AWS Big Data Blog
Announcing cross-account ingestion for Amazon OpenSearch Service
Amazon OpenSearch Ingestion is a powerful data ingestion pipeline that AWS customers use for many different purposes, such as observability, analytics, and zero-ETL search. Many customers today push logs, traces, and metrics from their applications to OpenSearch Ingestion to store and analyze this data.
Today, we are happy to announce that OpenSearch Ingestion pipelines now support cross-account ingestion for push-based sources such as HTTP and OpenTelemetry (OTel). Organizations can now use this feature to effortlessly share data across teams. For example, many organizations have central observability teams—now these teams can create OpenSearch Ingestion pipelines and share them with other teams in their organization. You can also use this feature to ingest data into Amazon OpenSearch Service domains or Amazon OpenSearch Serverless collections in other accounts.
Previously, sharing OpenSearch Ingestion pipelines across accounts required teams to use virtual private cloud (VPC) features to share access. For example, teams could use VPC peering, which is not always feasible, or AWS Transit Gateway. The new cross-account ingestion features in OpenSearch Ingestion can simplify your deployment and reduce cost for sharing pipelines.
Solution overview
Let’s look at how to share a pipeline from a central logging account with two other development accounts (A and B). The central logging account can create an OpenSearch Ingestion pipeline using a push-based source, for example, HTTP. After creating the pipeline, a member of the central logging team can grant access to the other teams. They can use a resource policy that gives permissions to the two other team accounts to create pipeline endpoints. After making this change, the OpenSearch Ingestion pipeline is available for use by the other teams.
The following diagram illustrates this configuration.
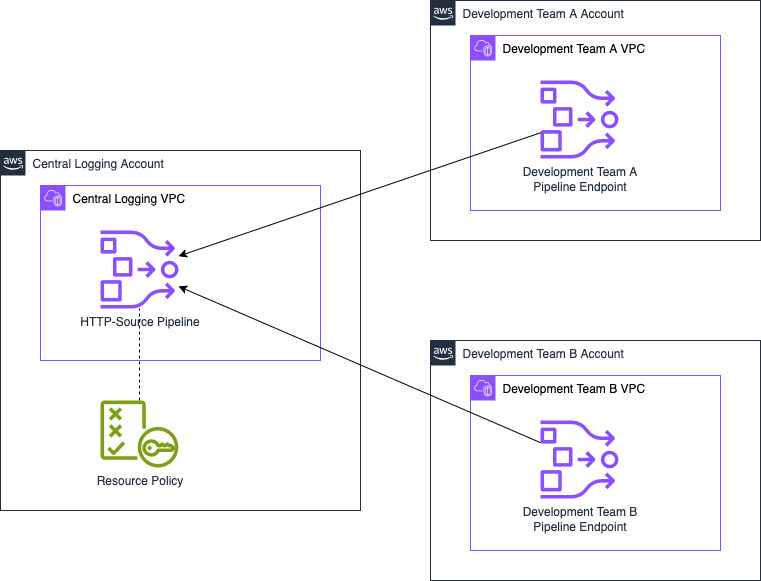
In the following sections, we demonstrate how to implement this solution.
Prerequisites
First, the central logging account must have a VPC with two options enabled.
- enableDnsSupport must be set to true
- enableDnsHostnames must be set to true
The central logging account must also create a push-based OpenSearch Ingestion pipeline in the VPC. This can be a pipeline receiving logs from FluentBit or OpenTelemetry telemetry.
The development accounts that are going to connect to the pipeline also must have VPCs in the same region with the same DNS options enabled.
- enableDnsSupport must be set to true
- enableDnsHostnames must be set to true
Create resource policy
As the owner of the pipeline, you can create a resource policy that allows the two development accounts to create pipeline endpoints against your pipeline.
The following is an example resource policy for this scenario:
The OpenSearch Ingestion console makes it straightforward to create these policies, as shown in the following screenshot.
