AWS Big Data Blog
Build petabyte-scale synthetic test data with Amazon EMR on EC2
As you scale your data systems, you face a challenge: how to test thoroughly without putting customer data at risk. Using production data for testing can expose sensitive customer information to unauthorized access or breaches. For customers in regulated industries like finance and healthcare, this risk isn’t only a concern. It’s unacceptable. A data breach during testing could compromise their privacy, damage their trust, and expose organizations to significant compliance penalties. Synthetic test data solves this problem by generating artificial datasets that replicate the structure and patterns of real data without containing any actual customer information. This approach means you can test performance, validate data pipelines, and develop new features while ensuring that customer data remains protected and compliance requirements are met.
As data volumes grow from terabytes to petabytes, the architecture for generating synthetic data must evolve to meet increasing demands for scale, performance, and data quality. In this post, we show how you can build a scalable synthetic data generation solution using Amazon EMR, Apache Spark, and the Faker library.
The challenge of synthetic data generation
Traditional benchmark datasets like TPC-DS provide standardized schemas and predetermined data volumes for consistent testing environments across different systems. However, they fall short in meeting real-world testing requirements. These benchmarks don’t capture industry-specific patterns or the complex relationships found in actual production data. Their rigid schemas and simplified distributions fail to reflect business requirements, and scaling them while maintaining data consistency proves difficult. Perhaps most critically, generating massive datasets with traditional approaches requires specialized architectures to avoid proportional increases in compute costs and time.
Requirements for production-grade synthetic data
Effective workload validation demands synthetic data that mirrors production distributions while maintaining referential integrity across related tables and entities. The generation process must scale horizontally to accommodate growing data volumes while delivering deterministic results. Given identical input parameters, the system should produce the same dataset across multiple runs, supporting consistent testing cycles and comparative analysis.
Beyond technical requirements, synthetic data addresses compliance needs by minimizing exposure of personally identifiable information (PII) and protected health information (PHI) in non-production environments. This approach satisfies GDPR, HIPAA, and CCPA requirements while supporting secure cross-border data transfer, regular stress testing without compromising sensitive information, and providing an audit-friendly alternative to data masking that preserves analytical properties.
Solution overview
Architecting a synthetic data generation system that scales from terabytes to petabytes requires balancing several competing demands: the system must scale horizontally while maintaining data quality, generate large volumes efficiently, manage compute and storage resources cost-effectively, and support various schemas and output formats.
