AWS Big Data Blog
Query Routing and Rewrite: Introducing pgbouncer-rr for Amazon Redshift and PostgreSQL
This post was last reviewed and updated August, 2022 with a section on Deploying pgbouncer in Elastic Kubernetes Service (EKS).
NOTE: You can now use federated queries in Amazon Redshift to query and analyze data across operational databases, data warehouses, and data lakes. For more information, please review the Amazon Redshift documentation article, “Querying Data with Federated Query in Amazon Redshift.”
Have you ever wanted to split your database load across multiple servers or clusters without impacting the configuration or code of your client applications? Or perhaps you have wished for a way to intercept and modify application queries, so that you can make them use optimized tables (sorted, pre-joined, pre-aggregated, etc.), add security filters, or hide changes you have made in the schema?
The pgbouncer-rr project is based on pgbouncer, an open source, PostgreSQL connection pooler. It adds two new significant features:
- Routing: Intelligently send queries to different database servers from one client connection; use it to partition or load balance across multiple servers or clusters.
- Rewrite: Intercept and programmatically change client queries before they are sent to the server; use it to optimize or otherwise alter queries without modifying your application.

Pgbouncer-rr works the same way as pgbouncer. Any target application can be connected to pgbouncer-rr as if it were an Amazon Redshift or PostgreSQL server, and pgbouncer-rr creates a connection to the actual server, or reuses an existing connection.
You can deploy multiple instances of pgbouncer-rr to avoid throughput bottlenecks or single points of failure, or to support multiple configurations. It can live in an Auto Scaling group, and behind an Elastic Load Balancing load balancer. It can be deployed to a public subnet while your servers reside in private subnets. You can choose to run it as a bastion server using SSH tunneling, or you can use pgbouncer’s recently introduced SSL support for encryption and authentication.
Documentation and community support for pgbouncer can be easily found online; pgbouncer-rr is a superset of pgbouncer.
Now I’d like to talk about the query routing and query rewrite feature enhancements.
Query Routing
The routing feature maps client connections to server connections using a Python routing function which you provide. Your function is called for each query, with the client username and the query string as parameters. Its return value must identify the target database server. How it does this is entirely up to you.
For example, you might want to run two Amazon Redshift clusters, each optimized to host a distinct data warehouse subject area. You can determine the appropriate cluster for any given query based on the names of the schemas or tables used in the query. This can be extended to support multiple Amazon Redshift clusters or PostgreSQL instances.
In fact, you can even mix and match Amazon Redshift and PostgreSQL, taking care to ensure that your Python functions correctly handle any server-specific grammar in your queries; your database will throw errors if your routing function sends queries it can’t process. And, of course, any query must run entirely on the server to which is it routed; cross-database joins or multi-server transactions do not work!
Here’s another example: you might want to implement controlled load balancing (or A/B testing) across replicated clusters or servers. Your routing function can choose a server for each query based on any combination of the client username, the query string, random variables, or external input. The logic can be as simple or as sophisticated as you want.
Your routing function has access to the full power of the Python language and the myriad of available Python modules. You can use the regular expression module (re) to match words and patterns in the query string, or use the SQL parser module (sqlparse) to support more sophisticated/robust query parsing. You may also want to use the AWS SDK module (boto) to read your routing table configurations from Amazon DynamoDB.
The Python routing function is dynamically loaded by pgbouncer-rr from the file you specify in the configuration:
The file should contain the following Python function:
The function parameters provide the username associated with the client, and a query string. The function return value must be a valid database key name (dbkey) as specified in the configuration file, or None. When a valid dbkey is returned by the routing function, the client connection will be routed to a connection in the specified server connection pool. When None is returned by the routing function, the client remains routed to its current server connection.
The route function is called only for query and prepare packets, with the following restrictions:
- All queries must run wholly on the assigned server. Cross-server joins do not work.
- Ideally, queries should auto-commit each statement. Set
pool_mode = statementin the configuration. - Multi-statement transactions work correctly only if statements are not rerouted by the
routing_rulesfunction to a different server pool mid-transaction. Setpool_mode = transactionin the configuration. - If your application uses database catalog tables to discover the schema, then the
routing_rulesfunction should direct catalog table queries to a database server that has all the relevant schema objects created.
