AWS Compute Blog
Managing AWS Lambda Function Concurrency
One of the key benefits of serverless applications is the ease in which they can scale to meet traffic demands or requests, with little to no need for capacity planning. In AWS Lambda, which is the core of the serverless platform at AWS, the unit of scale is a concurrent execution. This refers to the number of executions of your function code that are happening at any given time.
Thinking about concurrent executions as a unit of scale is a fairly unique concept. In this post, I dive deeper into this and talk about how you can make use of per function concurrency limits in Lambda.
Understanding concurrency in Lambda
Instead of diving right into the guts of how Lambda works, here’s an appetizing analogy: a magical pizza.
Yes, a magical pizza!
This magical pizza has some unique properties:
- It has a fixed maximum number of slices, such as 8.
- Slices automatically re-appear after they are consumed.
- When you take a slice from the pizza, it does not re-appear until it has been completely consumed.
- One person can take multiple slices at a time.
- You can easily ask to have the number of slices increased, but they remain fixed at any point in time otherwise.
Now that the magical pizza’s properties are defined, here’s a hypothetical situation of some friends sharing this pizza.
Shawn, Kate, Daniela, Chuck, Ian and Avleen get together every Friday to share a pizza and catch up on their week. As there is just six of them, they can easily all enjoy a slice of pizza at a time. As they finish each slice, it re-appears in the pizza pan and they can take another slice again. Given the magical properties of their pizza, they can continue to eat all they want, but with two very important constraints:
- If any of them take too many slices at once, the others may not get as much as they want.
- If they take too many slices, they might also eat too much and get sick.
One particular week, some of the friends are hungrier than the rest, taking two slices at a time instead of just one. If more than two of them try to take two pieces at a time, this can cause contention for pizza slices. Some of them would wait hungry for the slices to re-appear. They could ask for a pizza with more slices, but then run the same risk again later if more hungry friends join than planned for.
What can they do?
If the friends agreed to accept a limit for the maximum number of slices they each eat concurrently, both of these issues are avoided. Some could have a maximum of 2 of the 8 slices, or other concurrency limits that were more or less. Just so long as they kept it at or under eight total slices to be eaten at one time. This would keep any from going hungry or eating too much. The six friends can happily enjoy their magical pizza without worry!
Concurrency in Lambda
Concurrency in Lambda actually works similarly to the magical pizza model. Each AWS Account has an overall AccountLimit value that is fixed at any point in time, but can be easily increased as needed, just like the count of slices in the pizza. As of May 2017, the default limit is 1000 “slices” of concurrency per AWS Region.
Also like the magical pizza, each concurrency “slice” can only be consumed individually one at a time. After consumption, it becomes available to be consumed again. Services invoking Lambda functions can consume multiple slices of concurrency at the same time, just like the group of friends can take multiple slices of the pizza.
Let’s take our example of the six friends and bring it back to AWS services that commonly invoke Lambda:
- Amazon S3
- Amazon Kinesis
- Amazon DynamoDB
- Amazon Cognito
In a single account with the default concurrency limit of 1000 concurrent executions, any of these four services could invoke enough functions to consume the entire limit or some part of it. Just like with the pizza example, there is the possibility for two issues to pop up:
- One or more of these services could invoke enough functions to consume a majority of the available concurrency capacity. This could cause others to be starved for it, causing failed invocations.
- A service could consume too much concurrent capacity and cause a downstream service or database to be overwhelmed, which could cause failed executions.
For Lambda functions that are launched in a VPC, you have the potential to consume the available IP addresses in a subnet or the maximum number of elastic network interfaces to which your account has access. For more information, see Configuring a Lambda Function to Access Resources in an Amazon VPC. For information about elastic network interface limits, see Network Interfaces section in the Amazon VPC Limits topic.
One way to solve both of these problems is applying a concurrency limit to the Lambda functions in an account.
Configuring per function concurrency limits
You can now set a concurrency limit on individual Lambda functions in an account. The concurrency limit that you set reserves a portion of your account level concurrency for a given function. All of your functions’ concurrent executions count against this account-level limit by default.