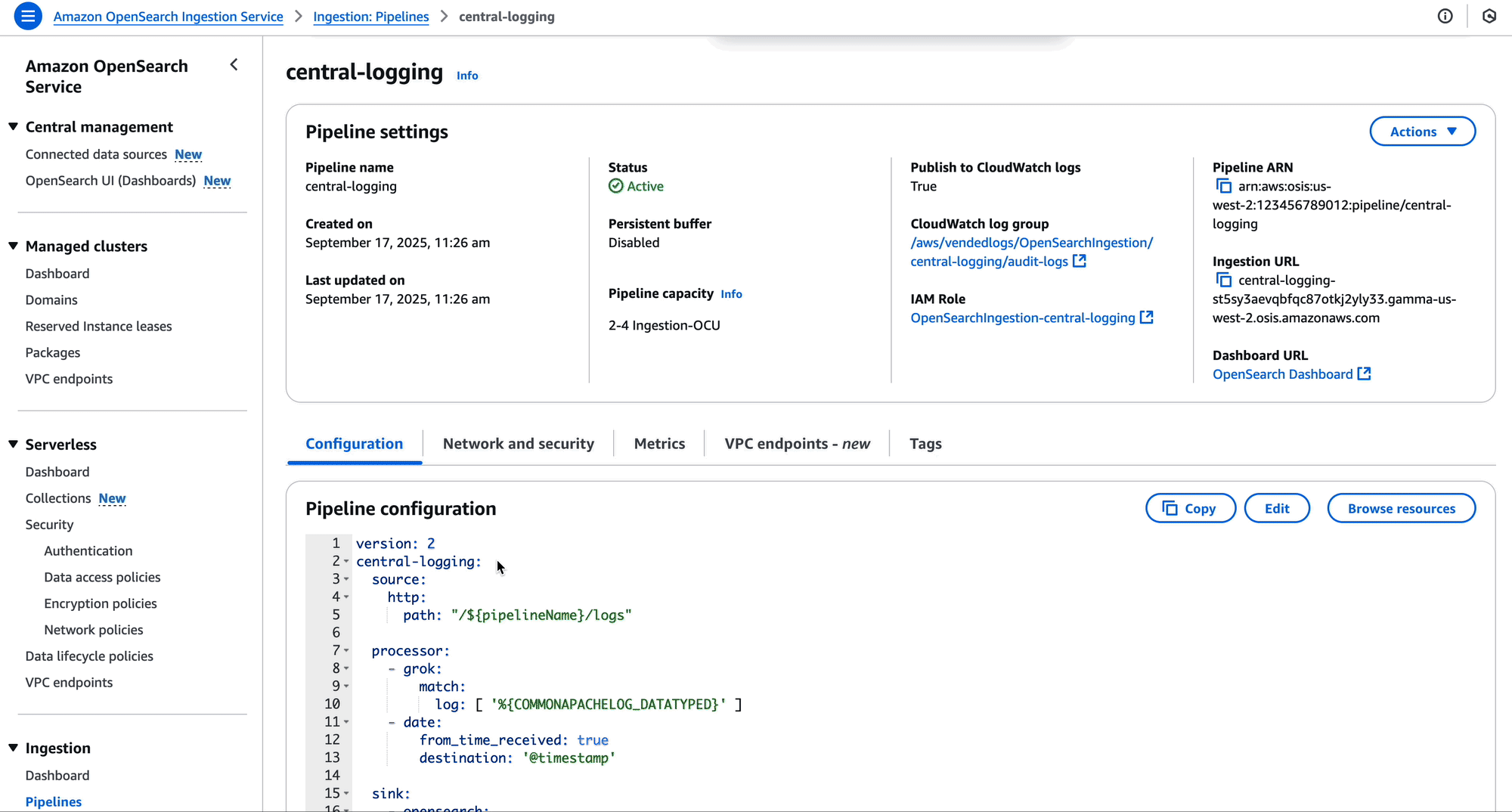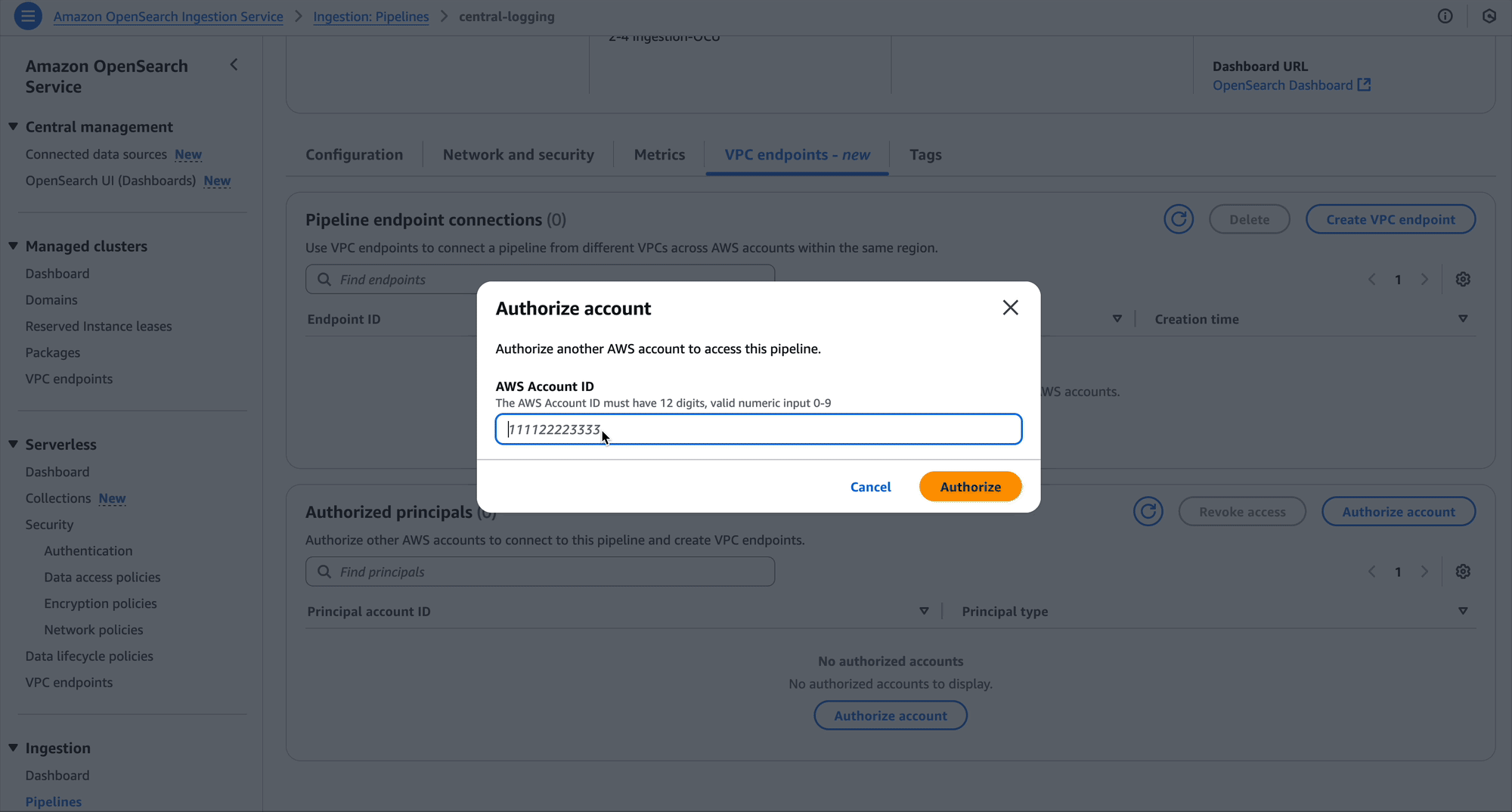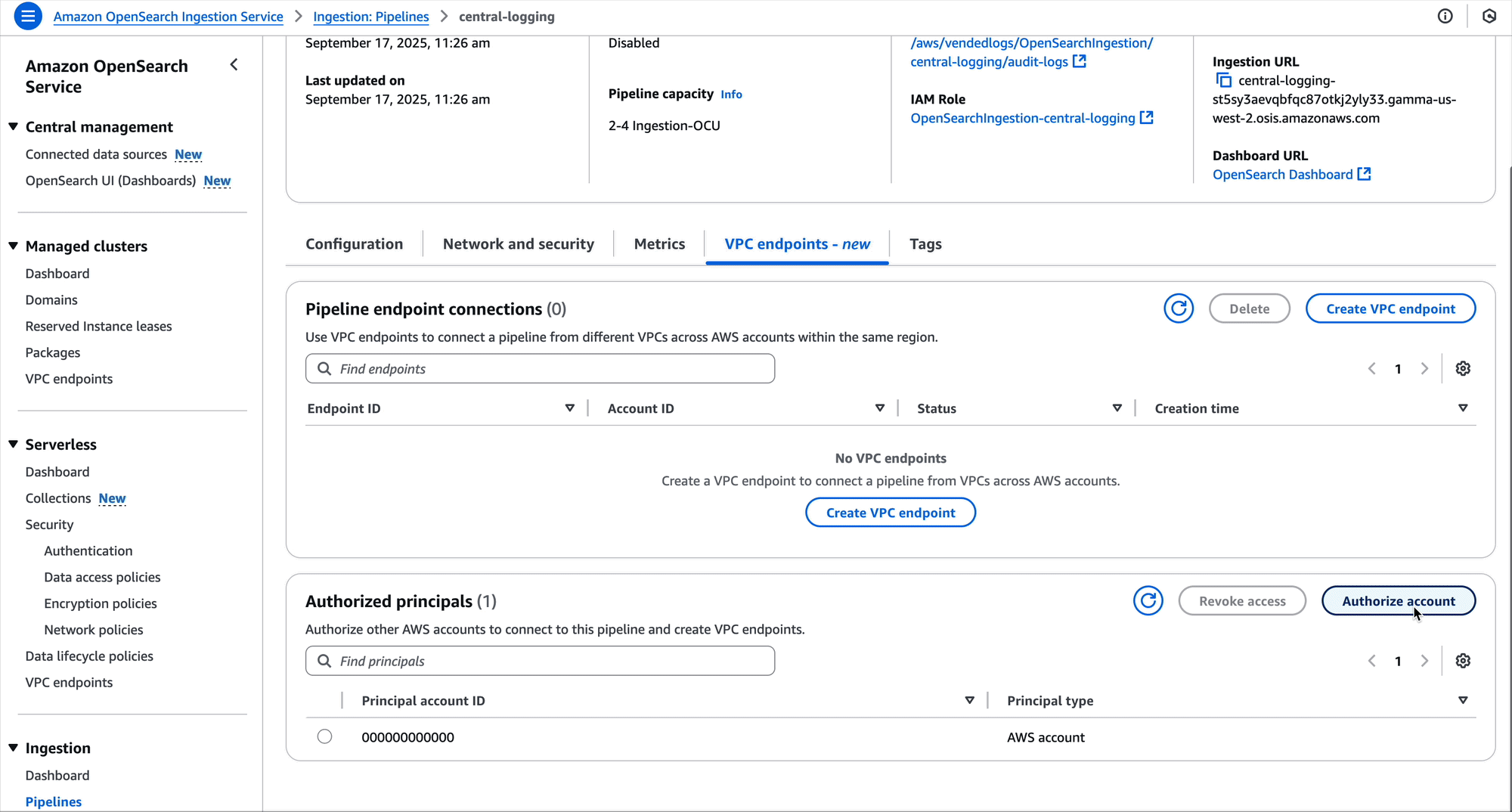