AWS in Switzerland and Austria (Alps)
How Nexthink Builds Enterprise AI Agents Using Fine-Tuned LLMs with Amazon SageMaker
AI agents powered by large language models (LLMs) are reshaping enterprise software by turning complex tasks into conversational experiences. Instead of requiring deep expertise, users can now interact with systems in natural language and get immediate, actionable answers. But delivering this simplicity at enterprise scale is hard: AI agents must be accurate, specialized, and deeply aligned with domain logic.
In this post, we share Nexthink’s journey in fine-tuning LLMs on Amazon SageMaker to power their AI agents and make advanced capabilities accessible to every user.
Democratizing DEX Insights
Nexthink, a Swiss Software company is a pioneering leader in digital employee experience (DEX). With a mission to empower IT teams and elevate workplace productivity, Nexthink’s Infinity platform offers real-time visibility into end user environments, actionable insights, and robust automation capabilities. By combining real-time analytics, proactive monitoring, and intelligent automation, Infinity enables organizations to deliver an optimal digital workspace.
Nexthink’s platform has been traditionally reserved for expert IT power users, but demand is growing across the organization: other IT teams, HR and even employees want the same level of insights.
Nexthink offers advanced analytical capabilities including a specialized query language called Nexthink Query Language (NQL) to retrieve information for analyzing complex IT issues. While powerful, these capabilities create a barrier for non-technical users.
The emergence of LLMs and AI agents creates the ideal opportunity to finally democratize DEX insights and make them accessible to everyone, not just specialists.
From Prompt Engineering to Fine-Tuning
Nexthink Assist is an AI agent that acts as a DEX advisor, allowing users to ask questions in plain language and get answers instantly, without expertise.
This capability is a powered by a tool called NL2NQL, responsible for translating natural language questions into precise NQL queries.
Early versions of NL2NQL relied solely on prompt engineering. This approach involves carefully crafting instructions to guide the LLM’s behavior. While prompt engineering can yield good results for simple tasks, it often falls short when dealing with specialized domain languages or complex business logic.
The team then adopted Retrieval Augmented Generation (RAG) which improved accuracy by providing relevant documentation and examples during inference.
Using Amazon OpenSearch vector database, the system leverages the most relevant examples and documentation during the retrieval phase and injects them into the prompt to guide the model’s output during generation. This significantly improved results, but performance remained inconsistent for complex queries.
Fine-tuning became the natural next step. Unlike prompt engineering or RAG, fine-tuning embeds domain knowledge directly into the model by updating its weights. This approach led to higher accuracy (+30%), more consistent outputs, lower token usage (-80%) and inference costs, as well as better handling of edge cases. The trade-off is increased complexity: fine-tuning requires substantial compute, high-quality datasets, and dedicated engineering effort.
How Nexthink Evaluated and Fine-tuned Tools for Their AI Agents
To develop and evaluate NL2NQL, Nexthink built a golden dataset: a curated benchmark of user questions paired with their corresponding NQL queries. This dataset serves as reference point for accuracy evaluation and regression testing within Amazon SageMaker’s comprehensive evaluation framework.
Nexthink’s annotation journey began with a clever mathematical insight: leveraging the inverse problem principle from optimization theory. Instead of translating questions to NQL queries, they reversed the process—providing employees and interns with real anonymized NQL queries and asking them to write corresponding natural language questions. This inverse approach significantly reduced cognitive load and increased annotation speed.
Nexthink used Amazon SageMaker Ground Truth to create a structured annotation workflow, enabling them to distribute tasks across their internal workforce, track progress, and maintain quality control measures.
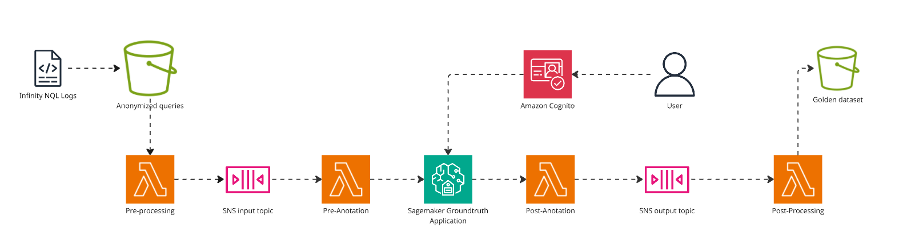
Figure 1: Architecture diagram showing Nexthink’s data labeling pipeline: anonymized queries stored in S3 trigger a Lambda function for pre-processing, flow through SQS to Amazon SageMaker Ground Truth for SSO-authenticated labeling and are stored in standardized format in S3 for LLM fine-tuning.
The architecture in Figure 1 shows how Nexthink stored anonymized queries in an S3 bucket, with each new addition triggering a pre-processing Lambda function that cleaned and prepared them before sending them into an SQS queue. From there, the tasks flowed into Amazon SageMaker Ground Truth, which provided a web interface where labelers could log in through SSO and perform their labeling work. Once labelled, the queries were stored in a dedicated S3 bucket in a standardized format, ready to be fed into the LLM fine-tuning pipeline.