If you set a concurrency limit for a specific function, then that function’s concurrency limit allocation is deducted from the shared pool and assigned to that specific function. AWS also reserves 100 units of concurrency for all functions that don’t have a specified concurrency limit set. This helps to make sure that future functions have capacity to be consumed.
Going back to the example of the consuming services, you could set throttles for the functions as follows:
Amazon S3 function = 350
Amazon Kinesis function = 200
Amazon DynamoDB function = 200
Amazon Cognito function = 150
Total = 900
With the 100 reserved for all non-concurrency reserved functions, this totals the account limit of 1000.
Here’s how this works. To start, create a basic Lambda function that is invoked via Amazon API Gateway. This Lambda function returns a single “Hello World” statement with an added sleep time between 2 and 5 seconds. The sleep time simulates an API providing some sort of capability that can take a varied amount of time. The goal here is to show how an API that is underloaded can reach its concurrency limit, and what happens when it does.
To create the example function
- Open the Lambda console.
- Choose Create Function.
- For Author from scratch, enter the following values:
- For Name, enter a value (such as concurrencyBlog01).
- For Runtime, choose Python 3.6.
- For Role, choose Create new role from template and enter a name aligned with this function, such as concurrencyBlogRole.
- Choose Create function.
- The function is created with some basic example code. Replace that code with the following:
import time
from random import randint
seconds = randint(2, 5)
def lambda_handler(event, context):
time.sleep(seconds)
return {"statusCode": 200,
"body": ("Hello world, slept " + str(seconds) + " seconds"),
"headers":
{
"Access-Control-Allow-Headers": "Content-Type,X-Amz-Date,Authorization,X-Api-Key,X-Amz-Security-Token",
"Access-Control-Allow-Methods": "GET,OPTIONS",
}}

- Under Basic settings, set Timeout to 10 seconds. While this function should only ever take up to 5-6 seconds (with the 5-second max sleep), this gives you a little bit of room if it takes longer.

- Choose Save at the top right.
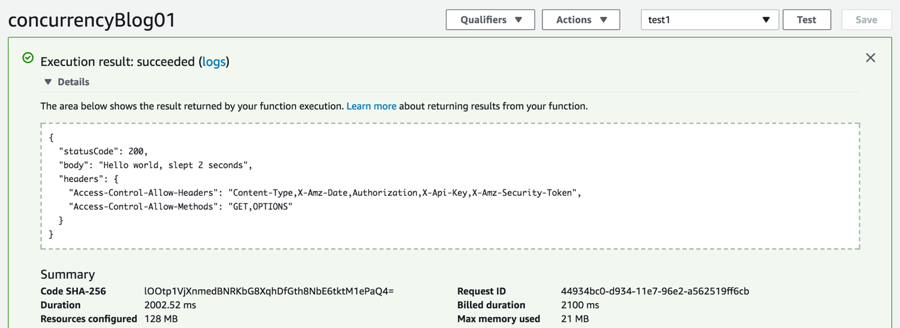
At this point, your function is configured for this example. Test it and confirm this in the console:
- Choose Test.
- Enter a name (it doesn’t matter for this example).
- Choose Create.
- In the console, choose Test again.
- You should see output similar to the following:
Now configure API Gateway so that you have an HTTPS endpoint to test against.
- In the Lambda console, choose Configuration.
- Under Triggers, choose API Gateway.
- Open the API Gateway icon now shown as attached to your Lambda function:

- Under Configure triggers, leave the default values for API Name and Deployment stage. For Security, choose Open.
- Choose Add, Save.
API Gateway is now configured to invoke Lambda at the Invoke URL shown under its configuration. You can take this URL and test it in any browser or command line, using tools such as “curl”:
$ curl https://ofixul557l.execute-api.us-east-1.amazonaws.com/prod/concurrencyBlog01
Hello world, slept 2 seconds
Throwing load at the function
Now start throwing some load against your API Gateway + Lambda function combo. Right now, your function is only limited by the total amount of concurrency available in an account. For this example account, you might have 850 unreserved concurrency out of a full account limit of 1000 due to having configured a few concurrency limits already (also the 100 concurrency saved for all functions without configured limits). You can find all of this information on the main Dashboard page of the Lambda console:

For generating load in this example, use an open source tool called “hey” (https://github.com/rakyll/hey), which works similarly to ApacheBench (ab). You test from an Amazon EC2 instance running the default Amazon Linux AMI from the EC2 console. For more help with configuring an EC2 instance, follow the steps in the Launch Instance Wizard.
