AWS Partner Network (APN) Blog
Creating an Asynchronous Ingestion Pattern Following Mia-Platform Fast Data Architecture
By Luca Mezzalira, Principal Solutions Architect – AWS
By Michel Murabito, Developer Advocate – Mia-Platform
By Paolo Martinoli, Technical Writer – Mia-Platform
 |
| Mia-Platform |
 |
Data is fundamental for every company. It gives insight into factors affecting the company and enables strategic business decision making. Nowadays, there is the possibility to use internal data to get very useful insights on a company’s performance. Also, data can be enriched with external sources for providing new opportunities for both organizations and customers.
Enterprise companies have data scattered across multiple systems—sometimes on premise, sometimes in third-party systems. Often, data is siloed in these systems. When an organization decides to ingest this data into greenfield projects, the implementation results in several ad-hoc workloads that require effort and manual processes.
Mia-Platform is an AWS Partner and Italian tech company delivering a leading solution for the creation of end-to-end cloud-native digital platforms. Mia-Platform is built by developers for developers and designed to streamline the development cycle of microservices on Kubernetes environments.
Leveraging Amazon Simple Storage Service (Amazon S3), Amazon Simple Queue Service (Amazon SQS), Amazon Elastic Container Service (Amazon ECS), and Amazon Route 53, Mia-Platform relies on the robustness and security of Amazon Web Services (AWS) to easily install its innovative digital platform on customers’ systems.
In this post, we discuss an asynchronous pattern for ingesting data from legacy systems, collecting it into projections, and aggregating it into single views. The purpose of this solution is to decouple the source systems where data is stored from the external channels that request data. This ensures both offloading of source systems and makes data available to channels 24/7 and in near real-time.
The proposed solution is a simplification of the high-end architecture of Mia-Platform Fast Data. This kind of system is usually very complex, especially if it is designed to offer excellent scalability and high performance, while guaranteeing consistency on millions or billions of daily events.
In scenarios where flexibility and scalability are required, event-based async communication systems are recommended. There are several reasons for this, but for the purpose of this post, we will focus only on key aspects of the pattern we are going to design.
Solution Overview
The first key feature of Mia-Platform Fast Data is that the source systems, such as CRM or ERP—also called system of records (SOR)—involved in this kind of architecture do not have to wait for processing confirmation after sending the data. The great advantage is a shorter processing time that isn’t dependent on the system that will receive the message.
In traditional synchronous communication, the SOR waits for the response of processing. During high traffic, the system can consume computational resources for undefined periods of time. The resources consumed just waiting for the response to a request cannot be dedicated to actually processing the response to other requests, so it is a waste of resources.
The SOR becomes responsible only for sending the data to a single system, which is usually a real-time streaming data pipeline (or queue), like Amazon SQS. From that point, the SOR is completely decoupled from the clients, so it will not need to know who will actually receive the data, nor how and when it will be processed.
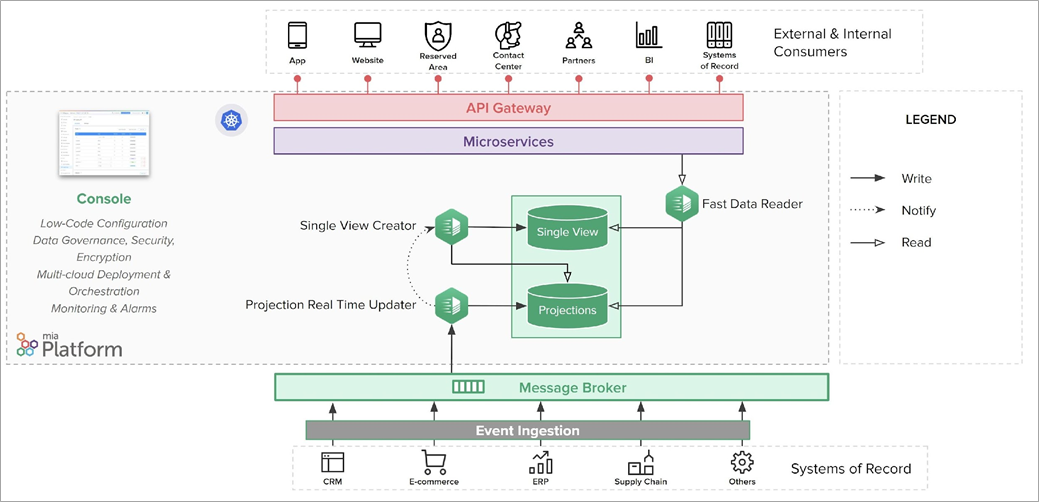
Figure 1 – Final architecture.
