AWS Big Data Blog
Easily manage table metadata for Presto running on Amazon EMR using the AWS Glue Data Catalog
Amazon EMR empowers many customers to build big data processing applications quickly and cost-effectively, using popular distributed frameworks such as Apache Spark, Apache HBase, Presto, and Apache Flink. For organizations that are crafting their analytical applications on Amazon EMR, there is a growing need to keep their data assets organized in an automated fashion. Because datasets tend to grow exponentially, using cataloging tools is essential to automating data discovery and organizing data assets.
AWS Glue Data Catalog provides this essential capability, allowing you to automatically discover and catalog metadata about your data stores in a central repository. Since Amazon EMR 5.8.0, customers have been using the AWS Glue Data Catalog as a metadata store for Apache Hive and Spark SQL applications that are running on Amazon EMR. Starting with Amazon EMR 5.10.0, you can catalog datasets using AWS Glue and run queries using Presto on Amazon EMR from the Hue (Hadoop User Experience) and Apache Zeppelin UIs.
You might wonder what scenarios warrant using Presto running on Amazon EMR and when to choose Amazon Athena (which uses Presto as the query engine under the hood). It is important to note that both are excellent tools for querying massive amounts of data and addressing different needs and use cases.
Amazon Athena provides the easiest way to run interactive queries for data in Amazon S3 without needing to set up or manage any servers. Presto running on Amazon EMR gives you much more flexibility in how you configure and run your queries, providing the ability to federate to other data sources if needed. For example, you might have a use case that requires LDAP authentication for clients such as the Presto CLI or JDBC/ODBC drivers. Or you might have a workflow where you need to join data between different systems like MySQL/Amazon Redshift/Apache Cassandra and Hive. In these examples, Presto running on Amazon EMR is the right tool to use because it can be configured to enable LDAP authentication in addition to the desired database connectors at cluster launch.
Now, let’s look at how metadata management for Presto works with AWS Glue.
Using an AWS Glue crawler to discover datasets
The AWS Glue Data Catalog is a reference to the location, schema, and runtime metrics of your datasets. To create this reference metadata, AWS Glue needs to crawl your datasets. In this exercise, we use an AWS Glue crawler to populate tables in the Data Catalog for the NYC taxi rides dataset.
The following are the steps for adding a crawler:
- Sign in to the AWS Management Console, and open the AWS Glue console. In the navigation pane, choose Crawlers. Then choose Add crawler.
- On the Add a data store page, specify the location of the NYC taxi rides dataset.
- In the next step, choose an existing IAM role if one is available, or create a new role. Then choose Next.
- On the scheduling page, for Frequency, choose Run on demand.
- On the Configure the crawler’s output page, choose Add database. Specify blog-db as the database name. (You can specify a name of your choice, but be sure to choose the correct database name when running queries.)
- Follow the remaining steps using the default values to create a crawler.

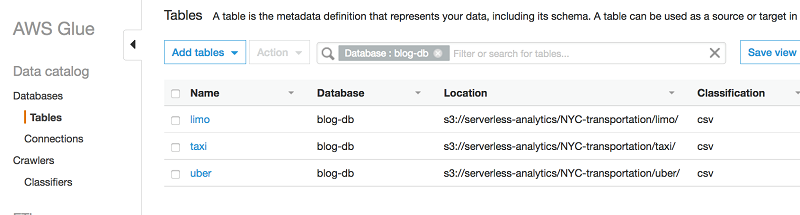
- When the crawler displays the Ready state, navigate to the Databases (Choose blog-db from the list of databases, or search for it by specifying it as a filter, as shown in the following screenshot.) Then choose Tables. You should see the three tables created by the crawler, as follows.
- (Optional) The discovered data is classified as CSV files. You can optionally convert this data into Parquet format for better response times on your queries.
Launching an Amazon EMR cluster
With the dataset discovered and organized, we can now walk through different options for launching Presto on an Amazon EMR cluster to use the AWS Glue Data Catalog.
Option 1: From the Amazon EMR console
- On the Amazon EMR console, choose Create cluster.
- In Create Cluster – Quick Options, choose EMR release 10.0 or greater.
- Choose Presto as an application.
- Under AWS Glue Data Catalog settings, select Use for Presto table metadata.
Option 2: From the AWS CLI
- Create a classification configuration as shown following, and save it as a JSON file (presto-emr-config.json).
- Create the cluster using the AWS CLI as follows:
Running queries with Presto on Amazon EMR
After you’ve set up the Amazon EMR cluster with Presto, the AWS Glue Data Catalog is available through a default “hive” catalog. To change between the Hive and Glue metastores, you have to manually update hive.properties and restart the Presto server. Connect to the master node on your EMR cluster using SSH, and run the Presto CLI to start running queries interactively.
Begin with a simple query to sample a few rows:
The query shows a few sample rows as follows:

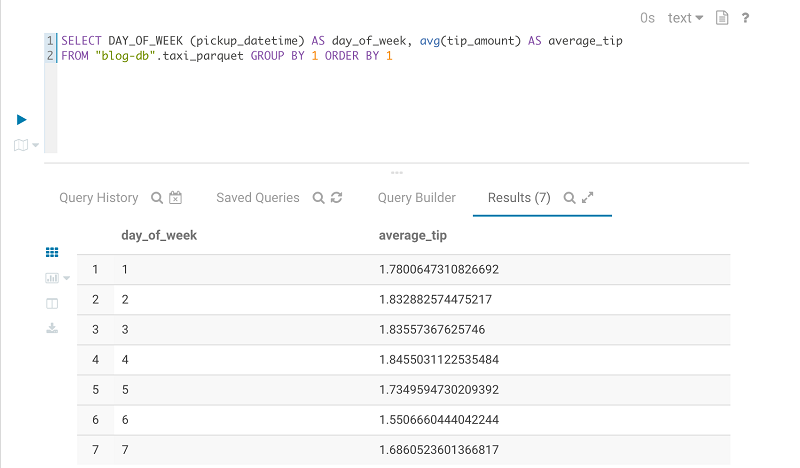
Query the average fare for trips at each hour of the day and for each day of the month on the Parquet version of the taxi dataset.
The following image shows the results:

