AWS Partner Network (APN) Blog
Building a Visual Quality Control Solution with Amazon Lookout for Vision and Advanced Video Preprocessing
By Oleg Smirnov, Data Scientist – Grid Dynamics
By Naresh Rajendra Shah, Sr. Data Scientist – Grid Dynamics
By Marko Nikolic, Staff Data Scientist – Grid Dynamics
By Ilya Katsov, VP of Technology – Grid Dynamics
 |
| Grid Dynamics |
 |
Conveyor belts are an essential material handling tool for various industrial processes, and one of the most effective ways to quickly and continuously transport large amounts of materials or products.
However, high throughput rates make it difficult for operators to detect defective products and remove them from the production line, especially in cases when several products are aligned on vertical sections of the belt. These challenges necessitate automatic anomaly detection tools that can track products on conveyors without interrupting processes.
Amazon Lookout for Vision is a machine learning (ML) service for detecting anomalies in images. This is a convenient AutoML service, but it often requires the development of custom video stream preprocessors to integrate the service for use in real-world scenarios, as well as the preparation of labeled datasets to train the anomaly detection model.
In this post, we demonstrate how to build an advanced video preprocessor and integrate it with Amazon Lookout for Vision, using a food processing use case as an example.
We also address the problem of data collection and labeling, which can be challenging in the development of a computer vision solution, and we demonstrate how the useful data can be collected and tracked across the video stream. This is helpful in a variety of scenarios and enables visual quality control without disrupting the production line.
This prototype is based on real-world experience Grid Dynamics has building visual quality control solutions for manufacturing clients. Grid Dynamics develops and maintains a large collection of prototypes for various enterprise artificial intelligence (AI) use cases that helps design and deliver innovative solutions more efficiently.
An engineering services company focused on delivering transformative, mission-critical cloud solutions, Grid Dynamics is an AWS Advanced Tier Services Partner with Competencies in DevOps and Data and Analytics.
Solution Overview
To illustrate the use cases we’re talking about in this post, a few videos of food production lines are presented below.
Confection