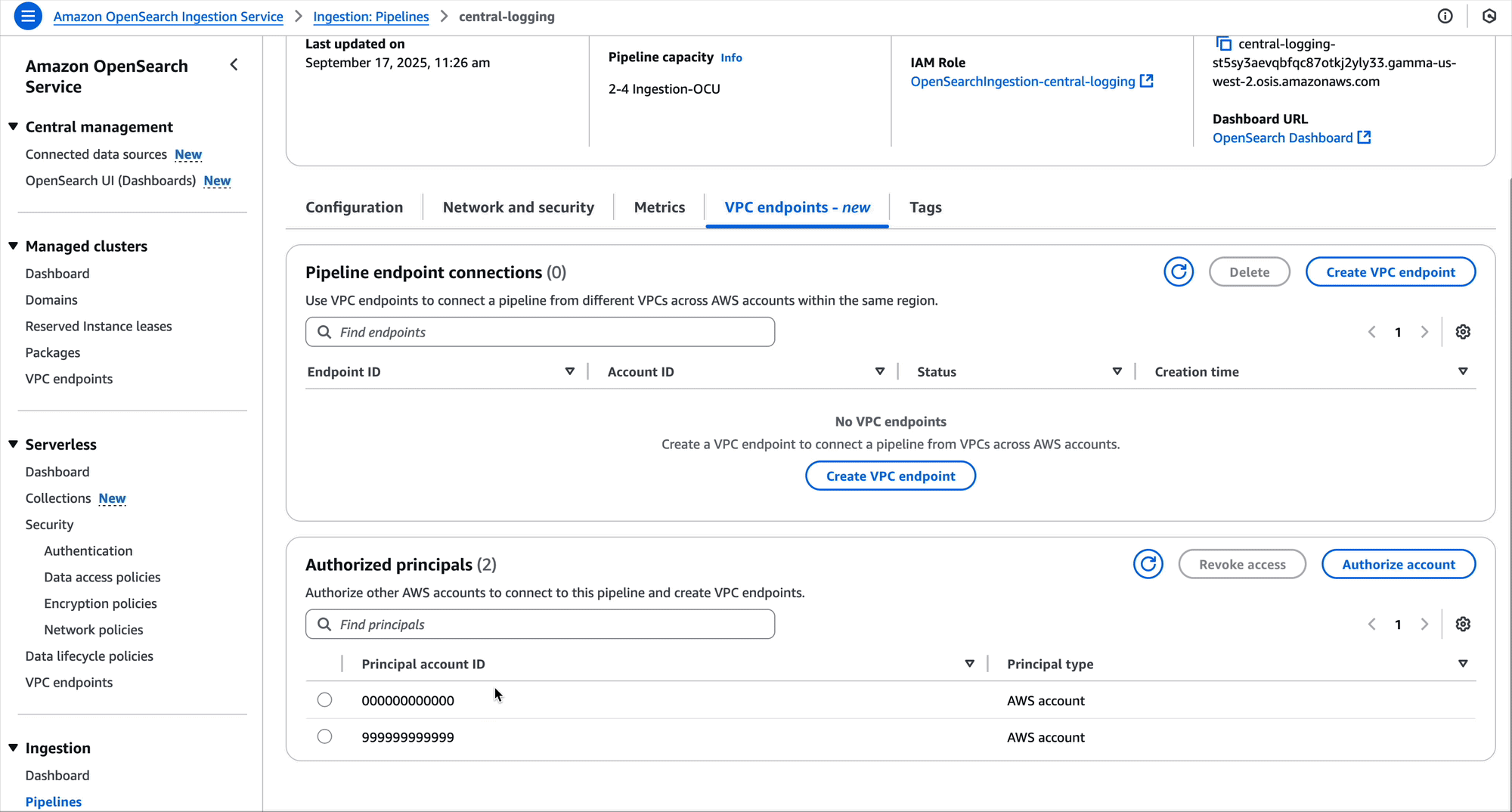
Create pipeline endpoint
Now that the central logging account has shared permissions on their pipeline, the development accounts can create pipeline endpoints. A pipeline endpoint is a connection from one VPC to an OpenSearch Ingestion pipeline.
