AWS Big Data Blog

Readmission Prediction Through Patient Risk Stratification Using Amazon Machine Learning
In this post, I show how to apply advanced analytics concepts like pattern analysis and machine learning to do risk stratification for patient cohorts.

Month in Review: July 2016
July was a busy month of big data solutions on the Big Data Blog. The month started with our most popular story yet, Generating Recommendations at Amazon Scale with Apache Spark and Amazon DSSTNE. It was a great post to start a spectacular month. Take a look at our summaries below. Learn, comment, and share. […]

Use Spark 2.0, Hive 2.1 on Tez, and the latest from the Hadoop ecosystem on Amazon EMR release 5.0
Jonathan Fritz is a Senior Product Manager for Amazon EMR We are excited to launch Amazon EMR release 5.0 today, giving customers the latest versions of 16 supported open-source applications in the big data ecosystem, including new major versions of Spark and Hive. Almost exactly a year ago, we shipped release 4.0, which brought significant […]

Installing and Running JobServer for Apache Spark on Amazon EMR
In this blog post, you will learn how to install JobServer on EMR using a bootstrap action (BA) derived from the JobServer GitHub repository. Then we’ll run JobServer using a sample dataset.

Process Large DynamoDB Streams Using Multiple Amazon Kinesis Client Library (KCL) Workers
Asmita Barve-Karandikar is an SDE with DynamoDB Introduction Imagine you own a popular mobile health app, with millions of users worldwide, that continuously records new information. It sends over one million updates per second to its master data store and needs the updates to be relayed to various replicas across different regions in real time. […]
AWS re:Invent 2016 Registration is Now Open
Register now for the fifth annual AWS re:Invent, the largest gathering of the global cloud computing community. Join us in Las Vegas for opportunities to connect, collaborate, and learn about AWS solutions. There will be many opportunities for developers and data scientists working in big data to sharpen their skills and learn what’s coming next […]

Simplify Management of Amazon Redshift Snapshots using AWS Lambda
NOTE: Amazon Redshift now supports creating an automatic snapshot schedule using the snapshot scheduler. For more information, please review this “What’s New” post. ———————————- Ian Meyers is a Solutions Architecture Senior Manager with AWS Amazon Redshift is a fast, fully managed, petabyte-scale data warehouse that makes it simple and cost-effective to analyze all your data […]
How SmartNews Built a Lambda Architecture on AWS to Analyze Customer Behavior and Recommend Content
This is a guest post by Takumi Sakamoto, a software engineer at SmartNews. SmartNews in their own words: “SmartNews is a machine learning-based news discovery app that delivers the very best stories on the Web for more than 18 million users worldwide.” Data processing is one of the key technologies for SmartNews. Every team’s workload […]
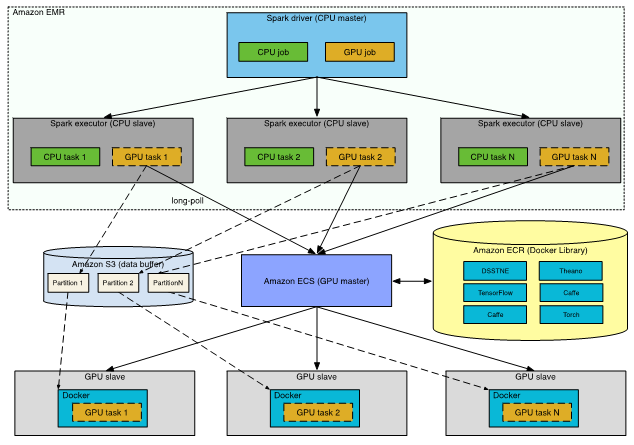
Generating Recommendations at Amazon Scale with Apache Spark and Amazon DSSTNE
In this post, I discuss an alternate solution; namely, running separate CPU and GPU clusters, and driving the end-to-end modeling process from Apache Spark.
Month in Review: June 2016
Lots to see on the Big Data Blog in June! Please take a look at the summaries below for something that catches your interest. Use Sqoop to Transfer Data from Amazon EMR to Amazon RDS Customers commonly process and transform vast amounts of data with EMR and then transfer and store summaries or aggregates of […]