AWS Database Blog
Best practices for migrating an Oracle database to Amazon RDS PostgreSQL or Amazon Aurora PostgreSQL: Source database considerations for the Oracle and AWS DMS CDC environment
An Oracle to PostgreSQL migration in AWS Cloud can be a complex multistage process with different technologies and skills involved, starting from the assessment stage to the cutover stage. To better understand details of the complexities involved, see the AWS Database Blog post Database Migration—What Do You Need to Know Before You Start?
This blog post is the second in a series. The previous post, Migration process and infrastructure considerations, talks about preparing the migration process and the infrastructure setup considerations for optimal performance. This second post discusses setting up the source Oracle database’s configuration and environment for both a one-time migration, and also for continuing replication with the change data capture (CDC) method. Configuring the Oracle DB components suitably to capture changes in the source database enables us to build a successful AWS Database Migration Service (AWS DMS) service environment. The third and final blog post in the series addresses the setup of a target PostgreSQL database environment, the endpoint in the database migration process using AWS DMS.
AWS DMS is a service for migrating an on-premises database, either in Amazon RDS or a database on Amazon EC2, to an Amazon RDS or Amazon Aurora database. AWS DMS can handle homogenous migrations, such as Oracle-to-Oracle, and also heterogeneous migrations, such as Oracle to MySQL or PostgreSQL in the AWS Cloud.
Setting up DMS is as simple as an administrator accessing AWS DMS from the AWS Management Console. The administrator then defines a database source from which data will be transferred to the database target for receiving the data.
Using AWS DMS, you can start replication tasks in minutes. AWS DMS monitors the data replication process, providing the administrator with performance data in real time. If the service detects a network or host failure during replication in a Multi-AZ instance setup, it automatically provisions a replacement host. During the database migration, AWS DMS keeps the source database operational. The source remains operational even if a transfer is interrupted, thereby minimizing application downtime.
Although DMS setup is relatively simple, before you begin we recommend that you understand the working of two important DMS processes, the full load and change data capture (CDC) migration methods.
AWS DMS process for Oracle database sources
AWS DMS is a pure data migration service—don’t mistake it for a two-way database replication service. AWS DMS transfers all objects and changes performed at the source. It doesn’t migrate any changes or modifications to an object like an index. It also doesn’t address conflict resolutions. However, it does migrate schema changes necessary to migrate the data such as column additions.
AWS DMS creates the target schema objects necessary to perform the migration. However, AWS DMS takes a minimalist approach and creates only those objects required to migrate the data efficiently. In other words, AWS DMS creates tables, primary keys, and in some cases unique indexes. However, it doesn’t create any objects that are not required to migrate the data from the source. For example, it doesn’t create secondary indexes, non–primary key constraints, or data defaults.
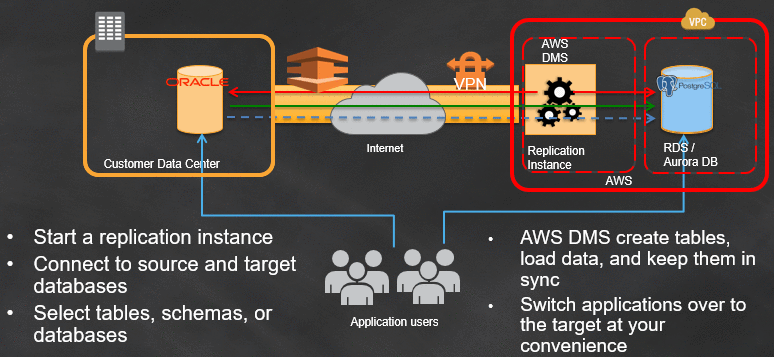
Any data migration is a crucial operation within an enterprise. Failure can result in a lot of pain, because migration can be time-consuming and costly. Before embarking on any AWS DMS migration project, make sure to understand the high-level perspective of the important DMS process steps for full load and change data capture (CDC), described following.
Full load only
For full load only, the following process applies:
- Migrate data definition language (DDL) using AWS Schema Conversion Tool (AWS SCT): Create the schema on the target database, similar to your source database. For more information about AWS SCT, see its documentation.