Our architecture addresses these challenges through four core components. Apache Spark on Amazon EMR provides the distributed computing framework necessary for large-scale generation. The Faker library offers synthetic data generation functions that integrate with Spark. Amazon Simple Storage Service (Amazon S3) with Apache Iceberg serves as the storage layer. We chose Iceberg for its schema and partition evolution capabilities without data rewrites, atomic transactions for consistency, precise time travel features for reproducible testing, and optimized performance at extreme scale. Amazon EMR handles dynamic resource allocation and cluster management.
The following diagram illustrates the solution architecture.
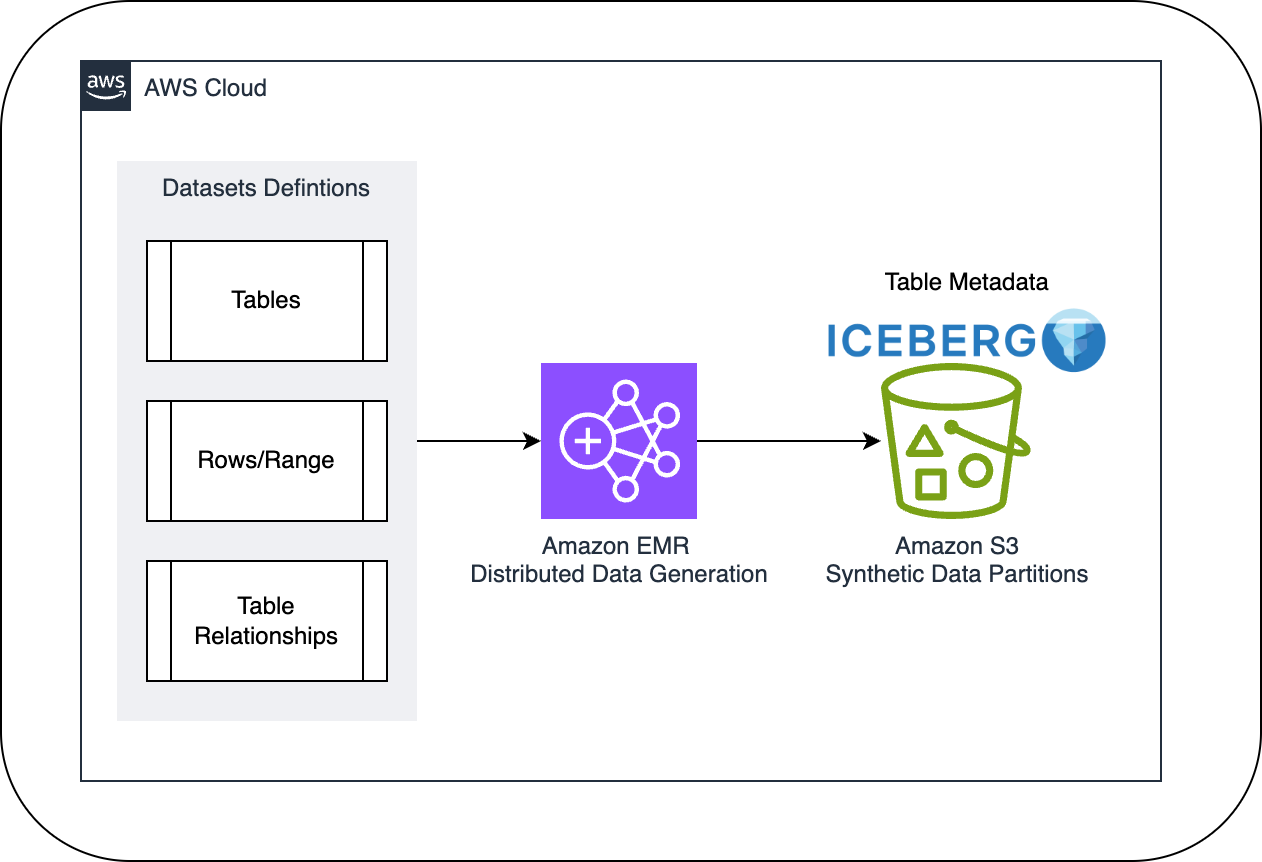
Synthetic data generation at scale with Amazon EMR
Amazon EMR emerges as a particularly powerful solution for this use case, offering several advantages that directly address our requirements. It facilitates scaling of compute resources through instance fleets and Spot Instances, which can reduce costs by up to 90% compared to On-Demand pricing. The service provides built-in performance optimization for Spark applications with real-time monitoring through Amazon CloudWatch integration.
The managed infrastructure reduces operational overhead by handling the underlying Spark ecosystem and cluster lifecycle, while still providing control over scaling policies, instance types, and configurations. Integration with Amazon S3, AWS Glue, and Amazon Athena facilitates end-to-end data generation and testing workflows. Support for multiple programming languages and notebooks provides flexibility in implementing generation logic tailored to specific testing scenarios.
The synthetic data generation process follows a systematic approach designed for efficiency and scalability, as illustrated in the following diagram.

Although synthetic data generation isn’t a sensitive workload, it’s important to maintain robust security throughout the data generation process. Amazon EMR provides security features that align with organizational compliance requirements.
For comprehensive security guidance specific to Amazon EMR deployments, refer to Security in Amazon EMR. The solution follows the AWS Shared Responsibility Model, where AWS manages the security of the cloud infrastructure, and customers maintain responsibility for data security, access management, and compliance controls in the cloud. Specifically for synthetic data generation workloads, AWS manages the security of the underlying Amazon EMR infrastructure, network, and service operations, and customers implement appropriate security controls for their data generation pipelines. Consider the following key areas:
- Data protection – Enable encryption at rest and in transit using Amazon EMR security configurations, including Amazon S3 encryption and TLS certificates for inter-node communication.
- Network security – Deploy Amazon EMR clusters in private subnets with security groups following least privilege, and enable the Amazon EMR block public access feature.
- Access control – Implement AWS Identity and Access Management (IAM) roles with least privilege for Amazon EMR service roles, Amazon Elastic Compute Cloud (Amazon EC2) instance profiles, and runtime roles to isolate job access. Fine-grained table-level and column-level permissions can be controlled using AWS Lake Formation. Additional authentication options are available using Kerberos and LDAP.
