AWS Big Data Blog
Optimize Amazon EMR runtime for Apache Spark with EMR S3A
With the Amazon EMR 7.10 runtime, Amazon EMR has introduced EMR S3A, an improved implementation of the open source S3A file system connector. This enhanced connector is now automatically set as the default S3 file system connector for Amazon EMR deployment options, including Amazon EMR on EC2, Amazon EMR Serverless, Amazon EMR on Amazon EKS, and Amazon EMR on AWS Outposts, maintaining complete API compatibility with open source Apache Spark.
In the Amazon EMR 7.10 runtime for Apache Spark, the EMR S3A connector exhibits performance comparable to EMRFS for read workloads, as demonstrated by TPC-DS query benchmark. The connector’s most significant performance gains are evident in write operations, with a 7% improvement in static partition overwrites and a 215% improvement for dynamic partition overwrites when compared to EMRFS. In this post, we showcase the enhanced read and write performance advantages of using Amazon EMR 7.10.0 runtime for Apache Spark with EMR S3A as compared to EMRFS and the open source S3A file system connector.
Read workload performance comparison
To evaluate the read performance, we used a test environment based on Amazon EMR runtime version 7.10.0 running Spark 3.5.5 and Hadoop 3.4.1. Our testing infrastructure featured an Amazon Elastic Compute Cloud (Amazon EC2) cluster comprised of nine r5d.4xlarge instances. The primary node has 16 vCPU and 128 GB memory, and the eight core nodes have a total of 128 vCPU and 1024 GB memory.
The performance evaluation was conducted using a comprehensive testing methodology designed to provide accurate and meaningful results. For the source data, we chose the 3 TB scale factor, which contains 17.7 billion records, approximately 924 GB of compressed data partitioned in Parquet file format. The setup instructions and technical details can be found in the GitHub repository. We used Spark’s in-memory data catalog to store metadata for TPC-DS databases and tables.
To produce a fair and accurate comparison between EMR S3A vs. EMRFS and open source S3A implementations, we implemented a three-phase testing approach:
- Phase 1: Baseline performance:
- Established a baseline using default Amazon EMR configuration with EMR’s S3A connector
- Created a reference point for subsequent comparisons
- Phase 2: EMRFS analysis:
- Maintained the default file system as EMRFS
- Preserved other configuration settings
- Phase 3: Open source S3A testing:
- Modified only the
hadoop-aws.jarfile by replacing it with the open source Hadoop S3A 3.4.1 version - Maintained identical configurations across other components
- Modified only the
This controlled testing environment was crucial for our evaluation for the following reasons:
- We could isolate the performance impact specifically to the S3A connector implementation
- It removed potential variables that could skew the results
- It provided accurate measurements of performance improvements between Amazon’s S3A implementation and the open source alternative
Test execution and results
Throughout the testing process, we maintained consistency in test conditions and configurations, making sure any observed performance differences could be directly attributed to the S3A connector implementation variations. A total of 104 SparkSQL queries were run in 10 iterations sequentially, and an average of each query’s runtime in these 10 iterations was used for comparison. The average of the 10 iterations’ runtime on the Amazon EMR 7.10 runtime for Apache Spark with EMR S3A was 1116.87 seconds, which is 1.08 times faster than open source S3A and comparable with EMRFS. The following figure illustrates the total runtime in seconds.