- Drop or disable all the foreign key constraints and triggers in the target. You can do this manually by generating the table DDL and either disabling the foreign key constraints or temporarily deleting them.
- Initiate the load using AWS DMS with this approach:
- Set migration type – Migrate existing data and replicate ongoing changes.
- Set target table preparation mode – Truncate (if you have the data on the target) or Do nothing (if target tables don’t have data).
- Include LOB columns in replication – Use Limited LOB mode (with default settings) for tables with LOB columns less than 32 KB in size. Use Limited LOB mode (with customized settings) for tables with LOB columns greater than 32 KB in size.
- Stop task after full load completes – Stop the task once full load is completed.
- Enable logging.
- Manually create secondary objects for the tables in the target database.
In step 3 preceding, DMS goes through three stages while migrating data:
- Fully migrating the table data in bulk load. This is the most efficient way to migrate the full data of a table with, for instance, 1 billion records.
- Keeping and caching on the T2, C4, or R4 DMS instance the changes that happen on the table until all data is migrated to the target, then applying cached changes. At times, the DMS instance type can become a performance bottleneck. Thus, we recommend that you choose your instance type with proper consideration of the migration scenario:
- T2 instances: Designed for light workloads with occasional bursts in performance. Mostly used for test migrations of small, intermittent workloads.
- C4 instances: Designed for compute-intensive workloads with best-in-class CPU performance. Mostly used for CPU-intensive, when performing heterogeneous migrations and replications (for example, Oracle to PostgreSQL).
- R4 instances: Designed for memory-intensive workloads. These instances include more memory per vCPU. Ongoing migrations or replications of high-throughput transaction systems using DMS can consume large amounts of CPU and memory.
- Migrating changes, at the CDC (ongoing replication) stage. If you include the secondary index in the full load stage of the migration, this creates an extra overhead to maintain and migrate the related objects.
To use a secondary index during the application of changes, we can set our task to stop after the full load stage completes, before starting the application of cached changes. We can then perform the task settings for the full load after adding the indexes.
Full load with CDC
- Steps 1–3 are the same as for full load only, preceding.
- Stop the task (for the automatic steps to do so, see following).
- Add all secondary objects and enable the foreign key constraints.
- Resume the task to capture changes.
In step 4 just preceding, you can set the following options for stopping the migration task after full load completes:
StopTaskCachedChangesApplied– Set this option to true to stop a task after a full load completes and cached changes are applied.StopTaskCachedChangesNotApplied– Set this option to true to stop a task before cached changes are applied.
After the task stops and before cached changes are applied, we can create all secondary objects that ensure data integrity and better CDC performance (minimizing latency).
The foreign keys are enabled only after the cached changes have been applied and before starting the ongoing replication. Thus, in this case, we stop the task after the cached changes are applied. This step occurs only for migration tasks in transactional mode, not bulk loading mode. Don’t enable triggers in this case, because the changes are already captured at source and applied by the DMS. If you enable triggers, they perform duplicate insertions, which leads to inconsistency. However, at times users have used triggers to audit the data migration, which can dramatically affect performance.
When using the AWS DMS CDC process to replicate Oracle as a source in an ongoing manner, DMS offers two methods for reading the logs: Oracle LogMiner and Oracle Binary Reader. Working with Binary Reader is described in the AWS Database Blog post AWS DMS now supports Binary Reader for Amazon RDS for Oracle and Oracle Standby as a source.
By default, AWS DMS uses Oracle LogMiner for change data capture (CDC). Alternatively, you can use Binary Reader. Binary Reader bypasses LogMiner and reads the logs directly. Binary Reader provides greatly improved performance and reduces load on the Oracle server when compared to LogMiner. However, we recommend using Oracle LogMiner for migrating your Oracle database unless you have a very active Oracle database.
AWS DMS uses Binary Reader by creating a temporary directory in the file system where the archive logs are generated and stored. In most situations, this is the directory location indicated by USE_DB_RECOVERY_FILE_DEST. This directory is deleted after the migration task is stopped.
