Containers
Developers guide to using Amazon EFS with Amazon ECS and AWS Fargate – Part 1
We have recently introduced a native integration between Amazon Elastic Container Service (ECS) and Amazon Elastic File System (EFS). Amazon ECS is a fully managed container orchestrator service purpose-built for the cloud and integrated with other AWS services. ECS supports deploying containers (wrapped in so called tasks) on both Amazon EC2 and AWS Fargate. Amazon EFS is a fully managed, elastic, shared file system designed to be consumed by other AWS services, such as ECS, or EC2 instances. Amazon EFS scales transparently, replicates your data, and makes it available across Availability Zones and supports multiple storage tiers to meet the demands of the majority of workloads.
This integration works for all ECS customers using either EC2 instances or Fargate. This integration has been enabled for Fargate via platform version 1.4, which we have recently released.
Before we start, it is important to call out that this integration is orchestrator-specific because it is an Amazon ECS task-level configuration that applies to both ECS on EC2 as well as ECS on Fargate. Amazon EKS has different integration mechanisms for EFS. For EKS on EC2, you can refer to this link in the EKS documentation. For EKS on Fargate, you can track this GitHub roadmap item because, at the time of this writing, the integration is still being worked on.
If you are not familiar with how ECS, EC2, and Fargate relate to each other, I strongly recommend you to read this blog post to clear the air.
We believe that this integration is so impactful and valuable to our customers that we have created a series of three blog posts that are going to touch on multiple angles of this integration. They cover key three aspects that we learned our ECS customers want to explore for this integration: the philosophy and scope, the technology, and a how-to example:
- Part 1: [this blog post] An overview of the need for EFS support, the technology basics and scope of the integration and the customer use-cases this release unlocks
- Part 2: A deep dive on how EFS security works in container deployments based on ECS and Fargate with some high-level considerations around regional ECS and EFS deployments best practices
- Part 3: A practical example, including reusable code and commands, of a containerized application deployed on ECS tasks that use EFS
Without further ado, let’s kick off Part 1.
Stateless vs. stateful containers philosophy
There are lots of opinions in the industry related to whether containers should be stateless or stateful. To be clear, all containers are stateless in the sense that what has historically been considered container storage is ephemeral and always only tied to the lifecycle of the container itself. A good parallel would be to try to think about how EC2 instance store works. So the “state“ must always be stored outside of the container. Because of this, proponents of stateless containers have historically recommended to use external fully de-coupled services for storing state and data. The communication between these services is achieved through API calls in a typical service-to-service pattern. Think, for example, about a container leveraging Amazon S3, Amazon DynamoDB, Amazon Aurora, and so forth.
However, the landscape is quickly changing. We have seen solid technical advancements in the context of container runtimes in managing storage. This has enabled possibilities that go beyond the original ephemeral container storage. Now it is possible to have stateful containers leveraging the notion of volume storage. This is a more tightly coupled architecture where the communication between the container and the storage isn’t service-to-service but it is rather achieved through common storage protocols. This allows, for example, mounting and attaching network volumes that are decoupled from the container lifecycle. The integration between ECS and EFS represents the introduction of a completely elastic managed file system available to containers. This file system can be seen as “serverless storage” and it complements containers allowing them to persist state in a very cloud-native way.
To be clear, the distinction between stateful containers and the need to access external services is not mutually exclusive. The fact that you are using a stateful container doesn’t mean you may not need to connect to external services with a service-to-service pattern.
Your container may require local persistency (via volume storage) for convenience, architectural, or legacy reasons and be done with it. For example, you have a legacy standalone web application that just needs to persist configuration parameters in a file called /data/server.json. And that’s perhaps all you need. EFS and ECS together allow you to achieve that with strong consistency across Availability Zones thus making it easy and transparent to implement a Multi-AZ deployment.
However, another stateful container may need to connect to external services. For example, you want to set up a scalable and highly available WordPress site where the containers running WordPress both need a way to share persistent web content across the various scale-out WordPress containers (you could achieve this with volume storage), as well as have access to a backend Aurora database.
