AWS Database Blog
Categorizing and Prioritizing a Large-Scale Move to an Open Source Database
July 2023: This post was reviewed for accuracy.
The AWS Schema Conversion Tool (AWS SCT) and AWS Database Migration Service (AWS DMS) are tools that help facilitate and simplify migrating your commercial database to a variety of engines on Amazon RDS. AWS SCT specifically helps simplify proprietary database migrations to open source. It does this by automatically converting your source database schema and a majority of the custom code to a format that is compatible with your new target database. The custom code that the tool converts includes views, stored procedures, and functions. Any code that the tool cannot convert automatically is clearly marked so that you can convert it yourself. AWS DMS helps you migrate your data easily and securely with minimal downtime.
Changing database engines can be daunting. However, the value proposition of a highly scalable, cost-effective, fully managed service such as Amazon Aurora can make the challenge worth it. Assessing and planning for a single database migration to open source is straightforward with AWS SCT and AWS DMS. You can generate an AWS SCT assessment report and get answers about how easy it is to use these tools to migrate your databases.
The following are just a few of the articles and videos about making the transition to open source for your databases:
- How to Migrate Your Oracle Database to PostgreSQL
- How to Migrate Your Oracle Database to Amazon Aurora
- Migrate from SQL Server or Oracle into Amazon Aurora using AWS DMS
What if you have hundreds or even thousands of databases?
Building an assessment report and planning a move for one, two, or even ten databases to open source is a straightforward process. You probably have enough familiarity with applications that attach to those databases that you can identify which ones to move first. What do you do if you have hundreds or thousands of database instances deployed in and around your organization that you don’t have intimate application knowledge about?
If you’re in a centralized IT department, you might know how many databases you manage, have backups scheduled for them, and be tracking them in your inventory. But you might not have enough detail to plan a large-scale move or prioritize them for analysis. This post talks about how to assess your database portfolio and break it down into a manageable pipeline of migrations to make the process go smoothly.
A collaboration of smaller projects
A detailed project plan for a single heterogeneous database migration consists of 12 steps, as detailed in the following table.
| Phase | Description | Phase | Description |
| 1 | Assessment | 7 | Functional testing of the entire system |
| 2 | Database schema conversion | 8 | Performance tuning |
| 3 | Application conversion/remediation | 9 | Integration and deployment |
| 4 | Scripts conversion | 10 | Training and knowledge |
| 5 | Integration with third-party applications | 11 | Documentation and version control |
| 6 | Data migration | 12 | Post-production support |
At a high level, and for the purposes of this blog, the process for planning a migration project can be grouped into five areas of work: Analysis and Planning, Schema Migration, Data Migration, Application Migration, and Cutover. How long your migration takes generally depends on how long you spend iterating over the migration and testing phases. If you are planning several migrations in tandem, you should understand when you start which ones are likely to take the most time and which ones can be tackled first or in rapid succession.
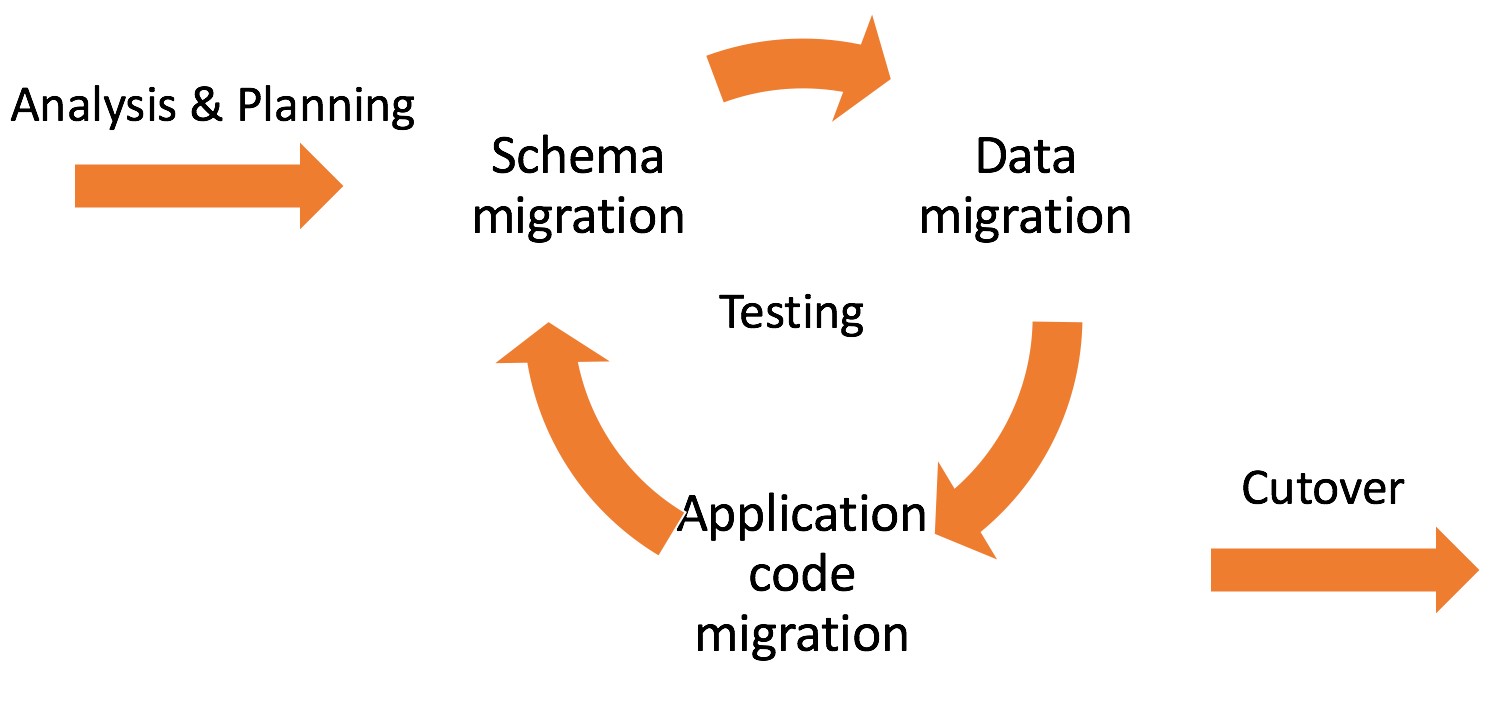
Prioritizing which databases to analyze first when moving to open source often hinges on how much proprietary database code is being used in the databases. The volume of proprietary code in use affects the amount of time it takes to translate it and test it during the migration phases of your project. You can categorize your databases by workload using dictionary queries after you establish the categories and criteria.
Workload qualification framework
