сравнению с запуском приложения на отдельном сервере, поэтому нам нужно сделать их более доступными. Теоретически мы должны были бы использовать откат, чтобы повысить надежность сервиса. Но, к сожалению, для отката в распределенных системах характерны те же и даже более серьезные проблемы, что касается сбоев в работе критических важных систем.
Распределенные резервные стратегии тестировать сложнее. Откат сервиса – более сложный процесс, чем откат в среде с одним компьютером, так как сбои затрагивают несколько компьютеров и подчиненных сервисов. При проверке сложно реплицировать именно состояния сбоя, такие как сценарии перегрузки, даже если можно провести согласованную проверку для нескольких компьютеров. При комбинаторном анализе также возрастает количество случаев, которые необходимо проверить, поэтому вам нужно выполнить больше проверок, которые к тому же намного сложнее настроить.
Сами по себе распределенные резервные стратегии могут потерпеть неудачу. Хотя может показаться, что запасные стратегии гарантируют успех, по нашему опыту, они обычно только повышают шансы на успех.
Распределенные резервные стратегии часто усугубляют перебои в работе. Как показывает наш опыт, стратегии откатов увеличивают диапазон последствий сбоев, а также длительность восстановления.
Стратегии откатов часто нецелесообразны ввиду связанных с ними рисков. Как и в случае с функцией malloc2, стратегия откатов часто приводит к необходимости идти на компромисс. В противном случае мы бы постоянно использовали ее. Зачем использовать откат, который только усугубляет текущую проблему?
Распределенные резервные стратегии часто содержат скрытые ошибки, которые появляются только при маловероятных совпадениях, возможно, через несколько месяцев или лет после их появления.
Прекрасная иллюстрация всех этих проблем – крупный сбой, который был вызван механизмом отката, использовавшемся на веб-сайте компании Amazon для розничной торговли. Этот сбой произошел приблизительно в 2001 году. Его вызвал новый компонент, который предоставлял актуальные данные по срокам доставки всех продуктов, отображавшихся на веб-сайте.
Вот как выглядел этот новый компонент:

Поэтому мы добавили слой кэширования, работающий как отдельный процесс на каждом веб-сервере.
В то время архитектура веб-сайта включала только два уровня. Так как данные хранились в базе данных цепочки поставок, веб-серверам необходимо было отправлять запросы непосредственно в эту базу данных. Однако она не справлялась с объемом запросов, отправлявшихся с веб-сайта. Трафик на нем был высоким. На некоторых страницах отображалось 25 или более продуктов со сроками доставки каждого из них. Поэтому мы добавили слой кэширования, работающий как отдельный процесс на каждом веб-сервере (что-то вроде Memcached):
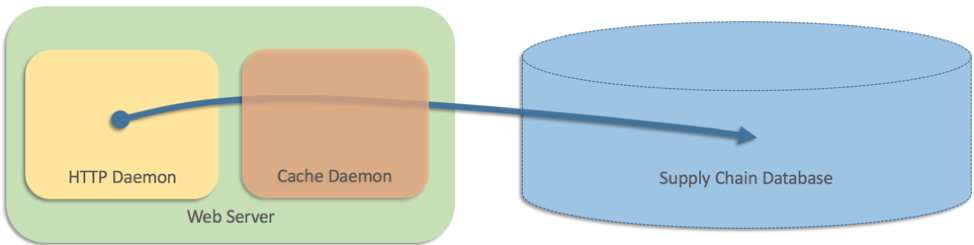
Вот как выглядел псевдокод:
Все было хорошо, но команда наших специалистов также попыталась решить проблему, вследствие которой кэш (отдельный процесс) по какой-то причине работал с ошибками. В этом сценарии веб-серверы возвращались к отправке запросов непосредственно в базу данных. В псевдокоде мы написали следующее: Возврат к прямым запросам к базе данных был интуитивно понятным решением, которое работало несколько месяцев. Однако впоследствии все процессы кэширования завершились ошибками приблизительно в одно время, то есть каждый веб-сервер обращался непосредственно к базе данных. Возникшей нагрузки хватило для полной блокировки базы данных. Веб-сайт полностью вышел из строя, так как все выполняемые веб-серверами процессы блокировались в базе данных. Эта база данных по цепочке поставок также имела решающее значение для центров выполнения заказов, поэтому перебои продолжались, и все