Come ti è sembrato il contenuto?
Lingua dei contenuti
Al momento, non tutti i contenuti sono tradotti.
- Scopri
- World Models and the multimodal AI stack: rewriting the rules of robotics
World Models and the multimodal AI stack: rewriting the rules of robotics

For most of human history, we learnt about and made sense of the world through our bodies and sense of touch. We learnt that fire burns by getting too close to a flame, we learnt that ice is slippery by falling. That knowledge was embodied, gained through direct experience, and could only spread as fast as one person could experience it, accumulate it, and pass it on.
To transmit and share knowledge more widely, we had to formalize it. Laws of motion were written down, thermodynamics were codified, and systems which modelled how the world behaves were built. This approach created the foundation of physics, and for three centuries these hand-crafted rules were the only means we had of making sense of the world.
Then came the machine learning revolution, and instead of manually encoding knowledge, systems could be trained to learn it. Hand-built representations were replaced with learned ones, not for physics (yet), but for language. The moment a transformer model trained on text from the internet could generate fluent, coherent prose, the grammar rules that linguists had spent decades writing down suddenly became obsolete. The gap between the old, hand-built approach and the new one, of learned representations, marked a major structural shift. In under a decade, the entire edifice of rules-based NLP had collapsed.
One giant leap for robotics?
Robotics and physical AI today are in exactly the same position that language AI was in 2005. Every simulation is built on hand-coded physics. Every collision dynamic, every friction coefficient, and every contact model are specified by engineers who are, in effect, writing grammar rules for the physical world.
A robot trained in one of these simulations can perform well for the environment it was created for. Problems arise, however, if you take it to an unfamiliar environment, like a kitchen, or ask it to perform a new task, like grabbing an object. Not because the simulation was badly built, but because of structural failures: you can’t hand-code your way to general physical intelligence any more than you could hand-code your way to GPT-4. Hand-coded physics can't scale to general physical intelligence.
If language AI made such a dramatic leap, why can’t robotics? LLMs had a significant advantage: the internet. With trillions of tokens, already digitized, and essentially free, LLMs had access to the largest corpus of human knowledge ever assembled. GPT-4, for instance, trained on around 13 trillion tokens. Robotics has no equivalent resource base. Every robot trajectory (an instance of a robot completing a task), requires physical hardware, human operators, real environments, and painstaking curation. The Open X-Embodiment dataset, the combined output of thirty-four robotics laboratories worldwide, contains around one million of them. That gap, between GPT-4’s 13 million tokens versus one million trajectories, is huge, and it can’t be closed with incremental investment.
An entirely new approach to data acquisition is needed. And the one that’s emerging, training robots on internet video, may represent the most consequential architectural decision in the history of physical AI.
World models, world knowledge & neural networks
A world model is a neural network that learns physical intuition in a similar way that humans do, through observation rather than formalization. How does a child learn that a ball will roll off a table? Not by solving Newton’s second law, nor by running a physical simulation. It watches, and eventually it knows.
A world model works in the same way. Show it millions of hours of video, cooking tutorials, factory floors, traffic, construction, and it’ll start to develop an internal picture of how the world behaves. This kind of implicit understanding isn’t a less valuable form of knowledge. It’s often more reliable, because it’s more flexible and holds up in situations that no hand-coded model could have anticipated. Why does this matter for robotics? It comes down to a distinction between two types of knowledge.
World knowledge, such as the examples of how objects behave under gravity and how materials change, is universal. It has nothing to do with the specific robot. It’s the physics of reality itself and, fortunately for the development of robotics, the internet is saturated with video demonstrating exactly this.
Action knowledge, how a specific robot translates commands into physical movement, is hardware-specific and has to be learned from robot-specific data. Research gathered across the past two years has delivered a critical insight: you need very little action knowledge once you have strong world knowledge underneath.
Let’s look at two recent results which illustrate this in practice. First, Meta’s V-JEPA 2. The world model was trained on over one million hours of internet video, then given just 62 hours of unlabeled robot video with no task-specific training. It achieved 80 percent zero-shot success on pick-and-place tasks across laboratories it had never seen before.
Second, DeepMind’s Dreamer 4. The AI agent learned to collect diamonds in the game Minecraft, which required 20,000 sequential decisions from raw pixels, without any environmental interaction whatsoever. Both examples point to the same underlying dynamic: understanding how the physical world works can be achieved using the vast supply of internet video that already exists. The robot-specific data, which is scarce, only needs to cover the much smaller problem of how that particular machine moves. The data scarcity challenge that has held robotics back for years is suddenly far more manageable.
