Comment a été ce contenu ?
- Apprendre
- Articul8 AI comble le déficit d’expertise industrielle avec des modèles Llama 4 spécialisés et une architecture AWS axée sur la sécurité
Articul8 AI comble le déficit d’expertise industrielle avec des modèles Llama 4 spécialisés et une architecture AWS axée sur la sécurité

Les entreprises industrielles s’exposent à des risques financiers importants et à des retards opérationnels lorsqu’elles utilisent des modèles d’IA généralistes qui assimilent les données techniques spécialisées à du bruit blanc. Ces approches peinent à interpréter les journaux complexes des machines et les données de capteurs, ce qui entraîne des analyses des causes racines imprécises et des durées d’indisponibilité prolongées. Pour répondre à ce problème, Articul8 AI a développé une plateforme d’IA générative de niveau professionnel reposant sur des modèles Meta Llama spécialisés. En collaboration avec Meta et Amazon Web Services (AWS), Articul8 a créé des modèles propres à chaque domaine qui identifient les pannes d’équipement avec une précision globale de 88 %, offrant ainsi la plus forte densité d’intelligence spécifique au domaine. Les responsables industriels peuvent ainsi délaisser la collecte manuelle des données au profit d’une atténuation proactive des risques et d’une résolution plus rapide des interventions de maintenance.
Une solution pour percer à travers le bruit blanc de l’IA généraliste
Articul8 AI fournit une plateforme d’IA générative de niveau professionnel qui permet à des secteurs comme l’énergie et la fabrication de créer des applications qui vont bien au-delà du simple chatbot. Dans ces secteurs, les modèles généralistes sont souvent insuffisants, car ils ne possèdent pas l’expertise technique approfondie nécessaire pour interpréter des jeux de données complexes, comme les journaux des machines et les données de capteurs issues d’un atelier de production. Par exemple, dans la production et le stockage d’énergie, un modèle doit pouvoir distinguer des nuances techniques hautement spécialisées afin de contribuer à résoudre des problèmes de conception ou à planifier des arrêts de maintenance critiques. Pour un non-spécialiste, ces particularités techniques peuvent ressembler à du bruit blanc, mais pour un ingénieur, l’incapacité d’un modèle à les saisir rend ses résultats peu fiables pour une analyse des causes profondes à forts enjeux.
L’impact de ce déficit d’expertise se mesure en pertes financières massives et en manque de différenciation concurrentielle. Dans le secteur manufacturier, une panne d’équipement se traduit directement par des durées d’indisponibilité en production coûteuses ; comme l’explique Felipe Viana, responsable de la recherche appliquée chez Articul8 : « Lorsqu’une usine ne produit pas, elle ne génère tout simplement pas de revenus. Remettre cette installation en service plus rapidement n’est pas seulement un objectif technique : cela se traduit directement par des revenus récupérés. » Au-delà de ces coûts opérationnels immédiats, les organisations qui s’appuient uniquement sur des modèles prêts à l’emploi se heurtent à un problème de différenciation durable. Si chaque entreprise de services publics utilise le même modèle généraliste, sa seule différenciation réside dans l’ingénierie de requête : une barrière superficielle qui ne protège ni ne valorise ses données exclusives.
Au-delà de ces obstacles stratégiques, les entreprises industrielles doivent composer avec une tension critique entre densité d’intelligence, c’est-à-dire la puissance de raisonnement d’un modèle par rapport à sa taille, et contraintes d’infrastructure. Pour atteindre des performances de niveau expert, les organisations ont traditionnellement été contraintes d’étendre indéfiniment leur empreinte de calcul, ce qui devient rapidement prohibitif. En outre, de nombreux clients exigent que les applications soient entièrement isolées d’Internet ou déployées dans des clouds privés virtuels (VPC) strictement contrôlés afin de garantir la sécurité. Il en résulte un compromis d’importance majeure : les entreprises ont besoin d’une solution dotée d’une densité d’intelligence suffisante pour gérer des flux de travail agentiques complexes de niveau expert, tout en restant assez efficace pour tenir dans une empreinte matérielle compatible avec leurs budgets existants.