Before using AWS DMS for your Oracle source database, you perform the following basic tasks on the source Oracle database:
- Set up Oracle DMS user privileges – You must provide an Oracle user account for AWS DMS user. The user account must have read/write privileges on the Oracle database. Be aware of these considerations:
- When granting privileges, use the actual name of objects (for example,
V_$OBJECTincluding the underscore), not the synonym for the object (for example,V$OBJECTwithout the underscore). For information about access privileges to grant to the DMS user, see Using an Oracle Database as a Source for AWS DMS in the DMS documentation. - Also make sure that the IAM user that you log in to use the DMS service has all the permissions necessary to view the logs. For more information on these permissions, see IAM Permissions Needed to Use AWS DMS in the DMS documentation.
- When granting privileges, use the actual name of objects (for example,
- Enable archive logs – To use Oracle with AWS DMS, the source database must be in
ARCHIVELOGmode. - Enable supplemental logs – If you are planning to use a full load plus CDC task, set up supplemental logging to capture the changes for replication.
On-premises Oracle sources
When working with an on-premises Oracle source, be aware of the following.
Enable archive log mode
An Oracle database can run in one of two modes—NOARCHIVELOG or ARCHIVELOG. By default, the database is created in NOARCHIVELOG mode. In ARCHIVELOG mode, the database makes copies of all ONLINE REDO logs after they are filled up. These copies of archived redo logs are created by using the Oracle ARCH process. The ARCH process copies the archived redo log files to one or more archive log destination directories.
The commands following check to see if the database has been altered to run in ARCHIVELOG mode.
Enable supplemental logging
Redo log files are used for instance recovery and media recovery. The data needed for such operations is automatically recorded in the redo log files. However, a redo-based application might require that additional columns are logged in the redo log files. The process of logging additional columns is called supplemental logging.
By default, an Oracle database doesn’t provide any supplemental logging, and without supplemental logging you can’t use LogMiner. Therefore, you need to enable minimal supplemental logging before generating log files, which are then analyzed by LogMiner.
The following examples describe situations in which additional columns might be required when using LogMiner:
- An application that applies reconstructed SQL statements to a different database must identify the update statement by a set of columns that uniquely identify the row (for example, a primary key). Such an application can’t identify this by the
ROWIDshown in the reconstructed SQL returned by theV$LOGMNR_CONTENTSThis result is because theROWIDvalue in one database is different from the one in another database, and therefore meaningless. - An application might require that the before image of an entire row be logged, not just the modified columns, so that tracking of row changes is more efficient.
Supplemental log groups can be system-generated or user-defined. There are two types of supplemental log groups that determine when columns in the log group are logged:
- Unconditional supplemental log groups – The before images of specified columns are logged any time a row is updated, regardless of whether the update affected any of the specified columns. This type of group is sometimes referred to as an ALWAYS log group.
- Conditional supplemental log groups – The before images of all specified columns are logged only if at least one of the columns in the log group is updated.
In addition to the two types of supplemental logging, there are two levels of supplemental logging:
- Database-level supplemental logging – Using this type of logging ensures that the LogMiner has the minimal information to support various table structures such as clustered and index-organized tables. The command involved is
ALTER DATABASE ADD SUPPLEMENTAL LOG DATA. - Table-level supplemental logging for each table to be migrated – For all tables in the database that have primary keys, use this command:
This command creates a system-generated unconditional supplemental log group that is based on the table’s primary key.
Supplemental logging causes the database to place all columns of a row’s primary key in the redo log file whenever a row containing a primary key is updated. This placement occurs even if no value in the primary key has changed. In some cases, a table might not have a primary key but has one or more non-null unique index key constraints or index keys. In these cases, one of the unique index keys is chosen for logging as a means of uniquely identifying the row being updated.
If the table has neither a primary key nor a non-null unique index key, then all columns except LONG and LOB are supplemental logged. Doing this is equivalent to specifying ALL for supplemental logging for that row.