Tomatoes

Eggs

Bakery

To develop a full-fledged visual quality control solution, we start by taking a simple video stream of lots of items moving on a conveyor belt, and then build a simple non-machine learning-based bounding box detection around these objects of interest, thereby localizing the objects.
We then use the detected bounding boxes and extract the cropped objects in order to send them to the annotation service and/or the model prediction part of Amazon Lookout for Vision.
Next, to be able to track the exact number of objects and identify the defective objects in the video, we use a non-ML-based tracking algorithm to track and number the products, both defective and non-defective. This enables us to identify the source of the cropped objects from the video in the images.
This approach minimizes the friction that data scientists face when labeling objects in a complex, disorderly scenario, and reduces the amount of time spent annotating simple labels (anomaly or no anomaly) for the dataset. In addition, this methodology provides a continuous estimate of localization of the defect/defective product in the continuous stream of video.
Once the images are extracted and annotated, we can further augment the data using a variety of techniques to simulate scenarios common to manufacturing, and improve the already collected and cropped dataset derived from the video.
This entire process allows even a small amount of video data to be sufficient to train a robust deep learning model using the services of Lookout for Vision, and makes human intervention in the training process painless and quick.
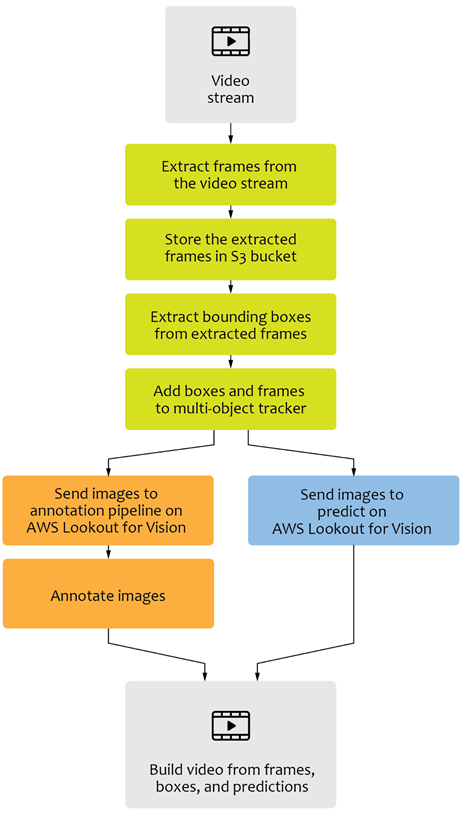
Figure 1 – Conceptual solution workflow.
The minimal AWS environment that implements this workflow can be as follows:
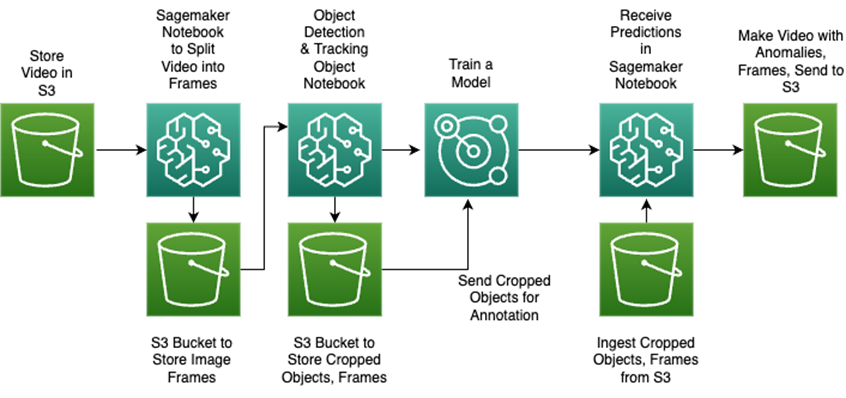
Figure 2 – Data flow in the solution prototype.
We’ll implement this minimal environment in the next sections to create a solution prototype. A fully-fledged production solution is usually more complex and can involve components related to monitoring, administration, and process automation.
An example architecture of a more realistic solution is shown below and was adapted from this AWS blog post.
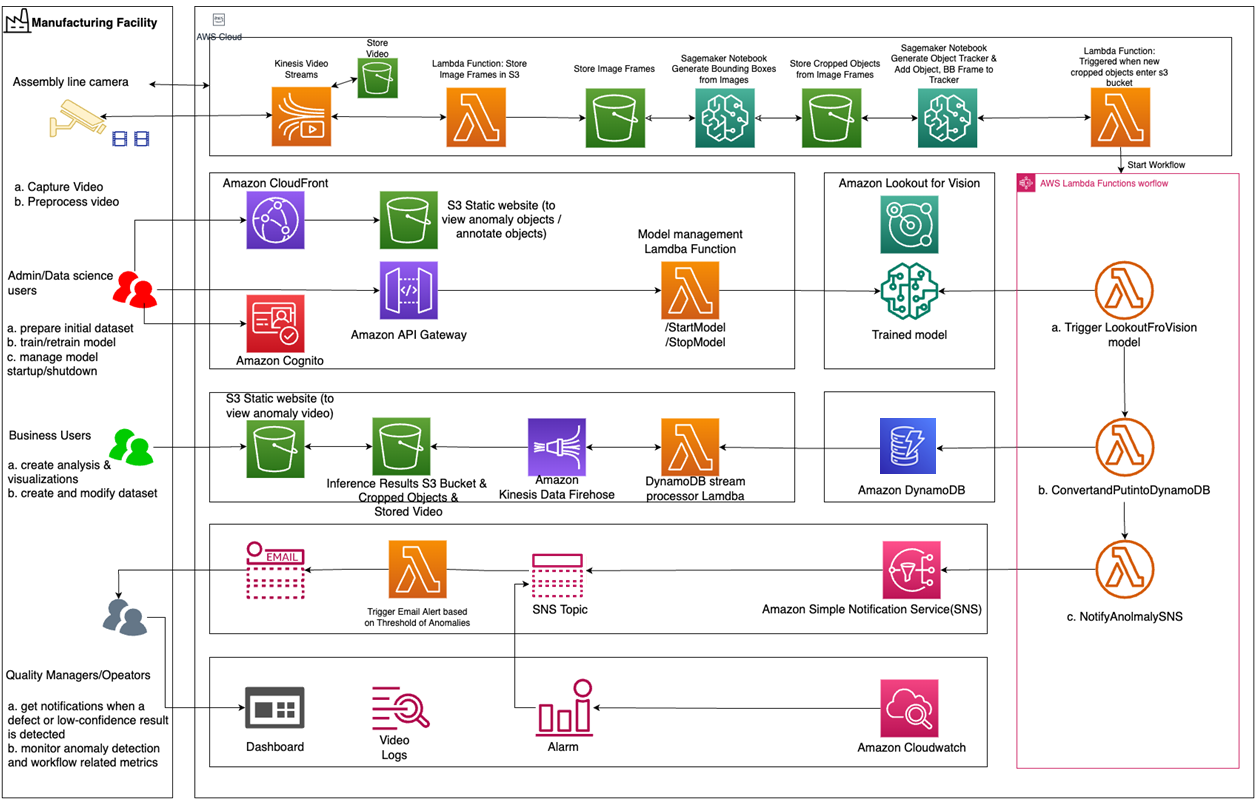
Figure 3 – Example of a complete solution for visual quality control.
Dataset Overview
To implement the prototype, we created an example video with chocolate cookies moving on a conveyor belt.

