AWS Big Data Blog
Author: George Komninos

Create a most-recent view of your data lake using Amazon Redshift Serverless
Building a robust data lake is very beneficial because it enables organizations have a holistic view of their business and empowers data-driven decisions. The curated layer of a data lake is able to hydrate multiple homogeneous data products, unlocking limitless capabilities to address current and future requirements. However, some concepts of how data lakes work […]

Design and build a Data Vault model in Amazon Redshift from a transactional database
This blog post was updated in June, 2022 to update the entity relationship diagram. Building a highly performant data model for an enterprise data warehouse (EDW) has historically involved significant design, development, administration, and operational effort. Furthermore, the data model must be agile and adaptable to change while handling the largest volumes of data efficiently. […]
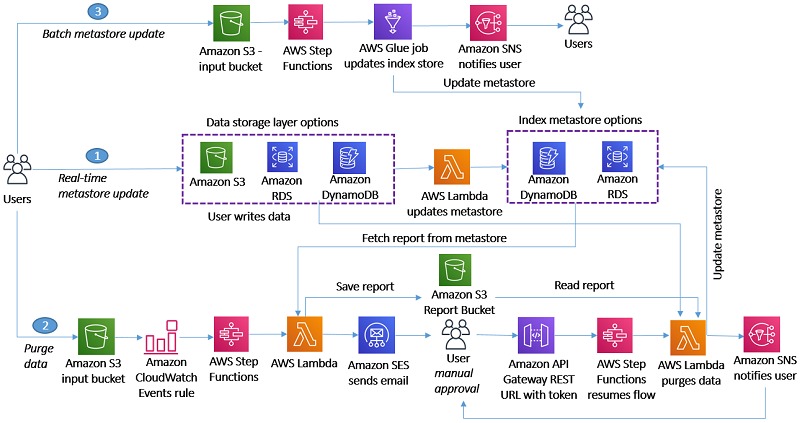
How to delete user data in an AWS data lake
General Data Protection Regulation (GDPR) is an important aspect of today’s technology world, and processing data in compliance with GDPR is a necessity for those who implement solutions within the AWS public cloud. One article of GDPR is the “right to erasure” or “right to be forgotten” which may require you to implement a solution […]