However, as the workloads increased, Nexthink encountered significant challenges with inconsistency in labeling and lack of scalability. Unlike images, where objects are visually concrete, queries are open to interpretation. Two annotators might read the same query and infer different user intents, introducing noise that makes it harder for models to converge. Additionally, human annotation doesn’t scale easily with the growing need for labeled data. Accelerating the process typically means hiring and training more annotators, which quickly becomes expensive, slow, and logistically complex.
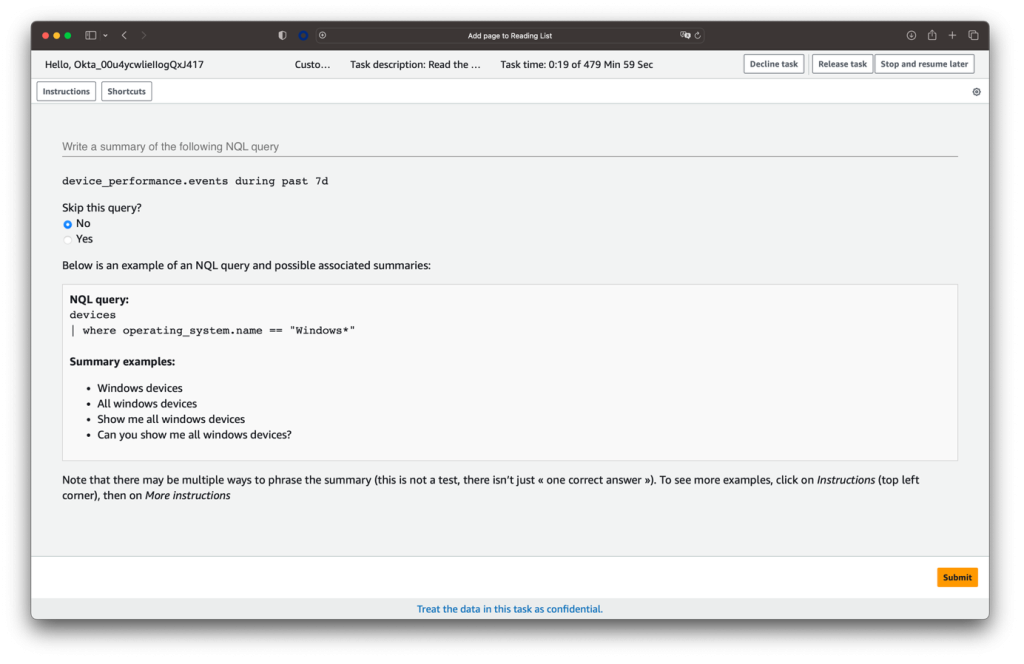
Figure 2: Screenshot of Amazon SageMaker Ground Truth labeling interface where annotators summarize NQL (Nexthink Query Language) queries, showing an example task to summarize “device_performance.events during past 7d” with sample summaries and instructions.
These limitations taught Nexthink that comprehensive annotation guidelines, clear quality assurance processes, and eventually scaling beyond their internal team were essential.
Scaling Annotation with LLM-as-a-Judge
As Nexthink Assist gained popularity, users demanded broader coverage of their data model to address a growing range of use cases. This required moving beyond manual annotation to an automated solution. The team implemented a new labeling pipeline where an LLM—specifically Anthropic Claude 3.5 Sonnet running on Amazon Bedrock—now generates the labels automatically.
They evolved their initial labeling pipeline by adding an LLM component: Anthropic Claude 3.5 Sonnet running on Amazon Bedrock. The prompt included relevant information for the task (key elements of NQL documentation and the Nexthink data model) to understand the details of each query.
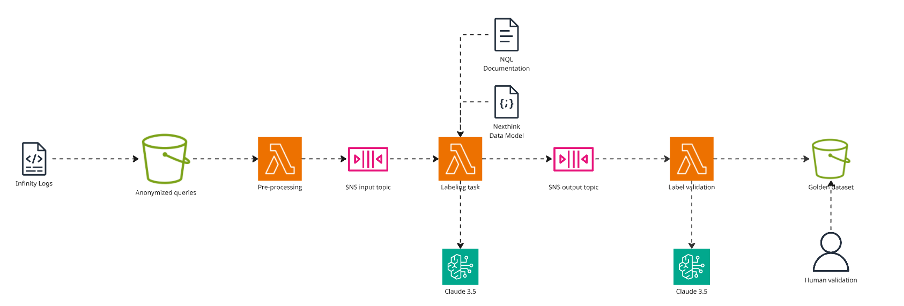
Figure 3: Architecture diagram of Nexthink’s LLM-as-judge evaluation workflow: NQL queries flow from S3 through Lambda pre-processing and SQS input queue to Lambda functions that leverage Claude 3.5 Sonnet (with NQL documentation and example data/code references) for annotation, then through SQS output queue to final Lambda processing for automated evaluation, and S3 storage for the labeled dataset. Human intervention is only used for sample validation.
