AWS Architecture Blog
Category: Storage

Building highly available Oracle databases with Amazon FSx for NetApp ONTAP
This post shows how to build a highly available Oracle database architecture using FSxN shared storage, Auto Scaling groups with dynamic AMI updates, and serverless orchestration to help reduce recovery times with current configurations.

Automating contract intelligence with Doczy.ai™ on AWS
In this post, we show you how Doczy.ai™ uses generative AI on AWS to automate contract intelligence at scale, transforming unstructured documents into structured, actionable insights, so organizations can automate critical business processes and unlock the full value of their data.
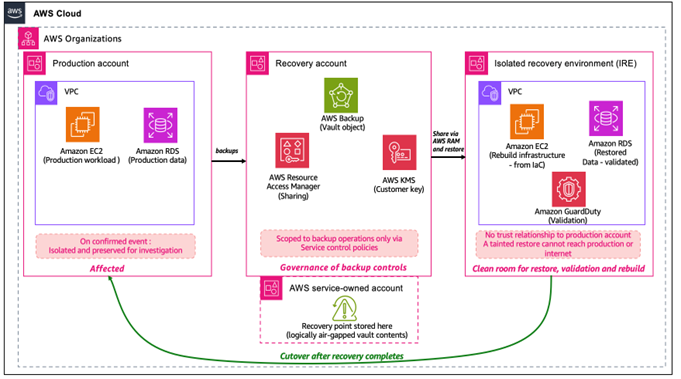
Cyber resilience on AWS: A reference approach for recovery from ransomware and destructive events
Cyber resilience is the ability to recover workloads to a known-good state after an adversary has affected the environment. Prevention works to keep threat actors out and detection works to find them quickly. Cyber resilience focuses on recovery: restoring a trustworthy environment when backups, credentials, or parts of the infrastructure can no longer be assumed […]
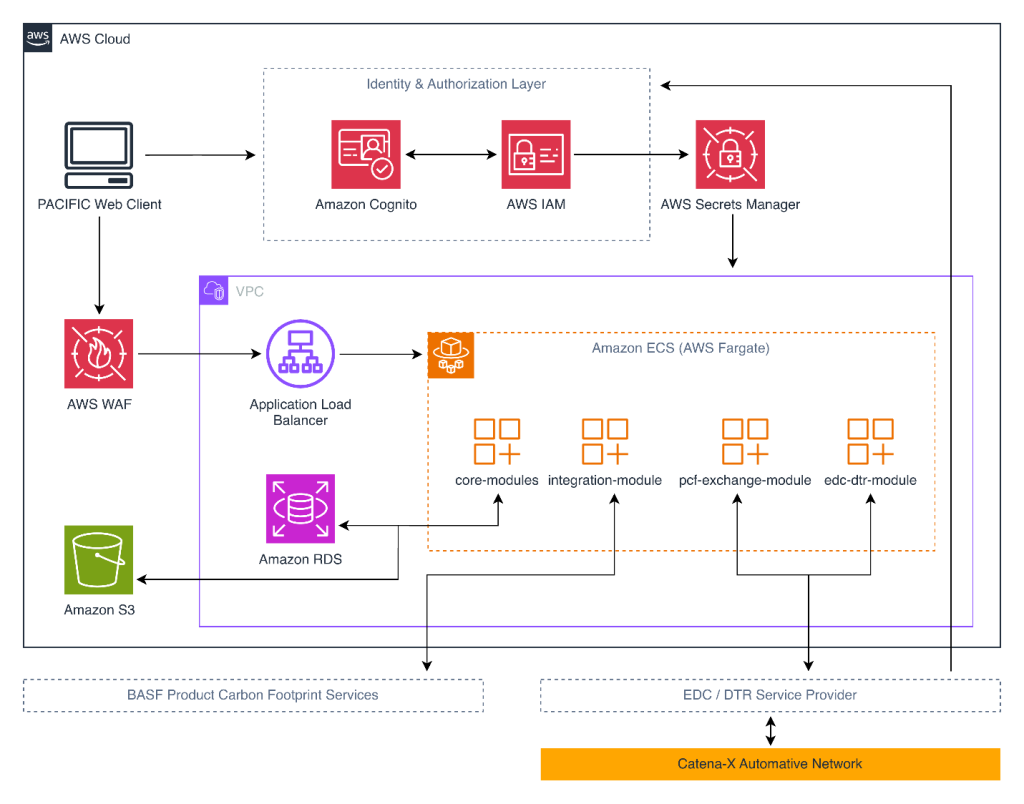
PACIFIC enables multi-tenant, sovereign product carbon footprint exchange on the Catena-X data space using AWS
This post explores how PACIFIC enables multi-tenant, sovereign PCF exchange on the Catena-X data space using Amazon Elastic Container Service (Amazon ECS) on AWS Fargate, Amazon Cognito, and AWS Identity and Access Management (IAM) to deliver measurable environmental impact and competitive advantage in a carbon-conscious marketplace.
