AWS Database Blog
Archive data from Amazon DocumentDB (with MongoDB compatibility) to Amazon S3
In this post, we show you how to archive older, less frequently accessed document collections stored in Amazon DocumentDB (with MongoDB compatibility) to Amazon Simple Storage Service (Amazon S3). Amazon DocumentDB is a fast, scalable, highly available, and fully managed document database service that supports MongoDB workloads. Amazon S3 provides a highly durable, cost-effective archive destination that you can query using Amazon Athena using standard SQL. You can use Amazon DocumentDB and Amazon S3 to create a cost-effective JSON storage hierarchy for archival use cases to do the following:
- Support an organization’s compliance requirements in accordance with policies, applicable laws, and regulations for extended retention periods
- Store documents long term at lower cost for infrequent use case requirements
- Dedicate Amazon DocumentDB for operational data while maintaining JSON collections in Amazon S3 for analytical purposes
- Address capacity needs beyond the current maximum 64 TiB database and 32 TiB collection size limits in Amazon DocumentDB
In general, older document collections are less frequently accessed and don’t require the higher performance characteristics of Amazon DocumentDB. This makes older documents good candidates for archiving to lower-cost Amazon S3. This post describes a solution using tweet data that stores document updates in Amazon DocumentDB while simultaneously streaming the document changes to Amazon S3. To maintain or reduce collection sizes, a best practice is to use a rolling collections methodology to drop older collections. For more information, refer to Optimize data archival costs in Amazon DocumentDB using rolling collections.
Solution overview
To archive Amazon DocumentDB data to Amazon S3, we use the Amazon DocumentDB change streams feature. Change streams provide a time-ordered sequence of change events as they occur within your cluster’s collections. Applications can use change streams to subscribe to data changes on individual collections or databases.
In this solution, we use AWS Secrets Manager to provide secure access to Amazon DocumentDB credentials, cluster endpoint, and port number. We also use an Amazon EventBridge rule running on a schedule to trigger an AWS Lambda function to write the document changes to Amazon S3. EventBridge is a serverless event bus that makes it easy to build event-driven applications at scale using events generated from your applications. Lambda is a serverless, event-driven compute service that lets you run code for virtually any type of application or backend service without provisioning or managing servers. The following diagram illustrates the architecture for this solution.
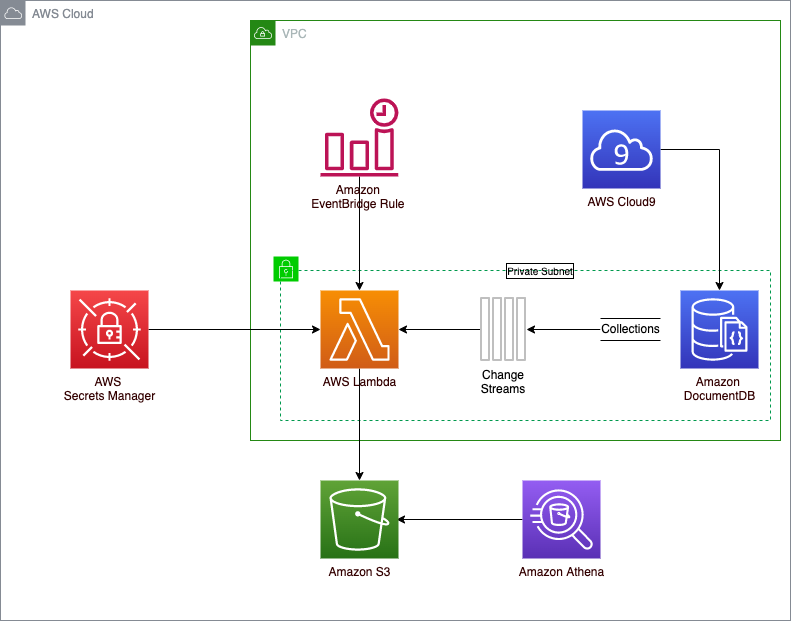
Write Amazon DocumentDB change streams to Amazon S3
We use Lambda to poll the change stream events and write the documents to Amazon S3. The Lambda function is available on GitHub. Additionally, an Amazon DocumentDB workshop is available for you to try the solution.