Decoupling leads to another advantage: allowing the queue to manage analytics, monitoring, and notifications on transiting data in a completely transparent way and at zero cost to the SOR. If a new SOR needs to be connected, the process will not in any way affect the set of systems already connected. No action on the previously connected systems is required.
The receiving system can be configured to scale and guarantee high reliability, in order to be available and effectively react to traffic peaks. Going through a queue potentially makes this process more time-consuming. Nevertheless, even with a slightly higher total processing time compared to the synchronous processing, the reliability ensured by adopting a queue is a great advantage when high stress occurs.
The time of direct elaboration has a linear growth and it can generate errors and downtimes, in cases of non-manageable peaks. Through this system, the time of elaboration can be constant, since it is possible to scale horizontally both the queue and the consumer.
SORs can be very heterogeneous and data extraction methods can vary depending on several factors, like the file formats or the extraction speed. Agents capable of reading data are often required. It is important to have tested and reliable agents to manage heterogeneous systems. Agents can work in different ways; for example, they can be small applications installed on the server or external systems that read data.
Data collected by SORs is sent to a specific topic available in the queue. Let’s take, for instance, a CRM from which extract registries of personal data. The registries can be read by an agent and sent to a topic called crm.anagrafica. In this kind of iteration, agents can be addressed as event-producers on the queue.

Figure 2 – Ingestion process.
The messages are now in the queue and data is waiting to be processed by the system. The time spent in the queue depends on many factors, but the most relevant one is the number of consumers that can process the data. Both the queue and the consumers can scale horizontally, using systems like Amazon SQS and Amazon ECS, allowing you to handle virtually any workload.
In this case, the consumer is a microservice that ingests and processes the data from the queue. This microservice is called Projection Real-Time Updater. During this ingestion phase, the processing verifies that data is compliant to a pre-defined pattern.
If data is different from the pattern, the processing parses it to make it adhere to the pattern. A typical parsing could be to uniform date formats, which can be different from each other according to the SOR of origin. Since data formats can be very heterogeneous, adopting functions that are ready to use, tested, and reliable can speed up the development, making it more trustworthy.
Once the ingestion phase is finished, the Projection Real-Time Updater takes care of persistently writing data to an architectural object called data projection (or simply projection). The projection is saved in the new database and can contain data that is slightly different from the original source; for example, some fields of a table can be omitted. Usually, it is recommended to translate data in its entirety.
When writing data on a projection, there are two different scenarios:
- Data is not existing in the system, so it is entirely written in a new document inside a projection.
- Data is already existing in the system. In this case, you can choose to replace the entire document or only the updated parts.
This process refers to a regular situation of a system in production, where most of the data is already in the system. When booting the system, instead, consider the amount of data already existing on the SORs, because it could be so huge as to make the integration impossible or very expensive in terms of resources. Relying on a ready-made tool can help avoid such problems.
Reading Data from Projections
Data is replicated on a new database: through specific queries, it can be easily read by its ID or perform searches. Now, to effectively decouple the system of records from the database, your clients have to point to the data in the projection.
This allows external channels to get the data without insisting on the legacy system. The new database also ensures greater efficiency, thanks to the use of new scalable and highly reliable technologies. Since creating and exposing endpoints can be long and repetitive, it can be helpful to adopt tools that automate this task.