It’s all about being able to use core architectural patterns (which now include an easy way to set up stateful container) to achieve what you need. This series of blog posts focus on using Amazon EFS as the volume storage provider but be mindful you can have other providers, such as EC2 instance store or EC2 EBS, making available volume storage for containers.
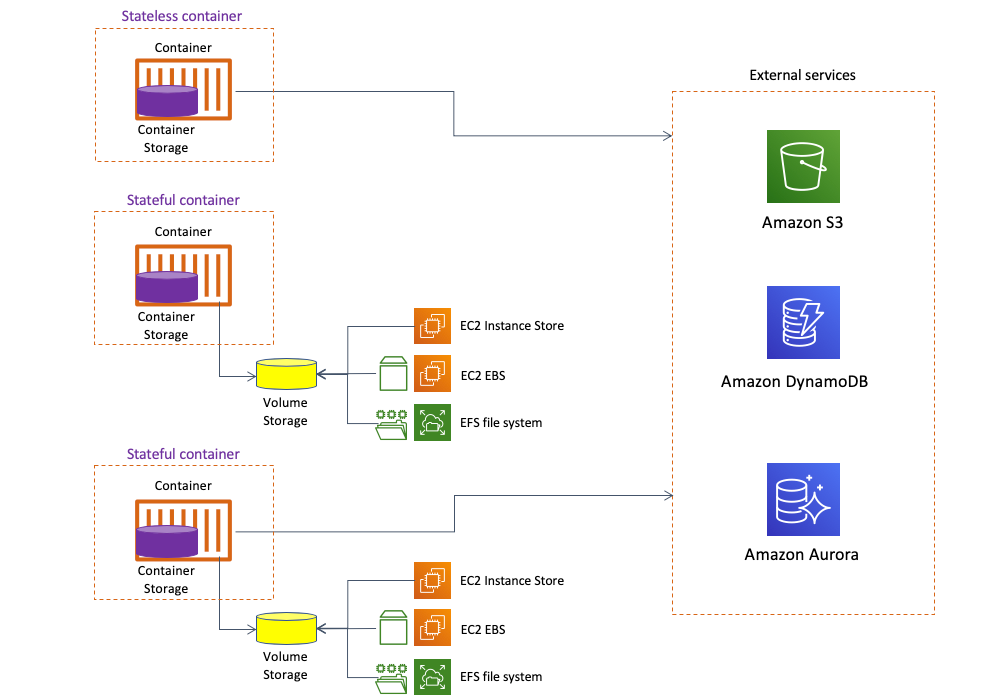
Of course the level of performance, redundancy, availability, and flexibility of your end solution is going to be different depending on the volume storage provider you choose. For example:
- Consuming volumes from an EC2 instance store ties the container to that specific EC2 instance
- Consuming volumes from an EC2 EBS disk ties the container to a specific AZ
- Consuming volumes from an EFS file system allows you to work cross-AZ
Interestingly, these stateless vs. stateful discussions aren’t new and what we are witnessing today are not new patterns. We have been observing them for more than a decade now. When AWS introduced EC2 back in 2006 it only supported ephemeral storage. Based on customer feedback and high demand, we then added EBS support and this unblocked a great number of use cases that couldn’t be fulfilled using local ephemeral storage.
And if customer demand is any indicator of the usefulness of a feature, we have had well over a thousand reactions on the feature request on our public roadmap for the feature we are discussing in this blog post series.
The opportunity
Everything we are going to discuss from this point on refers to how to run an application that requires persistent storage, regardless of whether they will also need to talk to other backend services following service-to-service pattern.