Lambda functions are stateless and have limited runtime durations. Because of those characteristics, the solution requires EventBridge to schedule a Lambda function to run at a defined frequency (1 minute in this example) to ensure continuous polling of the Amazon DocumentDB change stream events. The Lambda function connects to Amazon DocumentDB and watches for changes for a predefined time period of 15 seconds. At the end of each poll cycle, the function writes a last polled resume token to a different collection for subsequent retrieval. A resume token is a change streams feature that uses a token equal to the _id field of the last retrieved change event document. In Amazon DocumentDB, each document requires a unique _id field that acts as a primary key. The resume token is used as the change stream checkpoint mechanism for the next Lambda function invocation to resume polling activity of new documents from where the previous function left off. Change streams events are ordered as they occur on the cluster and are stored for 3 hours by default after the event has been recorded.
For collections where you intend to archive existing data, before enabling change streams, you may use a utility like mongoexport to copy your collections to Amazon S3 in JSON format. The mongoexport tool creates a point in time snapshot of the data. You can then use the resumeAfter change stream option with a resume token recorded when the export completed. The high-level steps are as follows:
- Export the collections to be archived to Amazon S3 using mongoexport.
- Record the timestamp and last updated
_id. - Insert a canary document that can be used as starting point from which change streams watch for document updates (we provide a code block example below).
- Enable change streams on the collection using either the
startAtOperationTimeorresumeAftercommand.
If using Amazon DocumentDB 4.0+ versions, you can use the change stream’s startAtOperationTime command and remove the need to insert a canary record (step 3). When using startAtOperationTime, the change stream cursor only returns changes that occurred at or after the specified timestamp. For sample code for using the startAtOperationTime command, refer to Resuming a Change Stream with startAtOperationTime.
You can configure the change stream retention period to store changed documents for periods up to 7 days using the change_stream_log_retention_duration parameter. When performing the export operation, the change stream retention period must be long enough to ensure storage of all document changes from the time the export began in step 1, until change streams are enabled after completion of the export in step 4.
Lambda code walkthrough
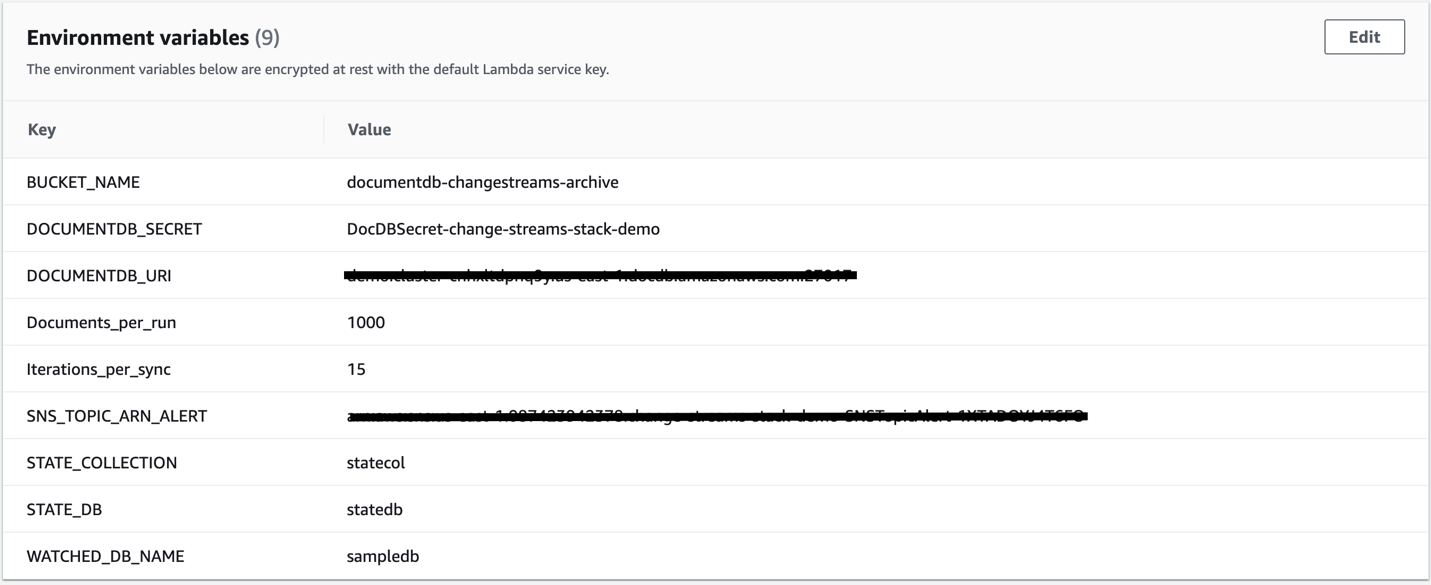
The Lambda Python code example described in this section is available on GitHub. The Lambda function uses environment variables to configure the database to watch for change events, the S3 bucket to archive data, the Amazon DocumentDB cluster endpoint, and a few other configurable variables, as shown in the following screenshot.
