AWS Database Blog
Category: Amazon Neptune Analytics

Improving generative AI accuracy with vector and graph search hybrid queries
In this post, we discuss the differences between vector search and graph search, how to combine the two for hybrid querying, and use cases that benefit from hybrid querying.
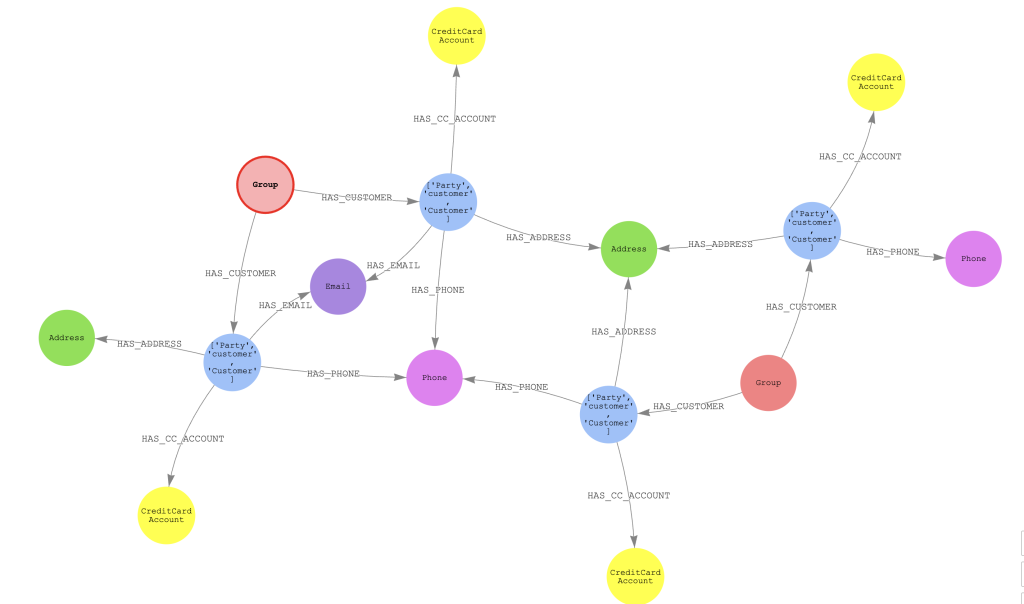
Build fraud detection systems using AWS Entity Resolution and Amazon Neptune Analytics
In this post, we show how you can use graph algorithms to analyze the results of AWS Entity Resolution and related transactions for the CNP use case. We use several AWS services, including Neptune Analytics, AWS Entity Resolution, Amazon SageMaker notebooks, and Amazon S3.
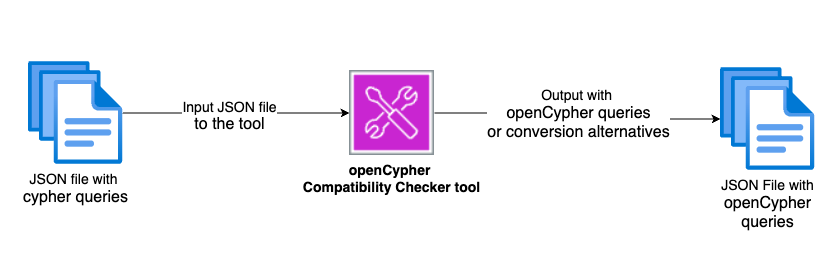
Validate Neo4j Cypher queries for Amazon Neptune migration
In this post, we show you how to validate Neo4j Cypher queries before migrating to Neptune using the openCypher Compatibility Checker tool. You can use this tool to identify compatibility issues early in your migration process, reducing migration time and effort.
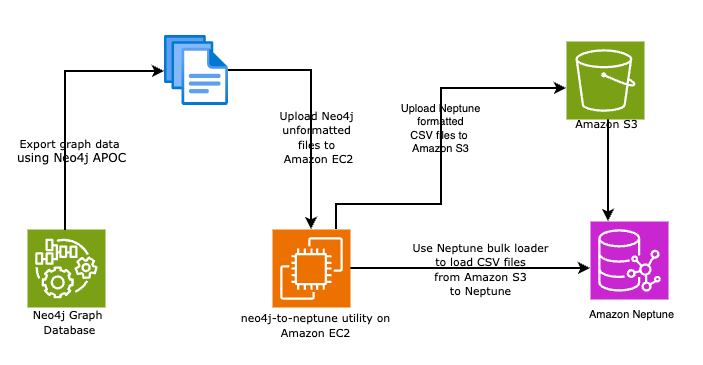
Automate your Neo4j to Amazon Neptune migration using the neo4j-to-neptune utility
In this post, we walk you through two methods to automate your Neo4j database to Neptune using the neo4j-to-neptune utility. This tool offers a fully automated end-to-end process in addition to a step-by-step manual process.

