المدوَّنة العربية
دعم البيانات الوصفية لجميع كائنات S3
أصبحت خدمة البيانات الوصفية Amazon S3 Metadata الآن توفر رؤية شاملة لجميع الكائنات (objects) الموجودة مسبقًا داخل حاويات (buckets) Amazon S3 الخاصة بك و ليس فقط الكائنات الجديدة أو التغييرات على الكائنات الموجودة. مع هذا التوسّع، يمكنك الآن تحليل واستعلام البيانات الوصفية (metadata) لكامل نطاق تخزينك على S3.
يعتمد العديد من العملاء اليوم على Amazon S3 لتخزين البيانات غير المهيكلة على نطاق واسع. وللتعرّف على محتويات الحاويات، كان من الضروري غالبًا بناء أنظمة مخصّصة لمسح الكائنات، تتبّع التغييرات، وإدارة البيانات الوصفية مع مرور الوقت. هذه الأنظمة باهظة التكلفة وصعبة الصيانة، خصوصًا مع نمو حجم البيانات.
منذ إطلاق خدمة البيانات الوصفية Amazon S3 Metadata في مؤتمر re:Invent 2024، أصبح بالإمكان استعلام بيانات الكائنات الجديدة والمحدَّثة من خلال جداول بيانات وصفية (metadata tables) بدلًا من الاعتماد على أدوات مثل Amazon S3 Inventory أو واجهات برمجة التطبيقات (APIs) مثل ListObjects, HeadObject, GetObject، والتي يمكن أن تسبب بطئًا أو تؤثر في سير العمل.
ولتسهيل العمل مع البيانات الوصفية الموسعة، تقدم S3 Metadata جداول جرد محدَّثة (live inventory tables) متوافقة مع أدوات SQL المألوفة. بعد إدراج الكائنات الموجودة مسبقًا في النظام، تظهر أي تحديثات (مثل التحميل أو الحذف) عادةً خلال ساعة في جداول الجرد.
مع جداول الجرد المحدَّثة للبيانات الوصفية (S3 Metadata live inventory tables) تحصل على جدول Apache Iceberg مُدار بالكامل يحتوي على صورة شاملة وحديثة للكائنات وبياناتها الوصفية، بما في ذلك الكائنات الموجودة مسبقًا، وذلك بفضل دعم خاصية إعادة الملء (backfill) . يتم تحديث هذه الجداول تلقائيًا في غضون ساعة واحدة من التغييرات مثل عمليات التحميل أو الحذف. يمكن استخدامها لاكتشاف الكائنات ذات الخصائص المحددة (مثل البيانات غير المشفرة، العلامات المفقودة، أو فئات التخزين المعيّنة) ودعم التحليلات، تحسين التكاليف، التدقيق، والحَوْكَمة.
جداول سجلات البيانات الوصفية (S3 Metadata journal tables)، والتي كانت تُعرف سابقًا باسم جداول البيانات الوصفية لـ S3، يتم تُفعّيلها تلقائيًا عند إنشاء جداول الجرد المحدَّثة. توفر عرضًا شبه لحظي لتغييرات الكائنات في الحاوية بما في ذلك عمليات التحميل والحذف وتحديثات البيانات الوصفية. هذه الجداول مثالية لمهام التدقيق، وتتبع دورة حياة الكائنات، وتوليد تحليلات قائمة على الأحداث. على سبيل المثال، يمكنك استخدامها لمعرفة الكائنات التي حُذفت خلال آخر 24 ساعة، أو تحديد من يقوم بأكثر عمليات PUT، أو مراقبة تحديثات البيانات الوصفية بمرور الوقت.
يتم إنشاء جداول البيانات الوصفية لـ S3 في namespace مشابه لاسم الحاوية الخاصة بك لتسهيل الاكتشاف .تُخزن الجداول في حاويات الجداول الخاصة بـ AWS، مُجمَّعة حسب الحساب والمنطقة .عند تفعيل البيانات الوصفية لحاوية S3 للأغراض العامة، يقوم النظام بإنشاء هذه الجداول وإدارتها تلقائيًا، دون الحاجة لإدارة عمليات ضغط أو التنظيف البيانات، إذ تتولى جداول S3 مهام صيانة الجداول في الخلفية.
تساعد هذه الجداول الجديدة على تجنب انتظار اكتشاف البيانات الوصفية قبل بدء المعالجة، مما يجعلها مثالية لأعمال التحليل واسعة النطاق و التعلم الآلي (ML). من خلال الاستعلام المسبق للبيانات الوصفية، يمكنك جدولة وظائف معالجات GPU بكفاءة أكبر وتقليل وقت الخمول في البيئات كثيفة الحوسبة.