Workloads are typically divided into 5 categories for further analysis. For this blog we will focus on categories 1 to 3.
Category 1: (ODBC/JDBC)
These applications use ODBC (Open Database Connectivity) / JDBC (Java Database Connectivity). They use very little proprietary database code in procedures, functions, triggers, or views. The application logic resides in code outside the database (e.g., Java, Python, Ruby). These are easy to port to another database.
Category 2: (Light embedded proprietary database code)
These workloads use a combination of application-level code (e.g., Java, Python, Ruby, bash) and proprietary database code to perform functionality that might be cumbersome to do in Java or Python. As a rule of thumb, less than 200 procedures/functions are being classified in this category. Your tolerance for the use of advanced features can vary. Use of advanced features can slow the automated translation of the code into the target engine. Schema design is usually fairly simple in these workloads. They use basic data structures like tables and views.
Category 3: (Heavy embedded proprietary database code)
These workloads are driven completely by proprietary database code, often using advanced features. Many of these workloads have 1,000 or more proprietary features. They also use advanced schema features such as functional columns, materialized views, linked servers, etc. The challenge with these workloads is that they consume more work hours when you translate them to other frameworks. Tuning options performed on the source code have to be translated and tested with the target engine.
Category 4: (Vendor Specific workloads)
These workloads use frameworks which can work only with limited commercial engine support. Moving these workloads to open source would mean a complete redesign of the application from the ground up or require advanced functionality that may not be currently supported. Features are very hard to migrate and consume very heavy man hours.
Category 5: (Legacy workloads)
These workloads use the proprietary programming interfaces to run their programs. Examples may include Oracle OCI applications. These are often legacy workloads and customers may not not have the source code for these programs. These can seldom be migrated.
Prioritizing your workloads
If you keep your database inventory in a central repository, you can automate your portfolio assessment using tools you have on hand, like SQL and scripting languages.
Oracle
If you have a large footprint of Oracle databases, you can use a PL/SQL block to loop over the schemas in your databases and extract information provided with a user that has SELECT ANY DICTIONARY granted. Use SQL*Plus against your system, exclude any unwanted system schemas, and append a comma-separated set of values to a local file migration_candidates.csv. To apply it to multiple databases, you could use a bash script or program to read from your inventory system or a file and execute the script repeatedly, writing to the same file each time. You can download a sample script for Oracle from this repository.
SQL Server
If you have a large footprint of SQL Server databases, you can use a SQL block to read from your databases and extract information provided with a user that has privileges to select from MSDB and the sys schema. You can run the script using sqlcmd against your SQL Server database and retrieve a comma-separated result, which you can then write to a local file on your file system (e.g., migration_candidates.csv). To apply it to multiple databases, you could use a PowerShell script or program to read from your inventory system or a file and execute the script repeatedly, appending to the same file each time. You can download a sample script for SQL Server from this repository.
Reviewing and categorizing script output
When you have the resulting data from all your databases, you can load the results into Microsoft Excel or another tool and look for patterns in your data. In the following example, conditional data bar formatting helps show the scale of some of the values you should review when categorizing your workloads. You can download a sample workload worksheet from this repository.