After the EC2 instance is running, SSH into the host and run the following:
sudo yum install go
go get -u github.com/rakyll/hey
“hey” is easy to use. For these tests, specify a total number of tests (5,000) and a concurrency of 50 against the API Gateway URL as follows(replace the URL here with your own):
$ ./go/bin/hey -n 5000 -c 50 https://ofixul557l.execute-api.us-east-1.amazonaws.com/prod/concurrencyBlog01
The output from “hey” tells you interesting bits of information:
$ ./go/bin/hey -n 5000 -c 50 https://ofixul557l.execute-api.us-east-1.amazonaws.com/prod/concurrencyBlog01
Summary:
Total: 381.9978 secs
Slowest: 9.4765 secs
Fastest: 0.0438 secs
Average: 3.2153 secs
Requests/sec: 13.0891
Total data: 140024 bytes
Size/request: 28 bytes
Response time histogram:
0.044 [1] |
0.987 [2] |
1.930 [0] |
2.874 [1803] |∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎
3.817 [1518] |∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎
4.760 [719] |∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎
5.703 [917] |∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎
6.647 [13] |
7.590 [14] |
8.533 [9] |
9.477 [4] |
Latency distribution:
10% in 2.0224 secs
25% in 2.0267 secs
50% in 3.0251 secs
75% in 4.0269 secs
90% in 5.0279 secs
95% in 5.0414 secs
99% in 5.1871 secs
Details (average, fastest, slowest):
DNS+dialup: 0.0003 secs, 0.0000 secs, 0.0332 secs
DNS-lookup: 0.0000 secs, 0.0000 secs, 0.0046 secs
req write: 0.0000 secs, 0.0000 secs, 0.0005 secs
resp wait: 3.2149 secs, 0.0438 secs, 9.4472 secs
resp read: 0.0000 secs, 0.0000 secs, 0.0004 secs
Status code distribution:
[200] 4997 responses
[502] 3 responses
You can see a helpful histogram and latency distribution. Remember that this Lambda function has a random sleep period in it and so isn’t entirely representational of a real-life workload. Those three 502s warrant digging deeper, but could be due to Lambda cold-start timing and the “second” variable being the maximum of 5, causing the Lambda functions to time out. AWS X-Ray and the Amazon CloudWatch logs generated by both API Gateway and Lambda could help you troubleshoot this.
Configuring a concurrency reservation
Now that you’ve established that you can generate this load against the function, I show you how to limit it and protect a backend resource from being overloaded by all of these requests.
- In the console, choose Configure.
- Under Concurrency, for Reserve concurrency, enter 25.
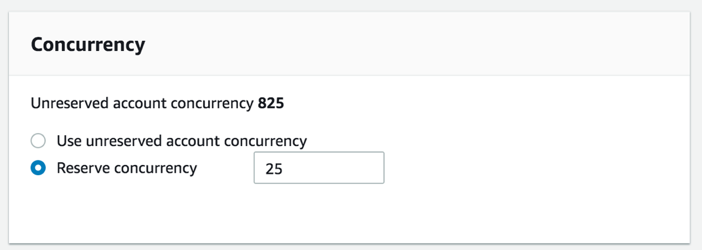
- Click on Save in the top right corner.
You could also set this with the AWS CLI using the Lambda put-function-concurrency command or see your current concurrency configuration via Lambda get-function. Here’s an example command:
$ aws lambda get-function --function-name concurrencyBlog01 --output json --query Concurrency
{
"ReservedConcurrentExecutions": 25
}
Either way, you’ve set the Concurrency Reservation to 25 for this function. This acts as both a limit and a reservation in terms of making sure that you can execute 25 concurrent functions at all times. Going above this results in the throttling of the Lambda function. Depending on the invoking service, throttling can result in a number of different outcomes, as shown in the documentation on Throttling Behavior. This change has also reduced your unreserved account concurrency for other functions by 25.
