AWS Big Data Blog
Stifel’s approach to scalable Data Pipeline Orchestration in Data Mesh
This is a guest post by Hossein Johari, Lead and Senior Architect at Stifel Financial Corp, Srinivas Kandi and Ahmad Rawashdeh, Senior Architects at Stifel, in partnership with AWS.
Stifel Financial Corp, a diversified financial services holding company is expanding its data landscape that requires an orchestration solution capable of managing increasingly complex data pipeline operations across multiple business domains. Traditional time-based scheduling systems fall short in addressing the dynamic interdependencies between data products, requires event-driven orchestration. Key challenges include coordinating cross-domain dependencies, maintaining data consistency across business units, meeting stringent SLAs, and scaling effectively as data volumes grow. Without a flexible orchestration solution, these issues can lead to delayed business operations and insights, increased operational overhead, and heightened compliance risks due to manual interventions and rigid scheduling mechanisms that cannot adapt to evolving business needs.
In this post, we walk through how Stifel Financial Corp, in collaboration with AWS ProServe, has addressed these challenges by building a modular, event-driven orchestration solution using AWS native services that enables precise triggering of data pipelines based on dependency satisfaction, supporting near real-time responsiveness and cross-domain coordination.
Data platform orchestration
Stifel and AWS technology teams identified several key requirements that would guide their solution architecture to overcome the above listed challenges along with traditional data pipeline orchestration.
Coordinated pipeline execution across multiple data domains based on events
- The orchestration solution must support triggering data pipelines across multiple business domains based on events such as data product publication or completion of upstream jobs.
Smart dependency management