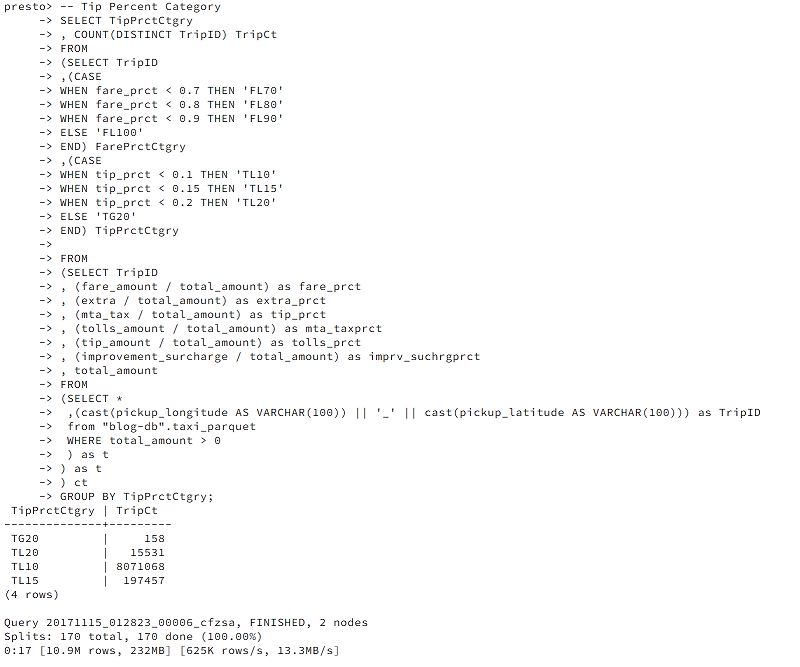
More interestingly, you can compute the number of trips that gave tips in the 10 percent, 15 percent, or higher percentage range:
The results are as follows:
While the preceding query is running, navigate to the web interface for Presto on Amazon EMR at <http://master-public-dns-name:8889/. Here you can look into the query metrics, such as active worker nodes, number of rows read per second, reserved memory, and parallelism.
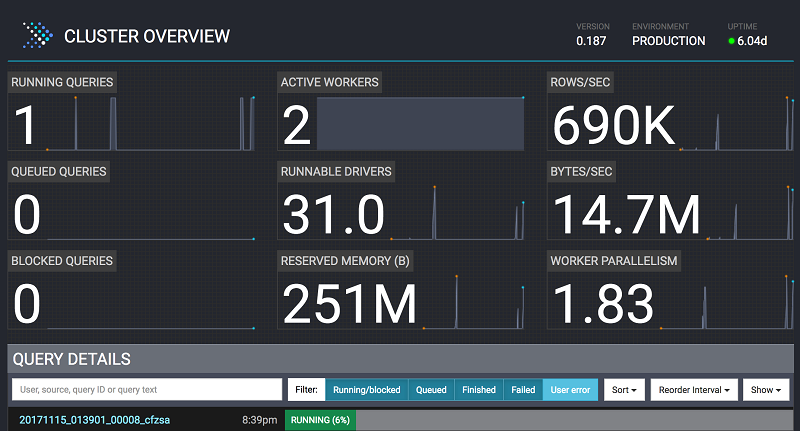
Running queries in the Presto Editor on Hue
If you installed Hue with your Amazon EMR launch, you can also run queries on Hue’s Presto Editor. On the Amazon EMR Cluster console, choose Enable Web Connection, and follow the instructions to access the web interfaces for Hue and Zeppelin.

After the web connection is enabled, choose the Hue link to open the web interface. At the login screen, if you are the administrator logging in for the first time, type a user name and password to create your Hue superuser account. Then choose Create account. Otherwise, type your user name and password and choose Create account, or type the credentials provided by your administrator.

Choose the Presto Editor from the menu. You can run Presto queries against your tables in the AWS Glue Data Catalog.
Conclusion
Having a shared data catalog for applications on Amazon EMR alleviates a myriad of data-related challenges that organizations face today—including discovery, governance, auditability, and collaboration. In this post, we explored how the AWS Glue Data Catalog addresses discoverability and manageability for table metadata for Presto on Amazon EMR. Go ahead, give this a try, and share your experience with us!
![]()
Additional Reading
If you found this post useful, be sure to check out Custom Log Presto Query Events on Amazon EMR for Auditing and Performance Insights and Build a Multi-Tenant Amazon EMR Cluster with Kerberos, Microsoft Active Directory Integration and EMRFS Authorization.

About the Author
 Radhika Ravirala is a Solutions Architect at Amazon Web Services where she helps customers craft distributed big data applications on the AWS platform. Prior to her cloud journey, she worked as a software engineer and designer for technology companies in Silicon Valley. She holds a M.S in computer science from San Jose State University.
Radhika Ravirala is a Solutions Architect at Amazon Web Services where she helps customers craft distributed big data applications on the AWS platform. Prior to her cloud journey, she worked as a software engineer and designer for technology companies in Silicon Valley. She holds a M.S in computer science from San Jose State University.