Création d’une IA industrielle spécialisée avec Meta Llama 4 sur Amazon SageMaker HyperPod
Pour combler l’écart entre l’infrastructure brute et les applications d’entreprise, Articul8 a développé une plateforme qui transforme des modèles généralistes en actifs spécialisés et hautement performants. Au cœur de cette stratégie se trouve sa solution exclusive ModelMesh, un moteur sophistiqué de raisonnement agentique qui constitue le noyau fonctionnel du raisonnement pour l’IA industrielle. Articul8 a utilisé AWS pour alimenter cette plateforme, en s’appuyant sur Amazon SageMaker HyperPod afin de gérer des charges de travail d’entraînement complexes et distribuées avec la flexibilité granulaire requise par les modèles industriels à grande échelle. En utilisant les versions Slurm et Amazon Elastic Kubernetes Service (Amazon EKS) d’HyperPod, l’équipe de recherche appliquée d’Articul8 effectue un pré-entraînement continu sur les modèles de fondation Meta Llama-4-Maverick. Ce processus injecte directement dans l’architecture du modèle des connaissances propres au domaine, issues d’un mélange organisé de corpus techniques et scientifiques. Articul8 peaufine ensuite ces modèles au moyen d’une boucle itérative d’ajustement supervisé et d’apprentissage par renforcement afin de garantir un raisonnement de niveau expert. Pour exécuter cet entraînement intensif dans des secteurs comme l’énergie et la fabrication, Articul8 s’appuie sur des instances Amazon Elastic Compute Cloud (Amazon Articul8), qui maintiennent des performances élevées et l’intégrité des données tout au long du pipeline.
Articul8 a choisi Meta Llama comme cœur de ce moteur, car il fournit le premier framework open source stable capable de fusionner des entrées multimodales, comme des dessins de CAO et des journaux de capteurs, avec des charges de travail textuelles agentiques sophistiquées. Cette densité d’intelligence permet à Articul8 de fournir des informations de niveau expert tout en limitant le nombre de paramètres. Il s’agit d’une exigence essentielle pour les clients industriels soumis à des budgets matériels stricts, qui ne peuvent pas se permettre d’exécuter d’immenses modèles généralistes. Felipe Viana précise : « Avant Llama, nous devions orchestrer des modèles distincts et fragmentés pour le texte et la vision. Llama a été la première base solide qui nous a permis de créer un système unique et unifié maîtrisant simultanément les applications multimodales et les flux de travail agentiques complexes. »
Le déploiement sur AWS permet à Articul8 de fournir une architecture axée sur la sécurité qui répond aux exigences strictes des secteurs réglementés. Comme de nombreux clients des services publics et de la fabrication doivent conserver un contrôle rigoureux de leurs environnements, Articul8 utilise Amazon Virtual Private Cloud (Amazon VPC) pour héberger sa plateforme dans l’infrastructure sécurisée du client. Le choix de ce modèle de déploiement permet de vérifier que les données exclusives d’une entreprise restent protégées par ses propres protocoles de sécurité tout en bénéficiant de l’échelle du cloud. Une étroite collaboration technique avec AWS a encore affiné cette architecture, en offrant à Articul8 une assistance approfondie et un accès anticipé à des optimisations d’infrastructure qui ont accéléré le passage du prototype à la production. En définitive, la synergie entre l’infrastructure AWS et les modèles à pondérations ouvertes de Meta offre une alternative fiable et rentable aux modèles frontières génériques, donnant aux responsables industriels une voie spécialisée vers une IA prête pour la production.
Établissement d’une précision SOTA et d’une fiabilité de niveau industriel
En concevant sa plateforme sur AWS avec Meta Llama, Articul8 a redéfini en profondeur le plafond de performance de l’IA générative industrielle. Le passage à une architecture de modèle spécifique au domaine (DSM) a entraîné un bond majeur de la précision technique, en particulier pour le secteur de l’énergie. Selon les benchmarks énergétiques de l’entreprise, Articul8 Energy DSM a atteint une précision globale de 88 %, comme l’indique le tableau ci-dessous. La figure suivante illustre le benchmark par thème.