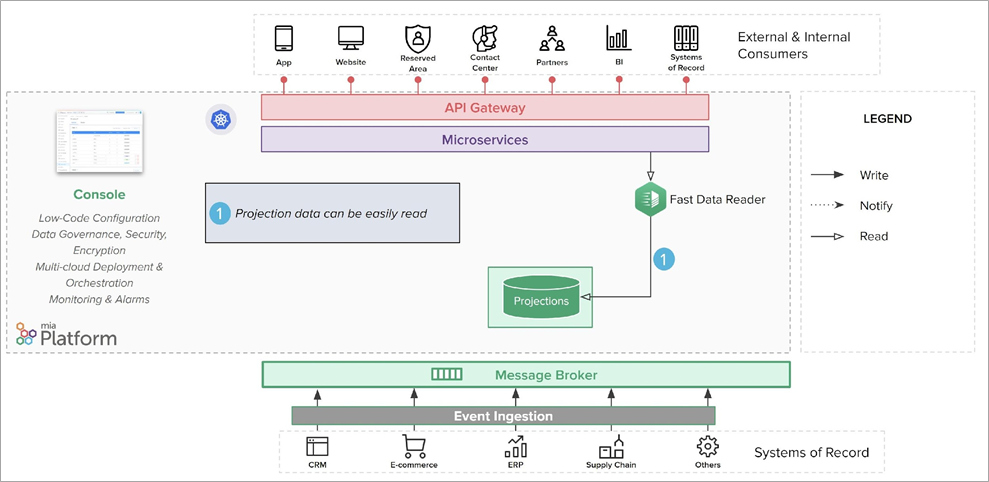
Figure 3 – Reading data from the new database.
Now, data from the SORs is replicated on the projections and the systems of records are effectively decoupled from the ability to read them. In this manner, the system can handle peak requests that would not be managed by the SORs. If one or more SORs are offline (due to scheduled maintenance or unexpected downtime), the system is still able to manage incoming requests.
The Projection Real-Time Updater can notify other microservices of the data that has been changed, with the goal of enabling the creation of single views. A single view is an aggregation of data from multiple SORs and different entities available to any clients that will request it.
To prevent data inconsistency, particular attention should be paid to avoid a race condition—which occurs when two or more threads access shared data at the same time.

Figure 4 – Notifying other services when data changes.
Creating Single Views
Single View Creator is the microservice responsible for creating the single view that receives the modified entity as input.
It can receive the ID of the aggregate entities affected by the change. For instance, the address associated with a registry has changed. The data of the new address is provided to the Single View Creator, which gets the corresponding registry ID from the data.
Thanks to a low code approach, you can speed up the process and avoid mistakes. In fact, configurations help you define both which entity should be edited and how to map data on the single view.
The Single View Creator retrieves the required data from all the involved projections. Then, it aggregates data and creates the single view according to the provided schema. The single views are saved on a different database collection to facilitate reading them. Since the data is already aggregated, it can be available in near real-time; which helps reading speed.

Figure 5 – Reading from projections to create single views.
It is also possible to have multiple single views containing partially similar data. The main purpose is to provide full data to external and internal consumers through a single request. So, you can optimize each single view in a useful way for a specific client, making it easier and more immediate to access it.
The single source of truth would still be the projection, while the single view provides a different view of the set of data in the system. Like projections, this data is stored on a highly scalable and flexible persistent database, and can easily be made available to clients to consume through APIs or other systems.

Figure 6 – Projections and single views are easily read.
Summary
Mia-Platform Fast Data provides a solution for ingesting data into your cloud workloads from external sources.
Whether you consume data from on-premise systems or from SaaS, you can create strong boundaries between systems of records and external channels. Thanks to this approach, you can effectively decouple the two parties, allowing both to evolve independently with minimum changes.
With this pattern, the data elaboration is done immediately after the ingestion into your system. This allows you to introduce even more complex algorithms for creating more accessible data models for your cloud workloads.
In fact, you can elaborate the data for better fulfilling the goals of your project, remapping them in a materialized view. As simple as it may sound, a materialized view can significantly improve the performance of your system when querying the data models.
Finally, you can ensure your system is always available in case of both planned interruptions of data sources, like maintenance operations and unexpected downtimes.
To learn more on how the pattern described in this post can help you bring data to the center and become a data-driven company, download the whitepaper.
.
 .
.
Mia-Platform – AWS Partner Spotlight
Mia-Platform is an AWS Partner with a suite of products for the development of enterprise digital platforms based on Kubernetes and the best cloud-native technologies.