AWS Architecture Blog
How Aigen transformed agricultural robotics for sustainable farming with Amazon SageMaker AI
This post is cowritten with Yuri Brigance, and Usman M. Khan from Aigen.
Aigen builds autonomous robots designed to help farmers remove herbicide-resistant weeds and improve crop yield through AI-driven technology. These robots operate without chemicals, using renewable energy, and provide real-time, field-level data to enhance decision-making. Using advanced computer vision AI, Aigen’s robots autonomously identify and remove weeds without harming crops, giving farmers an eco-friendly, cost-effective solution to traditional weed management and efficient farming. As its robotic fleet expanded, Aigen’s on-premises infrastructure became a bottleneck in scaling its model-building pipeline.
In this post, you will learn how Aigen modernized its machine learning (ML) pipeline with Amazon SageMaker AI to overcome industry-wide agricultural robotics challenges and scale sustainable farming. This post focuses on the strategies and architecture patterns that enabled Aigen to modernize its pipeline across hundreds of distributed edge solar robots and showcase the significant business outcomes unlocked through this transformation. By adopting automated data labeling and human-in-the-loop validation, Aigen increased image labeling throughput by 20x while reducing image labeling costs by 22.5x.
Key challenges of scaling field agricultural robots
Aigen’s initial ML pipeline was designed to build task-specific edge models for its field robots. Robot data was uploaded to Amazon Simple Storage Service (Amazon S3) for manual labeling. The annotated datasets were then used to train new task-specific edge models on Aigen’s on-premises infrastructure. However, this ML pipeline introduced several limitations:
- Connectivity Constraints: Inconsistent internet in rural areas hampered communication between robots and cloud.
- High Data Labeling Cost: Manual data labeling of thousands of new samples data per day proved prohibitively expensive and time-consuming.
- Limited Computational Power: Training specialized edge models and fine-tuning foundation models (FMs) for specific tasks using on-premises hardware was a bottleneck due to limited parallelism and GPU compute power with on-premises RTX 3090 machines.
- Scalability Issues: Model Training and data labeling batch Inference had to compete for the same RTX 3090 machines, causing delays either for the data science team for model training or the data labeling team for batch inference.
Solution
Aigen addresses these challenges by adopting an AWS AI-driven, cloud-native approach that enables scalable and automated operations:
- Edge Computing: Robots use AWS IoT Core and cloud utilities to safely offload data to Amazon S3, even in low-connectivity regimes.
- Automated Data Pipeline: Data collected by the robots flows through an Extract, Transform, and Load (ETL) pipeline for preprocessing. Data labeling is accelerated using an ensemble of vision foundation models (Grounding DINO, Owl-ViT, SAM2, CLIPSeg) along with custom expert vision models to automatically annotate large volumes of field imagery. Through active learning, the pipeline selects and down-samples the most informative samples, which are then reviewed and refined by human annotators before being passed downstream into the model training workflow.
- Cloud native ML Pipeline: Aigen accelerates model training on Amazon SageMaker AI, using Distributed Data Parallel (DDP) across multi-GPU clusters to achieve faster iteration cycles and efficient hyperparameter tuning. By scaling training in the cloud, Aigen removes resource contention between model training and data labeling batch inference. This results in improved throughput, reduced wait times, and a more predictable ML workflow for data science and labeling teams.
Let’s take a closer look at how Aigen’s solution architecture is designed to meet diverse machine learning needs, from data labeling to real-time inference on autonomous field robots, starting with its model architecture.
Model architecture
Aigen’s models are classified in four hierarchical categories that form a progression from broad, general-purpose models to highly specialized models tailored for edge computing. Foundation Models (L1) are the starting point, with each subsequent category building on the previous model, adding specificity or performance enhancements.