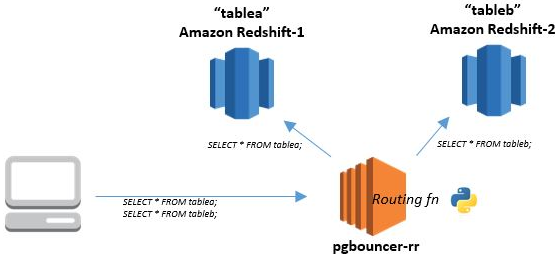
Simple query routing example
Amazon Redshift cluster 1 has data in table ‘tablea‘. Amazon Redshift cluster 2 has data in table ‘tableb‘. You want a client to be able to issue queries against either tablea or tableb without needing to know which table resides on which cluster.
Create a (default) entry with a key, say, ‘dev‘ in the [databases] section of the pgbouncer configuration. This entry determines the default cluster used for client connections to database ‘dev‘. You can make either redshift1 or redshift2 the default, or even specify a third ‘default’ cluster. Create additional entries in the pgbouncer [databases] section for each cluster; give these unique key names such as ‘dev.1‘, and ‘dev.2‘.
Ensure that the configuration file setting routing_rules_py_module_file specifies the path to your Python routing function file, such as ~/routing_rules.py. The code in the file could look like the following:
Below is a toy example, but it illustrates the concept. If a client sends the query SELECT * FROM tablea, it matches the first rule, and is assigned to server pool ‘dev.1‘ (redshift1). If a client (and it could be the same client in the same session) sends the query SELECT * FROM tableb, it matches the second rule, and is assigned to server pool ‘dev.2‘ (redshift2). Any query that does not match either rule results in None being returned, and the server connection remains unchanged.
Below is an alternative function for the same use case, but the routing logic is defined in a separate extensible data structure using regular expressions to find the table matches. The routing table structure could easily be externalized in a DynamoDB table.
You will likely want to implement more robust and sophisticated rules, taking care to avoid unintended matches. Write test cases to call your function with different inputs and validate the output dbkey values.
Query Rewrite
The rewrite feature provides you with the opportunity to manipulate application queries en route to the server without modifying application code. You might want to do this to:
- Optimize an incoming query to use the best physical tables when you have replicated tables with alternative sort/dist keys and column subsets (emulate projections), or when you have stored pre-joined or pre-aggregated data (emulate ‘materialized views’).
- Apply query filters to support row-level data partitioning/security.
- Roll out new schemas, resolve naming conflicts, and so on, by changing identifier names on the fly.
The rewrite function is also implemented in a fully configurable Python function, dynamically loaded from an external module specified in the configuration:
The file should contain the following Python function:
The function parameters provide the username associated with the client, and a query string. The function return value must be a valid SQL query string which returns the result set that you want the client application to receive.
Implementing a query rewrite function is straightforward when the incoming application queries have fixed formats that are easily detectable and easily manipulated, perhaps using regular expression search/replace logic in the Python function. It is much more challenging to build a robust rewrite function to handle SQL statements with arbitrary format and complexity.
Enabling the query rewrite function triggers pgbouncer-rr to enforce that a complete query is contained in the incoming client socket buffer. Long queries are often split across multiple network packets. They should all be in the buffer before the rewrite function is called, which requires that the buffer size be large enough to accommodate the largest query. The default buffer size (2048) is likely too small, so specify a much larger size in the configuration pkt_buf = 32768.
If a partially received query is detected, and there is room in the buffer for the remainder of the query, pgbouncer-rr waits for the remaining packets to be received before processing the query. If the buffer is not large enough for the incoming query, or if it is not large enough to hold the re-written query (which may be longer than the original), then the rewrite function will fail. By default, the failure is logged and the original query string will be passed to the server unchanged. You can force the client connection to terminate instead, by setting rewrite_query_disconnect_on_failure = true.
Simple query rewrite example
You have a star schema with a large fact table in Amazon Redshift (such as ‘sales’) with two related dimension tables (such as ‘store’ and ‘product’). You want to optimize equally for two different queries:
By experimenting, you have determined that the best possible solution is to have two additional tables, each optimized for one of the queries:
- store_sales: store and sales tables denormalized, pre-aggregated by store, and sorted and distributed by store name
- product_sales: product and sales tables denormalized, pre-aggregated by product, sorted and distributed by product name
So you implement the new tables, and take care of their population in your ETL processes. But you’d like to avoid directly exposing these new tables to your reporting or analytic client applications. This might be the best optimization today, but who knows what the future holds? Maybe you’ll come up with a better optimization later, or maybe Amazon Redshift will introduce cool new features that provide a simpler alternative.