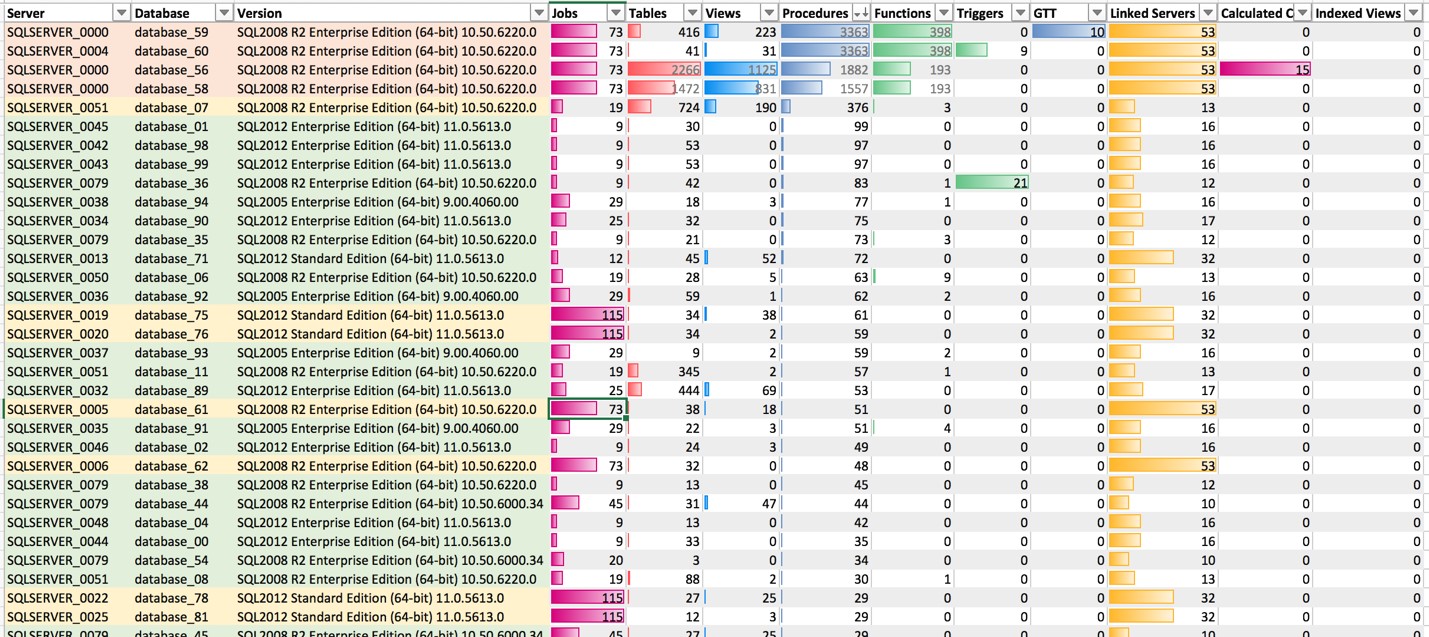
Category 1
You can see several workloads highlighted in green that would qualify as category 1 and should be assigned to a team for analysis and migration. These workloads have very few code objects that require translation, use few or no proprietary features (e.g., linked servers, jobs, or indexed views), and seem to have simple schemas (e.g., fewer tables and views).
Category 2
In the preceding example workload picture, you can see that there are a few workloads highlighted in yellow that would qualify as category 2. There are either quite a few procedures in these databases or they use a number of proprietary features that will extend the migration phases with additional testing at least.
Category 3
Rows 1–4 in the example workload picture show workloads highlighted in orange that would qualify as Category 3. These databases have more than 1,000 procedures and functions and also appear to have complex structures and several advanced features, like jobs and linked servers.
Staggered assignments by team
Now that you have an overview of your migration pipeline, you can start planning how your teams will approach the work. Team A in the following example would focus on Category 1 migrations. They would complete several migrations in rapid succession, moving through the pipeline one after the other. Team B from the example would take Category 2 migrations, where they might have to spend additional time in the migration phases. Team C would take on one of the more complex Category 3 migrations in the same time frame.
Each migration still goes through all the migration phases, from Analysis and Planning to Schema, Data, and Application Migration to Cutover. But they move at slightly different paces based on the amount of work that’s required.

By targeting the Category 1 migrations first, you quickly get to roll the lessons that you learn into subsequent projects. Staggering the start of the larger project gives your teams room to gain momentum before tackling an extended project. Tracking all projects and maintaining a pipeline of work keeps your teams engaged and allows you to report status relative to overall completion. The overall results are typically of greatest interest to your project stakeholders. You can download a sample planning sheet from this repository.
Conclusion
Viewing an overall migration to an open source engine as one effort can be overwhelming. By breaking down the work into manageable pieces with an initial high-level assessment, targeting the faster conversions first, and reporting out overall status, you can maintain a builder pipeline of conversions and keep your teams focused on delivering on time, earlier.
About the Author
 Wendy Neu has worked as a Data Architect with Amazon since January 2015. Prior to joining Amazon, she worked as a consultant in Cincinnati, OH helping customers integrate and manage their data from different unrelated data sources.
Wendy Neu has worked as a Data Architect with Amazon since January 2015. Prior to joining Amazon, she worked as a consultant in Cincinnati, OH helping customers integrate and manage their data from different unrelated data sources.