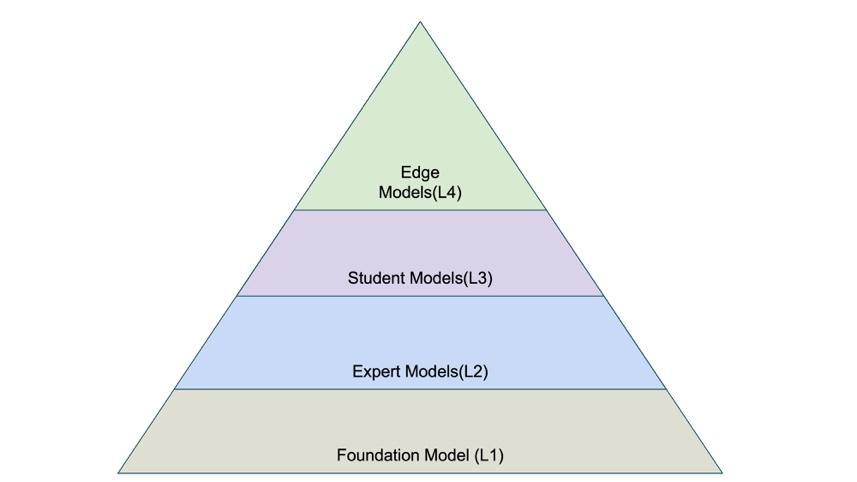
Figure 1: Aigen Model Architecture
- Foundation models use a combination of Aigen’s proprietary and open source foundation vision models to support plant detection, wheel detection, general object recognition, and segmentation. SAM2 is the primary model for generating segmentation masks, while Grounding DINO provides prompt-based annotation for objects like cars and people. Aigen employs a leading image generation model with ControlNet + Depth to create synthetic data with an option to fine-tune LoRA adapters to produce samples like field data. Aigen’s large vision models, trained on extensive field datasets, serve as robust foundations for crop identification and as high-quality starting points for building specialized pre-labeling models.
- Expert models are distilled from FMs and trained on annotated field images to perform precise, task-specific vision workloads. They generate high-quality pre-labels, bounding boxes, segmentation masks, and keypoint detections, which are then validated and refined by human annotators. Segmentation combined with key points allows the system to identify fine-grained plant anatomy, such as stems and other structural features. These models use both Vision Transformer and CNN-based architectures, and contain 10s of millions of parameters.
- Student models are compact, full-precision (FP32) models designed for ultra-low latency and minimal memory usage and are continuously fine-tuned on the latest data. Distilled from expert models, they remain extremely small, typically under 1.5M parameters, and are further improved through quantization-aware training (QAT), pruning, and other compression techniques. These optimizations enable efficient edge deployment, requiring as little as 2 Tera Operations Per Second (TOPS) while achieving real-time, double-digit frames per second (FPS) within the robot’s perception stack. Each student model is task-specific, tailored to individual crops (for example, tomato, cotton, sugar beets, soybeans) and various view angles such as top-down or intra-row.
- Edge models are built by further improving the full-precision student models for inference on the robot’s Neural Processing Unit (NPU). It undergoes QAT, followed by conversion to TFLite and INT8 quantization to reduce model size, lower power consumption, and increase inference throughput on the robot’s NPU. Purpose built for ultra-efficient edge inference, these models run on a 2.3-TOPS NPU using roughly 1.5W of power while sustaining real-time, double-digit FPS performance. These models contain 1M–1.2M parameters and occupy about 2 MB of memory.
This hybrid multi model ecosystem approach works well to balance model accuracy with edge computing constraints.
Modernized cloud native architecture for continuous model improvement
The modernized architecture forms a closed loop of nearly continuous model improvement, connecting field data collection from the robot to iterative training and rapid redeployment of updated models back onto the robot. This end-to-end cycle enables faster refinement, higher accuracy, and ongoing adaptation to real-world conditions.