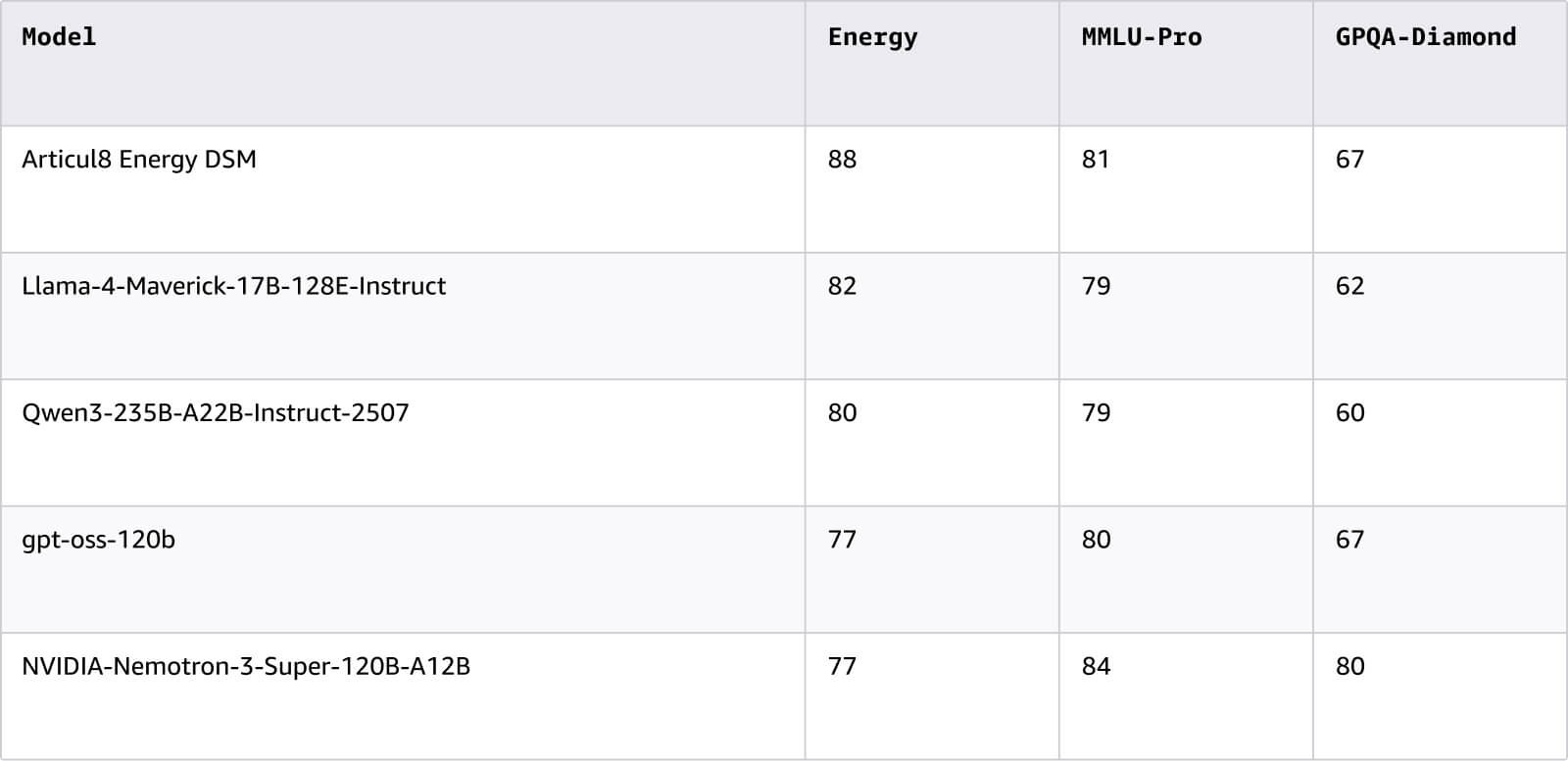
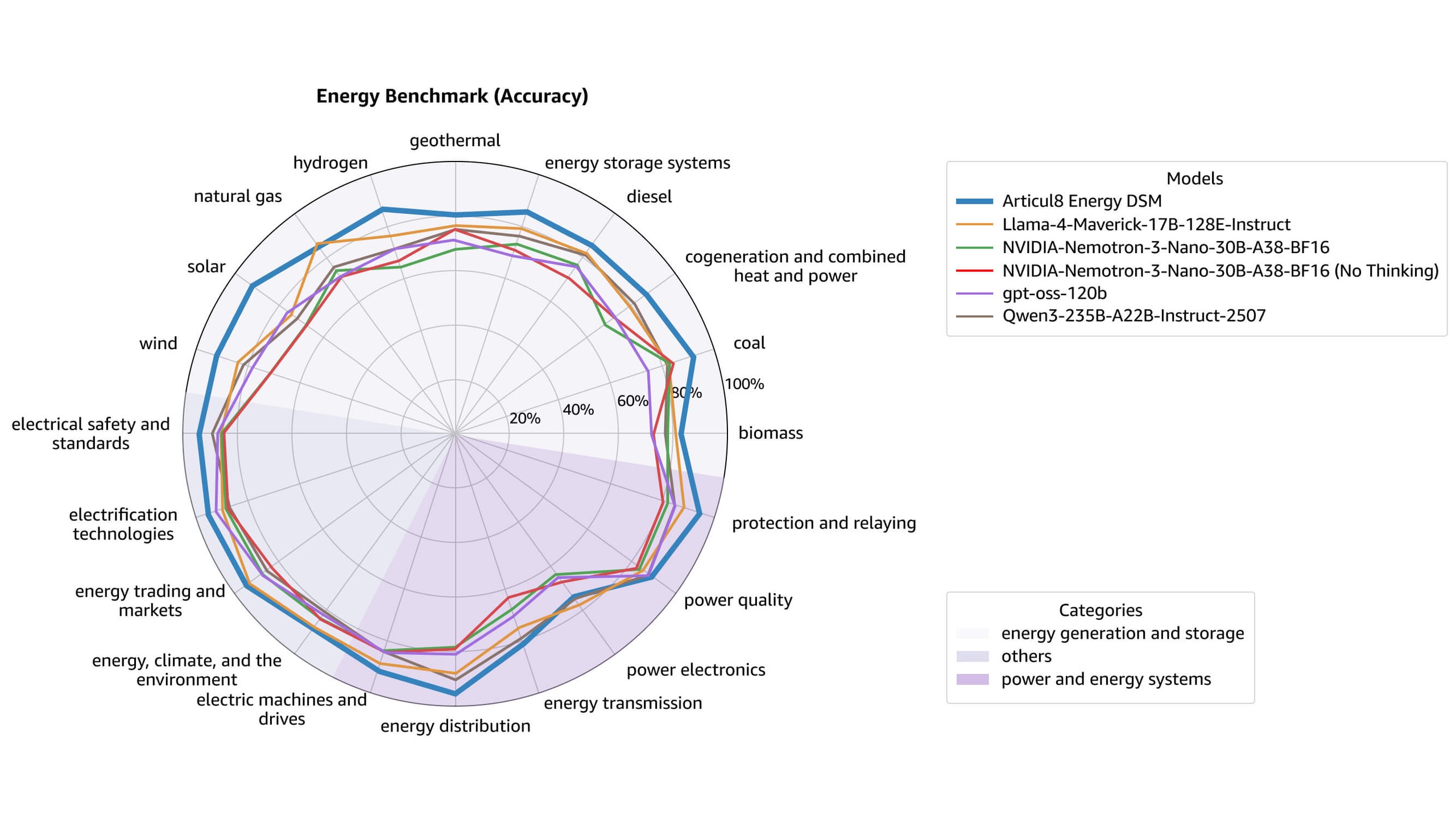
En ancrant la plateforme dans des données techniques exclusives plutôt que dans une simple ingénierie de requête, Articul8 permet à ses clients de bâtir un avantage concurrentiel durable et difficile à reproduire. L’impact opérationnel est particulièrement évident dans les environnements complexes de fabrication et de services publics, où des flux de travail agentiques spécialisés identifient et résolvent désormais les pannes d’équipement avec une rapidité sans précédent. En transformant des particularités techniques qui relevaient du bruit blanc en renseignements exploitables, la plateforme permet aux sites de reprendre rapidement la production, récupérant ainsi des revenus auparavant perdus en raison de durées d’indisponibilité.
La synergie entre l’infrastructure AWS et la densité d’intelligence de Llama a également apporté une stabilité système essentielle. Articul8 est parvenu à accroître l’expertise du domaine tout en conservant un nombre de paramètres réduit, ce qui permet aux clients de déployer une IA de niveau expert dans leur propre instance Amazon VPC sans dépasser des budgets matériels stricts. Felipe Viana précise : « Le fait que le système soit moins complexe signifie qu’il est plus stable et plus fiable. Ce ne sont pas des choses que l’on voit dans les benchmarks, mais nos clients, eux, les remarquent. » Cette base fiable sur laquelle s’appuyer ne fait pas que résoudre les inefficacités opérationnelles immédiates ; elle fournit également le cadre pouvant être mis à l’échelle nécessaire pour que les entreprises progressent vers des flux de travail agentiques entièrement autonomes et de niveau expert sur l’ensemble du réseau énergétique mondial. Prêt à entraîner et déployer des modèles à grande échelle ? Découvrez comment Amazon SageMaker et Amazon EC2 peuvent vous aider à créer, itérer et exécuter des charges de travail d’IA, même dans les environnements en temps réel les plus exigeants.
Comment a été ce contenu ?