We have two types of anomalies in this video:
- Broken cookies (in yellow frames in the example below).
- Several cookies stacked on top of each other (in blue frames in the example below).

Note that some anomalies intersect.
We created 66 seconds of this example video, with ~200 objects in total. We split the video in two parts of 36 and 30 seconds. The first part was used for training and hyperparameter tuning purposes, and the second part was used for testing to evaluate the final quality of the solution.
Preprocessing Pipeline
In this section, we develop the image preprocessing part of the pipeline to detect individual cookies in individual video frames. The reference implementation for the entire pipeline is available in this notebook.
Object Detection
For our task, and many similar tasks involving objects on a conveyor belt, even simple object detection methods can produce very accurate results. Usually, all objects are very different from the “belt” (background) itself in terms of color and brightness. This means simple color thresholding (which is similar to the chroma key technique) can accurately find all object masks.
In this case, using classical computer vision algorithms, it’s easy to extract the contours of individual objects or their bounding boxes from the obtained masks. We used built-in functions from the OpenCV library for this purpose, but there are many other alternatives.


Unfortunately, it doesn’t work perfectly in our scenario for a few reasons:
- Some of the objects touch each other (shown in red), and are recognized as a single object using a counter detecting algorithm.
- Object shadows may also be selected by the mask because their color gamma is closer to the object than the background.
Both of these issues are solved by adding a few processing steps to the algorithm. There are many simple non-ML-based approaches that can be used to solve these issues. We added shadow and edge mask detection and subtracted these masks from the object’s mask.
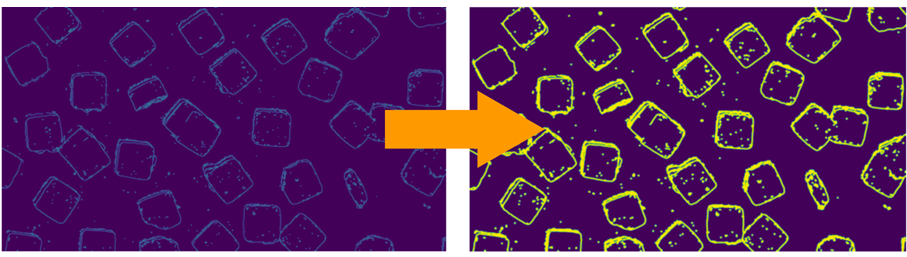
For edge detection, a classical computer vision algorithm can be used, such as Canny edge detection. As illustrated below, shadows can be extracted using simple color thresholding.