So, you implement a pgbouncer-rr rewrite function to change the original queries on the fly. Ensure that the configuration file setting rewrite_query_py_module_file specifies the path to your python function file, say ~/rewrite_query.py.
The code in the file could look like this:
Again, this is a toy example to illustrate the concept. In any real application, your Python function needs to employ more robust query pattern matching and substitution.

Your reports and client applications use the same join query as before:
Now, when you look on the Amazon Redshift console Queries tab, you see that the query received by Amazon Redshift is the rewritten version that uses the new product_sales table, leveraging your pre-joined, pre-aggregated data and the targeted sort and dist keys:
Getting Started
Here are the steps to start working with pgbouncer-rr.
Install
Download and install pgbouncer-rr by running the following commands (Amazon Linux/RHEL/CentOS):
Configure
Create a configuration file, using ./pgbouncer-example.ini as a starting point, adding your own database connections and Python routing rules and rewrite query functions.
Set up user authentication; for more information, see authentication file format.
NOTE: The recently added pgbouncer auth_query feature does not work with Amazon Redshift.
By default, pgbouncer-rr does not support SSL/TLS connections. However, you can experiment with pgbouncer’s TLS/SSL feature. Just add a private key and certificate to your pgbouncer-rr configuration:
Hint: Here’s how to easily generate a test key with a self-signed certificate using openssl:
Configure a firewall
Configure your Linux firewall to enable incoming connections on the configured pgbouncer-rr listening port. For example:
If you are running pgbouncer-rr on an Amazon EC2 instance, the instance security group must also be configured to allow incoming TCP connections on the listening port.
Launch
Run pgbouncer-rr as a daemon using the commandline pgbouncer <config_file> -d. See pgbouncer --help for commandline options.
Hint: Use -v -v to enable verbose logging. If you look carefully in the logfile, you will see evidence of the query routing and query rewrite features in action.
Connect
Configure your client application as though you were connecting directly to an Amazon Redshift or PostgreSQL database, but be sure to use the pgbouncer-rr hostname and listening port.
Here’s an example using plsql:
Here’s another example using a JDBC driver URL (Amazon Redshift driver):
Deploy pgbouncer in Elastic Kubernetes Service (EKS)
Dockerization and deployment considerations
We choose to deploy PGBouncer as a container on Amazon Elastic Kubernetes Service (EKS) to allow it to horizontally scale to the Redshift or Postgresql client load. We first containerized and stored the image in Amazon Elastic Container Registry (ECR); then we deployed Kubernetes (1) Deployment and (2) Service. The Kubernetes Deployment, pgbouncer-deploy.yaml defines the PGBouncer configuration, such as logging or the location of routing rules, as well as Redshift and Postgresql database cluster endpoint credentials. The startup script start.sh generates the pgbouncer.ini upon the PGBouncer container init (so don’t look for it here).
Security wise, we run the PGBouncer process in a non-root user to limit the process scope.
We also use Kubernetes secrets to allow secure credentials loading at runtime only. The secrets are created with create-secrets.sh that issue kubectl create secret generic with a local secret file, pgbouncer.secrets. Make sure you avoid loading the file to your git repository by adding *.secrets to your .gitignore. Here is an example of a secret file:
The Kubernetes Service,pgbouncer-svc.yaml uses Network Load Balancer that points to the PGBouncer containers deployed in the Kubernetes cluster public subnets. We choose to allow public access to the PGBouncer endpoint for demonstration purposes but we can limit the endpoint to be internal for production systems. Note, you need to deploy the AWS Load Balancer Controller to automate the integration between EKS and NLB. The AWS Load Balancer Controller uses annotations like:
aws-load-balancer-scheme:"internet-facing" exposes the PGBouncer service publicly. aws-load-balancer-nlb-target-type: "ip" uses the PGBouncer pods as target rather than the EC2 instance.
Deployment steps
The EKS option automates the configuration and installation sections above. The deployment steps with EKS are:
- Deploy EKS cluster with Karpenter for automatic EC2 instance horizontal scaling
- Install the AWS Load Balancer Controller add-on
- Build the PGBouncer Docker image.
- Deploy PGBouncer replicas
- Deploy PGBouncer NLB
- Discover the NLB endpoint
Use the EXTERNAL-IP value, pgbouncer-14d32ab567b83e8f.elb.us-west-2.amazonaws.com as the endpoint to connect the database
How to view the pgbouncer-rr logs?