Build persistent memory for agentic AI applications with Mem0 Open Source, Amazon ElastiCache for Valkey, and Amazon Neptune Analytics
Today, we’re announcing a new integration between Mem0 Open Source, Amazon ElastiCache for Valkey, and Amazon Neptune Analytics to provide persistent memory capabilities to agentic AI applications. This integration solves a critical challenge when building agentic AI applications: without persistent memory, agents forget everything between conversations, making it impossible to deliver personalized experiences or complete multi-step tasks effectively. In this post, we show how you can use this new Mem0 integration.

Beyond Correlation: Finding Root-Causes using a network digital twin graph and agentic AI
When your network fails, finding the root cause usually takes hours of investigations, going through correlated alarms that often lead to symptoms rather than the actual problem. Root-cause analysis (RCA) systems are often built on hardcoded rules, static thresholds, and pre-defined patterns that work great until they don’t. Whether you’re troubleshooting network-level outages or service-level degradations, those rigid rule sets can’t adapt to cascading failures and complex interdependencies. In this post, we show you our AWS solution architecture that features a network digital twin using graphs and Agentic AI. We also share four runbook design patterns for Agentic AI-powered graph-based RCA on AWS. Finally, we show how DOCOMO provides real-world validation from their commercial networks of our first runbook design pattern, showing drastic MTTD improvement with 15s for failure isolation in transport and Radio Access Networks.

Use Graph Machine Learning to detect fraud with Amazon Neptune Analytics and GraphStorm
Every year, businesses and consumers lose billions of dollars to fraud, with consumers reporting $12.5 billion lost to fraud in 2024, a 25% increase year over year. People who commit fraud often work together in organized fraud networks, running many different schemes that companies struggle to detect and stop. In this post, we discuss how to use Amazon Neptune Analytics, a memory-optimized graph database engine for analytics, and GraphStorm, a scalable open source graph machine learning (ML) library, to build a fraud analysis pipeline with AWS services.

Introducing the GraphRAG Toolkit
Amazon Neptune recently released the GraphRAG Toolkit, an open source Python library that makes it straightforward to build graph-enhanced Retrieval Augmented Generation (RAG) workflows. In this post, we describe how you can get started with the toolkit. We begin by looking at the benefits of adding a graph to your RAG application. Then we show you how to set up a quick start environment and install the toolkit. Lastly, we discuss some of the design considerations that led to the toolkit’s graph model and its approach to content retrieval.

Use Amazon Neptune Analytics to analyze relationships in your data faster, Part 2: Enhancing fraud detection with Parquet and CSV import and export
In this two-part series, we show how you can import and export using Parquet and CSV to quickly gather insights from your existing graph data. In Part 1, we introduced the import and export functionalities, and walked you through how to quickly get started with them. In this post, we show how you can use the new data mobility improvements in Neptune Analytics to enhance fraud detection.

Use Amazon Neptune Analytics to analyze relationships in your data faster, Part 1: Introducing Parquet and CSV import and export
In this two-part series, we show how you can import and export using Parquet and CSV to quickly gather insights from your existing graph data. Part 1 introduces the import and export functionalities, and walks you through how to quickly get started with them. In Part 2, we show how you can use the new data mobility improvements in Neptune Analytics to enhance fraud detection.