AWS Architecture Blog
Building an AI gateway to Amazon Bedrock with Amazon API Gateway
When building generative AI applications, enterprises need to govern foundation model usage through authorization, quota management, tenant isolation, and cost control. To meet these needs, Dynatrace developed a robust AI gateway architecture that has evolved into a reusable reference pattern for organizations looking to control access to Amazon Bedrock services at scale.
This pattern uses Amazon API Gateway as the access layer in front of Amazon Bedrock. It supports key capabilities such as request authorization with seamless integration into existing identity systems (for example, JWT validation), usage quotas and request throttling, lifecycle management, canary releases, and AWS WAF integration. The gateway also uses Amazon API Gateway response streaming, launched today, for real-time delivery of API model outputs that stream to users as they are generated. The complete solution code is available in our GitHub repository.
In this blog post, you’ll explore the underlying architecture, learn how to deploy and configure the solution, and discover further enhancement ideas.
Architecture of the AI gateway
The reference architecture gives you granular control over LLM access using fully managed AWS services. It is transparent to client applications and seamlessly integrates into existing enterprise environments.
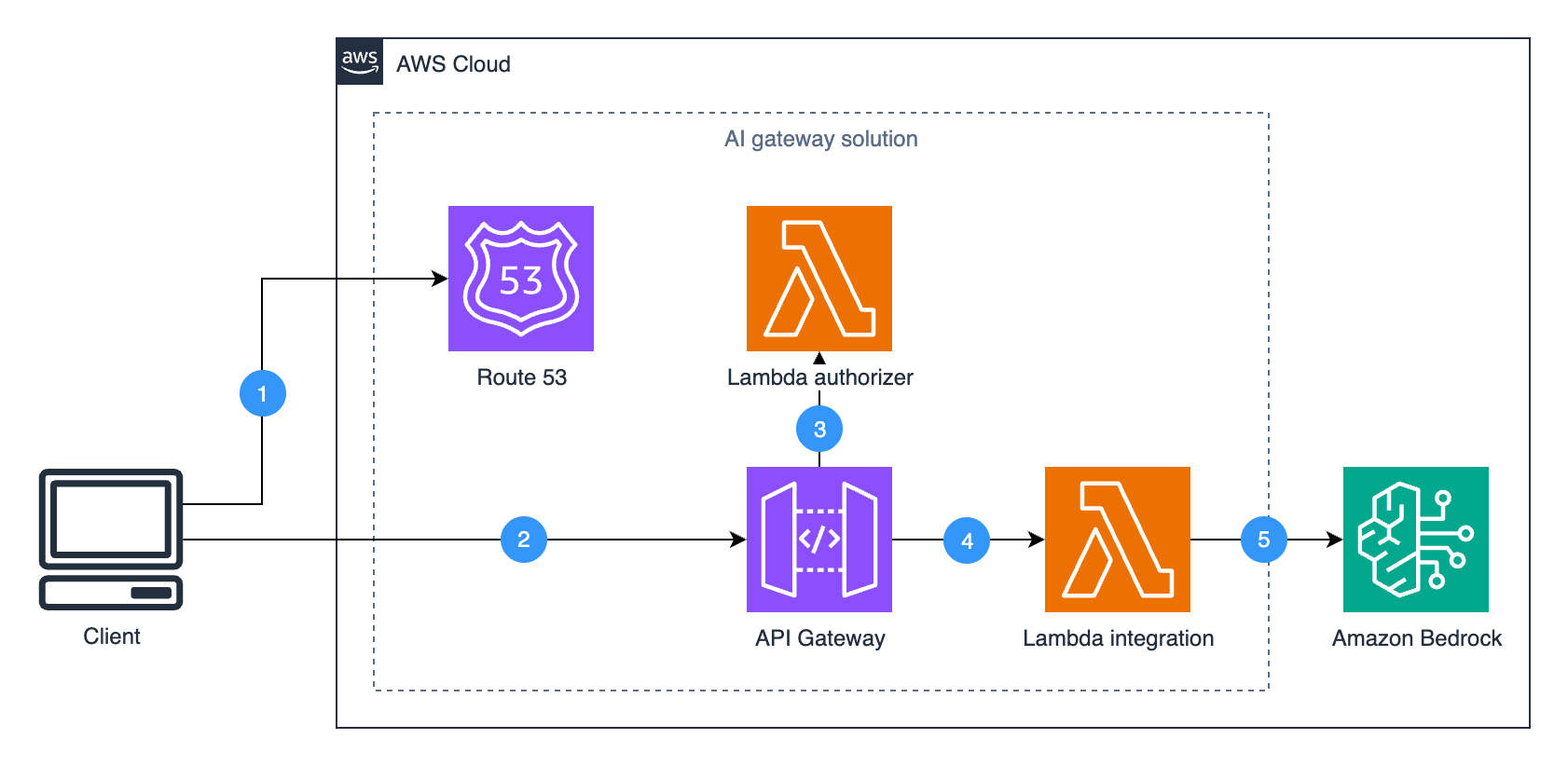
Figure 1. Reference architecture of the AI gateway.