Pgbouncer default logging writes the process logs to stdout and stderr as well as a preconfigured log file. One can view the log in three ways:
- Get a shell to the pgbouncer running container and view the log. Discover the pgbouncer process by:
- Use the pgbouncer-5dc7498984-f6js2 for getting the container shell
- Get the container
stdoutandstderr. Viewing the container’s stdout and stderr is preferred if the pgbouncer process is the only one running.
- View the logs in CloudWatch. Refer this knowledge center article to stream container logs running in Amazon Elastic Kubernetes Service (Amazon EKS) to a logging system like CloudWatch Logs.
How to make configuration changes?
You must push changes to EKS if you need to modify the pgbouncer configuration or binaries. Changing configurations is done using the kubectl tool, but updating binaries requires rebuilding the docker image and pushing it to the image registry (ECR). Below we describe both methods.
- Making configuration changes The pgbouncer-rr config is stored in pgbouncer-deploy.yaml or pgbouncer-svc.yaml. Say we wanted to increase the default_pool_size. You need to modify default_pool_size in pgbouncer-deploy.yaml and execute:
- Making binaries changes The pgbouncer-rr docker specification is stored in Dockerfile. Say you want to upgrade the pgbouncer version from 1.15 to 1.16. You need to modify
--branch "pgbouncer_1_15_0".
Instead of:use:
Then you rebuild and push the changes to the docker image registry and rollout the changes in Kubernetes.
Other uses for pgbouncer-rr
It can be used for lots of things, really. In addition to the examples shown above, here are some other use cases suggested by colleagues:
- Serve small or repetitive queries from PostgreSQL tables consisting of aggregated results.
- Parse SQL for job-tracking table names to implement workload management with job tracking tables on PostgreSQL, simplifies application development.
- Leverage multiple Amazon Redshift clusters to serve dashboarding workloads with heavy concurrency requirements.
- Determine the appropriate route based on the current workload/state of cluster resources (always route to the cluster with least running queries, etc).
- Use Query rewrite to parse SQL for queries which do not leverage the nuances of Amazon Redshift query design or query best practices; either block these queries or re-write them for performance.
- Use SQL parse to limit end user ability to access tables with ad hoc queries; e.g., identify users scanning N+ years of data and instead issue a query which blocks them with a re-write: e.g.,
SELECT 'WARNING: scans against v_all_sales must be limited to no more than 30 days' AS alert; - Use SQL parse to identify and rewrite queries which filter on certain criteria to direct them towards a specific table containing data matching that filter.
Actually, your use cases don’t need to be limited to just routing and query rewriting. You could design a routing function that leaves the route unchanged, but which instead implements purposeful side effects, such as:
- Publishing custom CloudWatch metrics, enabling you to monitor specific query patterns and/or user interactions with your databases.
- Capturing SQL DDL and INSERT/UPDATE statements, and wrap them into Amazon Kinesis
put-recordsas input to the method described in Erik Swensson’s excellent post, Building Multi-AZ or Multi-Region Amazon Redshift Clusters.
We’d love to hear your thoughts and ideas for pgbouncer-rr functions. If you have questions or questions or suggestions, please leave a comment below.
Copyright 2015-2015 Amazon.com, Inc. or its affiliates. All Rights Reserved.
| Since you’re reading this post, you may also be interested in the following: |
About the authors
 Bob Strahan is a Principal Solutions Architect in the AWS Language AI Services team.
Bob Strahan is a Principal Solutions Architect in the AWS Language AI Services team.
 Yahav Biran is a Solutions Architect in AWS, focused on Game tech at scale. Yahav enjoys contributing to open source projects and publish in AWS blog and academic journals. He currently contributes to the K8s Helm community, AWS databases and compute blogs, and Journal of Systems Engineering. He delivers technical presentations at technology events and working with customers to design their applications in the Cloud. He received his Ph.D. (Systems Engineering) from Colorado State University.
Yahav Biran is a Solutions Architect in AWS, focused on Game tech at scale. Yahav enjoys contributing to open source projects and publish in AWS blog and academic journals. He currently contributes to the K8s Helm community, AWS databases and compute blogs, and Journal of Systems Engineering. He delivers technical presentations at technology events and working with customers to design their applications in the Cloud. He received his Ph.D. (Systems Engineering) from Colorado State University.