Therefore, we recommend that when you use database-level primary key supplemental logging, all or most tables be defined to have primary or unique index keys. You can enable this by executing the following command for each individual table:
Name unique columns and also columns that are used to filter redo records:
ALTER DATABASE ADD SUPPLEMENTAL LOG DATA (…) COLUMNS;ALTER TABLE table_name ADD SUPPLEMENTAL LOG DATA (ALL) COLUMNS;
Assign ALL or individually by table the primary key and unique key columns for supplemental logging:
ALTER DATABASE ADD SUPPLEMENTAL LOG DATA (ALL) COLUMNS;ALTER DATABASE ADD SUPPLEMENTAL LOG DATA (FOREIGN KEY) COLUMNS;ALTER DATABASE ADD SUPPLEMENTAL LOG DATA (PRIMARY KEY) COLUMNS;ALTER DATABASE ADD SUPPLEMENTAL LOG DATA (UNIQUE) COLUMNS;
Dropping database supplemental logging of key columns doesn’t affect any existing table-level supplemental log groups.
To check if you have enabled the database-level primary key, unique index, logging, and so on, run the following commands:
Check if the on-premises or EC2 Oracle database has enabled supplemental logging:
Create SQL statements to add a primary key for all tables:
We also recommend that you keep sufficient archive log files for at least a 24-hour timeframe:
In addition, check the RMAN process for the 24-hour backlogs:
Amazon RDS for Oracle sources
When working with Amazon RDS for Oracle as a source, make sure that you enable automatic backup for your Amazon RDS for Oracle instance first:
To drop this, use the following commands:
In some cases, after a migration task has started you might create a new table for which there is no primary key. In such a case, we recommend that you add ‘addSupplementalLogging=Y‘ in the source Oracle endpoint connection attribute. Doing so means that DMS captures the all changed columns in the table. This addition requires ‘alter any table‘ privilege and an exclusive lock to alter the table.
If you enable ‘addSupplementalLogging=Y‘ without ‘alter any table‘ privilege, DMS returns an error. However, if you create a table with a primary key and do this, DMS doesn’t return an error, because DMS doesn’t add supplemental logging for all columns for that table.
Because enabling ‘addSupplementalLogging=Y‘ requires an exclusive lock on the source tables, you might find it best to enable this manually.
RDS Oracle with CDC mode
To perform a migration in CDC mode for an RDS Oracle source, you need the following prerequisites:
- Use Oracle Binary Reader release 2.4.2R1 or later.
- Use Oracle version 11.2.0.4.v11 and later, or 12.1.0.2.v7 and later. When you do so, use the ‘ORCL’ default name to create your RDS Oracle instance. Otherwise, the procedures following don’t run successfully.
- To create symbolic-linked server directories, which are required, run the procedure following. For more information on this procedure, see Accessing Transaction Logs in the DMS documentation.
- If you plan to use the Binary Reader method, use following the event condition action (ECA) for RDS Oracle. Enter all options following on one line.
- Create supplemental logging at the database level and for the primary key:
- Keep archive logs for DMS tasks, for least the last 24 hours:
Execute command below for RDS Oracle to switch log manually
Data migration from Oracle ASM
The Oracle Automatic Storage Management (ASM) database framework provides a volume manager and a file system for Oracle database files. It supports single-instance Oracle Database and Oracle Real Application Clusters (Oracle RAC) configurations. ASM has tools to manage file systems and volumes directly inside a database. You can find details on a migration from ASM in the AWS Database Blog post How to Migrate from Oracle ASM to AWS using AWS DMS.
In the Oracle ASM architecture, the DMS setup must create a temporary directory to configure Binary Reader for change processing. Because the disk groups and the extent of the data are managed by a separate ASM instance, AWS DMS also needs to connect to this ASM instance. Additionally, this ASM instance should also accept traffic from the DMS replication instance. AWS DMS creates a related directory for migration.
To set up Oracle ASM as a source for AWS DMS (details in the DMS documentation), you use the following extra connection attributes. These configure Binary Reader for change processing with ASM.
