AWS Big Data Blog
Optimize efficiency with language analyzers using scalable multilingual search in Amazon OpenSearch Service
Organizations manage content across multiple languages as they expand globally. Ecommerce platforms, customer support systems, and knowledge bases require efficient multilingual search capabilities to serve diverse user bases effectively. This unified search approach helps multinational organizations maintain centralized content repositories while making sure users, regardless of their preferred language, can effectively find and access relevant information.
Building multi-language applications using language analyzers with OpenSearch commonly involves a significant challenge: multi-language documents require manual preprocessing. This means that in your application, for every document, you must first identify each field’s language, then categorize and label it, storing content in separate, pre-defined language fields (for example, name_en, name_es, and so on) in order to use language analyzers in search to improve search relevancy. This client-side effort is complex, adding workload for language detection, potentially slowing data ingestion, and risking accuracy issues if languages are misidentified. It’s a labor-intensive approach. However, Amazon OpenSearch Service 2.15+ introduces an AI-based ML inference processor. This new feature automatically identifies and tags document languages during ingestion, streamlining the process and removing the burden from your application.
By harnessing the power of AI and using context-aware data modeling and intelligent analyzer selection, this automated solution streamlines document processing by minimizing manual language tagging, and enables automatic language detection during ingestion, providing organizations sophisticated multilingual search capabilities.
Using language identification in OpenSearch Service offers the following benefits:
- Enhanced user experience – Users can now find relevant content regardless of the language they search in
- Increased content discovery – The service can surface valuable content across language silos
- Improved search accuracy – Language-specific analyzers provide better search relevance
- Automated processing – You can reduce manual language tagging and classification
In this post, we share how to implement a scalable multilingual search solution using OpenSearch Service.
Solution overview
The solution eliminates manual language preprocessing by automatically detecting and handling multilingual content during document ingestion. Instead of manually creating separate language fields (en_notes, es_notes, and so on) or implementing custom language detection systems, the ML inference processor identifies languages and creates appropriate field mappings.
This automated approach improves accuracy compared to traditional manual methods and reduces development complexity and processing overhead, allowing organizations to focus on delivering better search experiences to their global users.
The solution comprises the following key components:
- ML inference processor – Invokes ML models during document ingestion to enrich content with language metadata
- Amazon SageMaker integration – Hosts pre-trained language identification models that analyze text fields and return language predictions
- Language-specific indexing – Applies appropriate analyzers based on detected languages, providing proper handling of stemming, stop words, and character normalization
- Connector framework – Enables secure communication between OpenSearch Service and Amazon SageMaker endpoints through AWS Identity and Access Management (IAM) role-based authentication.
The following diagram illustrates the workflow of the language detection pipeline.
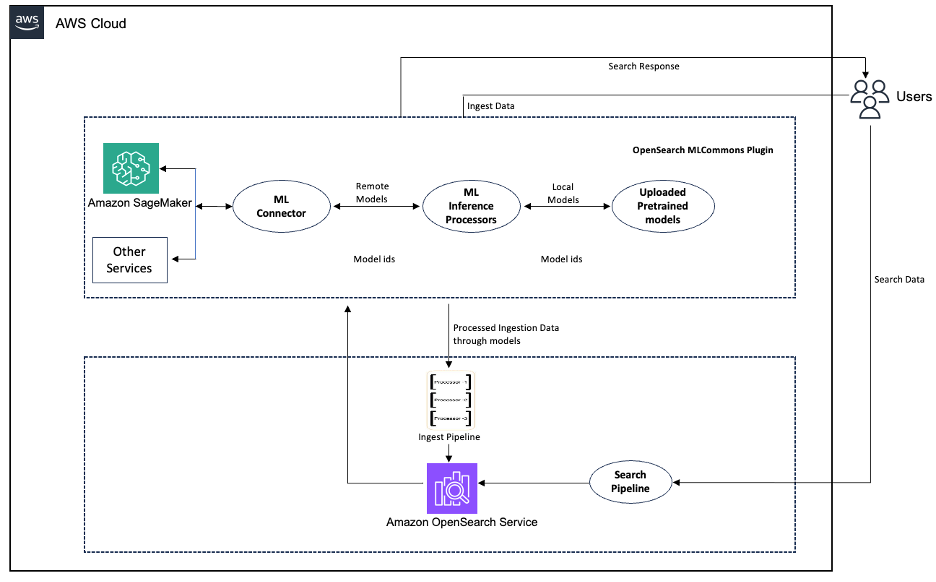
Figure 1: Workflow of the language detection pipeline
This example demonstrates text classification using XLM-RoBERTa-base for language detection on Amazon SageMaker. You have flexibility in choosing your models and can alternatively use the built-in language detection capabilities of Amazon Comprehend.