Five architectures, one open question
The term ‘world model’ is applied loosely. In practice, the major approaches disagree profoundly about what physical representation means. Five architectures have emerged, each built on a different theory of how physical systems should be encoded in a learned system. They agree that hand-coded simulation is insufficient. They disagree about nearly everything else.
Video-generative models take the most direct approach. Models like NVIDIA’s Cosmos and Runway’s GWM-1 both work by predicting future frames, given that a specific action has taken place. This is based on the idea that video captures enough information about the physical world to be able to train robots. The drawback here is efficiency, as the model uses significant resources predicting every pixel in a frame, including those that are irrelevant to the task. DeepMind’s Genie 3 pushes this the furthest. Running at 24 frames per second, it is the first world model that works in real time, functioning as live, playable simulation.
Latent space models have produced some of the most significant results. Danijar Hafner and Timothy Lillicrap at DeepMind, for instance, developed the Dreamer series around a simple idea. Instead of predicting what the next video frame will look like, the model builds a simplified internal summary of the world’s current state and uses that to simulate what happens next. This is far more efficient and has had some impressive results:
- Dreamer V2 was the first agent to reach human-level performance on Atari through a world model.
- Dreamer V3 outperformed specialized methods across over 150 tasks with no task-specific tuning.
- Dreamer 4 trained entirely from pre-recorded data, with no live environment interaction at all.
JEPA (Yann LeCun’s Joint Embedding Predictive Architecture), predicts abstract representations instead of pixels. This is based on the idea that an abstract, conceptual understanding of the world, rather than raw visual information, is more effective for physical reasoning. V-JEPA 2 achieved 80 percent zero-shot success on manipulation tasks using only internet video. LeCun backs this approach to the extent that he founded AMI Labs in Paris, which raised US $1.03 billion at a US $3.5 billion valuation, before it had even shipped a single product.
Native multimodal reasoning is the idea that an AI system needs to process text, images, video, and audio together from the ground up, not as separate components bolted together. The other four architectures assume that you can take a system built for text and add physical understanding onto it. Native multimodal reasoning rejects this, arguing that retrofitting physical understanding onto a text-first systems creates a hard ceiling on what it can ever achieve. Elorian, co-founded by Andrew Dai and Yinfei Yang are building on this thesis. Striker Partners led the co-seed round.
Diffusion-based world models may function as general-purpose learned simulators, generating accurate environments entirely from dynamics. The agentic AI model DIAMOND achieved the highest human-normalized score of any world model on Atari 100k. UniSim demonstrated that a single diffusion-based model can simulate how both humans and robots interact with the physical world. Of the five architectures, diffusion-based models are the least tested in real-world robotics.
It’s unclear if one paradigm will dominate or whether the five will gradually merge into something new. Evidence from the past 18 months suggests hybridization. Physical understanding is emerging across all five architectures as they scale, and the gap between each is narrowing. When this happens, the biggest differentiator may not be architectural, it may come down to which team can turn research into production the fastest.
Scale is working. The economics are not.
The field is progressing at a rapid rate. World model parameters have compounded roughly a thousandfold in five years, from PlaNet’s two million to Cosmos’s 14 billion. Training runs now rival the largest language model efforts: Cosmos consumed 10,000 H100 GPUs for three months. At this scale, something interesting starts to happen.
Understanding of the physical world is starting to emerge as an unintended side effect of scale. Models weren’t programed to understand cause and effect in the physical world, instead, they worked it out. OpenAI observed this in Sora, for example, as 3D consistency, object permanence, and realistic physics arose as a result of properties of scale in the model. DeepMind observed the same in Genie 2 at 11 billion parameters. The same pattern held across every architecture, making it hard to write off as mere coincidence.
Several major players have recently chosen to release their models publicly rather than keeping them private. NVIDIA’s Cosmos, Meta’s V-JEPA 2, and Physical Intelligence’s pi-zero were all open-sourced in 2025. In a competitive field this is a telling sign, suggesting that contributing to a broad research community is becoming a better strategy for progress than keeping them behind closed doors.
However, while the capability of models has improved, the cost of running them has not. A text language model costs approximately fifteen cents per hundred user-hours. Sora costs US $468 per user-hour. Even Odyssey, among the more efficient options, still requires a dedicated H100 per session at US $50 per hour. The reason is structural, as video has to be generated continuously, in real time, frame by frame. You can’t spread 50 users across a single GPU the way text models can, meaning the unit economics are closer to premium cloud compute than to API pricing.
This gap, between what the models can do in research and what it costs to run them, is the biggest obstacle between lab results and real-world deployment. The good news? We’ve seen this kind of cost curve before. LLM inference costs fell roughly a thousandfold in three years, and Decart already claims a 400x cost reduction for video through a custom-built engine. The production-grade inference systems that will deliver this at scale do not yet exist as commercial products. As such, the teams that are first to build them will gain a strong competitive advantage.