The solution consists of four core components:
- Amazon Route 53 (optional) manages custom domain routing, allowing clients to access the gateway through a company-specific endpoint instead of the default Amazon API Gateway domain.
- Amazon API Gateway serves as the entry point for the requests and provides capabilities like authorization, request throttling, and lifecycle management.
- AWS Lambda authorizer handles request authorization, which in the Dynatrace implementation involves validating JWT tokens with existing authentication systems. For your specific implementation, you can implement your own authorization logic in a Lambda authorizer, integrate with Amazon Cognito user pools, or use other API Gateway authorization mechanisms.
- Lambda integration is a dynamic request forwarder that signs incoming requests with AWS credentials and routes them to the appropriate Amazon Bedrock endpoints. The function preserves the original request details, including the API action and parameters, to support current or future Amazon Bedrock APIs without code changes. The complete implementation is available in the integration Lambda function.
- Amazon Bedrock provides access to foundation models and AI capabilities.
The benefit of this architecture is the transparency to client applications and future-proof design. Clients can use AWS SDKs (like Boto3) to access Amazon Bedrock functionalities (such as LLMs and Knowledge Bases) exactly as they would when calling the Amazon Bedrock API directly. Meanwhile, the AI gateway handles authorization, quota management, and other capabilities behind the scenes.
When a client makes an Amazon Bedrock API call to the AI gateway endpoint, the Lambda integration function:
- Captures the original request with its details (headers, body, and parameters).
- Applies AWS Signature Version 4 authentication.
- Forwards the request to the correct Amazon Bedrock service endpoint.
With this approach the AI gateway can support current and new Amazon Bedrock features without requiring specific API knowledge or code updates, reducing gateway maintenance as the available features grow.
Deploying with AWS CloudFormation
This walkthrough will deploy a private AI gateway with authorization disabled for initial testing. You’ll create the core infrastructure (API Gateway, Lambda functions, and VPC endpoints) and then test basic functionality before optionally adding security features.
The quickest way to deploy this solution is with AWS CloudFormation:
- Sign in as an administrator to the AWS Management Console and use the navigation bar to select your desired AWS Region for deployment.
- Choose the following Launch Stack button:
![]()
- In the Quick create stack page, configure the key parameters as follows. For complete parameter descriptions, see the documentation.
| Parameter | Description | Choose value | Why |
|---|---|---|---|
| EndpointType | API Gateway endpoint accessibility (PRIVATE or REGIONAL) | PRIVATE | Secure internal access only |
| EnableAuthorizer | Enable Lambda Authorizer for API Gateway | false | Start without auth for simpler testing |
| CustomDomain | Custom domain name for API Gateway | (leave empty) | Use default domain initially |
| HostedZoneId | Route 53 Hosted Zone ID for custom domain SSL validation | (leave empty) | Not needed with default domain |
- Select the capability I acknowledge that AWS CloudFormation might create IAM resources.
- Leave all other configurations at their default values and choose Create Stack.
- In the stack page, wait until the Status of the stack transitions to CREATE_COMPLETE.