центры выполнения заказов по всему миру были закрыты до тех пор, пока проблема не была устранена. Все проблемы, которые мы видели в случае с одной машиной, присутствовали в распределенном случае с более тяжелыми последствиями. Протестировать запасной вариант распределенного резервного варианта было сложно; даже если бы мы смоделировали сбой кэша, мы бы не обнаружили проблему, для срабатывания которой требовались сбои на нескольких машинах. И в данном случае резервная стратегия сама по себе усугубила проблему и оказалась хуже, чем полное отсутствие запасной стратегии. В результате частичного простоя веб-сайта (из-за отсутствия возможности отображать скорость доставки) произошел полный сбой сайта (страницы не были загружены вообще), а в серверной части была отключена вся сеть выполнения заказов Amazon. В данном случае наша запасная стратегия была нелогичной. Если надежнее было отправлять запросы непосредственно в базу данных, а не через кэш, зачем мы внедрили его? Мы боялись, что отсутствие кэша приведет к перегрузке базы данных, но при этом использовать потенциально небезопасный код отработки отката было совсем нецелесообразно. Возможно, мы заметили ошибку на раннем этапе, но ошибка была скрытой, и ситуация, вызвавшая сбой, возникла спустя несколько месяцев после запуска.
if (cache_healthy) {
shipping_speed = get_speed_via_cache(sku);
} else {
shipping_speed = get_speed_from_database(sku);
}Как компания Amazon избегает откатов
Учитывая все эти недостатки отката в распределенных системах, в настоящее время мы практически всегда отдаем предпочтение альтернативным вариантам. Они перечислены ниже.
Улучшение надежности сценариев, не предусматривающих отката
Как упоминалось ранее, стратегии откатов просто сокращают вероятность полных сбоев. Доступность сервиса можно значительно улучшить, повысив надежность главного кода (не предназначенного для отката). Например, вместо того чтобы внедрить логику отката между двумя хранилищами данных, можно инвестировать средства в базу данных, которая отличается большей доступностью, такую как Amazon DynamoDB. Компания Amazon часто и успешно использует эту стратегию. Например, в этом докладе описывается использование DynamoDB для поддержки amazon.com в Prime Day 2017.
Устранение ошибок оператором
Одно из решений по устранению критических сбоев в системе – не применять откат, а позволить системе отправки вызовов устранить ошибку (например, путем повторной попытки). Это предпочтительная стратегия для сервисов AWS, в которых интерфейсы командной строки и пакеты SDK уже включают встроенную логику повторных попыток. Мы стараемся по возможности использовать эту стратегию, особенно в ситуациях, когда значительное внимание было уделено внедрению принципа fate-sharing (разделение судьбы) и снижению вероятности сбоя основного сценария (кроме того, крайне маловероятно, что логика отката приведет к улучшению доступности).
Упреждающая передача данных
Во избежание откатов мы также сокращаем количество перемещаемых компонентов при ответе на запросы. Например, если для выполнения запроса сервису требуются данные, которые уже размещены в локальной среде (их не нужно извлекать), необходимость в стратегии обработки отказов отпадает. Успешным примером этого является реализация ролей AWS Identity and Access Management (IAM) для Amazon EC2 . Сервису IAM необходимо предоставить коду, запущенному в инстансах EC2, подписанные и подвергшиеся ротации данные для доступа. Чтобы полностью избежать отката, данные для доступа заранее передаются в каждый инстанс и остаются действительными в течение многих часов. Таким образом, связанные с ролью IAM запросы продолжат работать даже при маловероятном случае ошибки в работе механизма передачи.
