AWS Big Data Blog
How Hudl built a cost-optimized AWS Glue pipeline with Apache Hudi datasets
This is a guest blog post co-written with Addison Higley and Ramzi Yassine from Hudl.
Hudl Agile Sports Technologies, Inc. is a Lincoln, Nebraska based company that provides tools for coaches and athletes to review game footage and improve individual and team play. Its initial product line served college and professional American football teams. Today, the company provides video services to youth, amateur, and professional teams in American football as well as other sports, including soccer, basketball, volleyball, and lacrosse. It now serves 170,000 teams in 50 different sports around the world. Hudl’s overall goal is to capture and bring value to every moment in sports.
Hudl’s mission is to make every moment in sports count. Hudl does this by expanding access to more moments through video and data and putting those moments in context. Our goal is to increase access by different people and increase context with more data points for every customer we serve. Using data to generate analytics, Hudl is able to turn data into actionable insights, telling powerful stories with video and data.
To best serve our customers and provide the most powerful insights possible, we need to be able to compare large sets of data between different sources. For example, enriching our MongoDB and Amazon DocumentDB (with MongoDB compatibility) data with our application logging data leads to new insights. This requires resilient data pipelines.
In this post, we discuss how Hudl has iterated on one such data pipeline using AWS Glue to improve performance and scalability. We talk about the initial architecture of this pipeline, and some of the limitations associated with this approach. We also discuss how we iterated on that design using Apache Hudi to dramatically improve performance.
Problem statement
A data pipeline that ensures high-quality MongoDB and Amazon DocumentDB statistics data is available in our central data lake, and is a requirement for Hudl to be able to deliver sports analytics. It’s important to maintain the integrity of the data between MongoDB and Amazon DocumentDB transactional data with the data lake capturing changes in near-real time along with upserts to records in the data lake. Because Hudl statistics are backed by MongoDB and Amazon DocumentDB databases, in addition to a broad range of other data sources, it’s important that relevant MongoDB and Amazon DocumentDB data is available in a central data lake where we can run analytics queries to compare statistics data between sources.
Initial design
The following diagram demonstrates the architecture of our initial design.

Let’s discuss the key AWS services of this architecture:
- AWS Data Migration Service (AWS DMS) allowed our team to move quickly in delivering this pipeline. AWS DMS gives our team a full snapshot of the data, and also offers ongoing change data capture (CDC). By combining these two datasets, we can ensure our pipeline delivers the latest data.
- Amazon Simple Storage Service (Amazon S3) is the backbone of Hudl’s data lake because of its durability, scalability, and industry-leading performance.
- AWS Glue allows us to run our Spark workloads in a serverless fashion, with minimal setup. We chose AWS Glue for its ease of use and speed of development. Additionally, features such as AWS Glue bookmarking simplified our file management logic.
- Amazon Redshift offers petabyte-scale data warehousing. Amazon Redshift provides consistently fast performance, and easy integrations with our S3 data lake.
The data processing flow includes the following steps:
- Amazon DocumentDB holds the Hudl statistics data.
- AWS DMS gives us a full export of statistics data from Amazon DocumentDB, and ongoing changes in the same data.
- In the S3 Raw Zone, the data is stored in JSON format.
- An AWS Glue job merges the initial load of statistics data with the changed statistics data to give a snapshot of statistics data in JSON format for reference, eliminating duplicates.
- In the S3 Cleansed Zone, the JSON data is normalized and converted to Parquet format.
- AWS Glue uses a COPY command to insert Parquet data into Amazon Redshift consumption base tables.
- Amazon Redshift stores the final table for consumption.
The following is a sample code snippet from the AWS Glue job in the initial data pipeline:
Challenges
Although this initial solution met our need for data quality, we felt there was room for improvement:
- The pipeline was slow – The pipeline ran slowly (over 2 hours) because for each batch, the whole dataset was compared. Every record had to be compared, flattened, and converted to Parquet, even when only a few records were changed from the previous daily run.
- The pipeline was expensive – As the data size grew daily, the job duration also grew significantly (especially in step 4). To mitigate the impact, we needed to allocate more AWS Glue DPUs (Data Processing Units) to scale the job, which led to higher cost.
- The pipeline limited our ability to scale – Hudl’s data has a long history of rapid growth with increasing customers and sporting events. Given this trend, our pipeline needed to run as efficiently as possible to handle only changing datasets to have predictable performance.
New design
The following diagram illustrates our updated pipeline architecture.
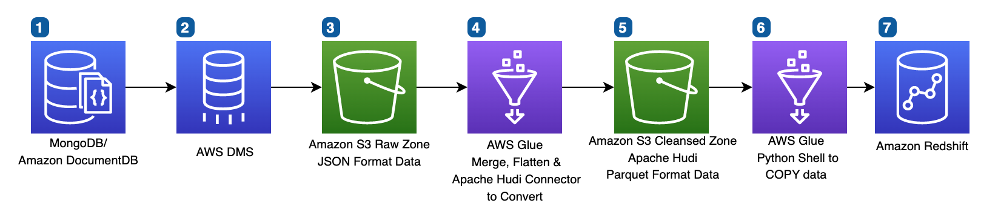
Although the overall architecture looks roughly the same, the internal logic in AWS Glue was significantly changed, along with addition of Apache Hudi datasets.