All of these steps require some hyperparameter tuning; for example, selecting proper threshold constants. This tuning should be based on the dataset images, and can be done manually or using hyperparameter tuning techniques such as grid search, as shown below:


We also used morphological transformations, such as erosion and dilation, to enlarge or smooth masks, and to reduce the effect of noise and algorithm inaccuracies on the result.
Object Tracking
As a next step, we use an object tracking algorithm to connect the same objects between different frames. There are many different classical object tracking algorithms that differ according to tracking accuracy and frame-per-second (FPS) throughput, and most of the basic ones have their own limitations.
The main limitation is the fact the simplest algorithms can track only a single object, and we need to track dozens of them. In order to overcome this limitation, we implemented a higher-level tracking algorithm, which utilizes the capabilities of simple classical trackers and is able to work with multiple objects.
The algorithm addresses the following features of the video for our use-case scenario:
- Each frame contains a lot of different objects.
- New objects appear during the video.
- Objects are only partially visible at the moment they enter the frame, but most of them become fully visible in later frames.
The idea is to use the object detection algorithm to initialize bounding boxes for the new objects, and then track them using a new instance of a basic tracker. The fact that an object cannot jump arbitrarily between frames is used to distinguish if the detected object is a new instance or an old one, and for that we implemented a distance threshold between object centroids.
In the case of partially visible objects entering the frame, we enable the replacement of a bounding box with a larger box as the object moves along the conveyor belt in subsequent frames.
This approach is illustrated in the example below. Note the blue objects have entered the frame recently, so the boxes could increase. For example, the box for object 4 was increased between frames.


Although both detection and tracking algorithms are quite simple, and therefore relatively fast, native application of them to each frame is not suitable for real-time processing. Therefore, we used a few optimizations techniques, including:
- Detection algorithm:
- New objects do not appear in every frame, so we can use the detection algorithm once every X frames (where X depends on the video frame rate, the “conveyor belt” speed, and the desired speed of recognition of new objects). For example, we used X = 20.
- New objects cannot appear in an arbitrary place. In our case, they always enter the frame on the left side of the frame. So, we use the object detection algorithm only for the leftmost part of the frame, effectively reducing the image size for detection.
- Tracking algorithm:
- Tracking algorithms work quite well even with low-resolution frames. Therefore, we apply tracking for downscaled frames. We used downscaling with ratio R = 0.4 for more than 2x FPS throughput increase.
Training Amazon Lookout for Vision
In order to use the Amazon Lookout for Vision service, we first needed to train the models for our particular use case. This step is simple and doesn’t require much machine learning knowledge; the only thing you need is to create a good dataset. Once you prepare a dataset, the rest is done by pressing a single button.
The dataset should contain examples of normal and anomalous images. In the documentation, it’s stated you need at least 20 examples of normal objects and at least 10 examples of anomalous ones. The number of example images directly affects the model’s quality (within reasonable limits), so the more samples you have the more accurate the models will be.
In our scenario, we used images of individual objects for anomaly classification. To get the images of individual objects, we used our object detection pipeline. As a result, we had a set of numbered objects, each of them with bounding boxes from different frames. We then manually created “normal” or “anomalous” labels for every object.
Lookout for Vision models work only with fixed-size images, so after cropping bounding boxes, we rescaled all images to the same square size (384×384) and padded them where required.