NVIDIA has assembled the most vertically integrated infrastructure stack in this space: Cosmos for world model training, Isaac Sim for physics simulation, GR00T for humanoid foundation models, Omniverse for digital twins, and Jetson Thor for edge VLA inference. AWS provides the cloud layer on which all of this trains and deploys: Amazon SageMaker for model training, AWS Batch for large scale simulation and workload orchestration, AWS Inferentia for optimized inference, and AWS IoT Greengrass for edge fleet management. In production, the pattern is consistent: NVIDIA for physics fidelity, cloud for training and data orchestration, purpose-built silicon for real-time deployment.
Three gaps that determine timelines
The infrastructure challenge is not the only thing standing between research and commercial deployment. There are three deeper, structural gaps that will determine how quickly this transition happens.
1. The data gap
The first is a gap that no amount of video cannot close. Video captures how things look, not how they feel. Tasks that involve touch, like handling materials, inserting components or assembling parts, result in a drop in model performance from impressive to unusable. Why? There is no tactile information in the training data. Consider that a human hand contains 17,000 touch receptors. Most deployed robot hands, on the other hand, have zero tactile sensors. Despite the sensors themselves being available, there is currently no standardized tactile dataset that exists at scale. This is not a failure of funding or technology, but rather a failure of coordination. Every laboratory would benefit from such a dataset, but none has enough incentive to build it alone. Whoever solves this coordination problem, whether through an open consortium or a commercial data play, accelerates the entire field by a magnitude that is difficult to overstate.
2. The architectural gap
Most robotics companies today rely on imitation learning: demonstrate a task, have the robot replicate it. This works for simple tasks but struggles in unpredictable conditions. When UPenn’s GRASP Lab tested robots trained this way in genuinely novel conditions, it recorded a success rate of only 16.7 percent, which is a long way from the reliability demanded by real-world conditions.
World models offer a different approach. A robot can explore failure modes in simulation, iterate through edge cases without physical risk, and build up competence before deploying in the real world. Every documented case of a robot operating continuously for 10 hours or more without human intervention has used this reinforcement learning, not imitation learning. To achieve industrial-grade reliability, we need to move beyond simple imitation to more robust learning methods.
3. Temporal coherence
Video-generative world models can simulate convincing physics over short periods. Streched over longer periods, and they start to become inconsistent. Objects might end up in the wrong place or something that should cause a reaction doesn’t. The longer the simulation runs, the more the errors can build up, until the simulated world no longer resembles the physical one. Genie 3, for instance, is coherent for only a few minutes before this kind of drift sets in. It’s a problem that’s built into how these models are designed, so requires an architectural solution. Other models, like World Labs’ Marble, can handle temporal drift better, but these tend to be more expensive. The real challenges therefore lies in finding the right balance between high-fidelity simulations and the cost of running them.
Mapping the ecosystem
We mapped over 120 entities across the world models and multimodal AI ecosystem. The full interactive network visualization is included alongside this document.
Many of the people behind these companies are researchers, not product managers, and have left the field of academics to join big tech brands. Hafner and Yan moved from the Dreamer series to Embo, Hausman left DeepMind’s robotics team to co-found Physical Intelligence, LeCun moved from Meta AI to AMI Labs.
The willingness of such researchers to leave their tenured roles and corporate research labs to commercialize the science they’re developing signals a major change. The core science has matured past the point where the return on the next paper exceeds the return on the first product.
How fast & who captures value?
Every major transition in machine learning has followed the same pattern, one so consistent that it resembles a natural law more than a trend. Learned representations replace hand-engineered ones. Every time AI finds a way to learn something automatically from data, it replaces the old approach of humans manually encoding the rules, and it’s happening fast. Transformers did it for hand-coded grammar rules and world models are now attempting the same for physics itself, replacing hand-built simulators with learned models trained on internet-scale video.
The question now is not whether it happens in principle, but how fast it happens, which challenges get solved first, and who captures lasting value.
Scaling is clear and consistent across architectures and the data economics are improving. Inference costs are still high but falling, due to a combination of more efficient model designs, better serving infrastructure, and the rapid deployment of specialized inference hardware.
