AWS Architecture Blog
Category: Storage
Optimize your modern data architecture for sustainability: Part 1 – data ingestion and data lake
The modern data architecture on AWS focuses on integrating a data lake and purpose-built data services to efficiently build analytics workloads, which provide speed and agility at scale. Using the right service for the right purpose not only provides performance gains, but facilitates the right utilization of resources. Review Modern Data Analytics Reference Architecture on […]

How USAA built an Amazon S3 malware scanning solution
United Services Automobile Association (USAA) is a San Antonio-based insurance, financial services, banking, and FinTech company supporting millions of military members and their families. USAA has partnered with Amazon Web Services (AWS) to digitally transform and build multiple USAA solutions that help keep members safe and save members money and time. Why build a S3 […]

Deploying IBM Cloud Pak for Data on Red Hat OpenShift Service on AWS
Editor’s note, October 2024: This post is now obsolete. For the latest post, refer to Deploying IBM Cloud Pak for Data on Red Hat OpenShift Service on AWS. Amazon Web Services (AWS) customers who want to deploy and use IBM Cloud Pak for Data (CP4D) on the AWS Cloud, can use Red Hat OpenShift Service […]

A multi-dimensional approach helps you proactively prepare for failures, Part 2: Infrastructure layer
Distributed applications resiliency is a cumulative resiliency of applications, infrastructure, and operational processes. Part 1 of this series explored application layer resiliency. In Part 2, we discuss how using Amazon Web Services (AWS) managed services, redundancy, high availability, and infrastructure failover patterns based on recovery time and point objectives (RTO and RPO, respectively) can help in […]

Coordinating large messages across accounts and Regions with Amazon SNS and SQS
Many organizations have applications distributed across various business units. Teams in these business units may develop their applications independent of each other to serve their individual business needs. Applications can reside in a single Amazon Web Services (AWS) account or be distributed across multiple accounts. Applications may be deployed to a single AWS Region or […]

Augmentation patterns to modernize a mainframe on AWS
Customers with mainframes want to use Amazon Web Services (AWS) to increase agility, maximize the value of their investments, and innovate faster. On June 8, 2022, AWS announced the general availability of AWS Mainframe Modernization, a new service that makes it faster and simpler for customers to modernize mainframe-based workloads. In this post, we discuss […]

Using AWS Backup and Oracle RMAN for backup/restore of Oracle databases on Amazon EC2: Part 2
Customers running Oracle databases on Amazon Elastic Compute Cloud (Amazon EC2) often take database and schema backups using Oracle native tools like Data Pump and Recovery Manager (RMAN) to satisfy data protection, disaster recovery (DR), and compliance requirements. A priority is to reduce backup time as the data grows exponentially and recover sooner in case […]
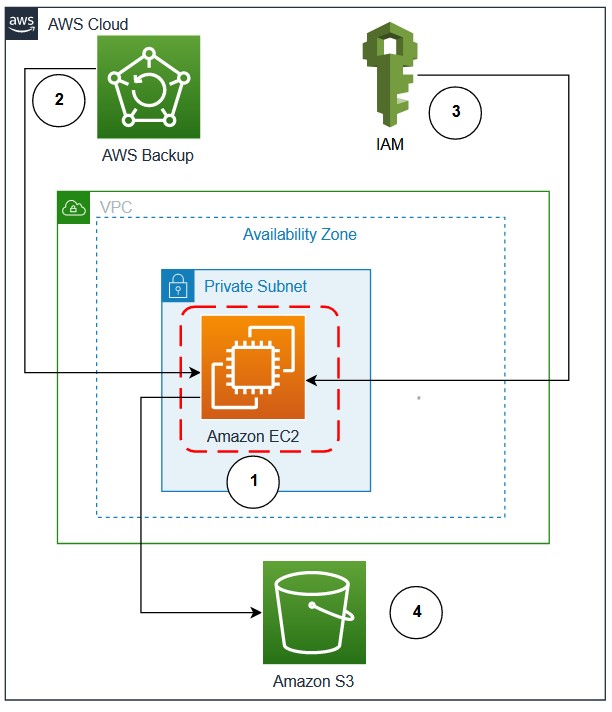
Using AWS Backup and Oracle RMAN for backup/restore of Oracle databases on Amazon EC2: Part 1
Customers running Oracle databases on Amazon Elastic Compute Cloud (Amazon EC2) often take database and schema backups using Oracle native tools, like Data Pump and Recovery Manager (RMAN), to satisfy data protection, disaster recovery (DR), and compliance requirements. A priority is to reduce backup time as the data grows exponentially and recover sooner in case […]

Data warehouse and business intelligence technology consolidation using AWS
Organizations have been using data warehouse and business intelligence (DWBI) workloads to support business decision making for many years. These workloads are brought to the Amazon Web Services (AWS) platform to utilize the benefit of AWS cloud. However, these workloads are built using multiple vendor tools and technologies, and the customer faces the burden of […]

Image background removal using Amazon SageMaker semantic segmentation
Many individuals are creating their own ecommerce and online stores in order to sell their products and services. This simplifies and speeds the process of getting products out to your selected markets. This is a critical key indicator for the success of your business. Artificial Intelligence/Machine Learning (AI/ML) and automation can offer you an improved […]