كيفية عمل البيانات الوصفية:
لنرى كيف تعمل البيانات الوصفية عمليًا، سنقوم بتكوين البيانات الوصفية لحاوية للأغراض العامة باستخدام وحدة تحكم إدارة AWS.

بعد اختيار حاوية للأغراض العامة (general purpose bucket)، نختار علامة التبويب Metadata، ثم نختار Create metadata configuration .
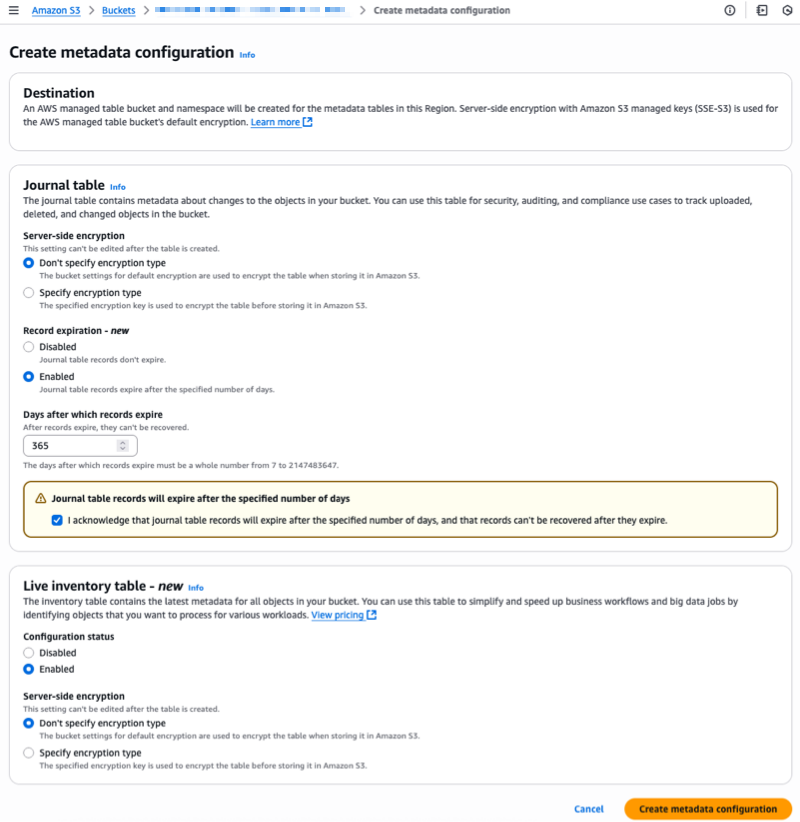
بالنسبة لـ Journal table ، يُمكننا تحديد خيارات كلٍّ من Server-side encryption و Record expiration. أما بالنسبة لـ Live Inventory table جدول الجرد المحدَّث، نختار Enabled ويمكننا تحديد خيارات Server-side encryption.
نقوم بتحديد Record expiration لجدول السجلات. تنتهي صلاحية سجلات الجدول بعد عدد محدد من الأيام، 365 يومًا (سنة واحدة) في هذا المثال.
ثم نختار Create metadata configuration.
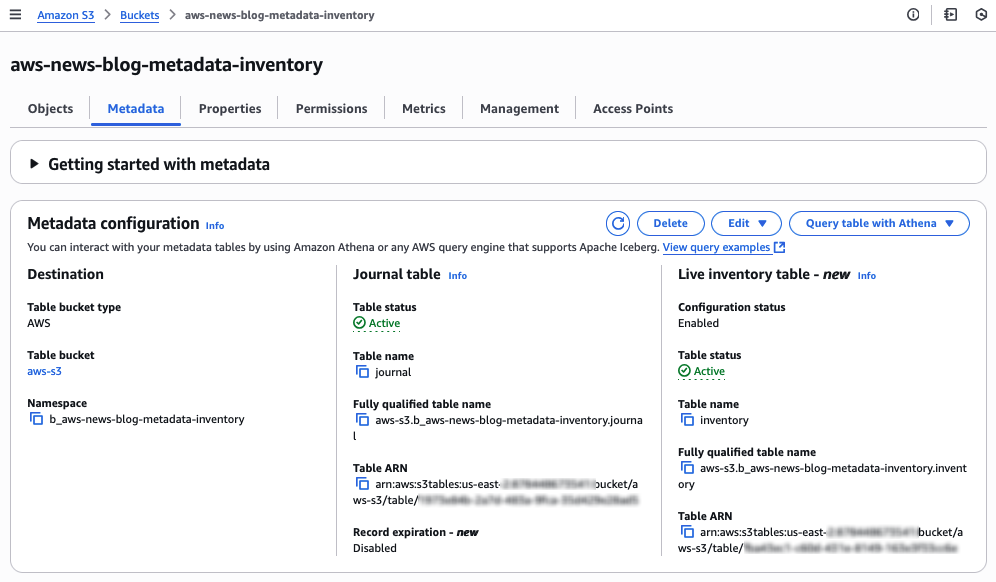
تقوم البيانات الوصفية بإنشاء جدول الجرد المحدَّث وجدول السجلات. في قسم جدول الجرد المحدَّث، يمكننا مراقبة حالة الجدول : يبدأ النظام على الفور في ملء الجدول بالبيانات الوصفية للكائنات الموجودة. قد يستغرق الأمر ما بين دقائق إلى ساعات. يعتمد الوقت الدقيق على كمية الكائنات الموجودة في حاوية S3 الخاصة بك.
