AWS Compute Blog
Enriching addresses with AWS Lambda and the Amazon Location Service
This post is written by Matthew Nightingale, Associate Solutions Architect.
Traditional methods of performing address validation on geospatial datasets can be expensive and time consuming. Using Amazon Location Service with AWS Lambda in a serverless data processing pipeline, you may achieve significant performance improvements and cost savings on address validation jobs that use geospatial data.
This blog contains a deployable AWS Serverless Application Model (AWS SAM) template. It also uses sample data sourced from publicly available datasets that you can deploy and use to test the application. This blog offers a starting point to build out a serverless address validation pipeline in your own AWS account.
Overview
This application implements a serverless scatter/gather architecture using Lambda and Amazon S3, performing address validation with the Amazon Location Service. An S3 PUT event triggers each Lambda function to run data processing jobs along each step of the pipeline.
To test the application, a user uploads a .CSV file to S3. This dataset is labeled with fields that are recognized by the 2waygeocoder Lambda function. The application returns a processed dataset to S3 appended with location information from the Amazon Location Places API.
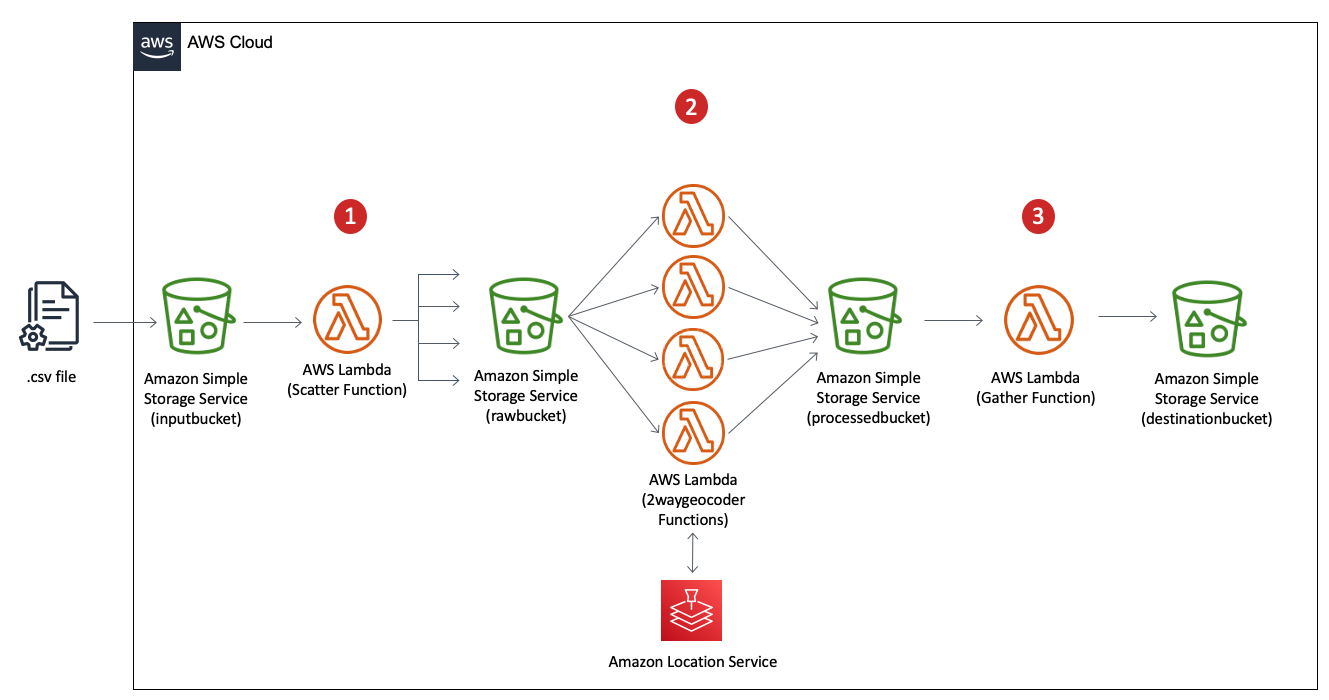
- The Scatter Lambda function takes a dataset from the S3 bucket labeled input and splits it into equally sized shards.