The development accounts are responsible for creating the pipeline endpoints in the VPCs they want to connect from. They create this in the subnets they need and provide a security group. The security group should have an inbound rule allowing access port HTTPS over port 443 from any source that the development accounts need to ingest logs.
Development team A can create a pipeline endpoint using a command similar to the following:
Development team A can also use the OpenSearch Ingestion console to create the pipeline endpoint.
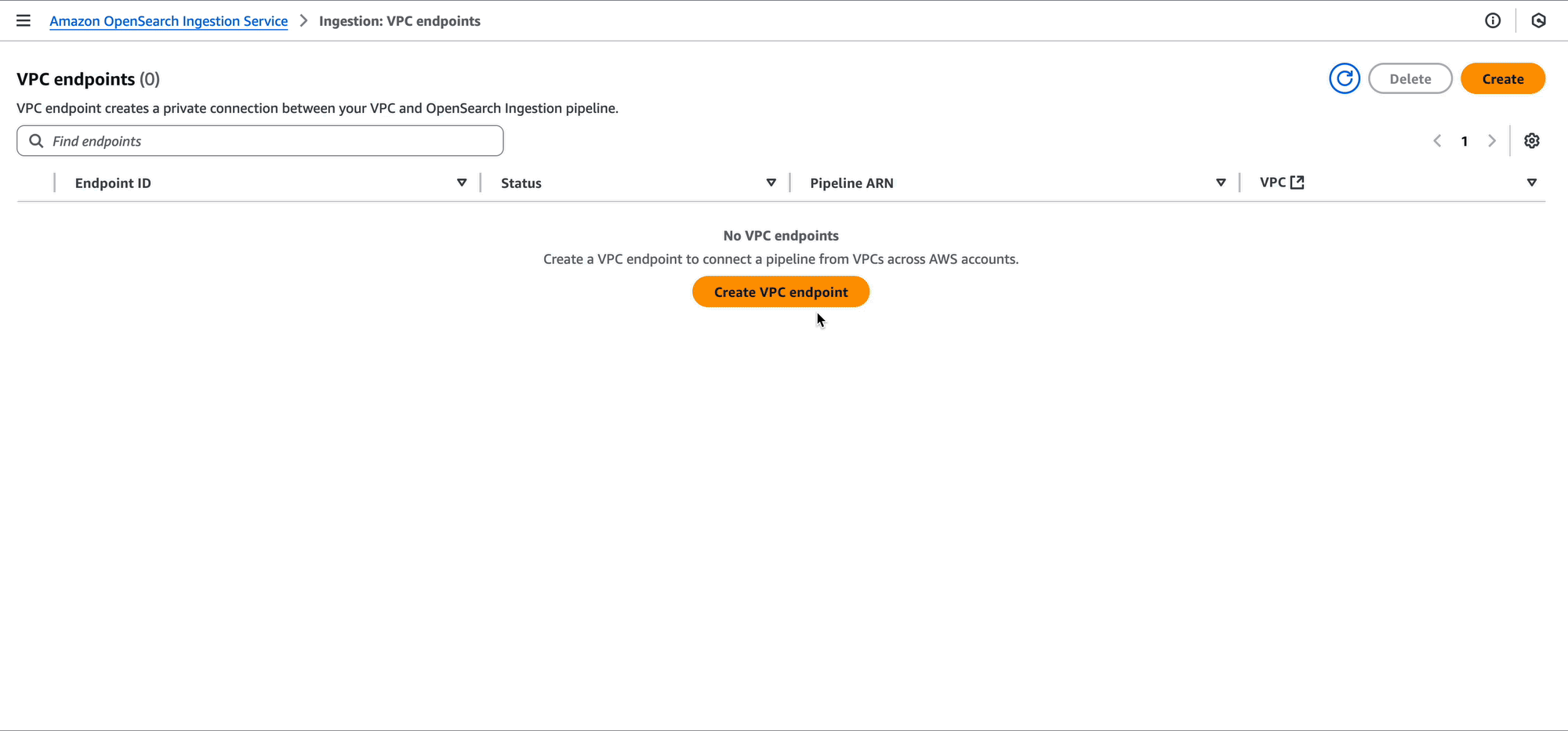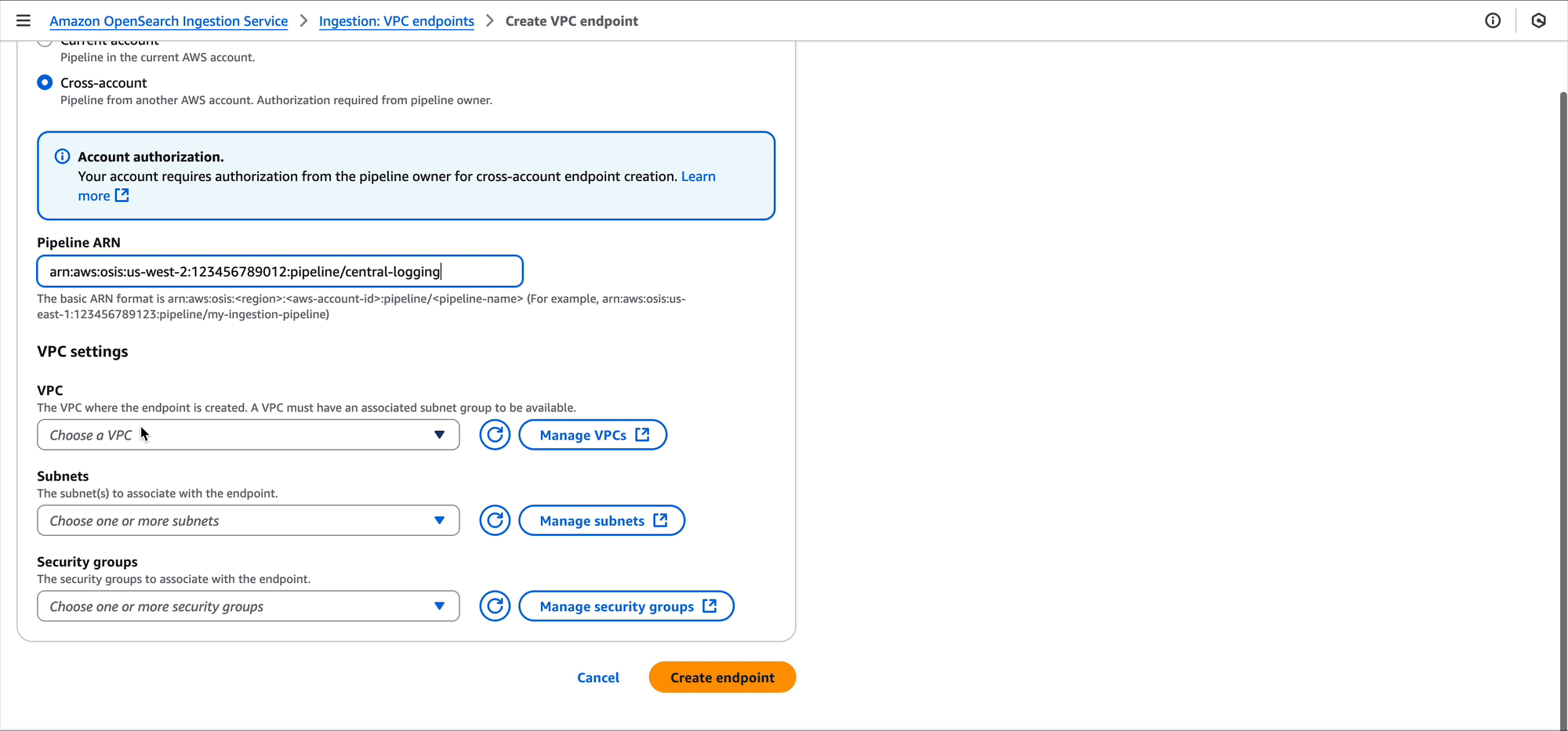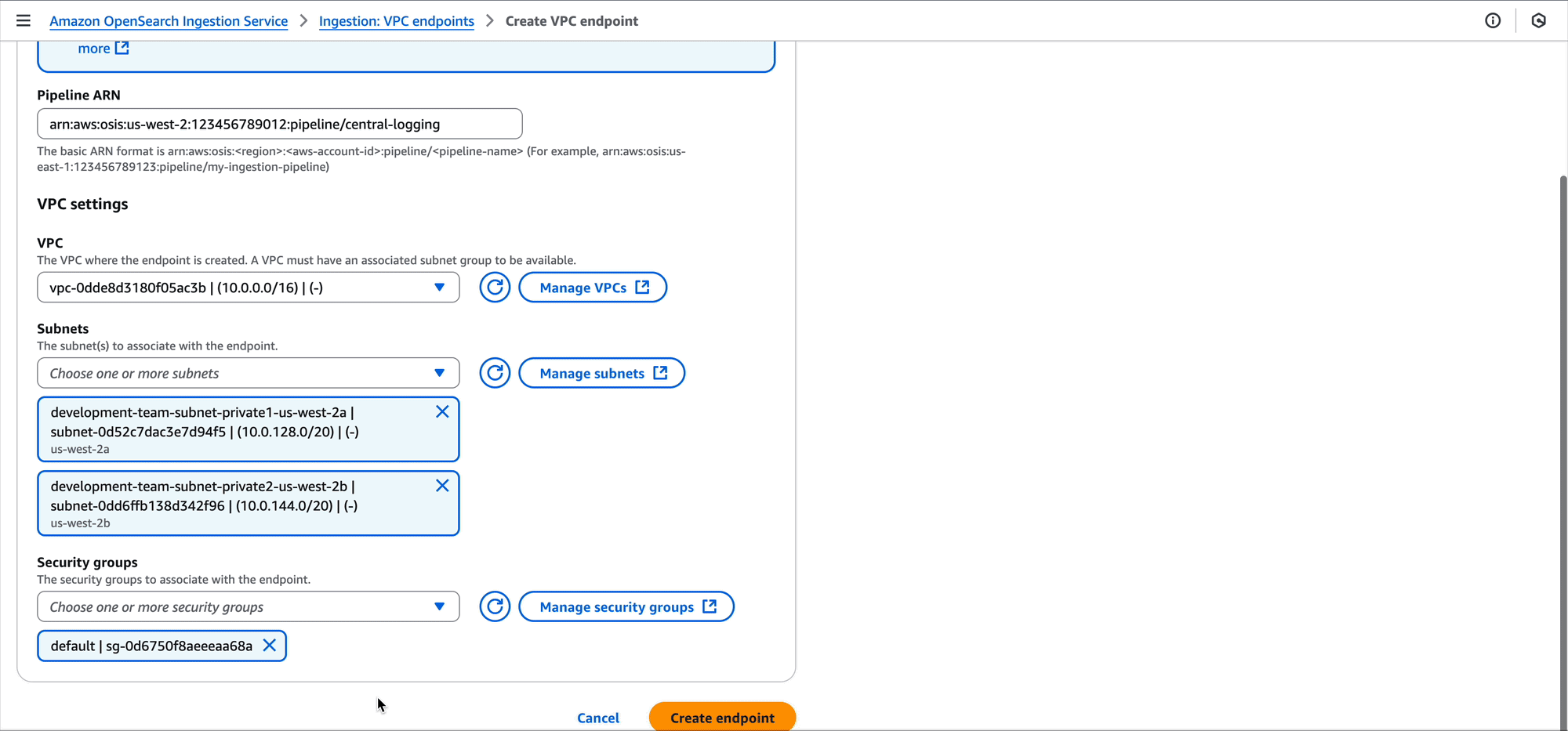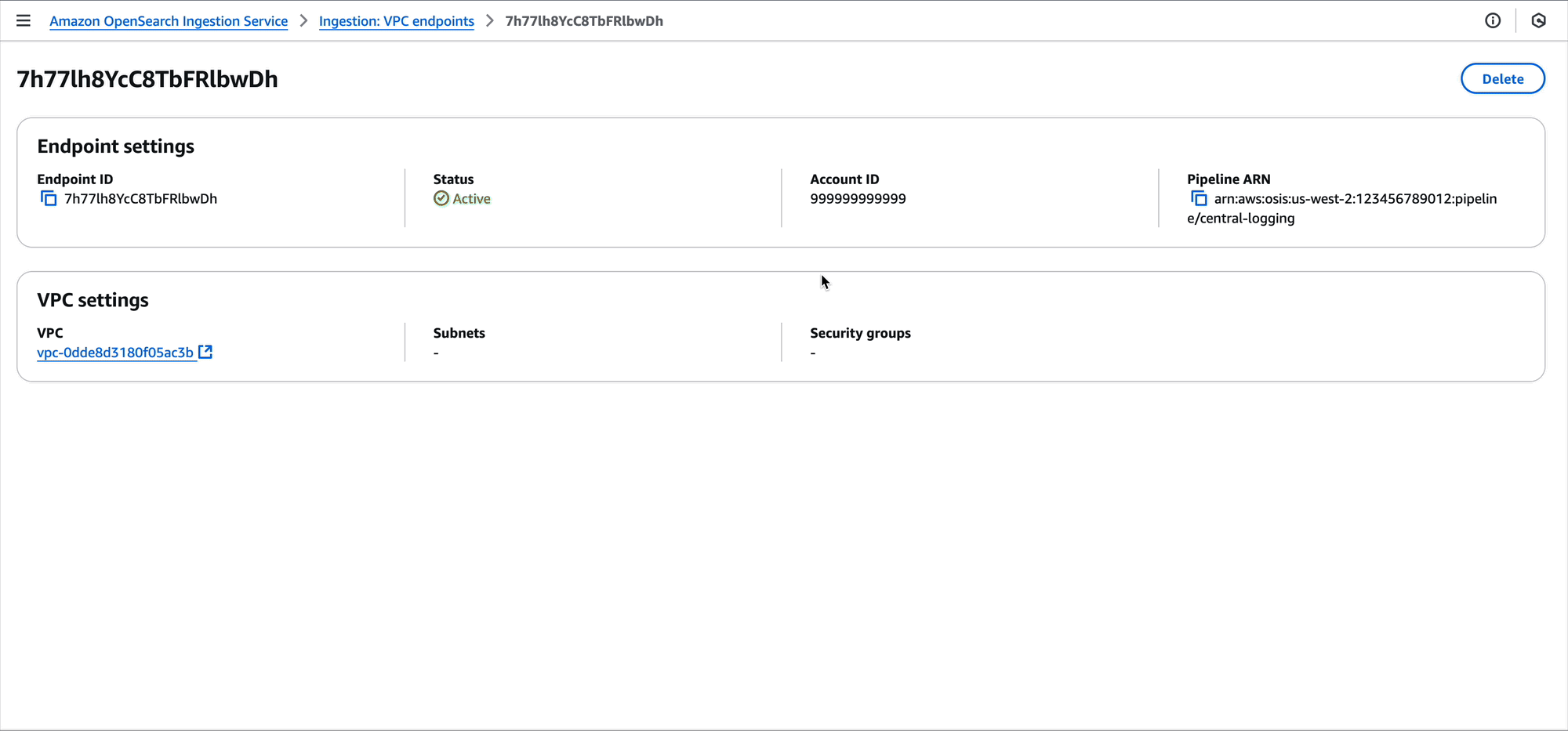