Up until the introduction of this feature, customers had the option to consume, from within an ECS task, the local file system of the virtual machine they were running the task on (also known as container storage). This was true for an ECS task running on EC2 or Fargate. The limitation of this setup was that the file system the task was using was tied to the specific EC2 instance or the dedicated virtual machine the Fargate fleet makes available. This means that the data customers were saving was tied to the infrastructure they were using at that point in time. Should the EC2 instance stop for any reason and the task was to be restarted on another EC2 instance the data is gone. Similarly, if the Fargate task was stopped and restarted, the data would no longer be available:
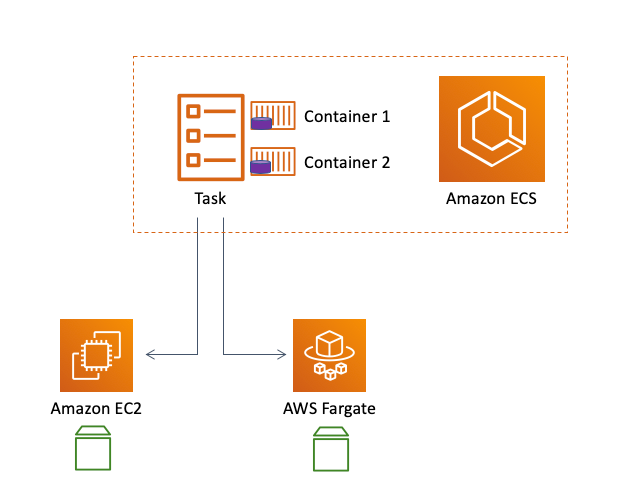
In order to create more flexibility and more independence between the compute fabric (EC2 or Fargate) and storage, some customers decided to configure their compute platform to map external storage and let their tasks consume that external storage. This allowed them to decouple the tasks from the storage achieving a good level of flexibility (via so called volume storage). There are other examples we made available for leveraging EFS as external storage services for ECS tasks.
These were all valid mechanisms to achieve this compute and storage independence but there are a couple of main reasons why they were not optimal:
- They only work for the ECS with EC2 launch type use-case. They cannot work with Fargate. Those mechanisms require you to configure your data plane to do certain things (such as installing drivers and mounting external storage at the instance level). This cannot be done with Fargate because there is no access to the underlying infrastructure.
- These mechanisms push a lot of the undifferentiated heavy lifting associated to the infrastructure configuration onto the customer. There are a lot of configurations that need to be done to allow ECS tasks to consume transparently this decoupled storage. This is not rocket-science but still nothing that adds business value directly.
This is a visual representation of the situation before the availability of the ECS and EFS integration:
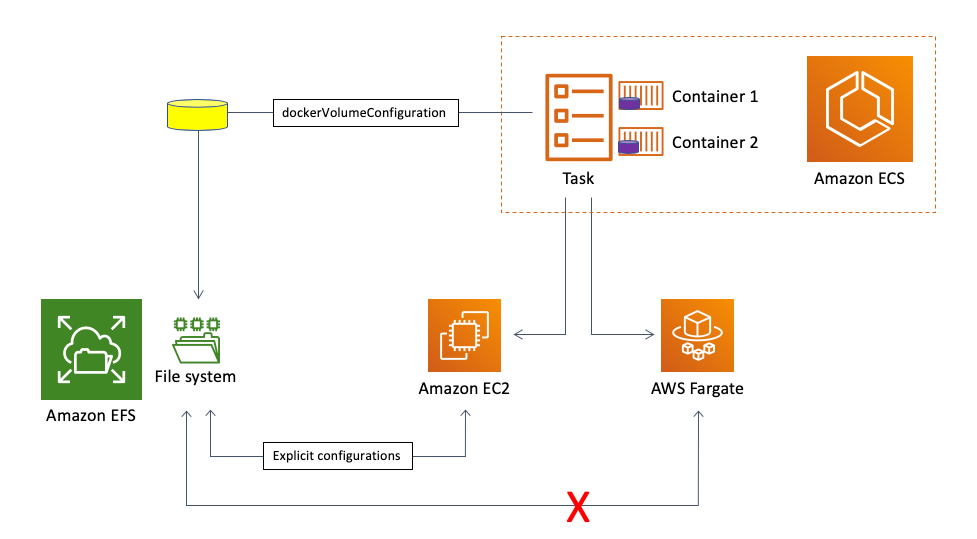
The opportunity consisted of both simplifying the EC2 experience as well as enabling the AWS Fargate experience.