- The Process Lambda function takes each shard from the pre-processed bucket. It performs address validation in parallel with a 2waygeocoder function calling the Amazon Location Service Places API.
- The Gather Lambda function takes each shard from the post-processed bucket. It appends the data into a complete dataset with additional address information.
Amazon Location Service
Amazon Location Service sources high-quality geospatial data from HERE and ESRI to support searches by using a place index resource.
With the Amazon Locations Places API, you can convert addresses and other textual queries into geographic coordinates (also known as geocoding). You can also convert geographic positions into addresses and place descriptions (known as reverse geocoding).
The example application includes a 2waygeocoder capable of both geocoding and reverse geocoding. The next section shows examples of the call and response from the Amazon Location Places API for both geocoding and reverse geocoding.
Geocoding with Amazon Location Service
Here is an example of calling the Amazon Location Service Places API using the AWS SDK for Python (Boto3). This uses the search_place_index_for_text method:
Response = location.search_place_index_for_text(
IndexName = ‘explore.place’
###index is created using Amazon Location service
Text = “Boston, MA”)
location_response = Reponse[“Results”]
print(location_response)
Example response:

Example reverse-geocoding with Amazon Location Service
Here is another example of calling the Amazon Location Service Places API using the AWS SDK for Python (boto3). This uses the search_place_index_for_position method:
Response = location.search_place_index_for_position(
IndexName = ‘explore.place’
###index is created using Amazon Location service
Position = “-71.056739, 42.358660”))
location_response = Reponse[“Results”]
print(location_response)
Example response:

Design considerations
Processing data with Lambda in parallel using a serverless scatter/gather pipeline helps provide performance efficiency at lower cost. To provide even greater performance, you can optimize your Lambda configuration for higher throughput. There are several strategies you can implement to do this and a key few topics to keep in mind.
Increase the allocated memory for your Lambda function
The simplest way to increase throughput is to increase the allocated memory of the Lambda function.
Faster Lambda functions can process more data and increase throughput. This works even if a Lambda function’s memory utilization is low. This is because increasing memory also increases vCPUs in proportion to the amount configured. Each function supports up to 10 GB of memory and you can access up to six vCPUs per function.
To see the average cost and execution speed for each memory configuration, the Lambda Power Tuning tool helps to visualize the tradeoffs.
Optimize shard size
Another method for increasing performance in a serverless scatter/gather architecture is to optimize the total number of shards created by the scatter function. Increasing the total number of shards consequently reduces the size of any single shard, allowing Lambda to process each shard faster.
When scaling with Lambda, one instance of a function handles one request at a time. When the number of requests increases, Lambda creates more instances of the function to process traffic. Because S3 invokes Lambda asynchronously, there is an internal queue buffering requests between the event source and the Lambda service.
In a serverless scatter/gather architecture, having more shards results in more concurrent invocations of the process Lambda function. For more information about scaling and concurrency with Lambda, see this blog post. Increasing concurrency with Lambda can lead to API request throttling.
Consider API request throttling with your concurrent Lambda functions
In a serverless scatter/gather architecture, the rate at which your code calls APIs increases by a factor equal to the number of concurrent Lambda functions. This means API request limits can quickly be exceeded. You must consider Service Quotas and API request limits when trying to increase the performance of your serverless scatter/gather architecture.
For example, the Amazon Location Places APIs called in the processing function of this application has a default limit of 50 API requests per second. The 2waygeocoder calls on average about 12 APIs per second. Splitting the application into more than four shards may cause API throttling exception errors in this case. Requests to increase Service Quotas can be made through your AWS account.
Deploying the solution
You need the following perquisites to deploy the example application:
- AWS account.
- AWS SAM CLI.
- Python 3.9.
- An AWS Identity and Access Management (IAM) role with appropriate access.