The Lambda handler function in the code establishes a connection to the Amazon DocumentDB cluster using a PRIMARY read preference and connects to the database configured in the environment variable WATCHED_DB_NAME. Change streams are only supported with connections to the primary instance of an Amazon DocumentDB cluster (at the time of this writing). The Lambda handler function then retrieves the last processed _id to use as a resume token for the next Lambda invocation and stores it in a separate database and collection identified by the STATE_DB and STATE_COLLECTION environment variables.
Next, let’s discuss some key Python code blocks.
The following code is the get_last_processed_id function that stores the resume token corresponding to the last successfully processed change event:
The Lambda handler function watches the change stream for any change events and calls the get_last_processed_id function:
When the Lambda function is triggered for the first time after enabling the change streams, the last_processed_id is set to None. To activate the change streams and start capturing the change events, a canary record is inserted and deleted to act as a dummy record to start capturing the change events:
The changes are streamed in a loop for the current invocation for 1 minute or until the number of documents to process for each invocation is met:
The change_event variable contains an operation type to indicate if an event corresponds to an insert, update, or delete event. All events contain the _id. Insert and update events include the document body as well. The content of the change_event variable is used to create a payload containing the document ID, body, and last updated timestamp. This payload is then written to Amazon S3, into a bucket indicated by the BUCKET_NAME environment variable.
For the delete operation, the document ID and last updated timestamp are stored in Amazon S3:
Finally, if you want to identify documents that have been deleted and view document revisions, you can use the document ID to query Amazon S3 using Athena. Visit the workshop Archiving data with Amazon DocumentDB change streams for more information.
Conclusion
In this post, we provided use cases for archiving Amazon DocumentDB documents to Amazon S3, along with a link to an Amazon DocumentDB workshop for you to try the solution. We also provided a link to the Lambda function that is central to the solution, and walked through some of the critical code sections for better understanding.
Do you have follow-up questions or feedback? Leave a comment. To get started with Amazon DocumentDB, refer to the Developer Guide.
About the authors
 Mark Mulligan is a Senior Database Specialist Solutions Architect at AWS. He enjoys helping customers adopt Amazon’s purpose-built databases, both NoSQL and Relational to address business requirements and maximize return on investment. He started his career as a customer in roles including mainframe Systems Programmer and UNIX/Linux Systems Administrator providing him with customer’s perspective for requirements in the areas of cost, performance, operational excellence, security, reliability, and sustainability.
Mark Mulligan is a Senior Database Specialist Solutions Architect at AWS. He enjoys helping customers adopt Amazon’s purpose-built databases, both NoSQL and Relational to address business requirements and maximize return on investment. He started his career as a customer in roles including mainframe Systems Programmer and UNIX/Linux Systems Administrator providing him with customer’s perspective for requirements in the areas of cost, performance, operational excellence, security, reliability, and sustainability.
 Karthik Vijayraghavan is a Senior DocumentDB Specialist Solutions Architect at AWS. He has been helping customers modernize their applications using NoSQL databases. He enjoys solving customer problems and is passionate about providing cost effective solutions that performs at scale. Karthik started his career as a developer building web and REST services with strong focus on integration with relational databases and hence can relate to customers that are in the process of migration to NoSQL.
Karthik Vijayraghavan is a Senior DocumentDB Specialist Solutions Architect at AWS. He has been helping customers modernize their applications using NoSQL databases. He enjoys solving customer problems and is passionate about providing cost effective solutions that performs at scale. Karthik started his career as a developer building web and REST services with strong focus on integration with relational databases and hence can relate to customers that are in the process of migration to NoSQL.