AWS Compute Blog
Category: Compute

Introducing AWS Lambda Powertools for .NET
CloudWatch and AWS X-Ray offer functionality that provides comprehensive observability for your applications. Lambda Powertools .NET is now generally available. The library helps implement observability when running Lambda functions based on .NET 6 while reducing the amount of custom code.

Developing portable AWS Lambda functions
This blog post is written by Uri Segev, Principal Serverless Specialist Solutions Architect When developing new applications or modernizing existing ones, you might face a dilemma: which compute technology to use? A serverless compute service such as AWS Lambda or maybe containers? Often, serverless can be the better approach thanks to automatic scaling, built-in high […]

Enabling Microsoft Defender Credential Guard on Amazon EC2
This blog post is written by Jason Nicholls, Principal Solutions Architect AWS. In this post we show you how to enable Windows Defender Credential Guard (Credential Guard) on Amazon Elastic Compute Cloud (Amazon EC2) running Microsoft Windows Server. Credential Guard, when enabled on Amazon EC2 Windows Instances protects sensitive user login information from being extracted […]

Using Porting Advisor for Graviton
This blog post is written by Ryan Doty Solutions Architect, AWS and Vishal Manan Sr. SSA, EC2 Graviton , AWS. AWS customers recognize that Graviton-based EC2 instances deliver price-performance benefits but many are concerned about the effort to port existing applications. Porting code from one architecture to another can require investment in time and effort. AWS […]

Implementing reactive progress tracking for AWS Step Functions
This blog post is written by Alexey Paramonov, Solutions Architect, ISV and Maximilian Schellhorn, Solutions Architect ISV This blog post demonstrates a solution based on AWS Step Functions and Amazon API Gateway WebSockets to track execution progress of a long running workflow. The solution updates the frontend regularly and users are able to track the […]

How to create custom health checks for your Amazon EC2 Auto Scaling Fleet
This blog post is written by Gaurav Verma, Cloud Infrastructure Architect, Professional Services AWS. Amazon EC2 Auto Scaling helps you maintain application availability and lets you automatically add or remove Amazon Elastic Compute Cloud (Amazon EC2) instances according to the conditions that you define. You can use dynamic and predictive scaling to scale-out and scale-in […]
Scaling an ASG using target tracking with a dynamic SQS target
This blog post is written by Wassim Benhallam, Sr Cloud Application Architect AWS WWCO ProServe, and Rajesh Kesaraju, Sr. Specialist Solution Architect, EC2 Flexible Compute. Scaling an Amazon EC2 Auto Scaling group based on Amazon Simple Queue Service (Amazon SQS) is a commonly used design pattern in decoupled applications. For example, an EC2 Auto Scaling […]
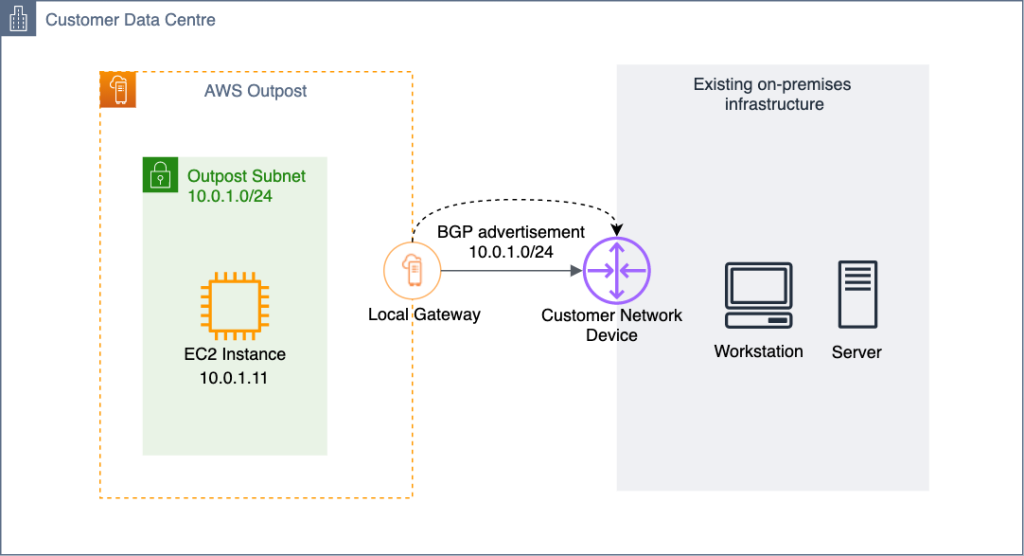
How to choose between CoIP and Direct VPC routing modes on AWS Outposts rack
This blog post is written by Sumit Menaria, Senior Hybrid Solutions Architect AWS WWSO Core Services. AWS Outposts Rack is a fully-managed service that extends AWS infrastructure, services, APIs, and tools to customer premises. By providing local access to AWS managed infrastructure and services, Outposts rack enables customers to build and run applications on premises […]

Introducing new asynchronous invocation metrics for AWS Lambda
Using these new CloudWatch metrics, you can gain visibility into the processing of Lambda asynchronous invocations. This blog explained the new metrics AsyncEventsReceived, AsyncEventAge, and AsyncEventsDropped and how to use them to troubleshoot issues.

Securing CI/CD pipelines with AWS SAM Pipelines and OIDC
AWS SAM Pipeline support for OIDC is a new feature of AWS SAM CLI that simplifies the integration of CI/CD pipelines hosted outside of AWS. Using short-term credentials and scoping AWS actions to specific pipeline tasks reduces risk for your organization.