Deploy the example application:
- Clone the repository and download the sample source code to your environment where AWS SAM is installed:
git clone https://github.com/aws-samples/amazon-location-service-serverless-address-validation - Change into the project directory containing the template.yaml file:
cd ~/environment/amazon-location-service-serverless-address-validation - Build the application using AWS SAM:
sam build

- Deploy the application to your account using AWS SAM. Be sure to follow proper S3 naming conventions providing globally unique names for S3 buckets:
sam deploy --guided


Testing the application
Testing geocoding
To test the application, download the dataset that is linked in Testing the Application section of the GitHub repository. These tests demonstrate both the geocoding and reverse-geocoding capabilities of the application.
First, test the geocoding capabilities. You perform address validation on the City of Hartford Business Listing dataset linked in the GitHub repository. The dataset contains a listing of all the active businesses registered in the city Hartford, CT, and each business address. The GitHub repo links to an external website where you can download the dataset.
- Download the .csv version of the City of Hartford Business Listing dataset. The link is found in the Testing the Application section of the README file on GitHub.
- Open the file locally to explore its contents.
- Ensure that the .csv file contains columns labeled as “Address”, “City”, and “State”. The 2waygeocoder deployed as part of the AWS SAM template recognizes these columns to perform geocoding.
- Before testing the application’s geocoding capabilities, explore the pricing of Amazon Location Service. In order to save money, you can trim the length of the dataset for testing by removing rows. Once the dataset is trimmed to a desired length, navigate to S3 in the AWS Management Console.
- Upload the dataset to the S3 bucket labeled “input”. This triggers the scatter function.
- Navigate to the S3 bucket labeled “raw” to view the shards of your dataset created by the scatter function.
- Navigate to Lambda and select the 2waygeocoder function to view the CloudWatch Logs to see any information that is returned by the function code in near-real-time.
- Once the data is processed, navigate to the S3 bucket labeled “destination” to view the complete processed dataset that is created by the gather function. It may take several minutes for your dataset to finish processing.
Congratulations! You have successfully geocoded a dataset using Amazon Location Service with a serverless address validation pipeline.
Testing reverse-geocoding
Next, test the reverse-geocoding capabilities of the application. You perform address validation on the Miami Housing Dataset linked in the GitHub repository. This dataset contains information on 13,932 single-family homes sold in Miami. The repo links to an external website where you can download the dataset.
Before testing, explore the pricing of Amazon Location Service. To start the test:
- Download the zip file containing the .csv version of the dataset from . The link is found in the Testing the Application section of the README file on GitHub.
- Open the file locally to explore its contents.
- Ensure the .csv file contains columns A and B labeled “Latitude” and “Longitude”. You must edit these column headers to match the correct format that is recognized by the 2waygeocoder to perform reverse-geocoding. Only the “L” should be capitalized.
- To minimize cost, trim the length of the dataset for testing by removing rows. At the full size of ~13,933 rows, the dataset takes approx. 5 minutes to process.
- Once the dataset is trimmed to a desired length and both column A and B are labeled as “Latitude” and “Longitude” respectively, navigate to S3 in the AWS Management Console, and upload the dataset to your S3 bucket labeled “Input”.
- Navigate to the S3 bucket labeled “raw” to view the shards of your dataset.
- Navigate to Lambda and select the 2waygeocoder function to view the CloudWatch Logs to see any information that is returned by the function code in near-real-time.
- Navigate to the S3 bucket labeled “destination” to view the complete processed dataset that is created by the gather function. It may take several minutes for your dataset to finish processing.
Congratulations! You have successfully reverse-geocoded a dataset with Amazon Location Service using a serverless scatter/gather pipeline. You can move on to the conclusion, or continue to test the geocoding capabilities of the application with additional datasets.
Next steps
To get started testing your own datasets, use the AWS SAM template from GitHub deployed as part of this blog. Ensure that the labels in your dataset are labeled to match the constructs used in this blog post. The 2waygeocoder recognizes columns labeled “Latitude” and “Longitude” to perform reverse-geocoding, and “Address”, “City”, and “State” to perform geocoding.
Now that the data has been geocoded by Amazon Location Service and is in S3, you can use Amazon QuickSight geospatial charts to quickly and easily create interactive charts. For information on how to create a Dataset in QuickSight using Amazon S3 Files, check out the QuickSight User Guide.
