AWS Database Blog
Tag: Schema Conversion Tool (SCT)

Migration tips for developers converting Oracle and SQL Server code to PostgreSQL
PostgreSQL is one of the most popular open-source relational database systems. It is considered to be one of the top database choices when customers migrate from commercial databases such as Oracle and Microsoft SQL Server. AWS provides two managed PostgreSQL options: Amazon RDS and Amazon Aurora. In addition to providing managed PostgreSQL services, AWS also […]
Validating database objects after migration using AWS SCT and AWS DMS
Database migration can be a complicated task. It presents all the challenges of changing your software platform, understanding source data complexity, data loss checks, thoroughly testing existing functionality, comparing application performance, and validating your data. AWS provides several tools and services that provide a pre-migration checklist and migration assessments. You can use the AWS Schema […]

Use virtual partitioning in the AWS Schema Conversion Tool
In this post, we look at how to use virtual partitioning to optimize your data warehouse migrations using AWS SCT. Virtual partitioning speeds up large table extraction using parallel processing. It is a recommended best practice for data warehouse migrations.

AWS Database Migration Service and AWS Schema Conversion Tool now support IBM Db2 LUW as a source
Managing and operating relational databases is a basic piece of maintaining an effective business. Relational databases come in many flavors—commercial (Oracle, Microsoft SQL Server, IBM Db2, and so on) and open source (MySQL, PostgreSQL, and so on). With innovation and improvements in the open-source database world and cloud computing platforms like AWS, many enterprises are […]
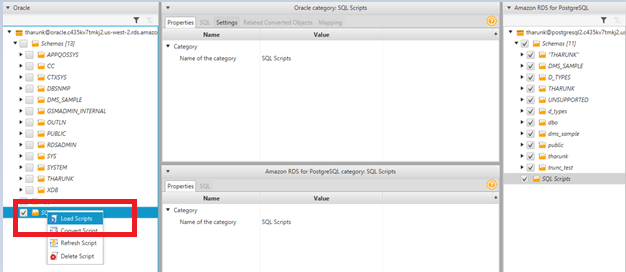
Schema Conversion Tool blog series: Introducing new features in build 613
The AWS Schema Conversion Tool (AWS SCT) helps convert your existing database schema from one database engine to another. You can convert from a relational OLTP schema or any supported data warehouse OLAP schema to Amazon RDS (for example, Amazon Aurora MySQL or Amazon Aurora PostgreSQL, among others). You can also convert from a relational […]

How the AWS Schema Conversion Tool Drove Trimble’s Database Migration Successes
By Todd Hofert, Director of Infrastructure Operations—FSM at Trimble Inc. The situation Recently, the Infrastructure Operations Group for Trimble’s Field Service Management division embarked on an aggressive initiative to migrate their privately hosted SaaS offerings to Amazon Web Services (AWS). The division faced the need for a hardware refresh, continuing cost reduction pressures, and a […]

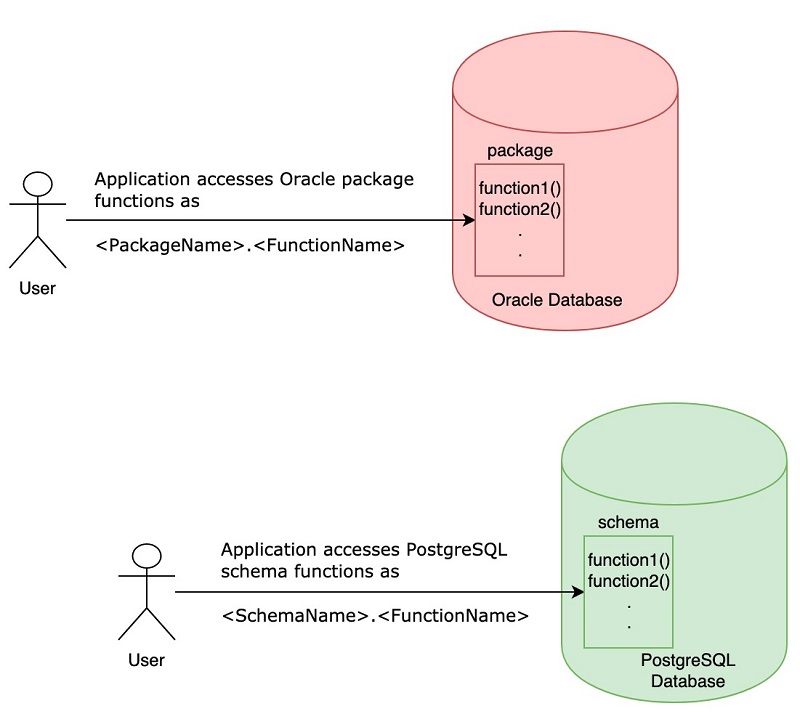
Challenges When Migrating from Oracle to PostgreSQL—and How to Overcome Them
David Rader is the vice president of engineering at OpenSCG. OpenSCG is an AWS Consulting Partner and a leading expert in PostgreSQL, helping customers migrate to, operate, and optimize PostgreSQL and other data platforms on premises and in the cloud. In previous posts, we looked at the overall approach for a successful database migration and […]

How to Migrate from MySQL to Amazon Aurora using AWS SCT and AWS DMS
MySQL is a great open-source database engine, which a lot of companies use because it’s cost-effective. However, like any other open-source database, it takes a lot of work to get commercial-grade performance out of it. As the size of your database increases, the complexity of scaling and crash recovery in MySQL also increases. Scaling out […]

Migrating a SQL Server Database to a MySQL-Compatible Database Engine
This post provides an overview of how you can migrate your Microsoft SQL Server database to a MySQL-compatible database engine such as Amazon RDS for MySQL, Amazon RDS for MariaDB, or Amazon Aurora MySQL. The following are the two main parts of a database migration: Schema conversion: Converting the schema objects is usually the most […]
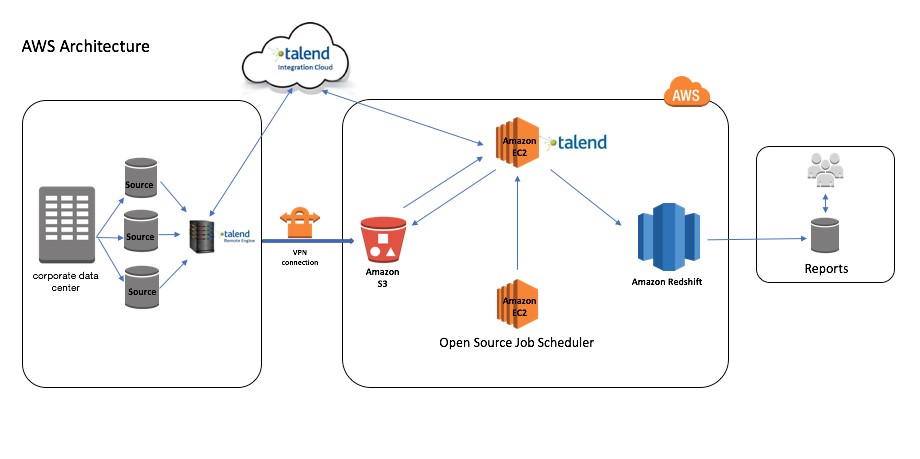
Using Amazon Redshift for Fast Analytical Reports
With digital data growing at an incomprehensible rate, enterprises are finding it difficult to ingest, store, and analyze the data quickly while keeping costs low. Traditional data warehouse systems need constant upgrades in terms of compute and storage to meet these challenges. In this post, we provide insights into how AWS Premier Partner Wipro helped […]