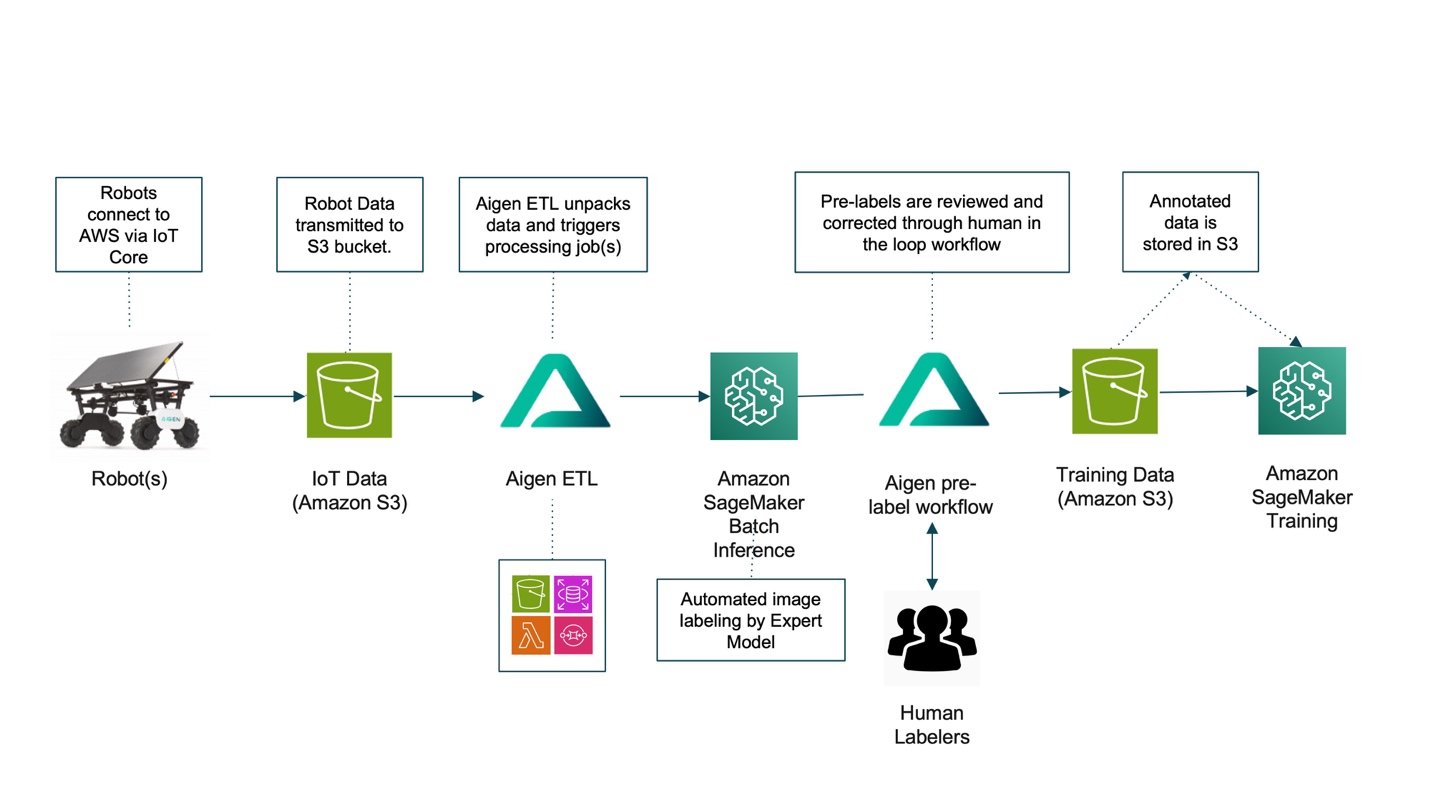
Figure 2: Aigen modernized architecture
The following sections describe the end-to-end process illustrated in the architecture diagram, from field data ingestion into AWS to continuous model delivery back to the robotic fleet. The workflow is organized into three key stages:
- Data Collection and Data Ingestion: Field Robots connect to AWS services using AWS IoT Core. Raw data, including navigation and crop-camera video (RGB + Depth), robot telemetry (odometry, frame timestamps), camera intrinsics/extrinsic, and job metadata, is continuously transmitted from the robots to Amazon S3 buckets. These data provide centralized storage for field, crop, and task specific downstream processing.
- Data Processing and Data Labeling: Aigen ETL unpacks the raw data, catalogs it, and stores it in Amazon S3. SageMaker AI processing jobs perform batch inference on this data and label the images using an ensemble of expert models running on the G5/G6 family of GPU instances. Aigen’s active learning process down-selects pre-labeled images and sends them for human review, where annotators validate and correct identified errors. Active learning analyzes images, embeddings, predictions, and other signals to identify the most informative samples for training. This approach removes the need to annotate every data point, often millions per field per season, by prioritizing images where the model struggles or those that add diversity. With multiple selection criteria, active learning helps keep dataset size manageable, control labeling effort, and verify only the most relevant samples are used to improve model performance.