When using the preceding attributes with an Oracle ASM source, if the test connection is successful, but not the migration. In this case, you might see the following errors in the migration task logs:
The extra connection attributes field for an Oracle ASM source should resemble the following:
The server_address value is the same as the one provided for the server name when creating the related endpoint.
Additionally, when working with an ASM instance, the password field requires that you provide the password of the Oracle instance you are trying to migrate. You also need to provide the password to connect to your ASM instance. You can separate the two passwords in the field with a comma:
CDC processing speed
In an ASM environment, accessing the redo logs is often slow. This slow speed occurs because the API operation responsible reads only up to 32 kilobytes of blocks in a single call. Additionally, when you set up ASM with AWS DMS using LogMiner for ongoing replication, performance degradation issues can create high latency. Sometimes the migration can’t recover properly if there are connectivity issues or the source instance goes down.
To increase speed and make migration more robust for an Oracle ASM source with AWS DMS, we recommend using Binary Reader with the DMS copy functionality. In this method, DMS copies the archived logs from ASM to a local directory on the Oracle server. DMS can then read the copied logs using Binary Reader.
The only requirement here is that the local directory should be located on the underlying Linux file system and not on the ASM instance.
These are some other quick pointers to improve CDC speed:
- You can’t use reserved words such as ‘
tag‘ in a table’s DDL or primary key. - You must have a primary key on the PostgreSQL target to make an update or delete, to run in bulk mode and for better performance.
- It’s best to first precreate the table with a sort key and primary key, then use truncate or do nothing as your table preparation mode. Your sort key can be compound or interleaved, depending on the pattern of the query.
- Your distribution key should be even or key and can’t be
ALL. - To improve performance, set ‘
BatchApplyPreserveTransaction‘ to false.
DMS with Oracle RAC, DMS copy, and ASM configuration
Your Oracle database must be able to write and delete from a temporary folder. If the Oracle source database is an Oracle RAC cluster, the temporary folder must be located on a file share that is accessible to all of the nodes in Oracle RAC. If you chose the Binary Reader method for accessing the temporary folder, the folder doesn’t need to be a shared network folder.
If multiple tasks use the same temporary folder, conflicts can arise (such as one task needing to access a redo log that another task has already deleted). To prevent such conflicts, only one DMS task should access the same temporary folder at any given time. However, you can create a different subfolder under the same root folder for each task. For example, instead of specifying /mnt/dms as the temporary folder for both tasks, you can specify /temp/dms/task1 for one task and /temp/dms/task2 for the other.
When working with the temporary folder, make sure that the archived redo log files processed by DMS are deleted. Deleting these ensures that the redo logs don’t accumulate in the temporary folder. Make sure that there’s enough space in the file system where the temporary folder is created. If multiple tasks are running, multiply the disk space required by the number of tasks, because each task has its own temporary folder.
Take these steps to set up Binary Reader access with DMS copy functionality:
- Choose a temporary folder on the Oracle server. If your source is an Oracle RAC, all RAC nodes should be able to access the folder as described preceding. The folder should have permissions for the Oracle user and Oracle group (for example, DBA) to read, write, and delete.
- Give the following permissions to the user that DMS uses to connect to Oracle. The last permission listed following enables the archived redo logs to be copied to the temporary folder using the
COPY_FILEmethod. - If you want AWS DMS to create and manage the Oracle directories, grant the following privilege. As mentioned earlier, AWS DMS needs to use directory objects for copying redo logs to and deleting them from the temporary folder. If you grant the following privilege, AWS DMS creates the Oracle directories with the
DMSREP_prefix. If you don’t grant this privilege, you need to create the corresponding directories manually. The directories should point to the archived redo logs and temporary folder paths. If you create the directories manually, you don’t need to append theDMSREP_prefix to the directory names.
- When you create the Oracle source endpoint, if the DMS user specified isn’t the user that created the Oracle directories, provide the following additional permissions (an example follows):
READon the Oracle directory object specified as the source directory (that is, the ASM archived redo logs path and the temporary folder if you use the BFILE method to read from the temporary folder).WRITEon the directory object specified as the destination directory in the copy process (that is, the temporary folder).
