- What is Cloud Computing?›
- Cloud Computing Concepts Hub›
- Compute›
- What Is Parallel Processing?
What Is Parallel Processing?
Page topics
- What is parallel processing?
- What are the benefits of parallel processing?
- How does parallel processing work?
- What are the types of parallel processing computer architecture?
- What are the key challenges in parallel processing?
- What are the best practices in parallel processing?
- How does parallel processing compare to distributed computing?
- How does parallel processing enable machine learning?
- How can AWS support your parallel processing requirements?
What is parallel processing?
Parallel processing, or parallel computing, divides a computing task into smaller pieces and then processes each piece individually before combining them to attain an answer. This type of processing can reduce the time required to complete certain tasks and better use available resources. Parallel processing is common in big data analytics and is an essential part of many machine learning training and inference processes.
What are the benefits of parallel processing?
Parallel processing offers a range of benefits when compared to traditional, serialized processing.
Speeds computation
Serial computing takes a sequential approach to solving problems, processing only one instruction at a time to perform a task on a computer. Parallel processing still performs these same tasks but breaks them down into smaller segments and distributes them across multiple processors. Because processors run concurrently, they can complete a computational task much faster, speeding up the overall computation.
Greater data volumes
By processing data through parallel architectures, computer systems can handle larger data sets. When working with a huge volume of data, parallel processing can split it down into smaller units, processing without exceeding the per-node memory limit. For systems that require a high degree of big data analysis or movement, parallel processing can be useful.
Better resource utilization
Because parallel processing splits and distributes a computational task across multiple cores, it ensures the entire system is active when processing tasks. Instead of only using a fraction of available GPU or CPU cores, like you do with sequential computing, this means that the workload can be balanced across all available resources.
Enables real-time analytics
Real-time analytics rely on low-latency processing pipelines that can ingest, transfer, and analyze data as soon as it enters the system. Producing live insights relies on a system that can process data at speed, often using parallel processing to deliver a fast and reliable stream of data.
How does parallel processing work?
Here are the four main stages of parallel processing.
Decomposition
Decomposition is the process of splitting a computational task down into many smaller subsections. The exact format that these smaller segments take depends on the task at hand. For example, if processing data, the system can use data parallelism to split datasets. Alternatively, task parallelism will segment different computational operations, and pipeline parallelism arranges tasks in stages.
Whichever form of decomposition the system uses, it all has the same effect of breaking one large computational task into many smaller tasks.
Distribution
Distribution is the process of taking the segmented tasks and assigning them to individual units within the system. Again, the exact units involved in this stage depend on the type of task a computer needs to solve. The distribution phase assigns tasks to nodes, CPUs, or cores on a GPU, selecting an appropriate target based on current memory constraints and hardware architecture.
Distribution aims to spread out tasks across computational units while minimizing data movement when doing so.
Processing
The processing phase is where each of the nodes that received a task begins to work on their assigned task in parallel. Processing is concurrent, with shared memory architecture or a message-passing interface allowing each node to communicate with the others.
Aggregation
After each node completes its task, the results are recombined during the aggregation phase. Different aggregation systems use distinct parallel algorithms, meaning that this phase might need to merge data partitions, use reduction operations, checkpoint distributed states, or use another strategy to bring the individual components back together.
What are the types of parallel processing computer architecture?
There are several different types of parallel computing architectures that are in common use.
Shared memory parallelism
Shared memory is the most common form of parallel computing, as it is used in everyday technologies like mobile phones and laptops. Shared memory allows nodes to communicate with one another as they all connect to the same memory resource, allowing for rapid communication.
Distributed memory parallelism
Distributed parallelism is where nodes have their own individual memory stores. Instead of using a shared memory system to communicate, they use message passing or another high-speed interconnect.
Graphics Processing Units (GPU) parallelism
GPU parallel computing is where many GPUs run processes concurrently. GPU parallelism is very effective for specific tasks that need high computing power, such as machine learning. GPU parallelism works in a slightly different way from CPU parallelism, requiring different processes and mechanisms.
What are the key challenges in parallel processing?
Although parallel computing is effective for accelerating processing speeds, there are a number of challenges to overcome in deploying effective parallel processing mechanisms.