- The solution should intelligently manage pipeline dependencies across domains and accounts.
- It must ensure that downstream pipelines wait for all necessary upstream data products, regardless of which team or AWS account owns them.
- Dependency logic should be dynamic and adaptable to changes in data availability.
Business-aligned configuration
- A no-code architecture should allow business users and data owners to define pipeline dependencies and triggers using metadata.
- All changes to dependency configurations should be version-controlled, traceable, and auditable.
Scalable and flexible architecture
- The orchestration solution should support hundreds of pipelines across multiple domains without performance degradation.
- It should be easy to onboard new domains, define new dependencies, and integrate with existing data mesh components.
Visibility and monitoring
- Business users and data owners should have access showing pipeline status, including success, failure, and progress.
- Alerts and notifications should be sent when issues occur, with clear diagnostics to support rapid resolution.
Example Scenario
The following below illustrates a cross-domain data dependency scenario, where a data product in domain (D1 and D2) relies on the prompt refresh of data products from other domains, each operating on distinct schedules. Upon completion, these upstream data products emit refresh events that automatically trigger the execution of a dependent downstream pipeline.
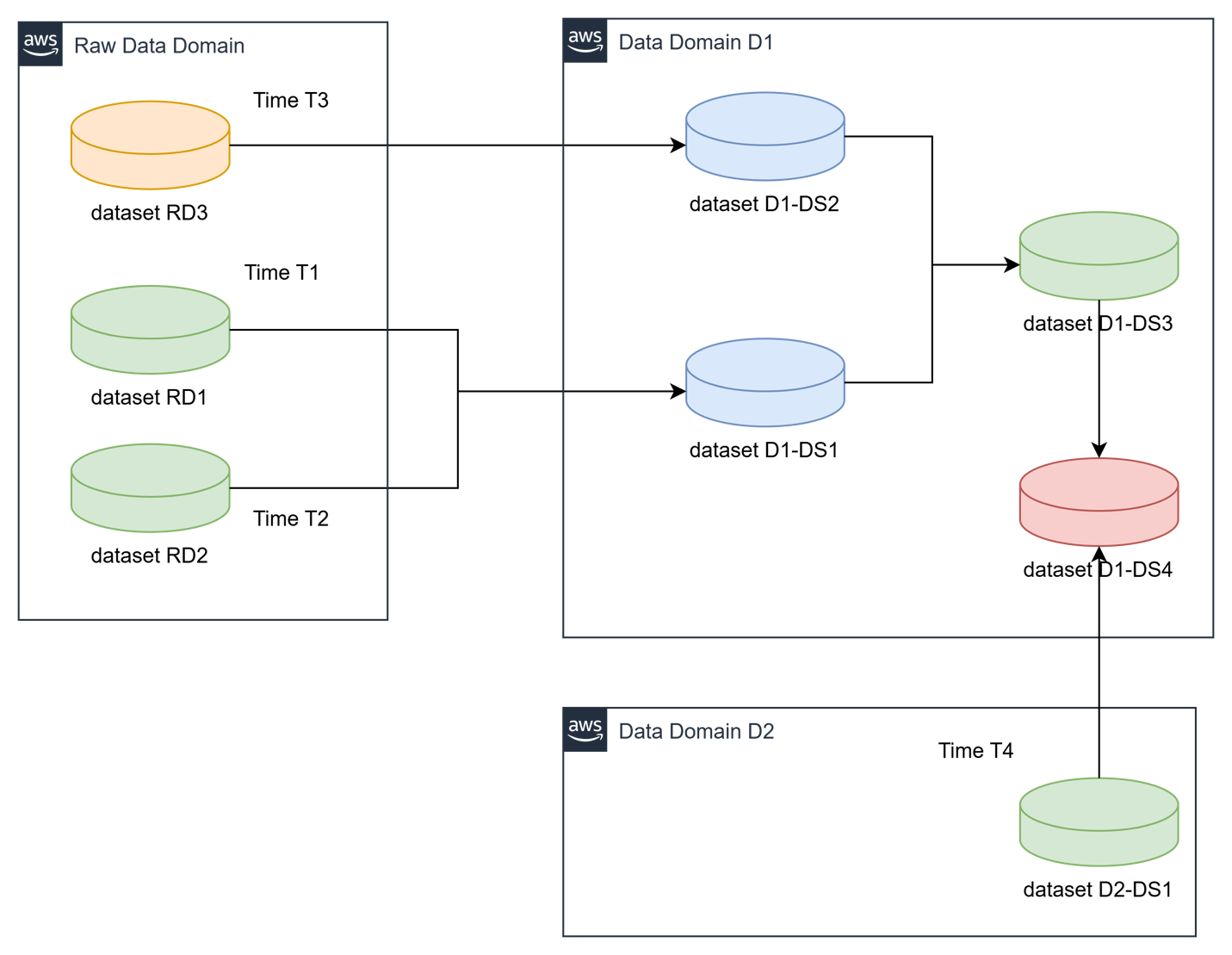
- Dataset DS1 for Domain D1 depends on RD1 and RD2 from raw data domain which gets refreshed at different times T1 and T2
- Dataset DS2 for Domain D1 depends on RD3 from raw data domain which gets refreshed at different times T3
- Dataset DS3 for Domain D1 depends on data refresh of datasets DS1 and DS2 from Domain D1
- Dataset DS4 for Domain D1 depends on datasets DS3 from Domain D1 and dataset DS1 from Domain D2 which is refreshed at time T4.
Solution Overview
The orchestration solution involves two main components.