- To prevent old redo logs from accumulating in the temporary folder, configure AWS DMS to delete the redo log files from the temporary folder after they have been processed. The delete operation is performed using Oracle file groups and the Oracle
DBMS_FILE_GROUPpackage. - Make sure that AWS DMS has the required ASM access permissions to read the online redo logs from ASM (that is,
SYSASMorSYSADMprivilege). This permission is required because reading the online redo logs from ASM is performed using a function from the Oracle DBMS_DISKGROUP package. Doing this requires the SYSASM or SYSADM privilege. You can also validate ASM account access by opening a command prompt window and issuing the following statements:Starting with Oracle 11g release 2 (11.2.0.2), the AWS DMS user must be granted the
SYSASMprivilege to access the ASM account. For older supported versions, granting theSYSDBAprivilege should be sufficient. - Choose an archived redo logs destination identifier. This number is the destination ID of the archived redo logs that replication should read. The value should be the same as the DEST_ID number in v$archived_log. Then add the following attribute on your source endpoint:
where
nnis the destination ID for the connection string in DMS. - Set up the Oracle ASM source endpoint so that the extra connection attribute field looks like this:
Here is an example:
There are a few additional considerations. First, if you create directories manually and the Oracle user specified in the Oracle source endpoint isn’t the user that created the Oracle directories, grant the READ ON DIRECTORY privilege.
If the Oracle user specified in the Oracle source endpoint isn’t the user that created the Oracle directories, the following additional permissions are also required:
READon the Oracle directory object specified as the source directory (that is, the ASM archived redo logs path and the temporary folder, if the BFILE method is used to read from the temporary folder)WRITEon the directory object specified as the destination directory in the copy process (that is, the temporary folder)
Run the following command:
In addition the following:
Another example follows:
For Oracle RAC with ASM, make sure to correctly configure IP addresses for source endpoints for your ASM server. Using a public IP address for the server and an internal IP address for asm_server results in an error message, because the migration task fails to connect.
For Oracle RAC with ASM, use the following configuration:
- Use the connection attribute following:
useLogminerReader=N;asm_user=<asm_username e.g. sysadm>;asm_server=<first_RAC_server_ip_address>/<ASM service name e.g. +ASM or +APX> - Use the comma-separated password field following:
- If you use RDS Oracle Binary Reader mode with a non-ASM setup, use these extra connection attributes:
Oracle Log Miner can work with Oracle RAC to extract DML and DDL changes from both thread 1 and 2. No extra connection attributes (ECAs) are required when using LogMiner for Oracle RAC with or without ASM. In version 2.3, DMS started supporting this functionality (‘additionalArchivedLogDestid=2‘) for both LogMiner and Binary Reader.
Summary
This blog post outlines the migration steps that are required to configure and set up your source Oracle database for migration to a PostgreSQL environment. We use AWS Database Migration Service (AWS DMS) and AWS Schema Conversion Tool (AWS SCT) throughout this portion of the migration buildout process.
For the steps involved in the final stage of this migration, see the final blog post of the series, Target database considerations for the PostgreSQL environment.
Acknowledgement
This blog could not have been possible without the thorough and persistent review and feedback of – Silvia Doomra, Melanie Henry, Wendy Neu, Eran Schitzer, Mitchell Gurspan, Ilia Gilderman, Kevin Jernigan, Jim Mlodgenski, Chris Brownlee, Ed Murray and Michael Russo.
About the Author
 Mahesh Pakala has worked with Amazon since April 2014. Prior to joining Amazon, he worked with companies such as Ingres, Oracle Corporation & Dell Inc.; advice strategic marquee customers design their highly available scalable applications, heterogeneous cloud application migrations and assist with system performance.
Mahesh Pakala has worked with Amazon since April 2014. Prior to joining Amazon, he worked with companies such as Ingres, Oracle Corporation & Dell Inc.; advice strategic marquee customers design their highly available scalable applications, heterogeneous cloud application migrations and assist with system performance.