Преобразование отката в обработку отказа
Один из главных недостатков отката заключается в том, что он редко используется и может не сработать или увеличить масштаб последствий при запуске во время сбоя. Может пройти несколько месяцев или даже лет, прежде чем возникнут естественные условия для запуска отката! Чтобы устранить проблему скрытых ошибок, вызываемых стратегией откатов, ее нужно регулярно применять в рабочей среде. Сервис должен постоянно запускать логику отката и его неприменения. Он не просто должен запускать сценарий отката, но и рассматривать его в качестве одинаково действительного источника данных. Например, сервис может случайным образом выбирать ответы, подразумевающие откат и не предусматривающие его (при их получении), чтобы убедиться в работоспособности обоих ответов. Однако в этом случае стратегия не может считаться откатом, а определенно является обработкой отказа.
Предотвращение превращения повторных попыток и тайм-аутов в откат
Повторные попытки и тайм-ауты описаны в статье Тайм-ауты, повторные попытки и перерыв в работе с дрожанием. В статье говорится, что повторные попытки являются мощным механизмом обеспечения высокой доступности в условиях временных и случайных ошибок. Другими словами, повторные попытки и тайм-ауты гарантируют защиту от случайных ошибок, вызванных незначительными проблемами, такими как фиктивная потеря пакетов, сбой независимого отдельного компьютера и т. д. Однако повторные попытки и тайм-ауты легко выполнить неправильно. Сервисы часто работают целыми месяцами, редко прибегая к повторным попыткам, что может сказаться на сценариях, которые команда ваших специалистов никогда не проверяла. По этой причине мы ведем метрики, которые отслеживают общую частоту повторных попыток, и используем оповещения, уведомляющие наших специалистов о частом выполнении повторных попыток.
Еще один способ избежать превращения повторных попыток в запасной вариант — постоянно выполнять их с помощью упреждающих повторных попыток (также называемых хеджированием или параллельными запросами). Этот метод встроен в системы, которые выполняют операции кворумного чтения или записи, при которых системе для реагирования может понадобиться ответ от двух или трех серверов. Упреждающая повторная попытка соответствует схеме постоянной работы. Постоянное выполнение избыточных запросов помогает избежать дополнительной нагрузки на систему, связанной с повторными попытками, по мере увеличения потребности в избыточных запросах.
Выводы
Компания Amazon избегает откатов своих систем, так как их эффективность сложно подтвердить и проверить. Стратегии откатов обеспечивают режим работы, в который система переходит только при наличии хаотических сбоев, и переключение в этот режим только увеличивает хаос. После внедрения стратегии откатов до ее применения в рабочей среде часто проходит значительное время.
Вместо этого мы предпочитаем ветви кода, которые постоянно (а не редко) выполняются в рабочей среде. Мы уделяем основное внимание улучшению доступности наших первичных систем, используя такие модели, как передача данных в системы, нуждающиеся в них, вместо того, чтобы передавать данные с риском ошибки удаленного вызова в критический момент. Наконец, мы отслеживаем необычные действия кода, которые могут привести к переключению в режим отката, например выполнение чрезмерного количества повторных попыток.
Если в системе крайне важно предусмотреть откат, мы как можно чаще выполняем его в рабочей среде, чтобы откат выполнялся с надежностью и предсказуемостью, характерными для основного режима роботы.
Об авторе
Джейкоб Габриэльсон – главный инженер в Amazon Web Services. Он сотрудничает с Amazon уже 17 лет и занимается в основном разработкой внутренних платформ микросервисов. Последние 8 лет он работает над EC2 и ECS, в том числе отвечает за системы развертывания программного обеспечения, сервисы плоскости управления, спотовый рынок, платформу Lightsail и (в последнее время) контейнеры. Джейкоб увлекается программированием систем, языками программирования и распределенными вычислениями. Больше всего ему не нравится двухрежимное поведение системы, особенно при возникновении сбоев. Он закончил Вашингтонский университет (г. Сиэтл), получив диплом бакалавра по компьютерным наукам.