1. Cross account event sharing
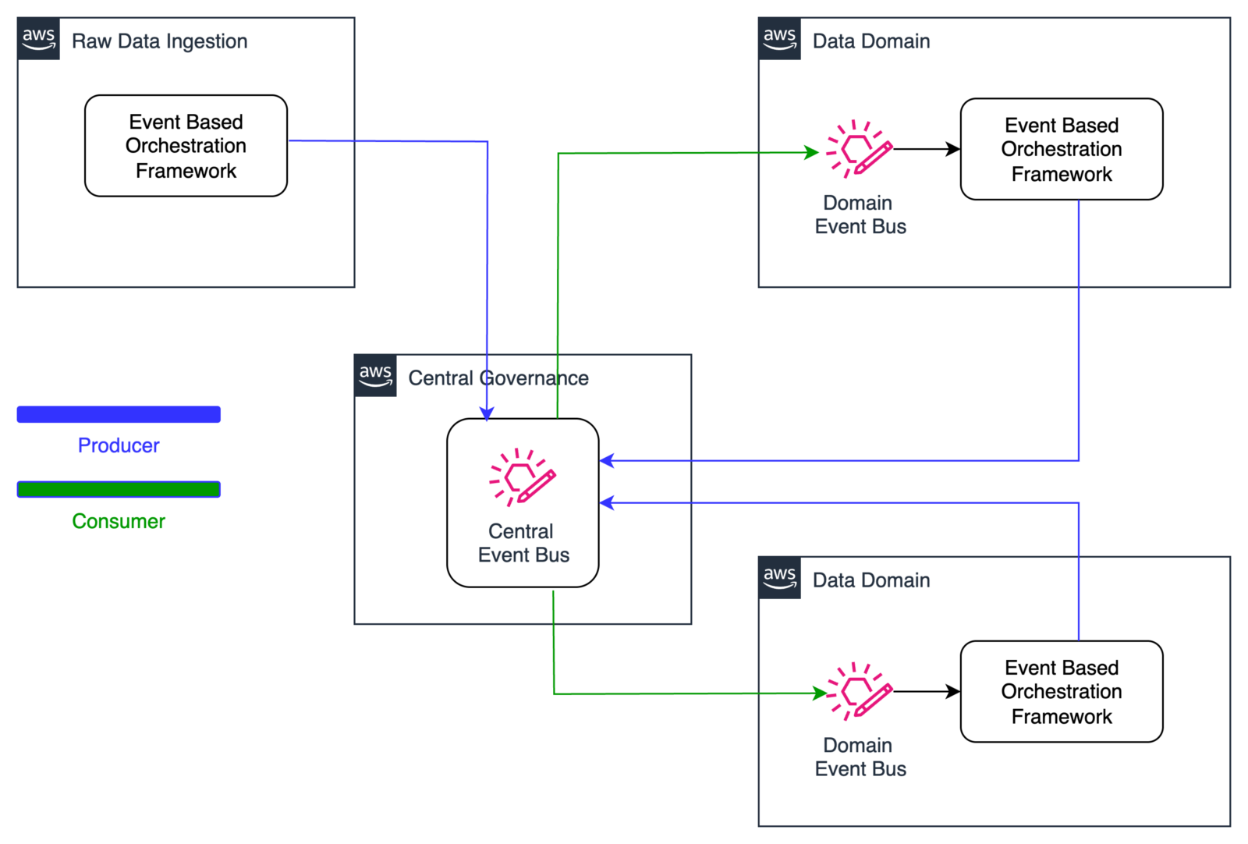
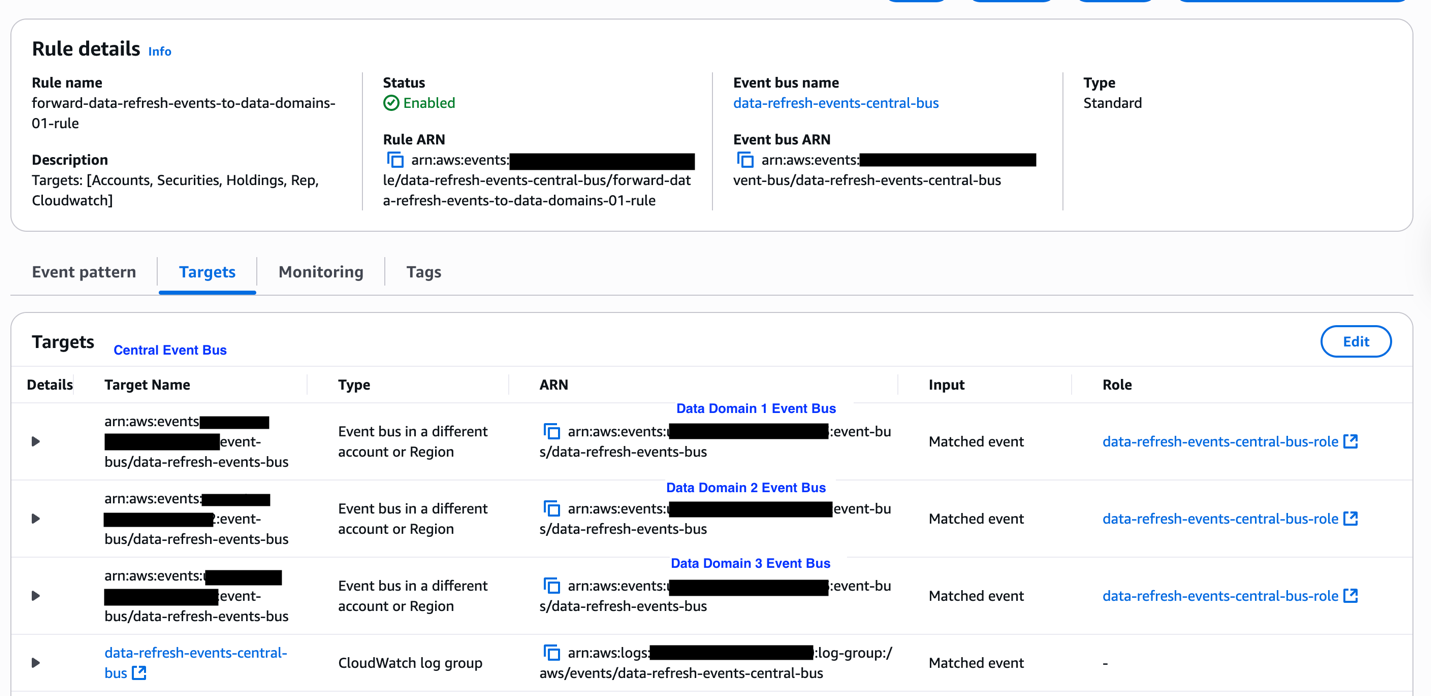
The following diagram illustrates the architecture for distributing data refresh events across domains within the orchestration solution using Amazon EventBridge. Data producers emit refresh events to a centralized event bus upon completing their updates. These events are then propagated to all