AWS Database Blog
Tag: RDS Oracle

Amazon RDS for Oracle Transportable Tablespaces using RMAN
In this post, we show you how you can use the RMAN XTTS functionality to migrate from an Oracle database hosted on Amazon Elastic Compute CLoud (Amazon EC2) to Amazon RDS for Oracle. Combined with Amazon Elastic File System (Amazon EFS) integration, XTTS can help reduce the complexity of your migration strategy, reduce the number and copies of data and backups required (as well as associated storage space consumption), and reduce the application downtime associated with completing the migration of your data.

Implementing cross-region disaster recovery using Oracle GoldenGate for Amazon RDS for Oracle
Many AWS users take advantage of the managed service offerings available in the AWS portfolio to do the heavy lifting in their day-to-day activities. Amazon RDS is one of these services and is ideal for your relational database deployments. With RDS, you can significantly reduce the administrative overhead of managing and maintaining a relational database. […]

Integrating Amazon RDS for Oracle with Amazon S3 using S3_integration
Amazon RDS for Oracle gives you the full benefits of a managed service solution. You can use the lift-and-shift approach to migrate your legacy Oracle database to Amazon RDS for Oracle and, as a result, reduce the need to refactor and change existing application components. Data warehouse (DW) extraction is an integral part of most […]

Australia Finance Group’s Journey to Cloud Databases: Migrating from Oracle Exadata to Amazon RDS
Australia Finance Group (AFG) is one of the largest mortgage aggregators in Australia, according to the Mortgage and Finance Association of Australia. AFG migrated their Oracle Siebel Customer Relationship Management (CRM) application to a managed database with Amazon RDS for Oracle. In this blog post, we describe their approach to migrating the database from Oracle […]

Testing Amazon RDS for Oracle: Plotting Latency and IOPS for OLTP I/O Pattern
Kevin Closson is a principal specialist solutions architect at Amazon Web Services. At Amazon Web Services (AWS), we take the Amazon Leadership Principles to heart. One such principle is that leaders Earn Trust. Although this principle guides how leaders should act, I like to extend the idea into how we can help customers enjoy more […]
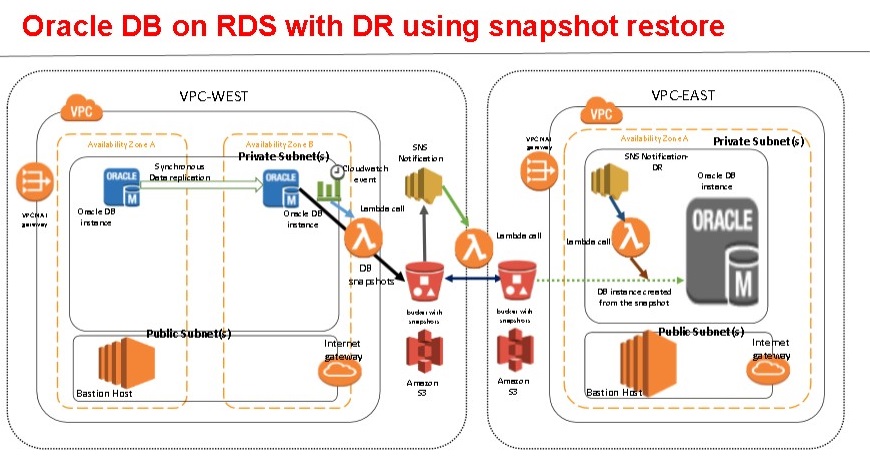
Cross-Region Automatic Disaster Recovery on Amazon RDS for Oracle Database Using DB Snapshots and AWS Lambda
Sameer Malik is a specialist solutions architect and Christian Williams is an enterprise solutions architect at Amazon Web Services. Many AWS users are taking advantage of the managed service offerings that are available in the AWS portfolio to remove much of the undifferentiated heavy lifting from their day-to-day activities. Amazon Relational Database Service (Amazon RDS) […]

Implementing DB Instance Stop and Start in Amazon RDS
This post is from Matt Merriel at AWS partner Kloud, and Marc Teichtahl, manager for AWS Partner Solutions Architecture Australia and New Zealand. Kloud uses the new stop and start capabilities in Amazon RDS to lower costs for customers who don’t require 24×7 access to their databases during the testing and development phases of their […]

Understanding Burst vs. Baseline Performance with Amazon RDS and GP2
When we think about database storage, the dimensions that matter are the size, latency, throughput, and IOPS of the volume. IOPS stands for input/output (operations) per second, and latency is a measure of the time it takes for a single I/O request to complete. As you can imagine, latency and IOPS are closely related and […]
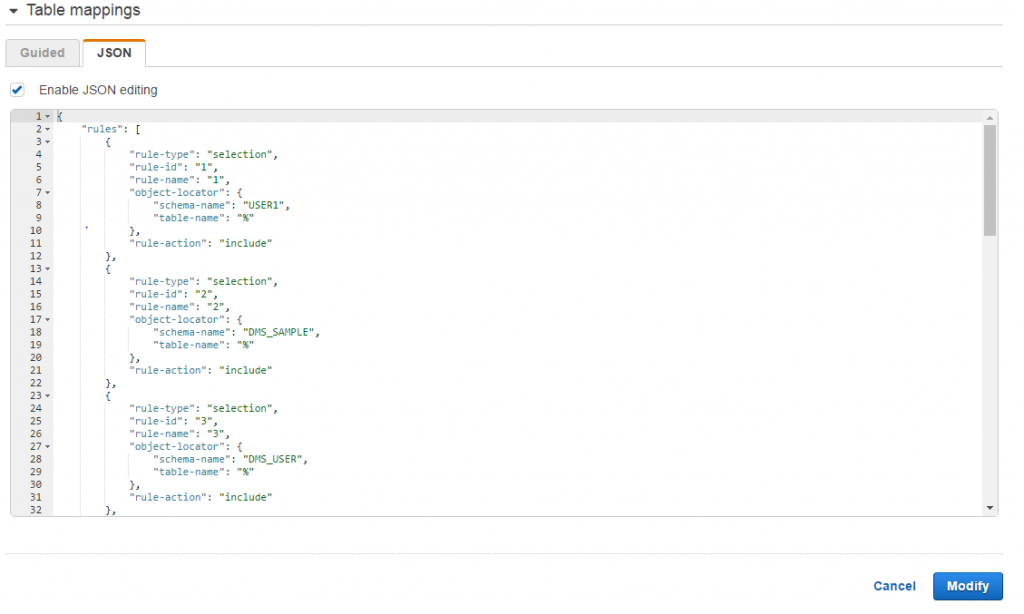
Oracle Migration Automated – How to Automate Generation of Selection and Transformation Rules for AWS Data Migration Service
Akm Raziul Islam is a database architect at Amazon Web Services. You can use AWS Data Migration Service (AWS DMS) to copy data from multiple schemas in an Oracle source to a single Amazon RDS for Oracle target. You can also migrate data to different schemas on a target. But to do this, you need […]

Installing JD Edwards EnterpriseOne on Amazon RDS for Oracle
Marc Teichtahl is a solutions architect at Amazon Web Services. Amazon Relational Database Service (Amazon RDS) is a web service that makes it easier to set up, operate, and scale a relational database in the cloud. It provides cost-efficient, resizable capacity for an industry-standard relational database and manages common database administration tasks. Amazon RDS offers […]