In step 4, AWS Glue now interacts with Apache HUDI datasets in the S3 Cleansed Zone to upsert or delete changed records as identified by AWS DMS CDC. The AWS Glue to Apache Hudi connector helps convert JSON data to Parquet format and upserts into the Apache HUDI dataset. Retaining the full documents in our Apache HUDI dataset allows us to easily make schema changes to our final Amazon Redshift tables without needing to re-export data from our source systems.
The following is a sample code snippet from the new AWS Glue pipeline:
Results
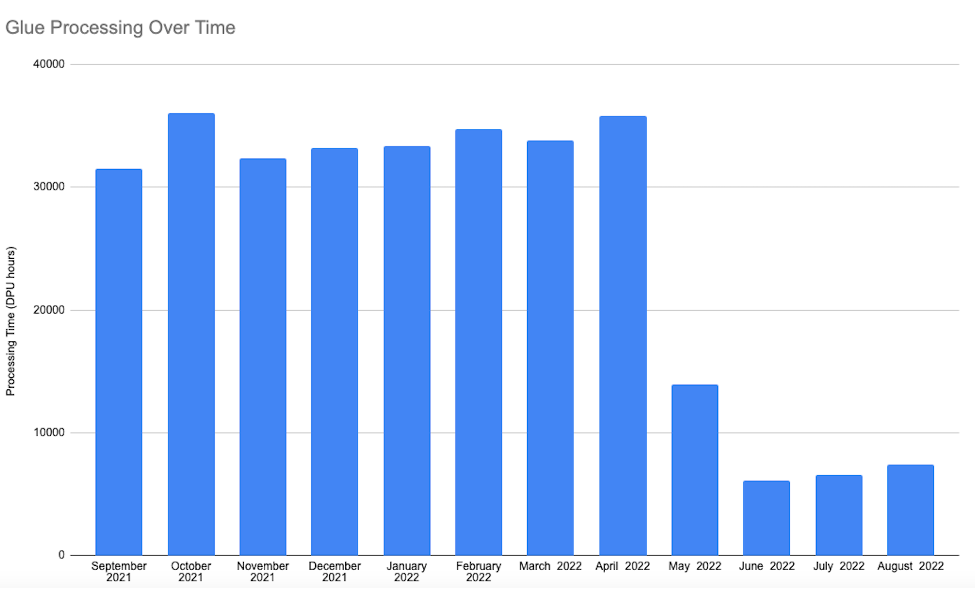
With this new approach using Apache Hudi datasets with AWS Glue deployed after May 2022, the pipeline runtime was predictable and less expensive than the initial approach. Because we only handled new or modified records by eliminating the full outer join over the entire dataset, we saw an 80–90% reduction in runtime for this pipeline, thereby reducing costs by 80–90% compared to the initial approach. The following diagram illustrates our processing time before and after implementing the new pipeline.
Conclusion
With Apache Hudi’s open-source data management framework, we simplified incremental data processing in our AWS Glue data pipeline to manage data changes at the record level in our S3 data lake with CDC from Amazon DocumentDB.
We hope that this post will inspire your organization to build AWS Glue pipelines with Apache Hudi datasets that reduce cost and bring performance improvements using serverless technologies to achieve your business goals.
About the authors
 Addison Higley is a Senior Data Engineer at Hudl. He manages over 20 data pipelines to help ensure data is available for analytics so Hudl can deliver insights to customers.
Addison Higley is a Senior Data Engineer at Hudl. He manages over 20 data pipelines to help ensure data is available for analytics so Hudl can deliver insights to customers.
 Ramzi Yassine is a Lead Data Engineer at Hudl. He leads the architecture, implementation of Hudl’s data pipelines and data applications, and ensures that our data empowers internal and external analytics.
Ramzi Yassine is a Lead Data Engineer at Hudl. He leads the architecture, implementation of Hudl’s data pipelines and data applications, and ensures that our data empowers internal and external analytics.
 Swagat Kulkarni is a Senior Solutions Architect at AWS and an AI/ML enthusiast. He is passionate about solving real-world problems for customers with cloud-native services and machine learning. Swagat has over 15 years of experience delivering several digital transformation initiatives for customers across multiple domains, including retail, travel and hospitality, and healthcare. Outside of work, Swagat enjoys travel, reading, and meditating.
Swagat Kulkarni is a Senior Solutions Architect at AWS and an AI/ML enthusiast. He is passionate about solving real-world problems for customers with cloud-native services and machine learning. Swagat has over 15 years of experience delivering several digital transformation initiatives for customers across multiple domains, including retail, travel and hospitality, and healthcare. Outside of work, Swagat enjoys travel, reading, and meditating.
 Indira Balakrishnan is a Principal Solutions Architect in the AWS Analytics Specialist SA Team. She is passionate about helping customers build cloud-based analytics solutions to solve their business problems using data-driven decisions. Outside of work, she volunteers at her kids’ activities and spends time with her family.
Indira Balakrishnan is a Principal Solutions Architect in the AWS Analytics Specialist SA Team. She is passionate about helping customers build cloud-based analytics solutions to solve their business problems using data-driven decisions. Outside of work, she volunteers at her kids’ activities and spends time with her family.