subscribing domains. Each domain evaluates incoming events against its pipeline dependency configurations, enabling precise and prompt triggering of downstream data pipelines.
Cross Account Event Publish Using Eventbridge
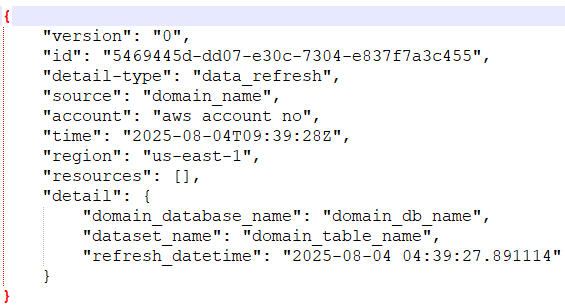
The following snippet shows the data refresh event:
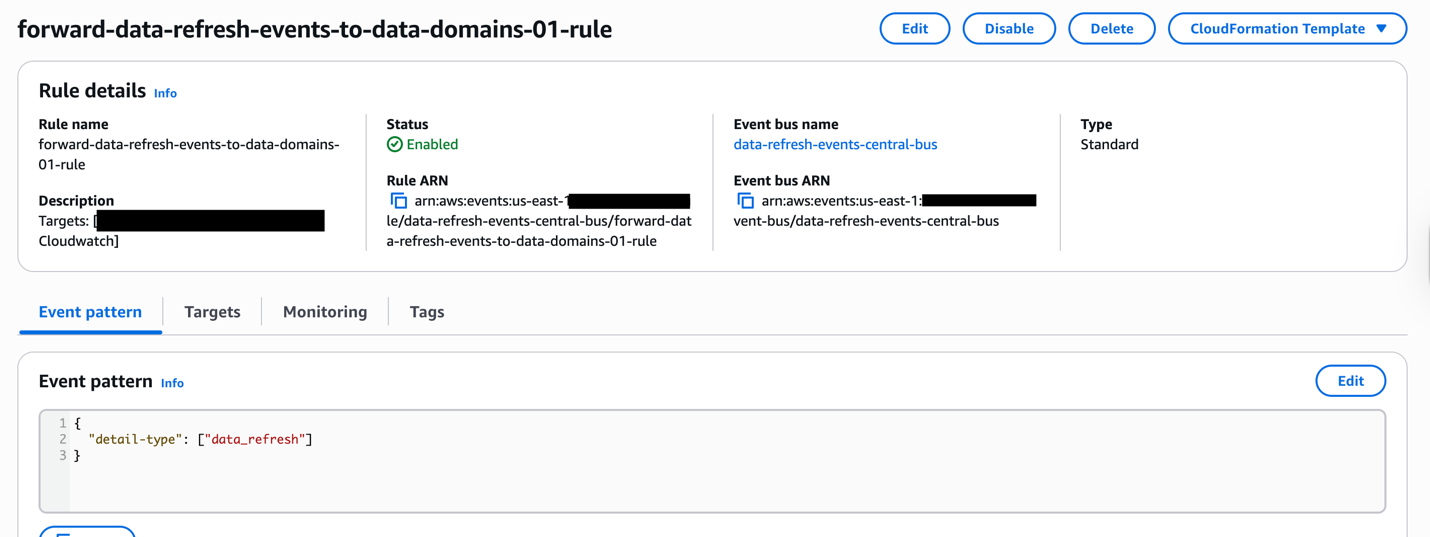
Sample EventBridge cross account event forward rule.