The solution
Before we dive into the details of integration itself and what it enables, let’s define its scope first. With this integration, it is now possible to mount an EFS file system endpoint inside an ECS task. The ECS task can run on an EC2 instance or on Fargate depending on the launch type you opted to use. Regardless of this choice, your ECS on EC2 task or your ECS on Fargate task will be able to natively map an EFS file system endpoint transparently without further infrastructure configurations. More on this later.
Assuming the EFS file system exists, there is nothing the user needs to configure at the infrastructure level (both on EC2 or Fargate). This integration works directly between the ECS task and Amazon EFS just by using the new EFSVolumeConfiguration directive inside the task definition.
This is a visual representation of how this integration works:
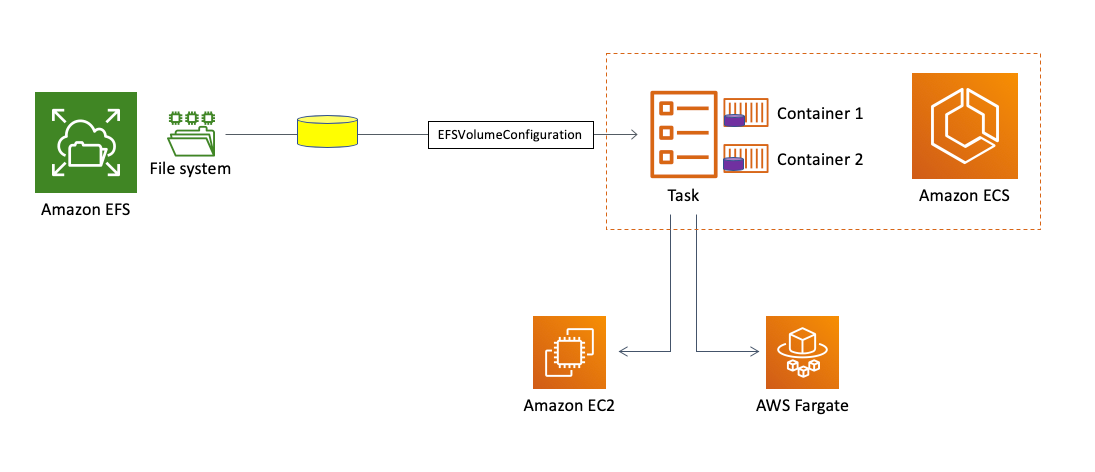
This tutorial on the ECS documentation guides you through how this integration actually works. It shows how you can create an EFS volume and map it across ECS tasks using the aforementioned EFSVolumeConfiguration directive.
Use cases that the Amazon ECS and Amazon EFS integration can unlock
We have heard from customers this feature will unlock a lot of uses cases they wanted to implement but could not. This is especially true for Fargate where mapping external volumes wasn’t just onerous but simply not possible. These use cases tend to fall into a couple of major buckets:
- Stateful tasks to run workloads that require file system persistence
- Multiple tasks that access a shared file system for parallel computation
Stateful standalone tasks to run applications that require file system persistency
Containers are the ideal tool for light and stateless workloads that scale horizontally easily. However, a set of workloads that customers are trying to run on Fargate require and can take advantage of some level of storage persistence. There is a set of applications a number of customers want to move to Fargate that require persistent storage capabilities.
With this in mind, imagine having to support an existing standalone application that requires configuration files to be persisted in, for example, /server/config.json and a tiny amount of data in a /data directory. This application may not even support any type of clustering technology and only relies on mechanisms to restart the application single instance and assuming to be able to find both /server/config.json and /data after the restart where they were left.
In the scenario outlined below, the Fargate task running the application is storing its assets (/server/config.json and /data) on Amazon EFS. Assuming this task runs as part of an ECS service, should this task stop for any reasons, ECS will restart the task, possibly even in another Availability Zone, reconnect it to the same remote file system and the application is back up crunching requests where it left:

One use case customers have brought to us is applications that need to access a set of data on a file system but that do not need to be always-on. Imagine an application that only needs to run twice a week to crunch data on a network share. Prior to this integration, you either had to run a Fargate task indefinitely to maintain that data in the ephemeral container storage. This was very risky because if the application failed and the task had to be restarted, all local data would be lost. Also, you’d be paying for a long running task that was crunching data only 30% of the time. Leveraging the ECS integration with EFS, you can now decouple the dataset from the task lifecycle thus mitigating data loss risks as well optimizing your bill.
