AWS Big Data Blog
Author: Karthik Prabhakar
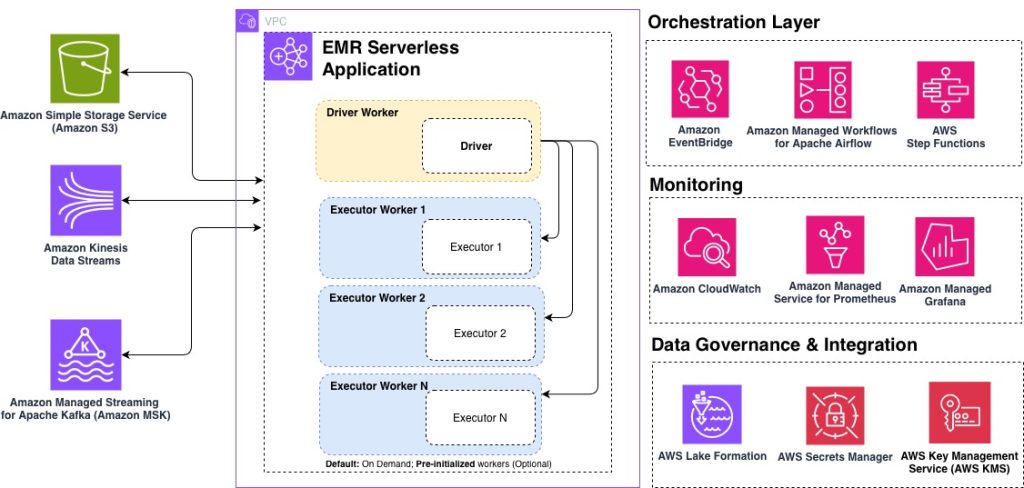
Top 10 best practices for Amazon EMR Serverless
Amazon EMR Serverless is a deployment option for Amazon EMR that you can use to run open source big data analytics frameworks such as Apache Spark and Apache Hive without having to configure, manage, or scale clusters and servers. Based on insights from hundreds of customer engagements, in this post, we share the top 10 best practices for optimizing your EMR Serverless workloads for performance, cost, and scalability. Whether you’re getting started with EMR Serverless or looking to fine-tune existing production workloads, these recommendations will help you build efficient, cost-effective data processing pipelines.

Amazon EMR Serverless eliminates local storage provisioning, reducing data processing costs by up to 20%
In this post, you’ll learn how Amazon EMR Serverless eliminates the need to configure local disk storage for Apache Spark workloads through a new serverless storage capability. We explain how this feature automatically handles shuffle operations, reduces data processing costs by up to 20%, prevents job failures from disk capacity constraints, and enables elastic scaling by decoupling storage from compute.

Achieve up to 27% better price-performance for Spark workloads with AWS Graviton2 on Amazon EMR Serverless
Amazon EMR Serverless is a serverless option in Amazon EMR that makes it simple to run applications using open-source analytics frameworks such as Apache Spark and Hive without configuring, managing, or scaling clusters. At AWS re:Invent 2022, we announced support for running serverless Spark and Hive workloads with AWS Graviton2 (Arm64) on Amazon EMR Serverless. […]