The following screenshots depicts a sample data refresh event that will be broadcasted to consumer data domains.
2. Data Pipeline orchestration
The following diagram describes the technical architecture of the orchestration solution using several AWS services such as Amazon Eventbridge, Amazon SQS, AWS Lambda, AWS Glue, Amazon SNS and Amazon Aurora.
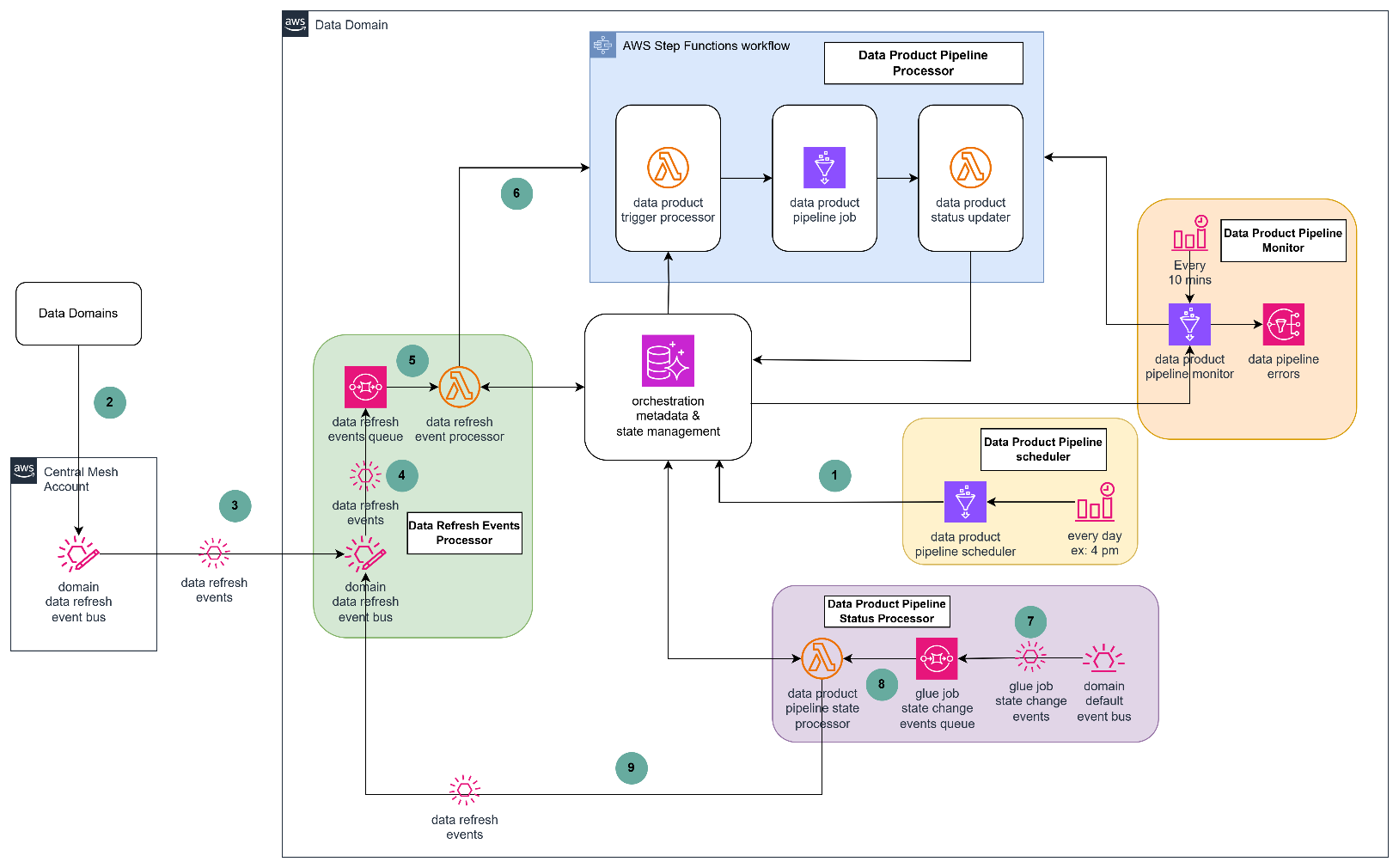
The orchestration solution revolves around five core processors.