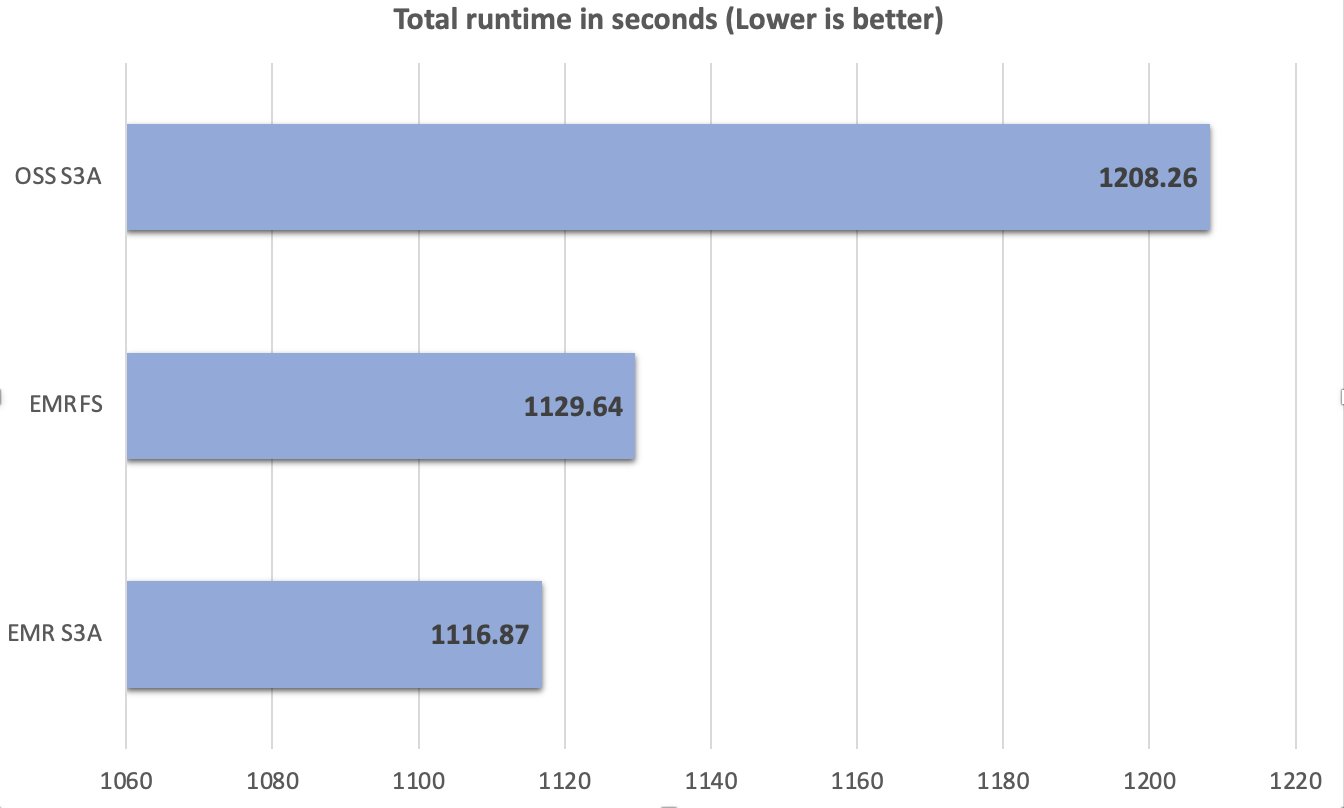
The following table summarizes the metrics.
| Metric | OSS S3A | EMRFS | EMR S3A |
| Average runtime in seconds | 1208.26 | 1129.64 | 1116.87 |
| Geometric mean over queries in seconds | 7.63 | 7.09 | 6.99 |
| Total cost * | $6.53 | $6.40 | $6.15 |
*Detailed cost estimates are discussed later in this post.
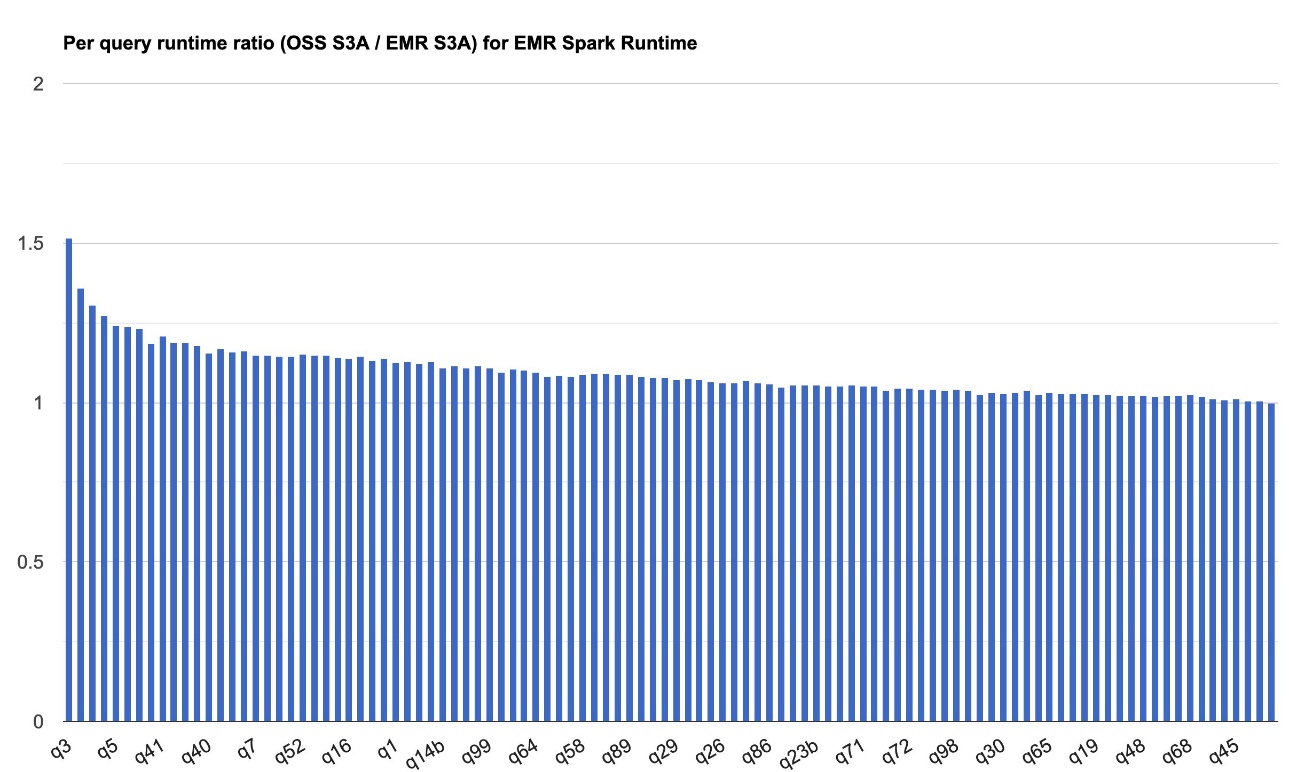
The following chart demonstrates the per-query performance improvement of EMR S3A relative to open source S3A on the Amazon EMR 7.10 runtime for Apache Spark. The extent of the speedup varies from one query to another, with the fastest up to 1.51 times faster for q3, with Amazon EMR S3A outperforming open source S3A. The horizontal axis arranges the TPC-DS 3TB benchmark queries in descending order based on the performance improvement seen with Amazon EMR, and the vertical axis depicts the magnitude of this speedup as a ratio.
Read cost comparison
Our benchmark outputs the total runtime and geometric mean figures to measure the Spark runtime performance. The cost metric can provide us with additional insights. Cost estimates are computed using the following formulas. They factor in Amazon EC2, Amazon Elastic Block Store (Amazon EBS), and Amazon EMR costs, but don’t include Amazon Simple Storage Service (Amazon S3) GET and PUT costs.
- Amazon EC2 cost (include SSD cost) = number of instances * r5d.4xlarge hourly rate * job runtime in hours
