AWS Compute Blog
Operating Lambda: Application design – Scaling and concurrency: Part 2
In the Operating Lambda series, I cover important topics for developers, architects, and systems administrators who are managing AWS Lambda-based applications. This three-part series discusses application design for Lambda-based applications.
Part 1 shows how to work with Service Quotas, when to request increases, and architecting with quotas in mind. This post covers scaling and concurrency and the different behaviors of on-demand and Provisioned Concurrency.
Scaling and concurrency in Lambda
Lambda is engineered to provide managed scaling in a way that does not rely upon threading or any custom engineering in your code. As traffic increases, Lambda increases the number of concurrent executions of your functions.
When a function is first invoked, the Lambda service creates an instance of the function and runs the handler method to process the event. After completion, the function remains available for a period of time to process subsequent events. If other events arrive while the function is busy, Lambda creates more instances of the function to handle these requests concurrently.
For an initial burst of traffic, your cumulative concurrency in a Region can reach between 500 and 3000 per minute, depending upon the Region. After this initial burst, functions can scale by an additional 500 instances per minute. If requests arrive faster than a function can scale, or if a function reaches maximum capacity, additional requests fail with a throttling error (status code 429).
All AWS accounts start with a default concurrent limit of 1000 per Region. This is a soft limit that you can increase by submitting a request in the AWS Support Center.
Requests and concurrency
One instance of a Lambda function handles one request at a time. When the number of requests increase, Lambda creates more instances of your function to process traffic. For event sources like SQS, you can use the BatchSize property to allow a function to process more messages per invocation. This may result in having a lower concurrency level because more requests are processed by a single instance.
For asynchronous event sources, like S3, there is an internal queue buffering requests between the event source and the Lambda service. Lambda processes requests from this queue and scales up concurrency. For functions with a short duration, it’s common to see a large number of requests processed by a smaller number of concurrent function instances.
For synchronous event sources, like Amazon API Gateway, the caller waits until Lambda responds. If multiple requests arrive at exactly the same time, there is a one-to-one relationship between the number of incoming requests and the function’s concurrency. This is because function instances process one request at a time. However, if requests are staggered, function instances may handle subsequent requests as they complete previous invocations, resulting in lower overall concurrency.
On-demand scaling example
In this example, a Lambda function receives 10,000 synchronous requests from API Gateway. The concurrency limit for the account is 10,000 and each request takes 15 seconds to complete. The following diagram shows four scenarios:

In each case, all of the requests arrive at the same time in the minute they are scheduled:
- All requests arrive immediately: 3000 requests are handled by new execution environments; 7000 are throttled.
- Requests arrive over 2 minutes: 3000 requests are handled by new execution environments in the first minute; the remaining 2000 are throttled. In minute 2, another 500 environments are created and the 3000 original environments are reused; 1500 are throttled.
- Requests arrive over 3 minutes: 3000 requests are handled by new execution environments in the first minute; the remaining 333 are throttled. In minute 2, another 500 environments are created and the 3000 original environments are reused; all requests are served. In minute 3, the remaining 3334 requests are served by warm environments.
- Requests arrive over 4 minutes: In minute 1, 2500 requests are handled by new execution environment; the same environments are reused in subsequent minutes to serve all requests.
Provisioned Concurrency scaling example
The majority of Lambda workloads are asynchronous so the default scaling behavior provides a reasonable trade-off between throughput and configuration management overhead. However, for synchronous invocations from interactive workloads, such as web or mobile applications, there are times when you need more control over how many concurrent function instances are ready to receive traffic.
Provisioned Concurrency is a Lambda feature that prepares concurrent execution environments in advance of invocations. Consequently, this can be used to address two issues. First, if expected traffic arrives more quickly than the default burst capacity, Provisioned Concurrency can ensure that your function is available to meet the demand. Second, if you have latency-sensitive workloads that require predictable double-digit millisecond latency, Provisioned Concurrency solves the typical cold start issues associated with default scaling.
Provisioned Concurrency is a configuration available for a specific published version or alias of a Lambda function. It does not rely on any custom code or changes to a function’s logic, and it’s compatible with features such as VPC configuration and Lambda layers. For more information on how Provisioned Concurrency optimizes performance for Lambda-based applications, watch this Tech Talk video.
Using the same scenarios with 10,000 requests, the function is configured with a Provisioned Concurrency of 7,000:

- In case #1, 7,000 requests are handled by the provisioned environments with no cold start. The remaining 3,000 requests are handled by new, on-demand execution environments.
- In cases #2-4, all requests are handled by provisioned environments in the minute when they arrive.
Using service integrations and asynchronous processing
Synchronous requests from services like API Gateway require immediate responses. In many cases, these workloads can be rearchitected as asynchronous workloads. In this case, API Gateway can persist messages durably in an Amazon SQS queue by using a service integration. This means that API Gateway invokes SQS directly without using a Lambda function as an intermediary step.