Data product pipeline scheduler
The scheduler is a daily scheduled Glue job that finds data products that are due for data refresh based on orchestration metadata and, for each identified data product, the scheduler retrieves both internal and external dependencies and stores them in the orchestration state management system database tables with a status of WAITING.
Data refresh events processor
Data refresh events are emitted from a central event bus and routed to domain-specific event buses. These domain buses send the events to a message queue for asynchronous processing. Any undeliverable events are redirected to a dead-letter queue for further inspection and recovery.
The event processor Lambda function consumes messages from the queue and evaluates whether the incoming event corresponds to any defined dependencies within the domain. If a match is found, the dependency status is updated from WAITING to ARRIVED. The processor also checks whether all dependencies for a given data product have been satisfied. If so, it starts the corresponding pipeline execution workflow by triggering an AWS Step Functions state machine.
Data product pipeline processor
Retrieves orchestration metadata to find the pipeline configuration and associated Glue job and parameters for the target data product. Triggers the Glue job using the retrieved configuration and parameters. This step ensures that the pipeline is launched with the correct context and input values. It also captures the Glue job run Id and updates the data product status to PROCESSING within the orchestration state management database, enabling downstream monitoring and status tracking.
Data product pipeline status processor
Each domain’s EventBridge is configured to listen for AWS Glue job state change events, which are routed to a message queue for asynchronous processing. A processing function evaluates incoming job state events:
- For successful job completions, the corresponding pipeline status is updated from PROCESSING to COMPLETED in the orchestration state database. If the pipeline is configured to publish downstream events, a data refresh event is emitted to the central event bus.
- For failed jobs, the pipeline status is updated from PROCESSING to ERROR, enabling downstream systems to manage exceptions or start retrying of a failed job.
- Sample Glue Job state change events for successful completion. The glue job name from the event is used to update the status of the data product.

Data product pipeline monitor
The pipeline monitoring system operates through an EventBridge scheduled trigger that activates every 10 minutes to scan the orchestration state. During this scan, it identifies data products with satisfied dependencies but pending pipeline execution and initiates those pipelines automatically. When pipeline reruns are necessary, the system resets the orchestration state, allowing the monitor to reassess dependencies and trigger the appropriate pipelines. Any pipeline failures are promptly captured as exception notifications and directed to a dedicated notification queue for thorough analysis and team alerting.
Orchestration metadata data model
The following diagram describes the reference data model for storing the dependencies and state management of the data pipelines.
