AWS Big Data Blog
Amazon Redshift data sharing best practices and considerations
Amazon Redshift is a fast, fully managed cloud data warehouse that makes it simple and cost-effective to analyze all your data using standard SQL and your existing business intelligence (BI) tools. Amazon Redshift data sharing allows for a secure and easy way to share live data for reading across Amazon Redshift clusters. It allows an Amazon Redshift producer cluster to share objects with one or more Amazon Redshift consumer clusters for read purposes without having to copy the data. With this approach, workloads isolated to different clusters can share and collaborate frequently on data to drive innovation and offer value-added analytic services to your internal and external stakeholders. You can share data at many levels, including databases, schemas, tables, views, columns, and user-defined SQL functions, to provide fine-grained access controls that can be tailored for different users and businesses that all need access to Amazon Redshift data. The feature itself is simple to use and integrate into existing BI tools.
In this post, we discuss Amazon Redshift data sharing, including some best practices and considerations.
How does Amazon Redshift data sharing work ?
- To achieve best in class performance Amazon Redshift consumer clusters cache and incrementally update block level data (let us refer to this as block metadata) of objects that are queried, from the producer cluster (this works even when cluster is paused).
- The time taken for caching block metadata depends on the rate of the data change on the producer since the respective object(s) were last queried on the consumer. (As of today the consumer clusters only update their metadata cache for an object only on demand i.e. when queried)
- If there are frequent DDL operations, the consumer is forced to re-cache the full block metadata for an object during the next access to maintain consistency as to enable live sharing as structure changes on the producer invalidate all the existing metadata cache on the consumers.
- Once the consumer has the block metadata in sync with the latest state of an object on the producer that is when the query would execute as any other regular query (query referring to local objects).
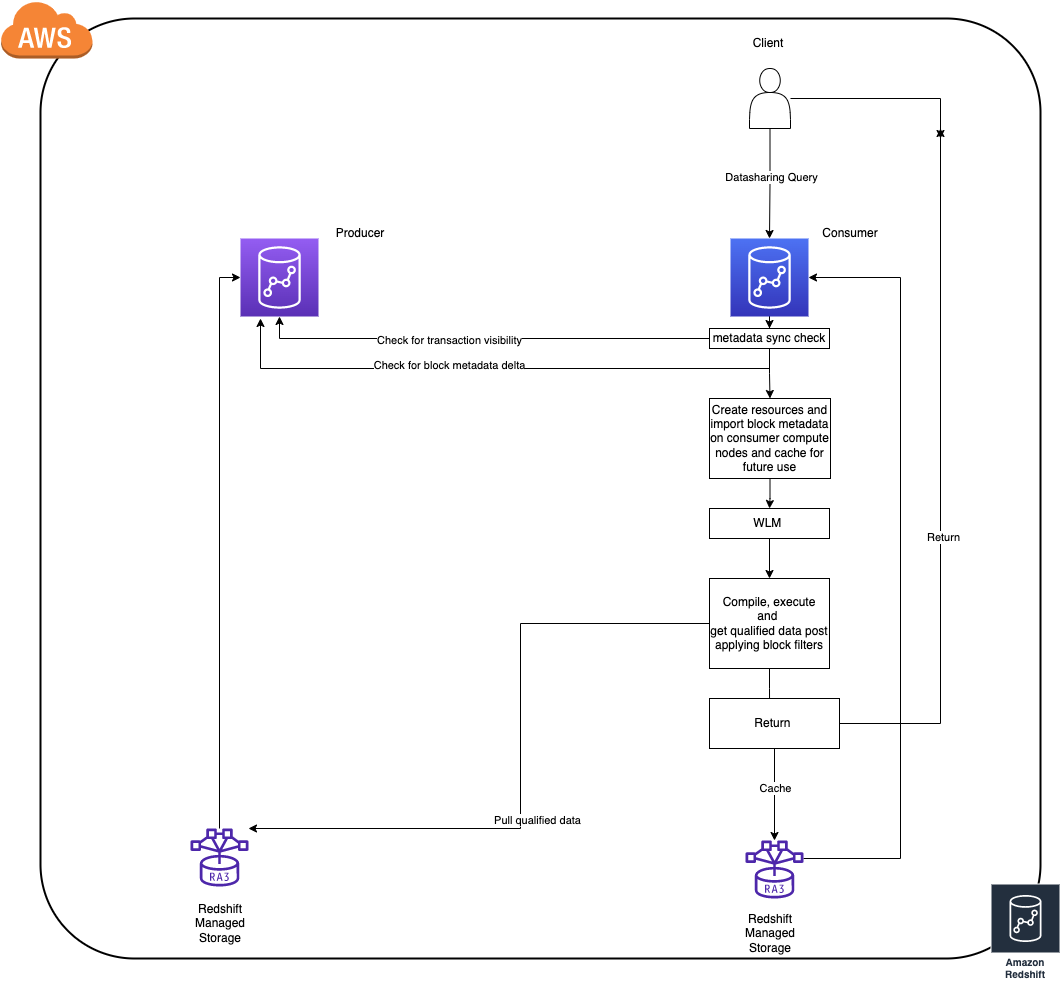
Now that we have the necessary background on data sharing and how it works, let’s look at a few best practices across streams that can help improve workloads while using data sharing.