Once the message is sent to SQS, a Lambda function consumes these messages from the queue and updates the status in an Amazon DynamoDB table. Another API endpoint provides the status of the request by querying the DynamoDB table:
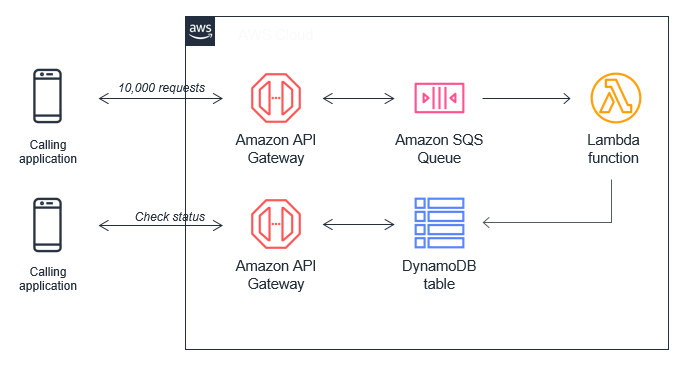
API Gateway has a default throttle limit of 10,000 requests per second, which can be raised upon request. SQS standard queues support a virtually unlimited throughput of API actions such as SendMessage.
The Lambda function consuming the messages from SQS can control the speed of processing through a combination of two factors. The first is BatchSize, which is the number of messages received by each invocation of the function, and the second is concurrency. Provided there is still concurrency available in your account, the Lambda function is not throttled while processing messages from an SQS queue.
In asynchronous workflows, it’s not possible to pass the result of the function back through the invocation path. The original API Gateway call receives an acknowledgment that the message has been stored in SQS, which is returned back to the caller. There are multiple mechanisms for returning the result back to the caller. One uses a DynamoDB table, as shown, to store a transaction ID and status, which is then polled by the caller via another API Gateway endpoint until the work is finished. Alternatively, you can use webhooks via Amazon SNS or WebSockets via AWS IoT Core to return the result.
Using this asynchronous approach can make it much easier to handle unpredictable traffic with significant volumes. While it is not suitable for every use case, it can simplify scalability operations.
Reserved concurrency
Lambda functions in a single AWS account in one Region share the concurrency limit. If one function exceeds the concurrent limit, this prevents other functions from being invoked by the Lambda service. You can set reserved capacity for Lambda functions to ensure that they can be invoked even if the overall capacity has been exhausted. Reserved capacity has two effects on a Lambda function:
- The reserved capacity is deducted from the overall capacity for the AWS account in a given Region. The Lambda function always has the reserved capacity available exclusively for its own invocations.
- The reserved capacity restricts the maximum number of concurrency invocations for that function. Synchronous requests arriving in excess of the reserved capacity limit fail with a throttling error.
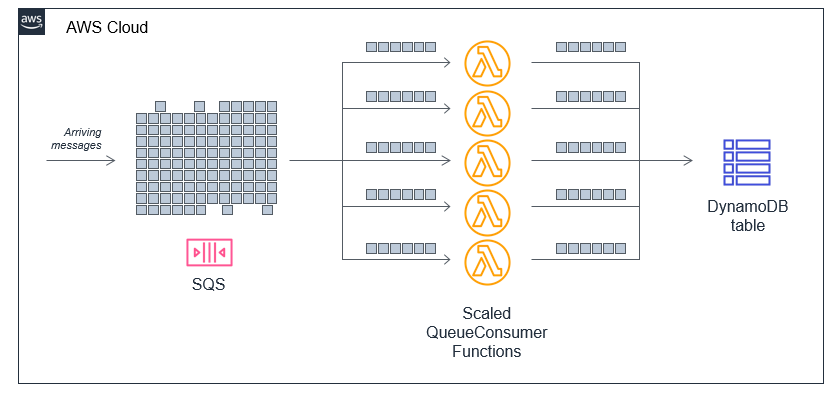
You can also use reserved capacity to throttle the rate of requests processed by your workload. For Lambda functions that are invoked asynchronously or using an internal poller, such as for S3, SQS, or DynamoDB integrations, reserved capacity limits how many requests are processed simultaneously. In this case, events are stored durably in internal queues until the Lambda function is available. This can help create a smoothing effect for handling spiky levels of traffic.
For example, a Lambda function receives messages from an SQS queue and writes to a DynamoDB table. It has a reserved concurrency of 10 with a batch size of 10 items. The SQS queue rapidly receives 1,000 messages. The Lambda function scales up to 10 concurrent instances, each processing 10 messages from the queue. While it takes longer to process the entire queue, this results in a consistent rate of write capacity units (WCUs) consumed by the DynamoDB table.
To learn more, read “Managing AWS Lambda Function Concurrency” and “Managing concurrency for a Lambda function”.
Conclusion
This post explains scaling and concurrency in Lambda and the different behaviors of on-demand and Provisioned Concurrency. It also shows how to use service integrations and asynchronous patterns in Lambda-based applications. Finally, I discuss how reserved concurrency works and how to use it in your application design.
Part 3 discusses choosing and managing runtimes, networking and VPC configurations, and different invocation modes.
For more serverless learning resources, visit Serverless Land.