AWS Big Data Blog
Author: Suthan Phillips

Reduce EMR HBase upgrade downtime with the EMR read-replica prewarm feature
In this post, we show you how the read-replica prewarm feature of Amazon EMR 7.12 improves HBase cluster operations by minimizing the hard cutover constraints that make infrastructure changes challenging. This feature gives you a consistent blue-green deployment pattern that reduces risk and downtime for version upgrades and security patches.

Enhancing data durability in Amazon EMR HBase on Amazon S3 with the Amazon EMR WAL feature
In this post, we dive deep into the new Amazon EMR WAL feature to help you understand how it works, how it enhances durability, and why it’s needed. We explore several scenarios that are well-suited for this feature.

Build your Apache Hudi data lake on AWS using Amazon EMR – Part 1
Apache Hudi is an open-source transactional data lake framework that greatly simplifies incremental data processing and data pipeline development. It does this by bringing core warehouse and database functionality directly to a data lake on Amazon Simple Storage Service (Amazon S3) or Apache HDFS. Hudi provides table management, instantaneous views, efficient upserts/deletes, advanced indexes, streaming […]
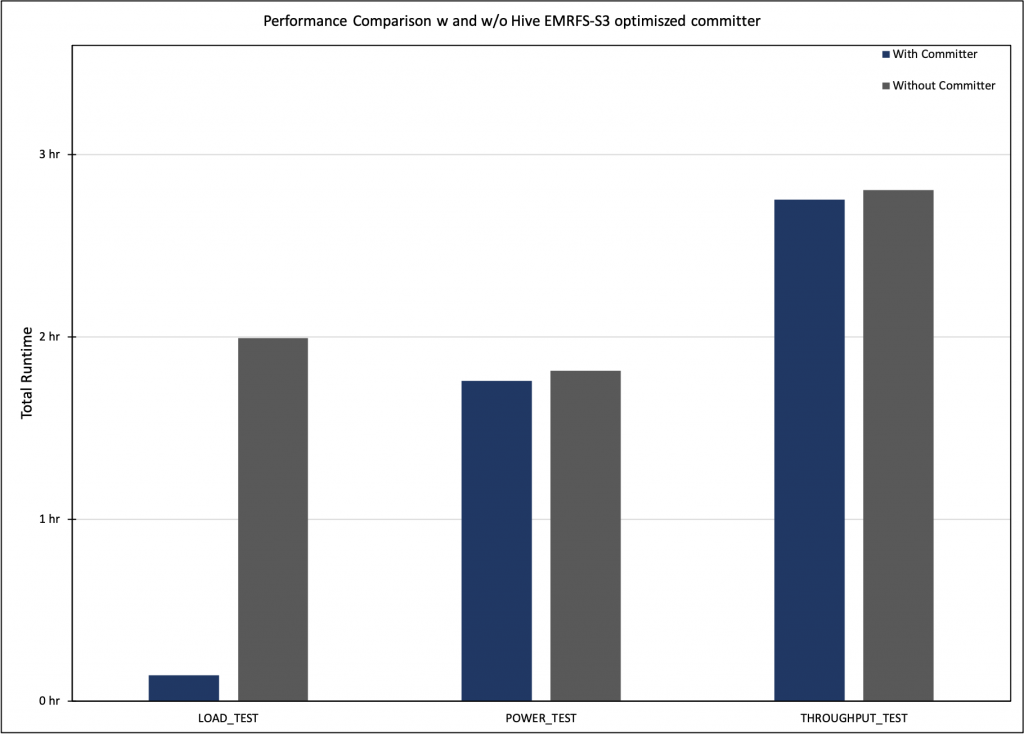
Up to 15 times improvement in Hive write performance with the Amazon EMR Hive zero-rename feature
Our customers use Apache Hive on Amazon EMR for large-scale data analytics and extract, transform, and load (ETL) jobs. Amazon EMR Hive uses Apache Tez as the default job execution engine, which creates Directed Acyclic Graphs (DAGs) to process data. Each DAG can contain multiple vertices from which tasks are created to run the application […]

Amazon EMR supports Apache Hive ACID transactions
December 2022: The best practice of using EMRFS consistent in this blog post is now obsolete as Amazon S3 has supported strong read-after-write consistency since December, 2020. Apache Hive is an open-source data warehouse package that runs on top of an Apache Hadoop cluster. You can use Hive for batch processing and large-scale data analysis. […]

Apache Hive is 2x faster with Hive LLAP on EMR 6.0.0
Customers use Apache Hive with Amazon EMR to provide SQL-based access to petabytes of data stored on Amazon S3. Amazon EMR 6.0.0 adds support for Hive LLAP, providing an average performance speedup of 2x over EMR 5.29, with up to 10x improvement on individual Hive TPC-DS queries. This post shows you how to enable Hive […]