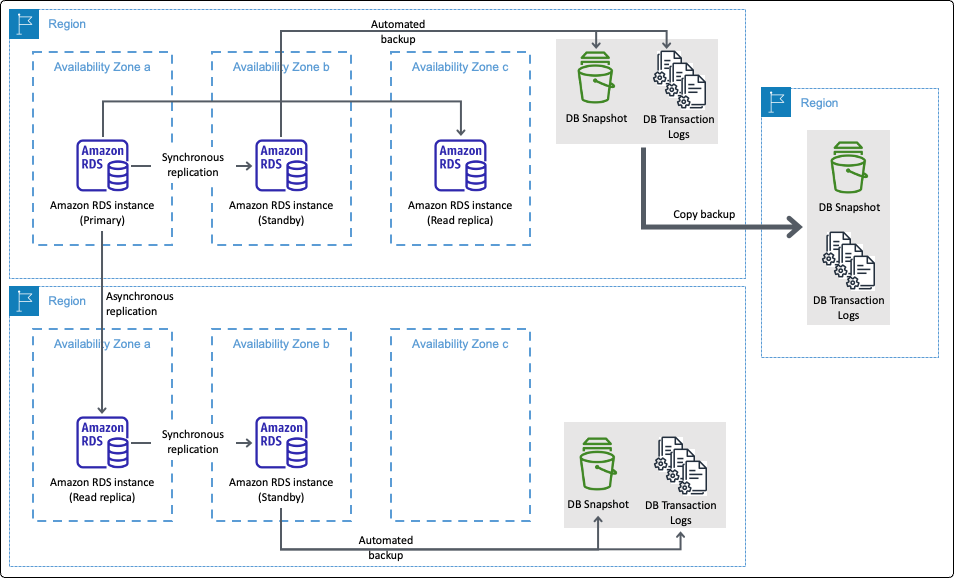
Streamlining access to powerful disaster recovery capabilities of AWS
In this blog post, we take a building blocks approach. Starting with the tools like AWS Backup to protect your data, we then add protection for Amazon Elastic Compute Cloud (Amazon EC2) compute using AWS Elastic Disaster Recovery (AWS DRS). Finally, we show how to use the full capabilities of AWS to restore your entire workload—data, infrastructure, networking, and configuration, using Arpio disaster recovery automation.
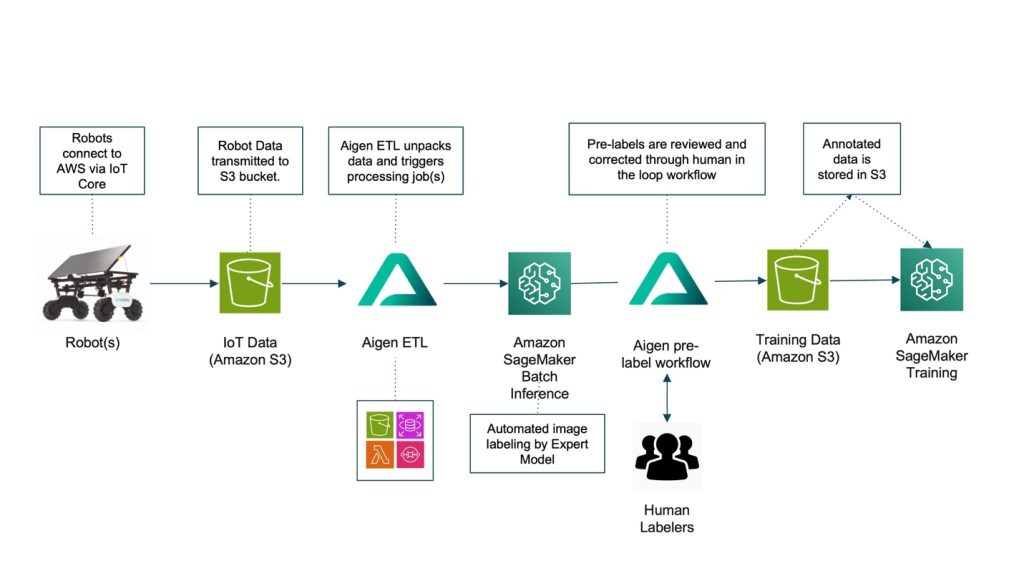
How Aigen transformed agricultural robotics for sustainable farming with Amazon SageMaker AI
In this post, you will learn how Aigen modernized its machine learning (ML) pipeline with Amazon SageMaker AI to overcome industry-wide agricultural robotics challenges and scale sustainable farming. This post focuses on the strategies and architecture patterns that enabled Aigen to modernize its pipeline across hundreds of distributed edge solar robots and showcase the significant business outcomes unlocked through this transformation. By adopting automated data labeling and human-in-the-loop validation, Aigen increased image labeling throughput by 20x while reducing image labeling costs by 22.5x.