أثناء الانتظار، نقوم أيضًا بتحميل وحذف الكائنات لتوليد البيانات في جدول السجلات.
ثم، ننتقل إلى Amazon Athena لبدء الاستعلام عن الجداول الجديدة.
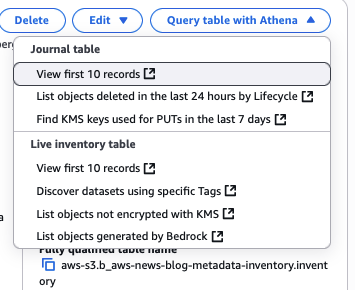
نختار Query table with Athena لبدء الاستعلام عن الجدول. يمكننا الاختيار بين عدة استعلامات افتراضية في وحدة التحكم.
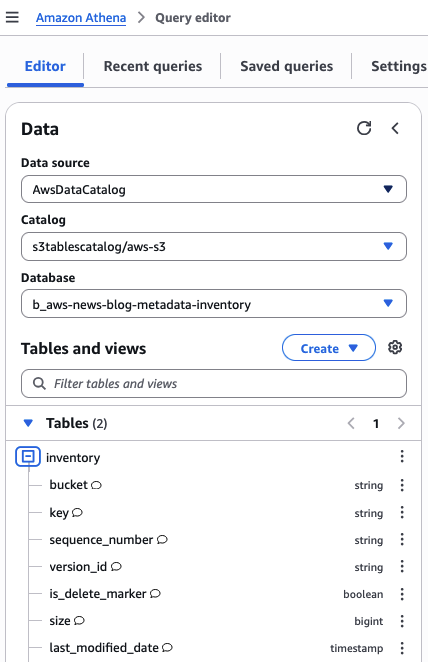
في Athena، يمكن مراقبة بنية الجداول في AWSDataCatalog Data source ويمكن البدء بالاستعلام للتحقق من عدد السجلات المتاحة في جدول السجلات. لدينا بالفعل 6,488 إدخالاً:
SELECT count(*) FROM "b_aws-news-blog-metadata-inventory"."journal";
# _col
01 6488فيما يلي بعض الاستعلامات التي يمكن تجربتها:
# Query deleted objects in last 24 hours
# Use is_delete_marker=true for versioned buckets and record_type='DELETE' otherwise
SELECT bucket, key, version_id, last_modified_date
FROM "s3tablescatalog/aws-s3"."b_aws-news-blog-metadata-inventory"."journal"
WHERE last_modified_date >= (current_date - interval '1' day) AND is_delete_marker = true;
# bucket key version_id last_modified_date is_delete_marker
1 aws-news-blog-metadata-inventory .build/index-build/arm64-apple-macosx/debug/index/store/v5/records/G0/NSURLSession.h-JET61D329FG0
2 aws-news-blog-metadata-inventory .build/index-build/arm64-apple-macosx/debug/index/store/v5/records/G5/cdefs.h-PJ21EUWKMWG5
3 aws-news-blog-metadata-inventory .build/index-build/arm64-apple-macosx/debug/index/store/v5/records/FX/buf.h-25EDY57V6ZXFX
4 aws-news-blog-metadata-inventory .build/index-build/arm64-apple-macosx/debug/index/store/v5/records/G6/NSMeasurementFormatter.h-3FN8J9CLVMYG6
5 aws-news-blog-metadata-inventory .build/index-build/arm64-apple-macosx/debug/index/store/v5/records/G8/NSXMLDocument.h-1UO2NUJK0OAG8
# Query recent PUT requests IP addresses
SELECT source_ip_address, count(source_ip_address)
FROM "s3tablescatalog/aws-s3"."b_aws-news-blog-metadata-inventory"."journal"
GROUP BY source_ip_address;
# source_ip_address _col1
1 my_laptop_IP_address 12488
# Query S3 Lifecycle expired objects in last 7 days
SELECT bucket, key, version_id, last_modified_date, record_timestamp
FROM "s3tablescatalog/aws-s3"."b_aws-news-blog-metadata-inventory"."journal"
WHERE requester = 's3.amazonaws.com' AND record_type = 'DELETE' AND record_timestamp > (current_date - interval '7' day);
(not applicable to my demo bucket)
كما نلاحظ تساعدنا النتائج في تتبع الكائنات المحددة التي تمت إزالتها، بما في ذلك تواريخها الزمنية.
