AWS News Blog
Amazon Kinesis Firehose – Simple & Highly Scalable Data Ingestion
Two years ago we introduced Amazon Kinesis, which we now call Amazon Kinesis Streams, to allow you to build applications that collect, process, and analyze streaming data with very high throughput. We don’t want you to have to think about building and running a fleet of ingestion servers or worrying about monitoring, scaling, or reliable delivery.
Amazon Kinesis Firehose was purpose-built to make it even easier for you to load streaming data into AWS. You simply create a delivery stream, route it to an Amazon Simple Storage Service (Amazon S3) bucket and/or a Amazon Redshift table, and write records (up to 1000 KB each) to the stream. Behind the scenes, Kinesis Firehose will take care of all of the monitoring, scaling, and data management for you.
Once again (I never tire of saying this), you can spend more time focusing on your application and less time on your infrastructure.
Inside the Firehose
In order to keep things simple, Kinesis Firehose does not interpret or process the raw data in any way. You simply create a delivery stream and write data records to it. After any requested compression (client-side) and encryption (server-side), the records are written to an S3 bucket that you designate. As my colleague James Hamilton likes to say (in other contexts), “It’s that simple.” You can even control the buffer size and the buffer interval for the stream if necessary.
If your client code isolates individual logical records before sending them to Kinesis Firehose, it can add a delimiter. Otherwise, you can identify record boundaries later, once the data is in the cloud.
After your data is stored in S3, you have multiple options for analyzing and processing it. For example, you can attach an AWS Lambda function to the bucket and process the objects as they arrive. Or, you can point your existing Amazon EMR jobs at the bucket and process the freshest data, without having to make any changes to the jobs.
You can also use Kinesis Firehose to route your data to an Amazon Redshift cluster. After Kinesis Firehose stores your raw data in S3 objects, it can invoke a Redshift COPY command on each object. This command is very flexible and allows you to import and process data in multiple formats (CVS, JSON, AVRO, and so forth), isolate and store only selected columns, convert data from one type to another, and so forth.
Firehose From the Console
You can do all of this from the AWS Management Console, the AWS Command Line Interface (AWS CLI), and via the Firehose APIs.
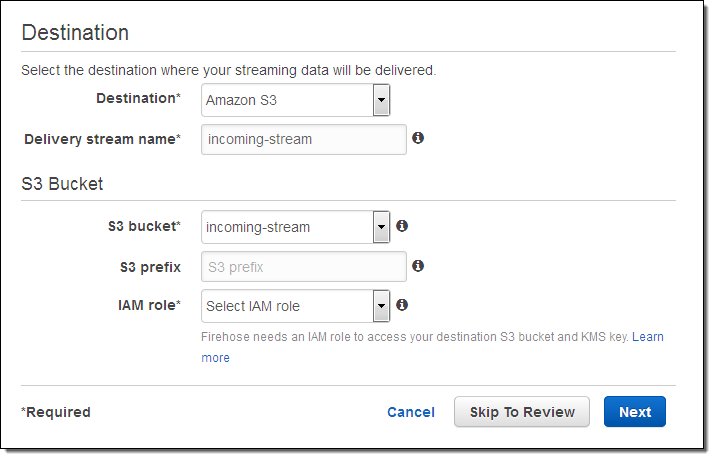
Let’s set up a delivery stream using the Kinesis Firehose Console. I simply open it up and click on Create Delivery Stream. Then I give my stream a name, pick an S3 bucket (or create a new one), and set up an IAM role so that Kinesis Firehose has permission to write to the bucket:
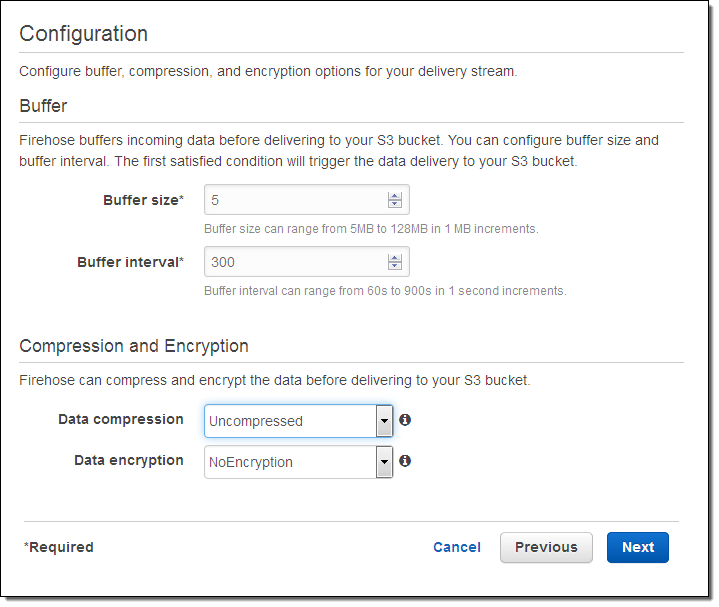
I can configure the latency and compression for the delivery stream. I can also choose to encrypt the data using one of my AWS Key Management Service (AWS KMS) keys:
Once my stream is created, I can see it from the console.