- r5d.4xlarge hourly rate = $1.152 per hour
- Root Amazon EBS cost = number of instances * Amazon EBS per GB-hourly rate * root EBS volume size * job runtime in hours
- Amazon EMR cost = number of instances * r5d.4xlarge Amazon EMR cost * job runtime in hours
- r5d.4xlarge Amazon EMR cost = $0.27 per hour
- Total cost = Amazon EC2 cost + root Amazon EBS cost + Amazon EMR cost
The following table summarizes these costs.
| Metric | EMRFS | EMR S3A | OSS S3A |
| Runtime in hours | 0.5 | 0.48 | 0.51 |
| Number of EC2 instances | 9 | 9 | 9 |
| Amazon EBS size | 0 gb | 0 gb | 0 gb |
| Amazon EC2 cost | $5.18 | $4.98 | $5.29 |
| Amazon EBS cost | $0.00 | $0.00 | $0.00 |
| Amazon EMR cost | $1.22 | $1.17 | $1.24 |
| Total cost | $6.40 | $6.15 | $6.53 |
| Cost savings | Baseline | EMR S3A is 1.04 times better than EMRFS | EMR S3A is 1.06 times better than OSS S3A |
Write workload performance comparison
We conducted benchmark tests to assess the write performance of the Amazon EMR 7.10 runtime for Apache Spark.
Static table/partition overwrite
We evaluated the static table/partition overwrite write performance of the different file system by executing the following INSERT OVERWRITE Spark SQL query. The SELECT * FROM range(...) clause generated data at execution time. This produced approximately 15 GB of data across exactly 100 Parquet files in Amazon S3.