Security
In this section, we share some best practices for security when using Amazon Redshift data sharing.
Use INCLUDE NEW cautiously
INCLUDE NEW is a very useful setting while adding a schema to a data share (ALTER DATASHARE). If set to TRUE, this automatically adds all the objects created in the future in the specified schema to the data share automatically. This might not be ideal in cases where you want to have fine-grained control on objects being shared. In these cases, leave the setting at its default of FALSE.
Use views to achieve fine-grained access control
To achieve fine-grained access control for data sharing, you can create late-binding views or materialized views on shared objects on the consumer, and then share the access to these views to users on consumer cluster, instead of giving full access on the original shared objects. This comes with its own set of considerations, which we explain later in this post.
Audit data share usage and changes
Amazon Redshift provides an efficient way to audit all the activity and changes with respect to a data share using system views. We can use the following views to check these details:
- SVL_DATASHARE_CHANGE_LOG – Records the activity and usage of data shares on the consumer cluster
- SVL_DATASHARE_USAGE_CONSUMER – Records the activity and usage of data shares on the consumer cluster
- SVL_DATASHARE_USAGE_PRODUCER – Records the activity and usage of data shares on the producer cluster
Performance
In this section, we discuss best practices related to performance.
Materialized views in data sharing environments
Materialized views (MVs) provide a powerful route to precompute complex aggregations for use cases where high throughput is needed, and you can directly share a materialized view object via data sharing as well.
For materialized views built on tables where there are frequent write operations, it’s ideal to create the materialized view object on the producer itself and share the view. This method gives us the opportunity to centralize the management of the view on the producer cluster itself.
For slowly changing data tables, you can share the table objects directly and build the materialized view on the shared objects directly on the consumer. This method gives us the flexibility of creating a customized view of data on each consumer according to your use case.
This can help optimize the block metadata download and caching times in the data sharing query lifecycle. This also helps in materialized view refreshes because, as of this writing, Redshift doesn’t support incremental refresh for MVs built on shared objects.
Factors to consider when using cross-Region data sharing
Data sharing is supported even if the producer and consumer are in different Regions. There are a few differences we need to consider while implementing a share across Regions:
- Consumer data reads are charged at $5/TB for cross region data shares, Data sharing within the same Region is free. For more information, refer to Managing cost control for cross-Region data sharing.
- Performance will also vary when compared to a uni-Regional data share because the block metadata exchange and data transfer process between the cross-Regional shared clusters will take more time due to network throughput.
Metadata access
There are many system views that help with fetching the list of shared objects a user has access to. Some of these include all the objects from the database that you’re currently connected to, including objects from all the other databases that you have access to on the cluster, including external objects. The views are as follows:
We suggest using very restrictive filtering while querying these views because a simple select * will result in an entire catalog read, which isn’t ideal. For example, take the following query:
This query will try to collect metadata for all the shared and local objects, making it very heavy in terms of metadata scans, especially for shared objects.