Synchronization across parallel computers
When distributing work across multiple processors, the computational system needs to coordinate progress and share updates. Synchronization across nodes becomes more challenging as these systems scale in size and complexity. Typically, parallel computing uses algorithmic or locking mechanisms to help ensure data consistency across nodes. Ineffective synchronization leads to bottlenecks, slowing down performance. This makes finding strategies for synchronization an important step of the process.
Network overhead
Distributed systems use various pathways to communicate between nodes, which require network infrastructure. Transferring lots of data between nodes creates latency and consumes bandwidth, especially when done ineffectively. Businesses can use strategies to reduce the need for communication and cut down on data movement to reduce network overhead and help parallel computing systems scale. This includes location, storage, and networking strategies.
Load balancing
Parallel computing works best when every individual node can work at capacity, without nodes idling or processing disproportionately sized workloads. The aim is for all nodes to finish their tasks at approximately the same time, balancing the entire workload across the system. Effective load balancing and distribution require careful data partitioning and redistribution strategies.
Debugging
In serial computing systems, it's easy to debug an error, as you can clearly see the precise step where the process went wrong. With parallel computing, there is a lack of consistency in determining which nodes finish which tasks at which time. This can make it difficult to reproduce an error, let alone isolate the error and perform debugging. Developers need to employ a range of specific tools to debug parallel processing environments.
What are the best practices in parallel processing?
Here are some best practices for using and maintaining a parallel computing system.
Minimize inter-process communication
Excessive communication between tasks slows down performance in parallel programs, as each node is constantly transferring data to others, consuming bandwidth and slowing its progress. Avoid transferring large volumes of data across multiple processors or multi-core systems, focusing on reducing communication where possible.
Balance workloads across systems
Especially in task parallelism, it's important to distribute all of your workloads evenly so that all nodes are active and no one node is overwhelmed by its workload. When using massively parallel processors with a large number of available nodes, focus on breaking down multiple tasks that your parallel programming system performs concurrently.
Profile before optimizing
Profiling your parallel computing workflow will help to pinpoint where potential delays or bottlenecks originate. You can use profiling to detect if the issue comes from ineffective parallel execution, poor task distribution across your multiple processors, or underlying serial computation issues. Identifying and remediating these issues helps to ensure all of your computing resources are used well and that parallel programming runs effectively.
Use established multi-processor frameworks
A multi-processor framework in parallel processing refers to frameworks such as Apache Spark, Hadoop, or GPU-specific frameworks that simplify parallel programming. These frameworks can handle aspects like scheduling, resource management, and memory access across multiple computers. Using established frameworks helps to ensure workloads run effectively locally, across multi-core processors, and in cloud computing environments.
How does parallel processing compare to distributed computing?
Although distributed and parallel computing both improve computation speeds, they use distinct architectures to do so. Parallel computing is where the same instructions that a serial computing system receives are broken down into many segments, each of which runs on separate hardware that focuses on completing concurrently. Parallel computing can occur on one computer with one operating system, using a shared memory pool to communicate across segments.
Distributed computing is where a task is split across different machines, each of which has its own pool of memory and hardware to run that aspect of the problem. Distributed computing systems require coordination from a centralized controller. Distributed computing is more commonly used in cloud computing systems.
How does parallel processing enable machine learning?
Machine learning (ML) workloads use parallel computing to process enormous amounts of data, most typically with large numbers of GPUs. ML employs data parallelism, where multiple processing units complete different data subsets with the same ML model. Instead of having to work through a sequential program, parallel computing provides the speed and agility needed for ML. Without parallel processing, ML tasks with the same data would not process the same operation fast enough to be useful.