After performing this change, the VPC for development team A will have a pipeline endpoint. This pipeline endpoint now allows for ingesting data into the central logging pipeline. Now, Amazon Elastic Compute Cloud (Amazon EC2) instances, Amazon Elastic Container Service (Amazon ECS) tasks, Kubernetes pods, and other compute running in the VPC can ingest their log data into the pipeline using tools such as FluentBit.
At the same time or at a later time, development team B can create a pipeline endpoint as well. This team will create it for their own VPC.
After this, the pipeline will now have two pipeline endpoints, so both teams can ingest their log data into the central logging VPC.
Clean up
After a pipeline endpoint is created, either account can remove it. The development teams in our scenario can use the DeletePipelineEndpoint API to delete it from their accounts. Additionally, if the central logging account needs to remove a pipeline endpoint from a pipeline, it can use the RevokePipelineEndpointConnections API. Both options are available on the OpenSearch Ingestion console as well.
After the pipeline endpoints are removed, the central logging team can also remove the pipeline if they no longer need it.
Conclusion
The new pipeline endpoint feature for OpenSearch Ingestion simplifies how you can share pipelines for cross-account ingestion. This can help teams use the powerful features of OpenSearch Ingestion and open up new possibilities for teams or organizations using multiple accounts and VPCs. The new pipeline endpoint feature is available today in AWS Regions where OpenSearch Ingestion is available.
To get started with cross-account ingestion in OpenSearch Ingestion, refer to OpenSearch Ingestion documentation or try creating your first cross-account pipeline on the OpenSearch Ingestion console.