- Model Training: The final annotated data is stored back in Amazon S3. SageMaker AI Training jobs pull this data from Amazon S3 and use multi-GPU instances to train expert, student and edge models. Edge-optimized models are deployed to the robots, while the newly finetuned expert models are used for the next cycle of data labeling.
Built on a cloud-native architecture, the workflow uses AWS services to deliver reliability, and robust performance, while effectively addressing the key challenges of scaling Aigen’s robotic fleet. The automated process collects data from field robot and use that in model training in the cloud, minimizing manual intervention while maintaining efficiency. Human-in-the-loop validation ensures high-quality training data by having annotators review and correct AI-generated pre-labels. Finally, active learning creates a positive feedback loop that continuously improves models by prioritizing the most relevant training data, enhancing robotic performance in real-world conditions.
Business benefits
This AI-powered solution delivered the following benefits:
- Cost Efficiency: Reduced labeling costs from ~$2.00 to $0.089 per image, achieving a 22.5× cost reduction
- Faster Annotation Pipeline: Reduced average annotation time from 14 minutes 57 seconds with manual labeling to just 41 seconds with SageMaker batch inference. This acceleration shortens model delivery for new crops from months to weeks, enabling quicker deployment and unlocking new business opportunities.
- Rapid Scaling Gains: Experiment capacity increased from five per week on on-premises infrastructure to hundreds per week using Amazon SageMaker AI, achieving a 20× increase in throughput over previous hardware.
- Innovation
- The powerful GPU instances of Amazon SageMaker AI enabled the training and fine-tuning of advanced Vision Transformers models, which were not feasible on limited on-premises hardware. This access to state-of-the-art (SOTA) GPUs accelerates model innovation.
- Scalable training infrastructure removes GPU bottlenecks by enabling parallel experimentation. This allows faster testing of new architectures and hyperparameters tuning, significantly speeding up model innovation compared to the slow, sequential workflow imposed by limited on-premises GPU capacity.
Key learnings
Amazon SageMaker AI has been instrumental in Aigen’s robotics system transformation, delivering significant benefits across the machine learning pipeline:
- Self-Managed AI Infrastructure: SageMaker AI removes the need for Aigen to build and maintain auto scaling GPU compute infrastructure. This reduction in development costs allows Aigen to focus more on model development rather than infrastructure management, accelerating the production of deployment-ready models.
- Streamlined ML Workflow: SageMaker AI streamlines the entire ML lifecycle, from data preparation to model deployment. Its flexibility supports the use of various built-in features and custom processes such as pre-labeling that cut down the time required to produce high-quality training data.
- Efficient Resource Utilization: The managed infrastructure of SageMaker AI lowers operational overhead, supports continuous model updates, such as daily fine-tuning as plants grow, without resource bottlenecks. For example, when moving to a new customer’s cotton field with different soil, lighting, or crop varieties, the base cotton model may underperform. With SageMaker AI, Aigen can rapidly ingest new data and fine-tune models on this new condition to improve performance. Over multiple seasons and fields, this process builds a diverse, high-quality dataset that steadily strengthens the model family.
To achieve similar results in your organization, start by evaluating your current data labeling costs and consider implementing active learning techniques to reduce manual annotation overhead.
Conclusion
By using AWS services, particularly SageMaker AI, Aigen moved beyond the limitations of its on-premises infrastructure and established a foundation for continued growth and innovation. The new architecture delivers the scalability, efficiency, and intelligence needed to expand its fleet of eco-friendly agricultural robots, bringing sustainable farming practices to more fields worldwide. Aigen’s journey illustrates how generative AI can modernize machine learning pipelines for robotics, enabling more productive and environmentally sustainable agriculture. You can implement a similar architecture pattern to improve the machine learning pipeline.
Get started with model training and model inference by visiting Amazon SageMaker AI Studio. Creating your first Serverless ML flow pipeline is also supported in SageMaker AI Studio for additional workflow flexibility.