Additionally, it’s important not to use the same object for training and testing the model. When this happens, we encounter “data leak” where the model simply memorizes the anomalous objects in the training dataset instead of learning general patterns.
This results in a high score on the training test, which means the model will continue overfitting to train samples and will not work properly for unseen examples during its usage later.
Further, Lookout for Vision has two options for train/test split:
- You can upload two separate datasets by yourself.
- Or, it splits your dataset into train and test parts randomly after uploading the single general dataset.
In the second case, it’s not recommended to have two different images of the same object because they could fall into different splits and cause the aforementioned issue. In the first case, it’s possible to use multiple images of the same object, but you need to make sure all of them fall into the same split (either train or test).
Results
The pipeline described in the previous sections enables the continuous detection and count of anomalies in the video stream.

We measured the quality of our solution for two parts separately:
- Object detection and object tracking
- Anomaly detection
For object detection, we used precision, recall, and f1 score as the main metrics. These metrics are better suited to our use case because they evaluate object detection only, even if the “predicted” (found by the algorithm) bounding box is slightly different in size to the true one. They also don’t take into account the area of intersection of predicted and true boxes.
For our holdout test video, containing 96 objects, there were no false positive bounding boxes found, but in two cases a bounding box joined two objects into one. In real-life scenarios, this problem can be mitigated with better lighting, different camera positions, or tracking with multiple cameras.
Nevertheless, the results of the model were:
- precision of 1
- recall of ~0.98
- f1 ~0.99
For anomaly detection, Lookout for Vision automatically calculates metrics on the test part of the dataset. Results were:
- ~93% precision
- ~76% recall
- 83% f1 score

Figure 4 – Model performance metrics.
It’s important to note here that we had a limited number of objects because of our artificial demo example video. Our training dataset contained about 60 different objects, of which only 20 were anomalous. In a real-life scenario, we would have much longer videos and the ability to iteratively increase the dataset to improve the model until it reaches the required quality.
The model training process is usually continuous and could take weeks or months. With Amazon Lookout for Vision, we were able to get reasonable quality after the very first training run, which took ~1 hour, even with a very small dataset.
Key Learnings
To summarize, our methodology has several advantages:
- The effort required by data scientists to annotate the data is significantly minimized by providing soft bounding boxes around the objects of interest. This is a great starting point for labeling tasks since it directly brings into focus the object of interest for labeling tasks.
- Objects are tracked so data scientists can clearly identify the object’s localization with respect to the video. This information can also be handy for root cause analysis down the line.
- Tracking the objects and generating object IDs enables businesses to see the number of normal and anomalous objects that have passed through a cross-section in a given time period. This gives them a bird’s eye view of how well the process is working.
As noted, this methodology does not work directly off the bat, and in order to implement this approach you need to consider the following:
- Some amount of effort and hyperparameter tuning will be required in order to automatically localize the objects and draw bounding boxes.
- In the case of a noisy background, different techniques for foreground extraction/background removal are required.
- In cases of complex objects with multi-color features or transparent features (for example, bottles/chips), the simple threshold-based morphological operations will need to be used with a lot more care and delicacy in order to avoid morphing the internal object features.
Conclusion
In this post, we described a typical end-to-end methodology for implementing anomaly detection technologies into a live video stream using smart, non-machine learning-based preprocessing pipelines and techniques.
This post covers in detail a few standard computer vision techniques, such as morphological operations, object detection, and object tracking without ML, and shows how they can be leveraged for model building on Amazon Lookout for Vision.
Finally, we described the functions and techniques that are used to pull together all of this information and re-encode it into the video stream for a clean video that shows the detected anomalies, their position and their count.
As a further step, the proposed solution could be advanced by improving the data quality prior to model building, and the amount of data required to train a good model could be minimized using active learning methodologies.
Special thanks to Kavita Mahajan, Sr. Partner Solutions Architect – AWS
.

.
Grid Dynamics – AWS Partner Spotlight
Grid Dynamics is an AWS Advanced Tier Services Partner and engineering services company known for transformative cloud solutions.