The test environment was configured as follows:
- EMR cluster with emr-7.10.0 release label
- Single m5d.2xlarge instance (primary group)
- Eight m5d.2xlarge instances (core group)
- S3 bucket in the same AWS Region as the EMR cluster
- The
trial_idproperty used a UUID generator to avoid conflict between test runs
Results
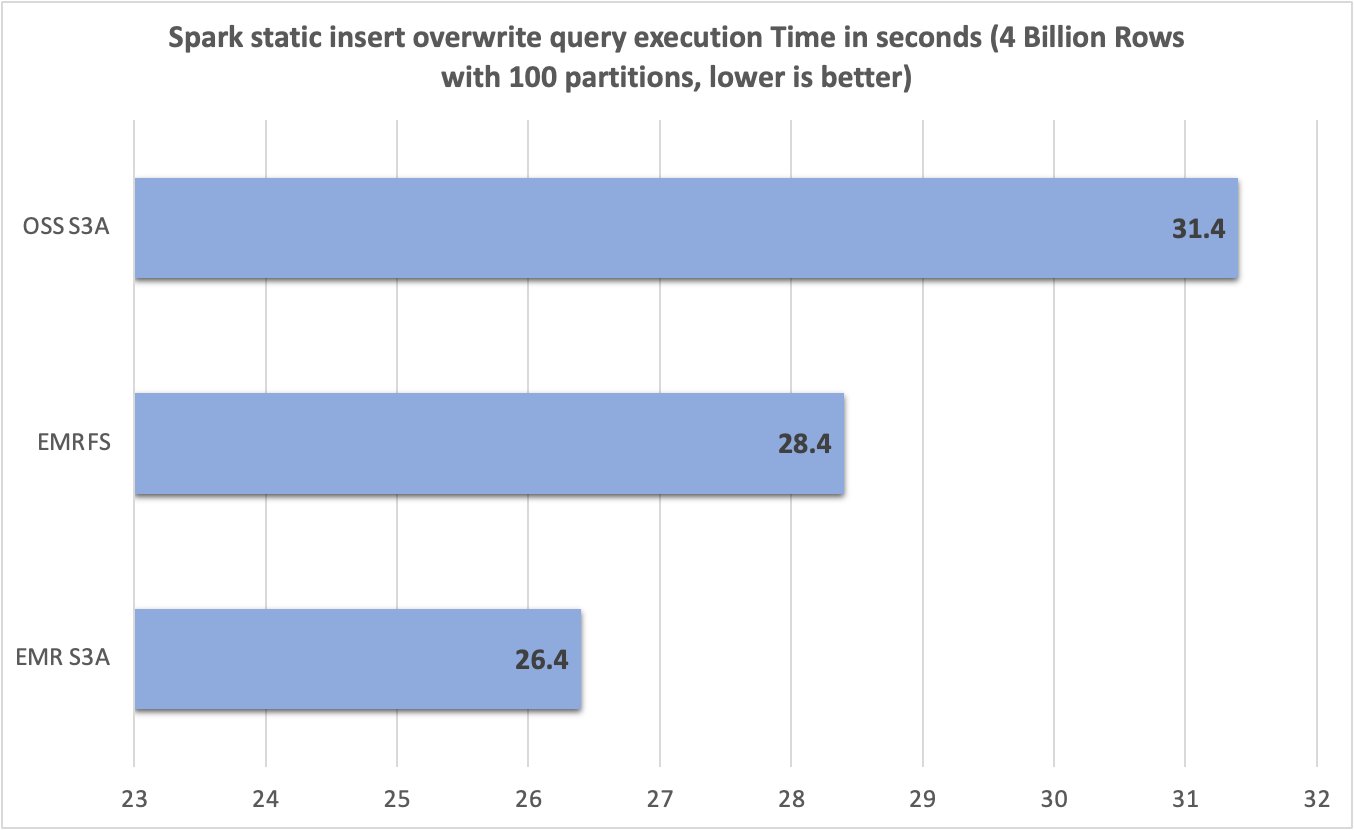
After running 10 trials for each file system, we captured and summarized query runtimes in the following chart. Whereas EMR S3A averaged only 26.4 seconds, the EMRFS and open source S3A averaged 28.4 seconds and 31.4 seconds—a 1.07 times and 1.19 times improvement, respectively.
Dynamic partition overwrite
We also evaluated the write performance by executing the following INSERT OVERWRITE dynamic partition Spark SQL query, which joins TPC-DS 3TB partitioned Parquet data of the table web_sales and date_dim tables, which inserts approximately 2,100 partitions, where each partition contains one Parquet file with a combined size of approximately 31.2 GB in Amazon S3.