- Choose Outputs and copy the values for GatewayUrl, VpcId, and ApiId – you’ll use these to test your gateway later.
Testing the deployment
Your gateway is now running privately inside its VPC, but that means you can’t reach it from the outside. You’ll now create an AWS CloudShell environment inside the VPC to test the gateway:
- Open the CloudShell console page, choose the + icon and then choose Create VPC environment.
- On the Create a VPC environment page, configure:
- Name: for example, AIGatewayTest
- Virtual Private Cloud (VPC): the VpcId you copied earlier
- Subnet: any available subnet
- Security group: the default VPC security group
- Choose Create to create your VPC environment.
Once your CloudShell environment is ready, you’ll create a client that properly routes requests through your private API endpoint.First, execute this command in CloudShell to create a reusable client factory that routes requests through your gateway while maintaining the standard boto3 interface:
With the factory in place, you can now create clients for different Amazon Bedrock services. Set your configuration variables:
Test model inference with Amazon Bedrock ConverseStream API:
Test retrieval from Amazon Bedrock Knowledge Bases:
Configuring authorization
After testing the basic functionality, you can now enable authorization by updating your deployed stack with custom authorization logic. For example, to implement JWT validation in a Lambda authorizer:
- Open the CloudFormation template file with your favorite text editor and replace the following placeholder code in the Lambda authorizer with your own authorization logic (see examples):
- Update the CloudFormation stack to enable your new authorization logic:
- Go back to the CloudFormation console
- Select your bedrock-llm-gateway stack, choose Update stack, and choose Make a direct update
- Choose Replace existing template, upload your modified template file, and choose Next
- In the parameters section, change EnableAuthorizer from false to true and choose Next
- Select the capability I acknowledge that AWS CloudFormation might create IAM resources.
- Choose Next and choose Submit
- Once the CloudFormation stack update is complete, deploy your changes to the API Gateway. API Gateway requires an explicit deployment step to activate configuration changes. While CloudFormation updates the API Gateway resources, the changes won’t be active until you create a new deployment to push them to the stage.
- Navigate to the API Gateway console
- Choose your API (find it using the ApiId from your CloudFormation outputs)
- Choose Deploy API
- For Stage select v1, and choose Deploy
- Test your authorization by going back to CloudShell and running this example. This example passes a JWT token to test the authorization – replace it with your actual token or other authorization parameters you configured in the Lambda authorizer.
Enhancement options for the AI gateway
The solution can be enhanced using additional API Gateway capabilities. Here are some examples:
- Rate limiting and throttling: Control request rates using usage plans and API keys. This is especially important in multi-tenant SaaS applications to avoid noisy neighbor problems. For examples of throttling scenarios, see the throttling documentation.
- Private or edge-optimized endpoints: Configure endpoint types to optimize for internal access or global performance.
- Lifecycle management and canary releases: Manage multiple API versions and implement gradual rollouts with stage variables and canary deployments.
- WAF integration: Add AWS WAF rules to help protect from common exploits.
- Prompt and response caching: Implement caching strategies to reduce costs and improve response times for frequently requested prompts using API Gateway caching.
- Content filtering: In addition to the safeguards offered by Amazon Bedrock Guardrails, add custom filtering in the Lambda integration layer to screen for sensitive content such as personally identifiable information (PII).
For more information about these capabilities, visit the API Gateway features page.
Conclusion
The AI gateway pattern demonstrated in this post provides a scalable way to manage access to foundation models and agent tools through Amazon Bedrock. Initially developed and implemented by Dynatrace to serve their global user base, this pattern has proven its effectiveness at enterprise-scale. By using the Amazon API Gateway enterprise features organizations can implement necessary controls while maintaining the benefits of serverless architecture.
To start using this solution today, follow the walkthrough in this blog post or check out our GitHub repository. To learn more about the services used in this solution, explore the Amazon API Gateway features page, or visit the documentation for Amazon API Gateway and Amazon Bedrock. To learn how this solution streams foundation model responses, see the documentation for the new Amazon API Gateway response streaming capability.