In the following sections, we walk through the steps to deploy the solution. For detailed implementation instructions, including code examples and configuration templates, refer to the comprehensive tutorial in the OpenSearch ML Commons GitHub repository.
Prerequisites
You must have the following prerequisites:
- An OpenSearch Service domain running version 2.15 or later
- Amazon SageMaker access for model deployment
- Appropriate IAM roles and policies for service integration
- Fine-grained access control enabled on the OpenSearch Service domain
Deploy the model
Deploy a pre-trained language identification model on Amazon SageMaker. The XLM-RoBERTa model provides robust multilingual language detection capabilities suitable for most use cases.
Configure the connector
Create an ML connector to establish a secure connection between OpenSearch Service and Amazon SageMaker endpoints, primarily for language detection tasks. The process begins with setting up authentication through IAM roles and policies, applying proper permissions for both services to communicate securely.
After you configure the connector with the appropriate endpoint URLs and credentials, the model is registered and deployed in OpenSearch Service and its modelID is used in subsequent steps.
Sample response:
After you configure the connector, you can test is by sending text to the model through OpenSearch Service, and it will return the detected language (for example, sending “Say this is a test” returns en for English).
Set up the ingest pipeline
Configure the ingest pipeline, which uses ML inference processors to automatically detect the language of the content in the name and notes fields of incoming documents. After language detection, the pipeline creates new language-specific fields by copying the original content to new fields with language suffixes (for example, name_en for English content).
The pipeline uses an ml_inference processor to perform the language detection and copy processors to create the new language-specific fields, making it straightforward to handle multilingual content in your OpenSearch Service index.
Configure the index and ingest documents
Create an index with the ingest pipeline that automatically detects the language of incoming documents and applies appropriate language-specific analysis. When documents are ingested, the system identifies the language of key fields, creates language-specific versions of those fields, and indexes them using the correct language analyzer. This allows for efficient and accurate searching across documents in multiple languages without requiring manual language specification for each document.
Here’s a sample index creation API call demonstrating different language mappings.
Next, ingest this input document in German
The German text used in the preceding code will be processed using a German-specific analyzer, supporting proper handling of language-specific characteristics such as compound words and special characters.
After successful ingestion into OpenSearch Service, the resulting document appears as follows:
Search documents
This step demonstrates the search capability after the multilingual setup. By using a multi_match query with name_* fields, it searches across all language-specific name fields (name_en, name_es, name_de) and successfully finds the Spanish document when searching for “comprar” because the content was properly analyzed using the Spanish analyzer. This example shows how the language-specific indexing enables accurate search results in the correct language without needing to specify which language you’re searching in.
This search correctly finds the Spanish document because the name_es field is analyzed using the Spanish analyzer:
Cleanup
To avoid ongoing charges and delete the resources created in this tutorial, perform the following cleanup steps
- Delete the Opensearch service domain. This stops both storage costs for your vectorized data and any associated compute charges.
- Delete the ML connector that links your OpenSearch service to your machine learning model.
- Finally, delete your Amazon SageMaker endpoints and resources.
Conclusion
Implementing multilingual search with OpenSearch Service can help organizations break down language barriers and unlock the full value of their global content. The ML inference processor provides a scalable, automated approach to language detection that improves search accuracy and user experience.
This solution addresses the growing need for multilingual content management as organizations expand globally. By automatically detecting document languages and applying appropriate linguistic processing, businesses can deliver comprehensive search experiences that serve diverse user bases effectively.