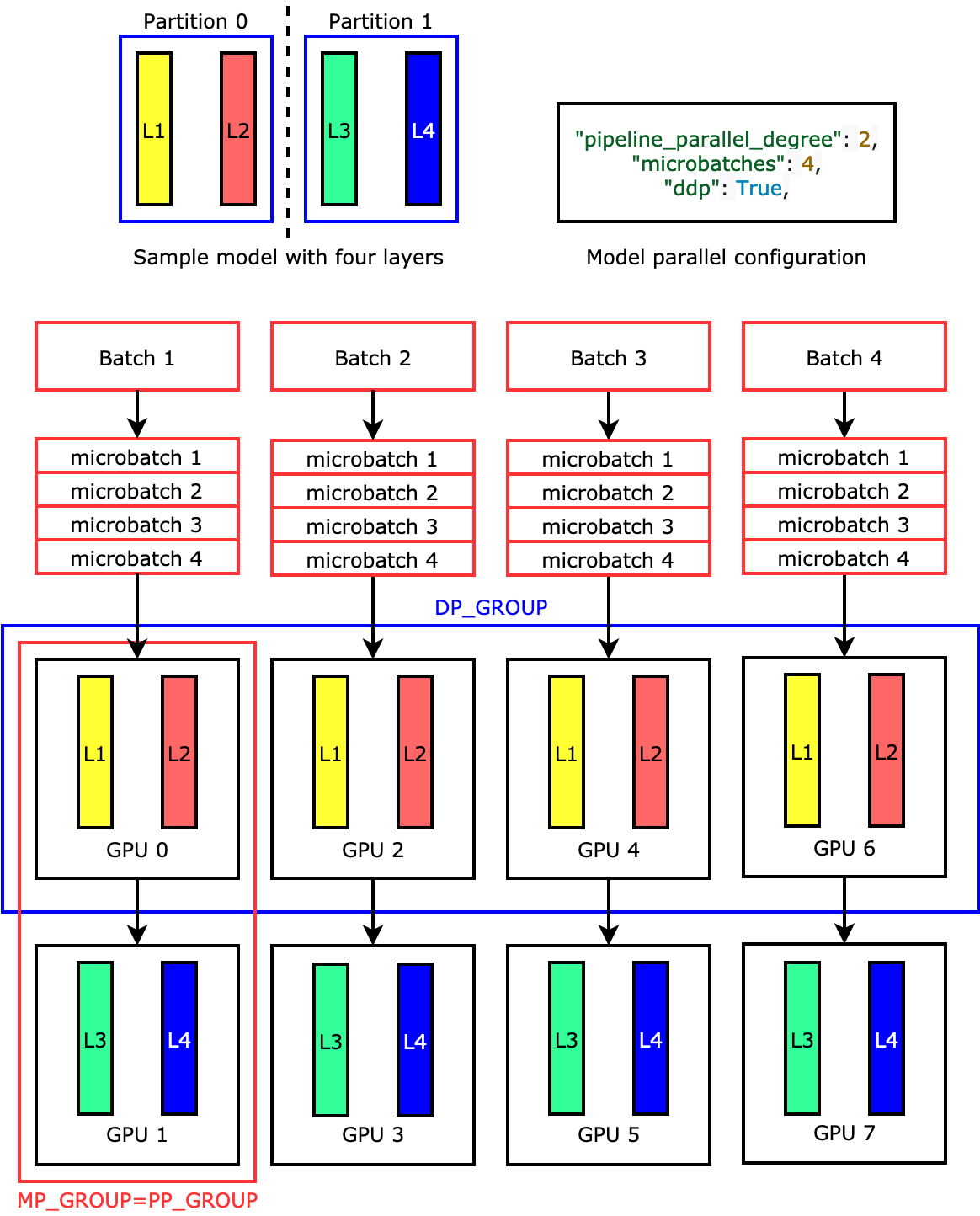
How can AWS support your parallel processing requirements?
AWS has a range of cloud processing services and power-efficient processors that allow parallelism by design. You can choose from these services to speed your processing and meet time-sensitive demands:
- Amazon EMR is a big data processing service that accelerates analytics workloads with unmatched flexibility and scale. EMR features performance-optimized runtimes for Apache Spark, Trino, Apache Flink, and Apache Hive, cutting costs and processing times.
- AWS Batch is a fully managed batch computing service that plans, schedules, and runs your containerized batch ML, simulation, and analytics workloads across the full range of AWS compute offerings, such as Amazon ECS, Amazon EKS, AWS Fargate, and Spot or On-Demand Instances.
- Amazon SageMaker delivers an integrated experience for analytics and AI with unified access to all your data. SageMaker offers distributed training for machine learning models and can help you deploy on parallel architectures.
- Amazon Redshift is a cloud data warehouse with an architecture that allows SQL query parallelism for analytics across massive datasets.
Get started with parallel processing on AWS by creating a free account today.