The test environment was configured as follows:
- EMR cluster with emr-7.10.0 release label
- Single r5d.4xlarge instance (master group)
- Five r5d.4xlarge instances (core group)
- Approximately 2,100 partitions with one Parquet file each
- Combined size of approximately 31.2 GB in Amazon S3
Results
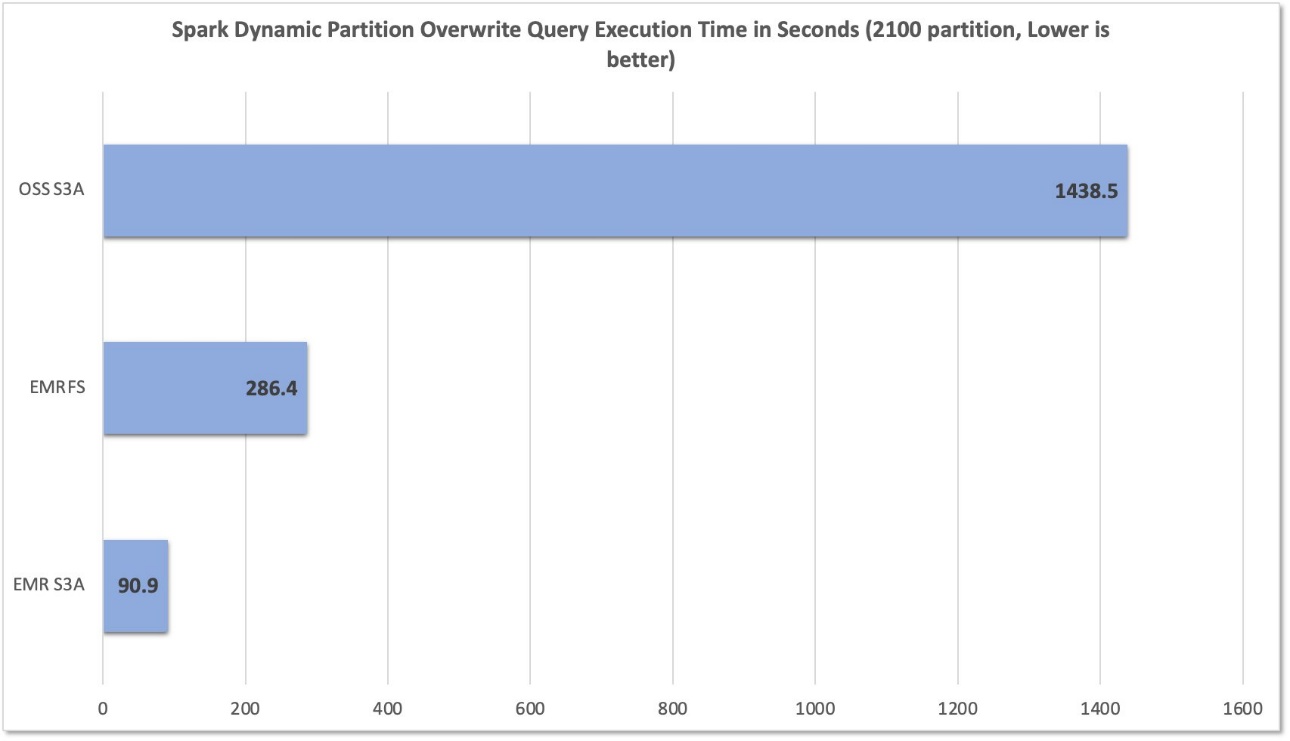
After running 10 trials for each file system, we captured and summarized query runtimes in the following chart. Whereas EMR S3A averaged only 90.9 seconds, the EMRFS and open source S3A averaged 286.4 seconds and 1,438.5 seconds—a 3.15 times and 15.82 times improvement, respectively.
Summary
Amazon EMR consistently enhances its Apache Spark runtime and S3A connector, delivering continuous performance improvements that help big data customers execute analytics workloads more cost-effectively. Beyond performance gains, the strategic shift to S3A introduces critical advantages, including enhanced standardization, improved cross-platform portability, and robust community-driven support—all while maintaining or surpassing the performance benchmarks established by the previous EMRFS implementation.
We recommend that you stay up-to-date with the latest Amazon EMR release to take advantage of the latest performance and feature benefits. Subscribe to the AWS Big Data Blog’s RSS feed to learn more about the Amazon EMR runtime for Apache Spark, configuration best practices, and tuning advice.