Publishing to a Delivery Stream
Here is some simple Java code to publish a record (the string “some data”) to my stream:
PutRecordRequest putRecordRequest = new PutRecordRequest();
putRecordRequest.setFirehoseName("incoming-stream");
String data = "some data" + "\n"; // add \n as a record separator
Record record = new Record();
record.setData(ByteBuffer.wrap(data.getBytes(StandardCharsets.UTF_8)));
putRecordRequest.setRecord(record);
firehoseClient.putRecord(putRecordRequest);
And here’s a CLI equivalent:
$ aws firehose put-record --delivery-stream-name incoming-stream --record Data="some data\n"
We also supply an agent that runs on Linux. It can be configured to watch one more log files and to route them to Kinesis Firehose.
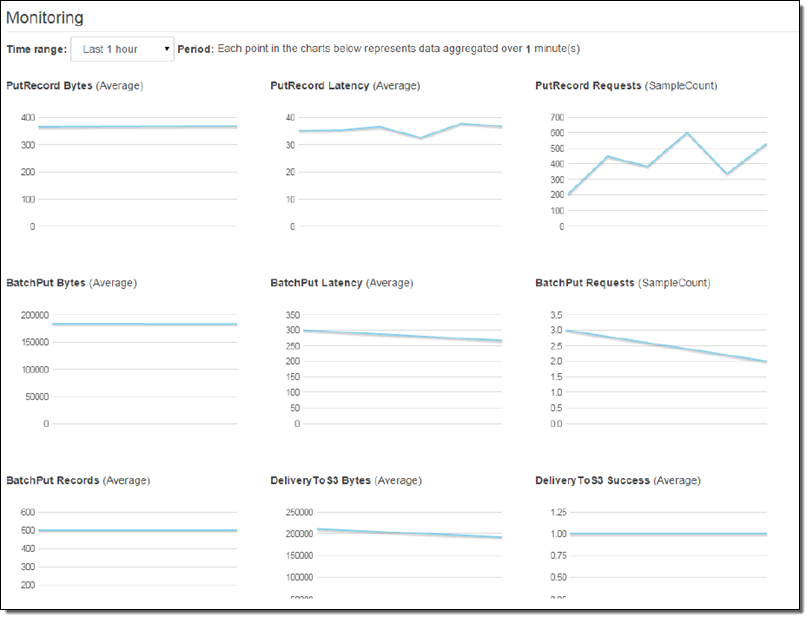
Monitoring Kinesis Firehose Delivery Streams
You can monitor the CloudWatch metrics for each of your delivery streams from the Console:
By the Numbers
Individual delivery streams can scale to accommodate multiple gigabytes of data per hour. By default, each stream can support 2500 calls to PutRecord or PutRecordBatch per second and you can have up to 5 streams per AWS account (both of these values are administrative limits that can be raised upon request, so just ask if you need more).
This feature is available now and you can start using it today. Pricing is based on the volume of data ingested via each Firehose.
— Jeff;