Before adding labeled samples to their golden dataset, they submitted them to Claude 3.5 with a different role: not labeling but criticizing. The LLM acted as a judge, verifying that the LLM-generated label matched the query exactly; if there was doubt, the sample was discarded. Research shows that LLM-as-a-judge achieves over 80% agreement with human evaluators, matching the agreement rate between humans themselves.
To safeguard against quality drift, Nexthink still had human experts periodically review samples of LLM-labeled queries.
While this approach allowed to gain in speed and consistency, Nexthink observed some challenges with conflicting instructions and limited diversity. Prompts impose constraints that cannot always be satisfied. For instance, they asked for concise questions, but some complex queries could not be concisely translated without losing information. Even with a non-zero temperature, LLM phrasing lacked diversity, resulting in labels that looked too similar. To mirror the diversity of real users, they started injecting persona-based prompting such as writing questions as detailed inquiries or as web search queries to generate more diverse and human-like expressions.
Fine-Tuning at Scale with Amazon SageMaker AI
Despite the good results with Claude 3.5 Sonnet for labeling and judging, Nexthink faced important challenges that forced them to try a different approach. The prompt-based method worked well for creating labels but couldn’t handle their main business need: turning natural language directly into NQL queries with high accuracy at scale. The team struggled with complex prompts, high costs from token usage, and slow response times when working with Nexthink’s full data model. These problems showed that using just a general-purpose LLM with prompts wouldn’t be fast, effective, or affordable enough for real-world use.
This situation led them to fine-tune their own specialized model—one that would work specifically with Nexthink’s unique data and query language. Instead of continuing to use prompts with a general LLM, they needed a model that already understood their data structures without needing extensive explanations in each prompt.
Amazon SageMaker AI provided the infrastructure and tools needed to fine-tune LLMs efficiently. Nexthink leveraged SageMaker’s capabilities to build their AI-powered query assistant.
The team used SageMaker’s distributed training capabilities to fine-tune a 7 billion parameter LLama LLM, incorporating advanced techniques like Low Rank Adaptation (LoRA). SageMaker’s managed infrastructure allowed Nexthink to focus on model quality rather than DevOps. They could experiment with different training approaches and quickly iterate based on results.
Key components of their SageMaker implementation included the native distributed training libraries, training job management, model deployment and model monitoring.
The main driver behind this approach was the need for a highly specialized, efficient solution that could understand Nexthink’s complex query language without extensive prompting. This strategic decision paid off significantly: the results after fine-tuning were impressive: a 30% improvement in query accuracy, 80% reduction in token usage, and comprehensive support across their entire data model.
Best Practices for Enterprise Fine-Tuning
Nexthink journey surfaced several best practices for organizations fine-tuning LLMs.
Data quality remains critical: fine-tuning only works with clean, representative datasets, and upfront curation directly translates into better performance. Fine-tuned models must also be regularly updated as requirements evolve.
Starting small and iterating helps control cost and risk. Begin with simpler tasks and smaller models, then scale complexity as the fine-tuning pipeline matures.
Strong evaluation metrics associated with a high-quality dataset are essential for progress. Metrics should reflect both technical accuracy but most importantly business requirements to bring value to the customers and drive adoption.
From Queries to Conversations: The Future of Enterprise AI is Here
Nexthink’s journey demonstrates the transformative potential of fine-tuned LLMs in enterprise environments. By leveraging Amazon SageMaker’s powerful infrastructure, they successfully evolved from prompt engineering to sophisticated fine-tuning techniques that dramatically improved performance while reducing costs. The results speak for themselves: 30% better query accuracy, 80% lower token usage, and comprehensive support across their entire data model—all directly translating to a superior user experience.
What makes Nexthink’s approach particularly valuable is their systematic progression through different AI implementation stages, carefully evaluating the trade-offs at each step. Their experience shows that while general-purpose LLMs offer a starting point, true enterprise-grade AI requires domain-specific optimization that embeds specialized knowledge directly into the model architecture.
The democratization of complex IT insights through conversational AI represents more than just a technical achievement—it’s a fundamental shift in how organizations can leverage their data, extending powerful capabilities beyond specialists to everyone who needs them. This approach doesn’t just improve efficiency; it creates entirely new possibilities for how employees across departments interact with enterprise systems.
Take Action: Begin Your Enterprise AI Journey
Ready to transform your own enterprise applications with fine-tuned AI capabilities? Explore these AWS resources to get started:
- Explore Amazon SageMaker JumpStart – Access pre-trained foundation models and fine-tuning capabilities through the SageMaker documentation.
- Watch SageMaker fine-tuning tutorials – Access step-by-step video tutorials on AWS’s YouTube channel.
- Join the AWS Machine Learning community – Connect with experts and peers on the AWS Machine Learning blog for the latest best practices and customer stories.
The future of enterprise software is conversational, intuitive, and accessible to everyone. By following Nexthink’s example and leveraging the power of Amazon SageMaker, you can lead this transformation in your own organization—turning complex systems into natural conversations that drive productivity and innovation.