الآن، لنلقي نظرة على جدول الجرد المحدَّث:
# Distribution of object tags
SELECT object_tags, count(object_tags)
FROM "s3tablescatalog/aws-s3"."b_aws-news-blog-metadata-inventory"."inventory"
GROUP BY object_tags;# object_tags _col1
1 {Source=Swift} 1
2 {Source=swift} 1
3 {} 12486
# Query storage class and size for specific tags
SELECT storage_class, count(*) as count, sum(size) / 1024 / 1024 as usage
FROM "s3tablescatalog/aws-s3"."b_aws-news-blog-metadata-inventory"."inventory"
GROUP BY object_tags['pii=true'], storage_class;
# storage_class count usage
1 STANDARD 124884 165
# Find objects with specific user defined metadata
SELECT key, last_modified_date, user_metadata
FROM "s3tablescatalog/aws-s3"."b_aws-news-blog-metadata-inventory"."inventory"
WHERE cardinality(user_metadata) > 0 ORDER BY last_modified_date DESC;
(not applicable to my demo bucket)
هذه مجرد أمثلة قليلة لما هو ممكن مع البيانات الوصفية لـ S3. تعتمد استعلاماتك على حالات الاستخدام الخاصة بك. راجع تحليل البيانات الوصفية لـ Amazon S3 باستخدام Amazon Athena و Amazon QuickSight في مدونة تخزين AWS لمزيد من الأمثلة.
الأسعار والتوافر:
جداول الجرد المحدَّثة والسجلات للبيانات الوصفية متاحة اليوم في مناطق شرق الولايات المتحدة (أوهايو، فيرجينيا الشمالية) وغرب الولايات المتحدة (كاليفورنيا الشمالية)
يتم تحصيل رسوم على جداول السجلات بقيمة 0.30 دولار لكل مليون تحديث. هذا تخفيض بنسبة 33 بالمائة عن سعرنا السابق.
بالنسبة لجداول الجرد، هناك تكلفة ملء خلفي لمرة واحدة قدرها 0.30 دولار لكل مليون كائن لإعداد الجدول وإنشاء بيانات وصفية للكائنات الموجودة. لا توجد تكاليف إضافية إذا كانت الحاوية الخاصة بك تحتوي على أقل من مليار كائن. بالنسبة للحاويات التي تحتوي على أكثر من مليار كائن، هناك رسوم شهرية قدرها 0.10 دولار لكل مليون كائن شهريًا.
كالمعتاد، تحتوي صفحة تسعير Amazon S3 على جميع التفاصيل.
مع جداول الجرد المحدَّثة والسجلات للبيانات الوصفية، يمكنك تقليل الوقت والجهد المطلوبين لاستكشاف وإدارة مجموعات البيانات الكبيرة. تحصل على عرض محدث لتخزينك وسجل للتغييرات، وكلاهما متاح كجداول Iceberg يمكنك الاستعلام عنها عند الطلب. يمكنك اكتشاف البيانات بشكل أسرع، وتعزيز سير عمل الامتثال، وتحسين مسارات تعلم الآلة الخاصة بك.
يمكنك البدء عن طريق تفعيل البيانات الوصفية على الحاوية S3 الخاصة بك من خلال وحدة تحكم AWS، أو واجهة سطر أوامر AWS (AWS CLI) ، أو مجموعات تطوير برمجيات AWS. عند تفعيلها، يتم إنشاء وتحديث جداول السجلات والجرد المحدَّث تلقائيًا. لمعرفة المزيد، قم بزيارة صفحة البيانات الوصفية لـ S3.