Optimize Faker for petabyte-scale data generation
When generating synthetic data at petabyte scale, using Faker’s implementations can quickly lead to performance bottlenecks. To overcome these limitations, adopt a combination of different optimization approaches instead of the default setup. Some of the approaches we adopted in this scenario are discussed in this section.
Faker instance pooling
The following code creates multiple Faker instances to avoid contention when generating data in parallel:
Consistent seed management
The following code provides reproducible data generation across distributed executors:
Random access to Faker pool
The following code distributes load across multiple Faker instances to reduce contention:
Broadcast variables for reference data
The following code efficiently distributes reference data to all executors:
Batch generation of synthetic data
The following code generates fake data in batches rather than one-by-one:
ThreadPoolExecutor for parallel processing
The following code uses Python’s threading for parallel operations within executors:
Optimize Amazon EMR and Spark
When processing massive datasets with Spark on Amazon EMR, carefully tuning configurations can substantially enhance performance beyond the standard settings. In this section, we discuss ways to optimize the execution environment, so you can efficiently handle petabyte-scale workloads with synthetic data generation. By strategically using Spark’s advanced features and configuring Amazon EMR for your specific use case, you can improve throughput, reduce processing time, and maximize resource utilization.
Arrow configuration
The following code enables Apache Arrow for efficient data transfer between Python and JVM. The default value is false.
Enable this configuration when your PySpark application frequently converts data between Python and JVM, especially for large DataFrames or when using Pandas operations. Keep this setting disabled for pure Spark SQL workloads or when memory is constrained.
This optimization is most effective in the following scenarios:
- When processing large-scale datasets that require frequent conversion between Python and JVM.
- In a PySpark application where large DataFrame operations and Pandas integration are needed.
- With data science workloads that combine Python UDFs with Spark SQL operations.
Consider the following trade-offs:
- Arrow maintains in-memory columnar format, resulting in increased memory consumption.
- Not all data types are fully supported in older versions of Spark.
- It might introduce overhead for very small datasets where conversion costs outweigh the benefits.
Adaptive query execution
The following code allows Spark to dynamically optimize query execution plans. The default value is true in Spark 3.2 and later, and false in earlier versions.
This optimization is generally recommended to keep enabled for most workloads. Consider disabling only when you have highly optimized, predictable queries where the adaptive overhead isn’t beneficial, or when troubleshooting query performance issues.
This optimization is most effective in the following scenarios:
- Complex join operations with unknown or skewed data distributions.
- Multi-stage queries where initial plans might be suboptimal.
- When processing data with changing characteristics over time.
Consider the following trade-offs:
- You may experience additional overhead during the query planning phase.
- You might occasionally choose suboptimal plans for certain edge cases.
Parallelism configuration
The following code sets appropriate parallelism for distributed data processing based on the volume of data you’re generating. The default value for spark.default.parallelism is the total number of cores on all executor nodes or 2, whichever larger. The default value for spark.sql.shuffle.partitions is 200.
Adjust this configuration when the default of 200 shuffle partitions creates too many small tasks (increase data volume) or too few large tasks (decrease for smaller datasets). Generally, aim for partition sizes of 100–200 MB. Modify default.parallelism when your RDD operations need different parallelism than the CPU-based default.
This optimization is most effective in the following scenarios:
- When generating consistent volumes of synthetic data across multiple runs.
- When you have predictable resource requirements.
- When you need to precisely control executor utilization.
Consider the following trade-offs:
- Static configuration might not adapt well to varying data volumes.
- Too many partitions can lead to task scheduling overhead.
- Too few partitions might cause memory pressure on executors.
Memory management
The following code optimizes memory allocation for execution and storage. The default value for spark.memory.fraction is 0.6, and for spark.memory.storageFraction is 0.5.
Increase memory.fraction from 0.6 to 0.8 when your workload is memory-intensive and you’re not using the JVM heap for other purposes. Adjust storageFraction based on your caching vs. execution memory needs. Decrease to 0.3 if you do minimal caching but have complex computations, and increase to 0.7 or higher for cache-heavy workloads.
This optimization is most effective in the following scenarios:
- Workloads that are memory-intensive and need fine-grained control.
- Workloads that balance between execution memory and cached data.
- During synthetic data generation that has many interdependent fields.