Below is an example using QuickSight Geospatial charts to map the Miami housing dataset. The map shows average sale price by zipcode:

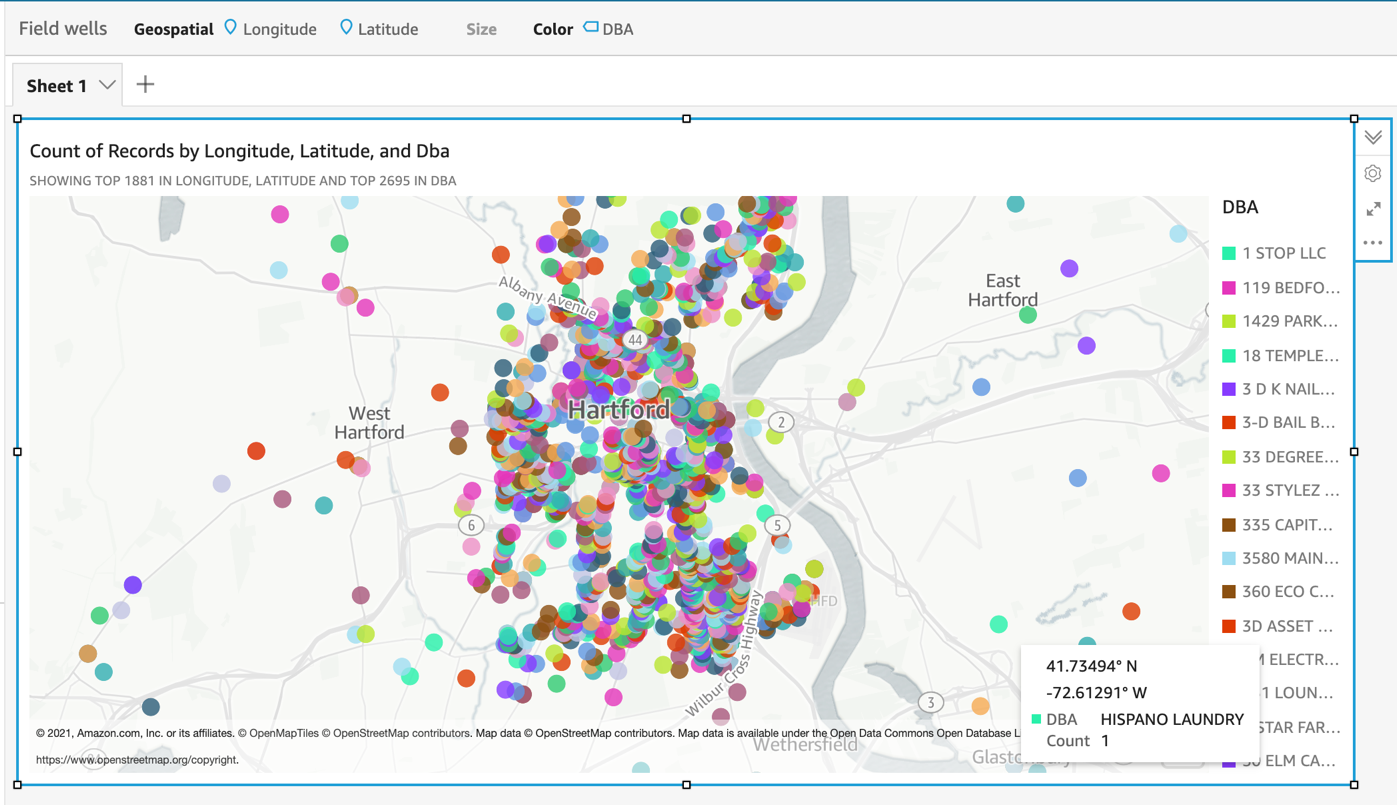
This example uses QuickSight geospatial charts to map the City of Hartford Business dataset. The map shows DBA (doing business as) by latitude and longitude:
Conclusion
This blog post performs address validation with the Amazon Location Service, demonstrating both geocoding and reverse geocoding capabilities.
Using a serverless architecture with S3 and Lambda, you can achieve both cost optimization and performance improvement compared with traditional methods of address validation. Using this application, your organization can better understand and harness geospatial data.
For more serverless learning resources, visit Serverless Land.