The following is a better query for achieving a similar result:
This is a good practice to follow for all metadata views and tables; doing so allows seamless integration into several tools. You can also use the SVV_DATASHARE* system views to exclusively see shared object-related information.
Producer/consumer dependencies
In this section, we discuss the dependencies between the producer and consumer.
Impact of the consumer on the producer
Queries on the consumer cluster will have no impact in terms of performance or activity on the producer cluster. This is why we can achieve true workload isolation using data sharing.
Encrypted producers and consumers
Data sharing seamlessly integrates even if both the producer and the consumer are encrypted using different AWS Key Management Service (AWS KMS) keys. There are sophisticated, highly secure key exchange protocols to facilitate this so you don’t have to worry about encryption at rest and other compliance dependencies. The only thing to make sure is that both the producer and consumer are in a homogeneous encryption configuration.
Data visibility and consistency
A data sharing query on the consumer can’t impact the transaction semantics on the producer. All the queries involving shared objects on the consumer cluster follow read-committed transaction consistency while checking for visible data for that transaction.
Maintenance
If there is a scheduled manual VACUUM operation in use for maintenance activities on the producer cluster on shared objects, you should use VACUUM recluster whenever possible. This is especially important for large objects because it has optimizations in terms of the number of data blocks the utility interacts with, which results in less block metadata churn compared to a full vacuum. This benefits the data sharing workloads by reducing the block metadata sync times.
Add-ons
In this section, we discuss additional add-on features for data sharing in Amazon Redshift.
Real-time data analytics using Amazon Redshift streaming data
Amazon Redshift recently announced the preview for streaming ingestion using Amazon Kinesis Data Streams. This eliminates the need for staging the data and helps achieve low-latency data access. The data generated via streaming on the Amazon Redshift cluster is exposed using a materialized view. You can share this as any other materialized view via a data share and use it to set up low-latency shared data access across clusters in minutes.
Amazon Redshift concurrency scaling to improve throughput
Amazon Redshift data sharing queries can utilize concurrency scaling to improve the overall throughput of the cluster. You can enable concurrency scaling on the consumer cluster for queues where you expect a heavy workload to improve the overall throughput when the cluster is experiencing heavy load.
For more information about concurrency scaling, refer to Data sharing considerations in Amazon Redshift.
Amazon Redshift Serverless
Amazon Redshift Serverless clusters are ready for data sharing out of the box. A serverless cluster can also act as a producer or a consumer for a provisioned cluster. The following are the supported permutations with Redshift Serverless:
- Serverless (producer) and provisioned (consumer)
- Serverless (producer) and serverless (consumer)
- Serverless (consumer) and provisioned (producer)
Conclusion
Amazon Redshift data sharing gives you the ability to fan out and scale complex workloads without worrying about workload isolation. However, like any system, not having the right optimization techniques in place could pose complex challenges in the long term as the systems grow in scale. Incorporating the best practices listed in this post presents a way to mitigate potential performance bottlenecks proactively in various areas.
Try data sharing today to unlock the full potential of Amazon Redshift, and please don’t hesitate to reach out to us in case of further questions or clarifications.
About the authors
 BP Yau is a Sr Product Manager at AWS. He is passionate about helping customers architect big data solutions to process data at scale. Before AWS, he helped Amazon.com Supply Chain Optimization Technologies migrate its Oracle data warehouse to Amazon Redshift and build its next generation big data analytics platform using AWS technologies.
BP Yau is a Sr Product Manager at AWS. He is passionate about helping customers architect big data solutions to process data at scale. Before AWS, he helped Amazon.com Supply Chain Optimization Technologies migrate its Oracle data warehouse to Amazon Redshift and build its next generation big data analytics platform using AWS technologies.
 Sai Teja Boddapati is a Database Engineer based out of Seattle. He works on solving complex database problems to contribute to building the most user friendly data warehouse available. In his spare time, he loves travelling, playing games and watching movies & documentaries.
Sai Teja Boddapati is a Database Engineer based out of Seattle. He works on solving complex database problems to contribute to building the most user friendly data warehouse available. In his spare time, he loves travelling, playing games and watching movies & documentaries.