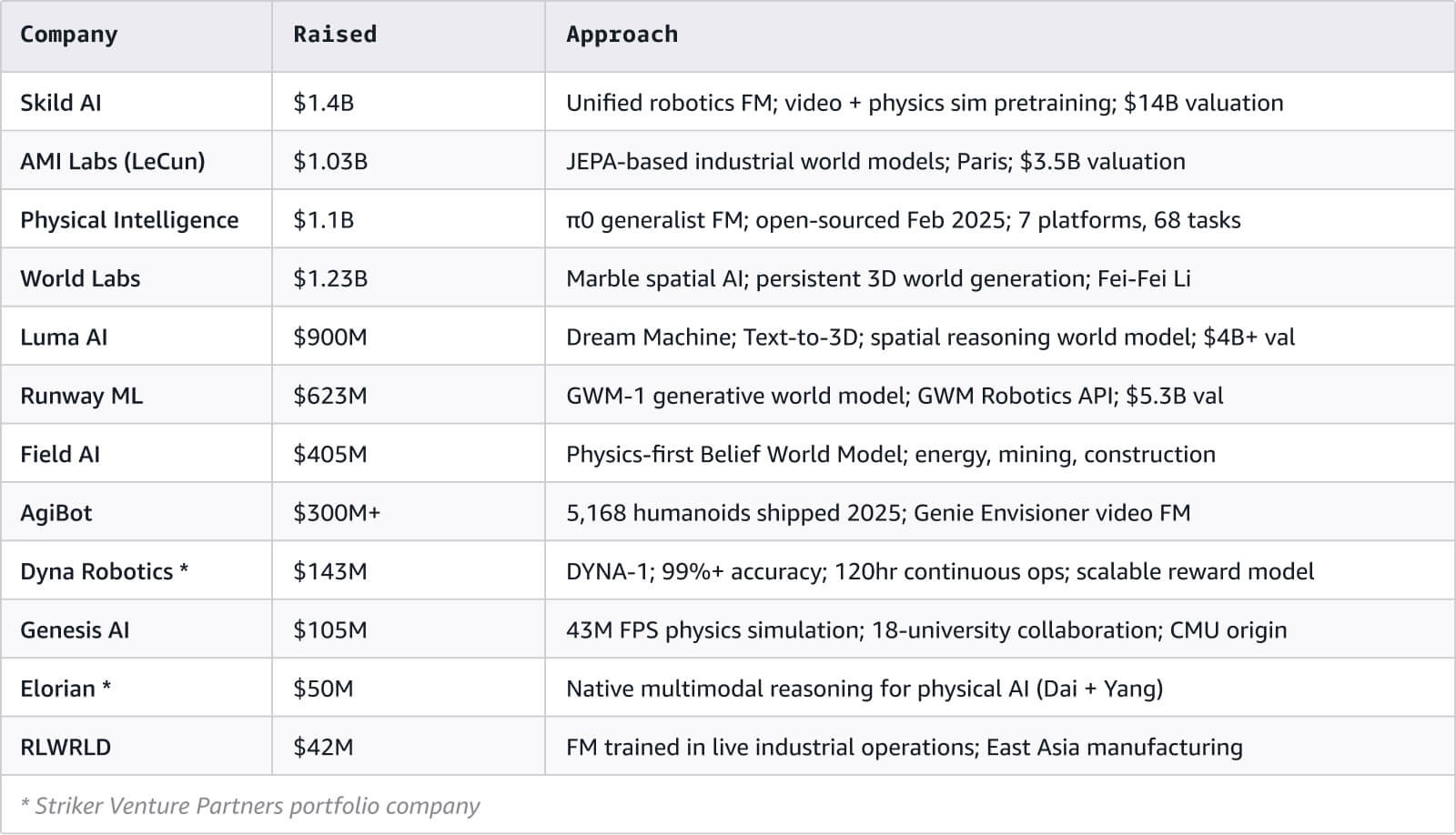
There’s also a wealth of capital supporting the market: over US $3 billion has been raised across the leading foundation model startups, and the companies building humanoid hardware are, in aggregate, valued at over US $50 billion.
The most important layer, and the one that is least developed, is the infrastructure that connects trained models to real-world deployments: the tooling, serving engines, and fleet management systems. The companies and founders who build these solutions will occupy the same position that cloud providers like AWS occupy in the language model world: providing the critical layer on which everything else ultimately depends.

Nikhil Suresh
Nikhil Suresh is an investor at Striker Venture Partners, where he partners with founders from day zero to build category-defining companies across AI, infrastructure, and hardware. A former serial founder and AI researcher at Stanford’s Scaling Intelligence Lab, Nikhil previously was an early engineer at Mercor working on Search and ML. Nikhil focuses on helping high-potential teams navigate early-stage product formation to build durable, generational businesses.

Dhruv Sharma
Dhruv Sharma is part of the Venture Capital & Startups team at AWS, where he partners with leading venture capital firms and their portfolio companies to build, launch, and scale - particularly across AI infrastructure and frontier technologies. Previously, he spent over eight years in venture capital and investment banking, leading investments and helping scale companies from early stage to IPO.
Come ti è sembrato il contenuto?