AWS News Blog
Planetary-Scale Computing – 9.95 PFLOPS & Position 40 on the TOP500 List

|
Weather forecasting, genome sequencing, geoanalytics, computational fluid dynamics (CFD), and other types of high-performance computing (HPC) workloads can take advantage of massive amounts of compute power. These workloads are often spikey and massively parallel, and are used in situations where time to results is critical.
Old Way
Governments, well-funded research organizations, and Fortune 500 companies invest tens of millions of dollars in supercomputers in an attempt to gain a competitive edge. Building a state-of-the-art supercomputer requires specialized expertise, years of planning, and a long-term commitment to the architecture and the implementation. Once built, the supercomputer must be kept busy in order to justify the investment, resulting in lengthy queues while jobs wait their turn. Adding capacity and taking advantage of new technology is costly and can also be disruptive.
New Way
It is now possible to build a virtual supercomputer in the cloud! Instead of committing tens of millions of dollars over the course of a decade or more, you simply acquire the resources you need, solve your problem, and release the resources. You can get as much power as you need, when you need it, and only when you need it. Instead of force-fitting your problem to the available resources, you figure out how many resources you need, get them, and solve the problem in the most natural and expeditious way possible. You do not need to make a decade-long commitment to a single processor architecture, and you can easily adopt new technology as it becomes available. You can perform experiments at any scale without long term commitment, and you can gain experience with emerging technologies such as GPUs and specialized hardware for machine learning training and inferencing.
Top500 Run
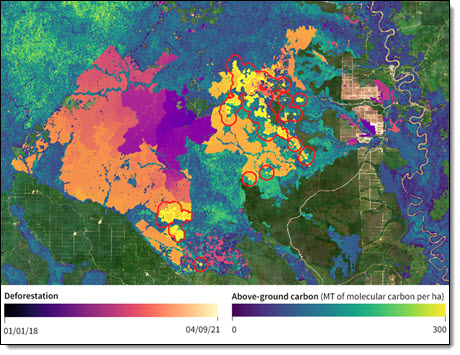 Descartes Labs optical and radar satellite imagery analysis of historical deforestation and estimated forest carbon loss for a region in Kalimantan, Borneo.
Descartes Labs optical and radar satellite imagery analysis of historical deforestation and estimated forest carbon loss for a region in Kalimantan, Borneo.
AWS customer Descartes Labs uses HPC to understand the world and to handle the flood of data that comes from sensors on the ground, in the water, and in space. The company has been cloud-based from the start, and focuses on geospatial applications that often involves petabytes of data.
CTO & Co-Founder Mike Warren told me that their intent is to never be limited by compute power. In the early days of his career, Mike worked on simulations of the universe and built multiple clusters and supercomputers including Loki, Avalon, and Space Simulator. Mike was one of the first to build clusters from commodity hardware, and has learned a lot along the way.
After retiring from Los Alamos National Lab, Mike co-founded Descartes Labs. In 2019, Descartes Labs used AWS to power a TOP500 run that delivered 1.93 PFLOPS, landing at position 136 on the TOP500 list for June 2019. That run made use of 41,472 cores on a cluster of C5 instances. Notably, Mike told me that they launched this run without any help from or coordination with the EC2 team (because Descartes Labs routinely runs production jobs of this magnitude for their customers, their account already had sufficiently high service quotas). To learn more about this run, read Thunder from the Cloud: 40,000 Cores Running in Concert on AWS. This is my favorite part of that story:
We were granted access to a group of nodes in the AWS US-East 1 region for approximately $5,000 charged to the company credit card. The potential for democratization of HPC was palpable since the cost to run custom hardware at that speed is probably closer to $20 to $30 million. Not to mention a 6–12 month wait time.
After the success of this run, Mike and his team decided to work on an even more substantial one for 2021, with a target of 7.5 PFLOPS. Working with the EC2 team, they obtained an EC2 On-Demand Capacity Reservation for a 48 hour period in early June. After some “small” runs that used just 1024 instances at a time, they were ready to take their shot. They launched 4,096 EC2 instances (C5, C5d, R5, R5d, M5, and M5d) with a total of 172,692 cores. Here are the results:
- Rmax – 9.95 PFLOPS. This is the actual performance that was achieved: Almost 10 quadrillion floating point operations per second.
- Rpeak – 15.11 PFLOPS. This is the theoretical peak performance.
- HPL Efficiency – 65.87%. The ratio of Rmax to Rpeak, or a measure of how well the hardware is utilized.
- N: 7,864,320 . This is the size of the matrix that is inverted to perform the Top500 benchmark. N2 is about 61.84 trillion.
- P x Q: 64 x 128. This is is a parameter for the run, and represents a processing grid.
This run sits at position 40 on the June 2021 TOP500 list, and represents a 417% performance increase in just two years. When compared to the other CPU-based runs, this one sits at position 20. The GPU-based runs are certainly impressive, but ranking them separately makes for the best apples-to-apples comparison.
Mike and his team were very pleased with the results, and believe that it demonstrates the power and value of the cloud for HPC jobs of any scale. Mike noted that the Thinking Machines CM-5 that took the top spot in 1993 (and made a guest appearance in Jurassic Park) is actually slower than a single AWS core!
The run wrapped up at 11:56 AM PST on June 4th. By 12:20 PM, just 24 minutes later, the cluster had been taken down and all of the instances had been stopped. This is the power of on-demand supercomputing!
Imagine a Beowulf Cluster
Back in the early days of Slashdot, every post that referenced some then-impressive piece of hardware would invariably include a comment to the effect of “Imagine a Beowulf cluster.” Today, you can easily imagine (and then launch) clusters of just about any size and use them to address your large-scale computational needs.
If you have planetary-scale problems that can benefit from the speed and flexibility of the AWS Cloud, it is time to put your imagination to work! Here are some resources to get you started:
- AWS High Performance Computing page.
- AWS HPC Resources.
- AWS HPC Blog.
- AWS HPC Workshops.
- AWS ParallelCluster.
- AWS High Performance Computing Competency Partners.
Congratulations
I would like to offer my congratulations to Mike and to his team at Descartes Labs for this amazing achievement! Mike has worked for decades to prove to the world that mass-produced, commodity hardware and software can be used to build a supercomputer, and the results more than speak for themselves.

To learn more about this run and about Descartes Labs, read Descartes Labs Achieves #41 in TOP500 with Cloud-based Supercomputing Demonstration Powered by AWS, Signaling New Era for Geospatial Data Analysis at Scale.
— Jeff;
PS – The original version of this post indicated that this run qualified for position 41. After publication, one of the entries was removed and this blog post has been updated accordingly.