Multiple tasks that access in parallel a shared file system
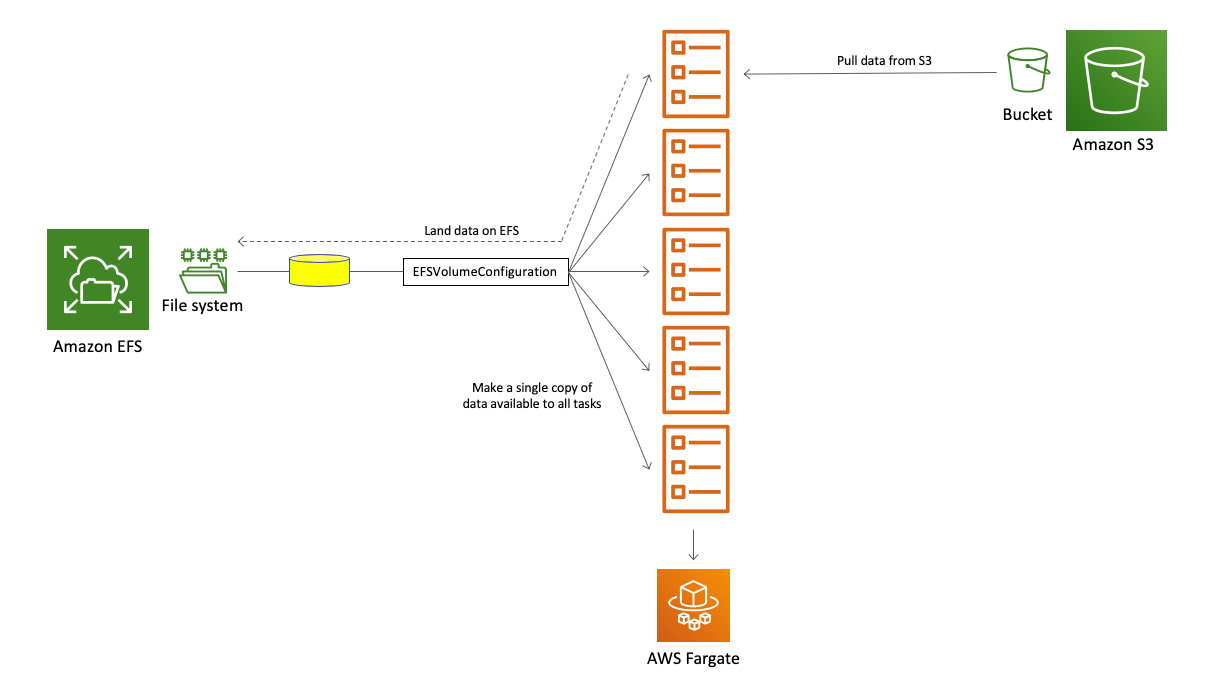
Another interesting use case this integration unlocks is the possibility to share among a large number of ECS tasks, running on either EC2 or Fargate, a common shared file system for parallel access. The example in our tutorial covers this use case from a web farm perspective (where the HTML content being served is centralized and mounted in read-only on each task). This is similar to how you’d need to scale the front end of a highly available WordPress setup. But imagine even more advanced scenarios where you have a large dataset hosted on S3 that your tasks need to pull and act upon. ML training and inference use cases are another good example that could take advantage of this shared file system pattern. Prior to this integration every task would have had to pull data from S3 and save it locally on the ephemeral storage available in the task (if it fits). Now there is an option for one of the tasks to pull data from S3 and put them on EFS where all the other tasks could access them. Users are already excited about this specific use case.
This graphic representation tries to summarize this flow:
Conclusions
This concludes Part 1. So far we discussed the motivations, the scope, and the use cases that this integration enables. You can now move to Part 2 which is going to go a level deeper into discussing how Amazon EFS works and how you can build regionally resilient deployments based on EFS, ECS and Fargate.