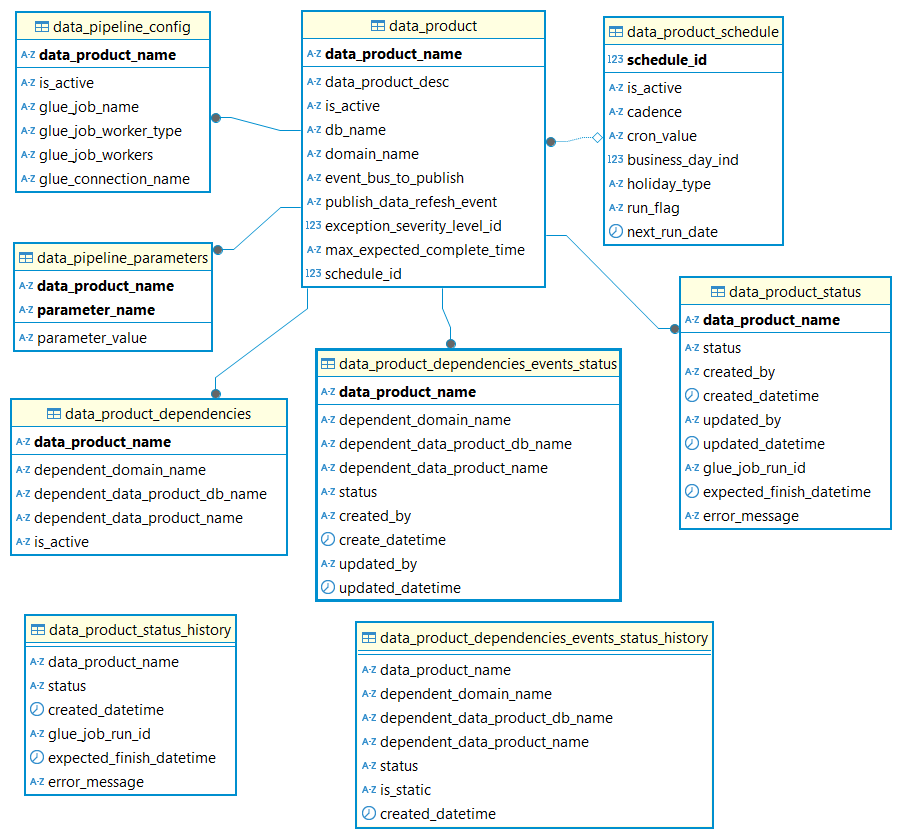
| Table Name | Description |
| data_product | This table stores information on the data product and settings such publishing event for the data product. |
| data_product_dependencies | This table stores information on the data product dependencies for both internal and external data products. |
| data_product_schedule | This table stores information on the data product run schedule (Ex: daily / weekly) |
| data_pipeline_config | This table stores information about the Glue job used for the data pipeline (ex: Name of the glue job, connections) |
| data_pipeline_parameters | This table stores the Glue job parameters |
| data_product_status | This table tracks the execution status of the data product pipeline, transitioning states from ‘Waiting’ to either ‘Complete’ or ‘Error’ based on runtime outcomes |
| data_product_dependencies_events_status | This table stores the status of data dependencies refresh status. It is used to keep track of the dependencies and updates the status as the data refresh events arrive |
| data_product_status_history | This table stores the historical data of data product data pipeline executions for audit and reporting |
| data_product_dependencies_events_status_history | This table stores the historical data of data product data dependency status for audit and reporting |
Outcome
With data pipeline orchestration and use of AWS serverless services, Stifel was able to speed up the data refresh process by cutting down the lag time associated with fixed scheduling of triggering data pipelines as well increase the parallelism of executing the data pipelines which was a constraint with on-premises data platform. This approach offers:
- Scalability by supporting coordination across multiple data domains.
- Reliability through automated tracking and resolution of pipeline dependencies.
- Timeliness by ensuring pipelines are executed precisely when their prerequisites are met.
- Cost optimization by leveraging AWS serverless technologies Lambda for compute, EventBridge for event routing, Aurora Serverless for database operations, and Step Functions for workflow orchestration and pay only for actual usage rather than provisioned capacity while providing automatic scaling to handle varying workloads.
Conclusion
In this post, we showed how a modular, event-driven orchestration solution can effectively manage cross-domain data pipelines. Organizations can refer to this blog post to build robust data pipeline orchestration avoiding rigid schedules and dependencies by leveraging event-based triggers.
Special thanks: This implementation success is a result of close collaboration between Stifel Financial leadership team (Kyle Broussard Managing Director, Martin Nieuwoudt Director of Data Strategy & Analytics) , AWS ProServe, and the AWS account team. We want to thank Stifel Financial Executives and the Leadership Team for the strong sponsorship and direction.