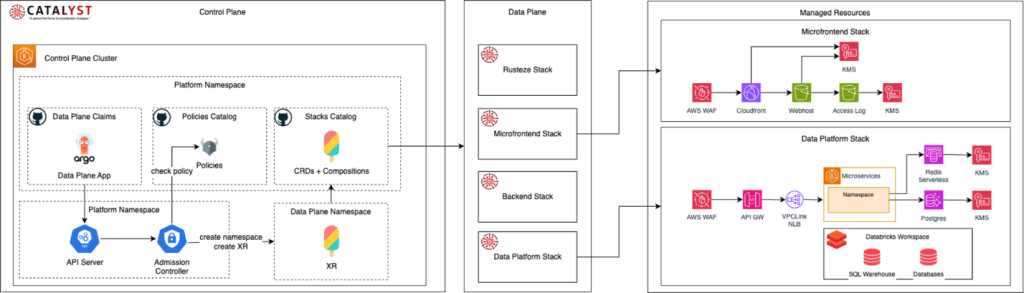
Digital Transformation at Santander: How Platform Engineering is Revolutionizing Cloud Infrastructure
Santander faced a significant technical challenge in managing an infrastructure that processes billions of daily transactions across more than 200 critical systems. The solution emerged through an innovative platform engineering initiative called Catalyst, which transformed the bank’s cloud infrastructure and development management. This post analyzes the main cases, benefits, and results obtained with this initiative.

BASF Digital Farming builds a STAC-based solution on Amazon EKS
This post was co-written with Frederic Haase and Julian Blau with BASF Digital Farming GmbH. At xarvio – BASF Digital Farming, our mission is to empower farmers around the world with cutting-edge digital agronomic decision-making tools. Central to this mission is our crop optimization platform, xarvio FIELD MANAGER, which delivers actionable insights through a range […]
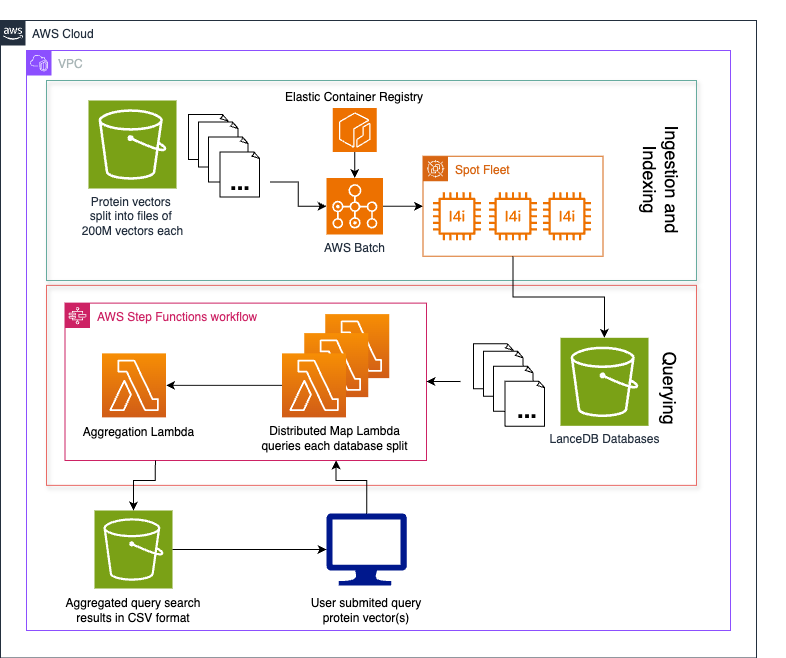
A scalable, elastic database and search solution for 1B+ vectors built on LanceDB and Amazon S3
In this post, we explore how Metagenomi built a scalable database and search solution for over 1 billion protein vectors using LanceDB and Amazon S3. The solution enables rapid enzyme discovery by transforming proteins into vector embeddings and implementing a serverless architecture that combines AWS Lambda, AWS Step Functions, and Amazon S3 for efficient nearest neighbor searches.

From virtual machine to Kubernetes to serverless: How dacadoo saved 78% on cloud costs and automated operations
In this post, we walk you step-by-step through dacadoo’s journey of embracing managed services, highlighting their architectural decisions as we go.