Rerun the same load generation as before and see what happens. Previously, you tested at 50 concurrency, which worked just fine. By limiting the Lambda functions to 25 concurrency, you should see rate limiting kick in. Run the same test again:
$ ./go/bin/hey -n 5000 -c 50 https://ofixul557l.execute-api.us-east-1.amazonaws.com/prod/concurrencyBlog01
While this test runs, refresh the Monitoring tab on your function detail page. You see the following warning message:

This is great! It means that your throttle is working as configured and you are now protecting your downstream resources from too much load from your Lambda function.
Here is the output from a new “hey” command:
$ ./go/bin/hey -n 5000 -c 50 https://ofixul557l.execute-api.us-east-1.amazonaws.com/prod/concurrencyBlog01
Summary:
Total: 379.9922 secs
Slowest: 7.1486 secs
Fastest: 0.0102 secs
Average: 1.1897 secs
Requests/sec: 13.1582
Total data: 164608 bytes
Size/request: 32 bytes
Response time histogram:
0.010 [1] |
0.724 [3075] |∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎∎
1.438 [0] |
2.152 [811] |∎∎∎∎∎∎∎∎∎∎∎
2.866 [11] |
3.579 [566] |∎∎∎∎∎∎∎
4.293 [214] |∎∎∎
5.007 [1] |
5.721 [315] |∎∎∎∎
6.435 [4] |
7.149 [2] |
Latency distribution:
10% in 0.0130 secs
25% in 0.0147 secs
50% in 0.0205 secs
75% in 2.0344 secs
90% in 4.0229 secs
95% in 5.0248 secs
99% in 5.0629 secs
Details (average, fastest, slowest):
DNS+dialup: 0.0004 secs, 0.0000 secs, 0.0537 secs
DNS-lookup: 0.0002 secs, 0.0000 secs, 0.0184 secs
req write: 0.0000 secs, 0.0000 secs, 0.0016 secs
resp wait: 1.1892 secs, 0.0101 secs, 7.1038 secs
resp read: 0.0000 secs, 0.0000 secs, 0.0005 secs
Status code distribution:
[502] 3076 responses
[200] 1924 responses
This looks fairly different from the last load test run. A large percentage of these requests failed fast due to the concurrency throttle failing them (those with the 0.724 seconds line). The timing shown here in the histogram represents the entire time it took to get a response between the EC2 instance and API Gateway calling Lambda and being rejected. It’s also important to note that this example was configured with an edge-optimized endpoint in API Gateway. You see under Status code distribution that 3076 of the 5000 requests failed with a 502, showing that the backend service from API Gateway and Lambda failed the request.
Other uses
Managing function concurrency can be useful in a few other ways beyond just limiting the impact on downstream services and providing a reservation of concurrency capacity. Here are two other uses:
- Emergency kill switch
- Cost controls
Emergency kill switch
On occasion, due to issues with applications I’ve managed in the past, I’ve had a need to disable a certain function or capability of an application. By setting the concurrency reservation and limit of a Lambda function to zero, you can do just that.
With the reservation set to zero every invocation of a Lambda function results in being throttled. You could then work on the related parts of the infrastructure or application that aren’t working, and then reconfigure the concurrency limit to allow invocations again.
Cost controls
While I mentioned how you might want to use concurrency limits to control the downstream impact to services or databases that your Lambda function might call, another resource that you might be cautious about is money. Setting the concurrency throttle is another way to help control costs during development and testing of your application.
You might want to prevent against a function performing a recursive action too quickly or a development workload generating too high of a concurrency. You might also want to protect development resources connected to this function from generating too much cost, such as APIs that your Lambda function calls.
Conclusion
Concurrent executions as a unit of scale are a fairly unique characteristic about Lambda functions. Placing limits on how many concurrency “slices” that your function can consume can prevent a single function from consuming all of the available concurrency in an account. Limits can also prevent a function from overwhelming a backend resource that isn’t as scalable.
Unlike monolithic applications or even microservices where there are mixed capabilities in a single service, Lambda functions encourage a sort of “nano-service” of small business logic directly related to the integration model connected to the function. I hope you’ve enjoyed this post and configure your concurrency limits today!