Consider the following trade-offs:
- Incorrect memory configuration can lead to frequent spills to disk or out-of-memory (OOM) errors.
- You might need to change the configuration to suit different workload characteristics.
- The settings must be monitored and tuned for optimal performance.
Limited Python UDF usage
The following code uses Spark’s built-in functions where possible instead of Python user-defined functions (UDFs). No additional configuration is needed. This is a coding practice.
We recommend using Spark functions over Python UDFs when the same functionality can be achieved. Use Python UDFs only when complex business logic can’t be expressed using Spark’s built-in functions, or when integrating with specialized Python libraries.
This optimization is most effective in the following scenarios:
- Simple transformations that can be performed using Spark functions.
- High-throughput workloads where serialization overhead needs to be minimized.
Consider the following trade-offs:
- This approach is less flexible compared to customer Python-based transformations or functions.
- You might need to use complex expressions to accomplish certain data patterns.
- There is a potential learning curve to familiarize yourself with Spark functions.
DataFrame caching
The following code caches frequently used DataFrames to avoid regenerating data. The default behavior doesn’t use caching. DataFrames are recomputed on each action.
Use this optimization to cache DataFrames that are accessed multiple times in your application. Monitor memory usage and use MEMORY_AND_DISK storage level for large DataFrames. Uncache DataFrames when they’re no longer needed to free memory.
This optimization is most effective in the following scenarios:
- When reusing reference data across multiple operations (can result in performance gains).
- For workloads where the same data is processed on multiple occasions.
Consider the following trade-offs:
- Too much caching might lead to memory process.
- Planning is required to manage cache in environments where memory is scarce.
Optimal partitioning
By default, Spark determines partitioning based on input data and previous operations. The following code makes sure data is properly distributed across executors:
Use repartition() when you need to increase partitions for better parallelism or support even data distribution. Use coalesce() when reducing partitions to avoid small files. Generally, target 100–200 MB per partition for optimal performance.
This optimization is most effective in the following scenarios:
- When controlling data distribution and avoiding data skew is very important.
- Before executing an expensive operation that will benefit from balanced data distribution.
- When optimizing downstream consumption use cases.
Consider the following trade-offs:
- This option is more expensive than
coalesce(). For large datasets,repartition()can lead to large shuffle. - The approach requires trial and experimentation to determine the optimal partition count.
- There is no “one-size-fits-all” setting. Different applications or operations might gain performance with different partitioning.
Partition-aware writing
By default, data is written without partitioning. The following code organizes data for efficient storage and retrieval:
Partition data when you have predictable query patterns that filter on specific columns. Choose partition columns that are frequently used in WHERE clauses and have reasonable cardinality (avoid too many small partitions or too few large ones).
This optimization offers the following benefits:
- Allows for highly parallel write operation across multiple executors.
- Organizes the data that is close to real-world production data.
- Allows for partition pruning when querying the data.
Consider the following trade-offs:
- Excess partitioning or too fine-grained partitioning might result in small files.
- It might result in data skew because of hot partitions.
- You might encounter storage and metadata overhead because of excessive partitions.
Best practices
Through our journey from terabytes to petabytes, we’ve identified several best practices:
- Begin with a modest dataset and incrementally scale, allowing for identification of bottlenecks at each stage.
- Implement robust data validation checks to confirm synthetic data maintains expected properties at scale.
- Regularly review and adjust Amazon EMR configurations, using Spot Instances and right-sizing clusters.
- Develop parameterized job scripts that can adjust data volume, complexity, and cluster resources dynamically.
- Design your synthetic data schema and generation logic to quickly accommodate new fields or changing distributions over time.
Conclusion
Our journey from terabytes to petabytes of synthetic data generation demonstrates how Amazon EMR, combined with Spark and Faker, can effectively address large-scale testing needs. The architecture we explored in this post scales to meet demanding data generation requirements while maintaining data quality and cost-efficiency.
We showed how starting with a solid foundation at terabyte scale, then gradually expanding through Amazon EMR managed services and Spot Instances, helps organizations build robust synthetic data pipelines. The combination of efficient data generation techniques, proper validation, and continuous monitoring provides reliable results at scale.
To begin implementing your own synthetic data generation system, start small, test thoroughly, and scale incrementally. For implementation guidance, refer to Generate production-grade synthetic data at petabyte-scale using Apache Spark and Faker on Amazon EMR.